このトピックでは、グラフアルゴリズムを使用して財務リスクを管理する方法について説明します。
背景情報
グラフアルゴリズムは、関係分析シナリオで使用されます。 グラフアルゴリズムは、頂点間の接続を含む関係グラフにデータを配置します。 接続はエッジとして表される。 AI用機械学習プラットフォーム (PAI) は、Kコア、最大接続サブグラフ、ラベル伝播分類など、いくつかのグラフアルゴリズムコンポーネントを提供します。
次の図は、相互リンクされたグループの関係グラフの例を示しています。 図中の矢印は、同僚や親戚などのこれらの人々の間の関係を表しています。 このグラフでは、Enochは信頼できる顧客であり、Evanは詐欺師です。 この情報と関係グラフに基づいて、グラフアルゴリズムを使用して、各人のクレジットインデックス、つまりその人が詐欺師である確率を計算できます。 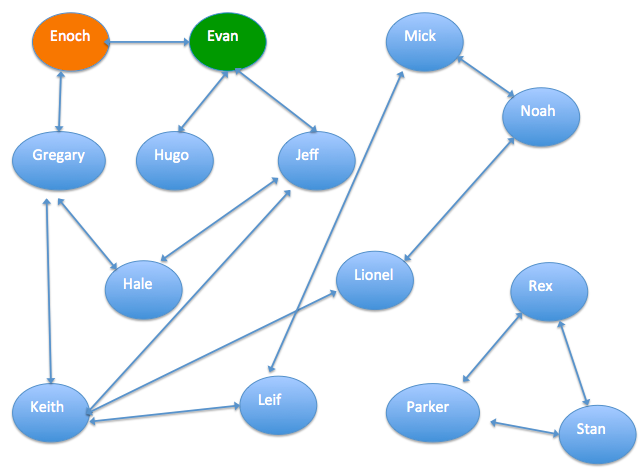
データセット
次の表に、このトピックで使用されるデータセットのフィールドについて説明します。
項目 | 意味 | データ型 | 説明 |
start_point | エッジの開始頂点 | STRING | 人の名前。 |
end_point | エッジの頂点の終了 | STRING | 人の名前。 |
集計 | 近さ | DOUBLE | 二人の親密さ。 値が大きいほど、2人の関係が近いことを示す。 |
次の図は、パイプラインで使用されるサンプルデータを示しています。 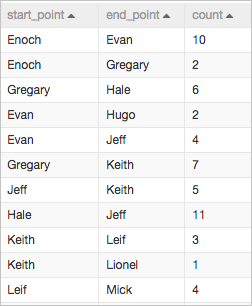
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
このタブで、Financial Risk Managementテンプレートを見つけ、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、次のパラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、[財務リスク管理] パイプラインをダブルクリックしてパイプラインを開きます。
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、組み込みテンプレートに基づいてパイプラインを自動的に作成します。
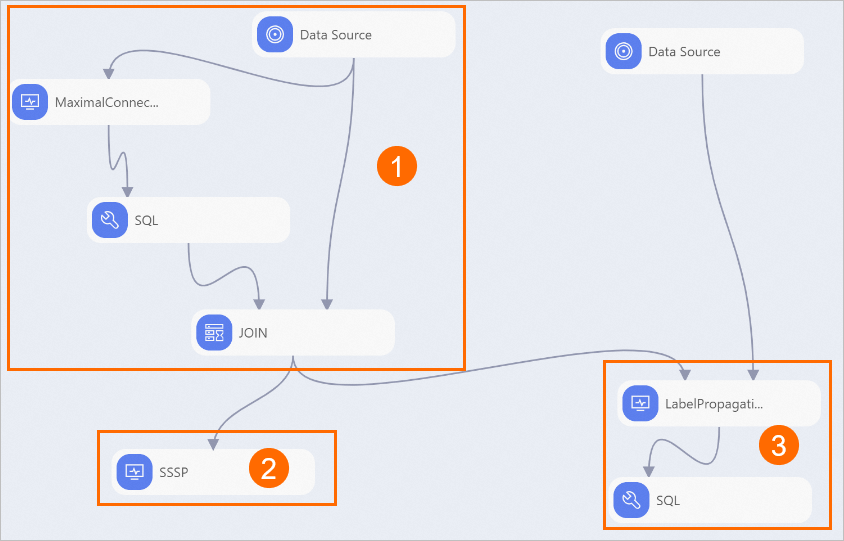
セクション
説明
①
最大接続サブグラフコンポーネントは、関係グラフ内の人々を2つのグループに分類し、各グループにIDを割り当てます。 次に、SQL ScriptおよびJOINコンポーネントは、