このトピックでは、Platform for AI (PAI) 、Data Science Workshop (DSW) 、およびFile Storage NAS (NAS) のDeep Learning Containers (DLC) を使用して、PyTorchベースのオフライン移行トレーニングを実行する方法について説明します。
前提条件
一般的なNASファイルシステムは、リージョンに作成されます。 詳細については、「NASコンソールでの汎用NASファイルシステムの作成」をご参照ください。
制限事項
このトピックで説明する操作は、一般的なコンピューティングリソースを使用し、パブリックリソースグループにデプロイされているクラスターにのみ適用できます。
手順1: データセットの作成
[データセット] ページに移動します。
最初にPAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、を選択します。
データセットページで、データセットの作成をクリックします。 [データセットの作成] ページで、[ストレージタイプ] パラメーターを [汎用NAS] に設定します。 基本データセットの作成方法の詳細については、「基本データセットの作成」をご参照ください。
手順2: DSWインスタンスの作成
DSWインスタンスを作成するには、次の表に示すパラメーターを設定します。 その他のパラメーターについては、「DSWインスタンスの作成」をご参照ください。
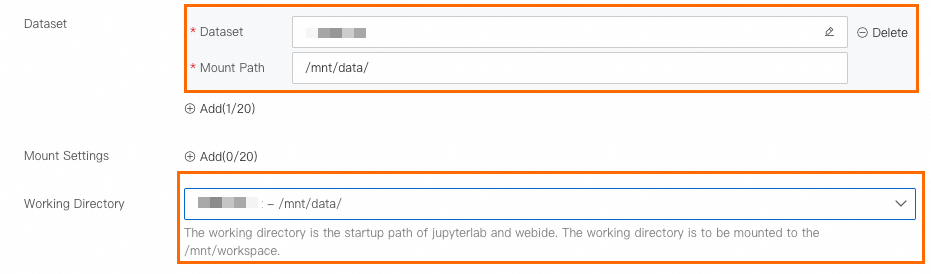
パラメーター | 説明 | |
環境情報 | データセットのマウント | [カスタムデータセット] をクリックし、ステップ1で作成したNASデータセットを選択し、[マウントパス] パラメーターを |
作業ディレクトリ |
| |
ネットワーク情報 | [VPC] | このパラメーターを設定する必要はありません。 |
ステップ3: データを準備する
このトピックで使用されるデータは、パブリックアクセスで使用できます。 こちらをクリックしてデータをダウンロードし、データを解凍して使用できます。
DSWインスタンスの開発環境に移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ページの左上隅で、PAIを使用するリージョンを選択します。
左側のナビゲーションウィンドウで、を選択します。
オプション: [Data Science Workshop (DSW)] ページで、検索ボックスにDSWインスタンスの名前またはキーワードを入力して、DSWインスタンスを検索します。
インスタンスのアクション列の開くをクリックします。
DSW開発環境で、上部のナビゲーションバーにあるノートタブをクリックします。
データをダウンロードします。
左上のツールバーの
 アイコンをクリックしてフォルダを作成します。 この例では、フォルダ名としてpytorch_transfer_learningが使用されています。
アイコンをクリックしてフォルダを作成します。 この例では、フォルダ名としてpytorch_transfer_learningが使用されています。 DSW開発環境で、上部のナビゲーションバーにあるターミナルタブをクリックします。
ターミナルタブで、次の図に示すようにコマンドを実行します。
cdコマンドを使用して作成したフォルダーに移動し、wgetコマンドを使用してデータセットをダウンロードできます。cd /mnt/workspace/pytorch_transfer_learning/ wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/data.tar.gzhttps://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/data.tar.gzは、データセットファイルをダウンロードするためのURLです。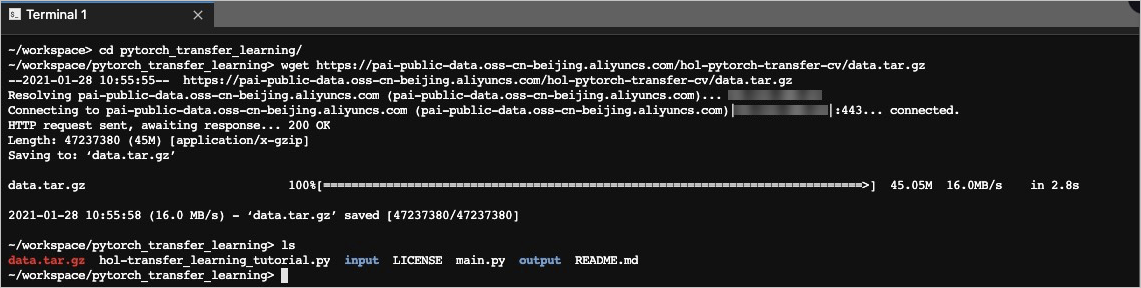
tar -xf ./data.tar.gzコマンドを実行して、データセットを解凍します。[ノートブック] タブをクリックします。 pytorch_transfer_learningディレクトリに移動し、抽出したhymenoptera_dataフォルダを右クリックし、[名前の変更] をクリックして、ファイルの名前を入力として変更します。
ステップ4: トレーニングコードとモデル格納フォルダを準備する
DSWインスタンスの [ターミナル] タブで、
wgetコマンドを実行して、トレーニングコードをpytorch_transfer_learningフォルダーにダウンロードします。cd /mnt/workspace/pytorch_transfer_learning/ wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.pyhttps://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.pyは、トレーニングコードをダウンロードするためのURLです。pytorch_transfer_learningという名前のフォルダを作成します。出力トレーニングされたモデルを保存します。
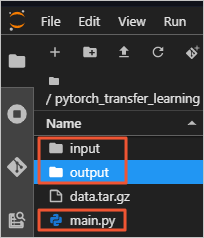
mkdir outputpytorch_transfer_learningフォルダーに含まれるコンテンツを表示します。
フォルダには次のコンテンツが含まれます。
input: トレーニングデータを格納するフォルダ。
main.py: トレーニングコードファイル。
output: トレーニング済みモデルを格納するフォルダー。
ステップ5: スケジュールされたジョブを作成する
[ジョブの作成] ページに移動します。
PAI コンソールにログインします。 上部のナビゲーションバーで、目的のリージョンを選択します。 右側のページで、目的のワークスペースを選択し、[ディープラーニングコンテナ (DLC) の入力] をクリックします。
[ディープラーニングコンテナ (DLC)] ページで、[ジョブの作成] をクリックします。
[ジョブの作成] ページで、パラメーターを設定します。 下表にパラメーターを示します。
セクション
パラメーター
説明
基本情報
ジョブ名
ジョブの名前を指定します。
環境情報
ノードイメージ
[Alibaba Cloudイメージ] を選択し、ドロップダウンリストからPyTorchイメージを選択します。 この例では、
pytorch-training:1.12-gpu-py39-cu113-ubuntu20.04イメージが使用されています。データセット
[カスタムデータセット] をクリックし、手順1で作成したNASデータセットを選択します。
Startupコマンド
このパラメーターを
python /mnt/data/pytorch_transfer_learning/main.py -i /mnt/data/pytorch_transfer_learning/input -o /mnt/data/pytorch_transfer_learning/outputに設定します。サードパーティのライブラリ
[リストから選択] をクリックし、テキストボックスに次の内容を入力します。
numpy==1.16.4 absl-py==0.11.0コードビルド
このパラメーターを設定する必要はありません。
リソース情報
ソース
[パブリックリソース] を選択します。
フレームワーク
[PyTorch] を選択します。
求人リソース
インスタンスタイプを選択し、インスタンス数を指定します。 例: [リソースタイプ] ページの [CPU] タブで [ecs.g6.xlarge] を選択します。 [ノード] パラメーターを1に設定します。
OKをクリックします。
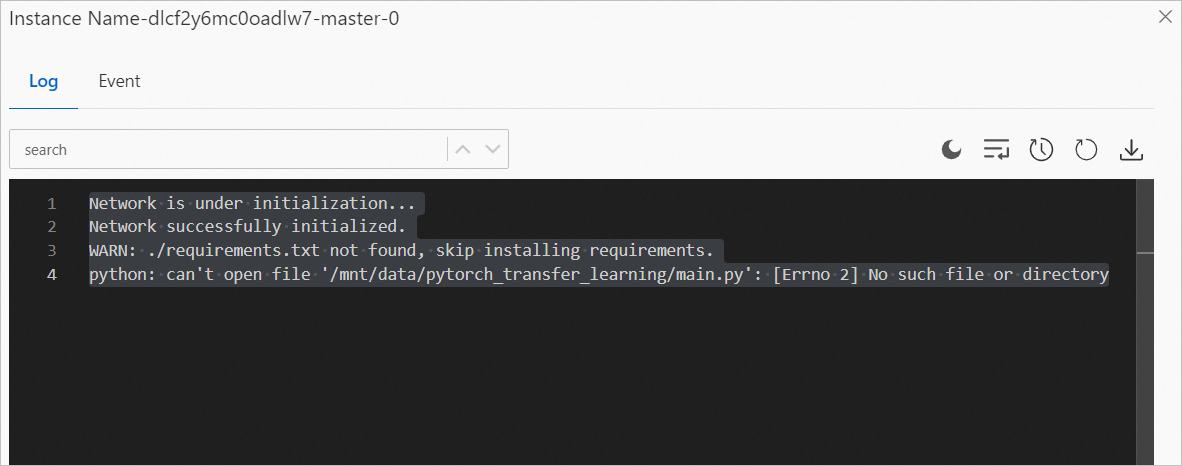
ステップ6: ジョブの詳細とログを表示する
[ディープラーニングコンテナ (DLC)] ページで、表示するジョブの名前をクリックします。
ジョブの詳細ページの概要タブで、ジョブの基本情報とリソース情報を表示します。
ジョブ詳細ページの概要タブのインスタンスセクションで、管理するインスタンスを見つけて、アクション列のログをクリックしてログを表示します。
ログの例を次の図に示します。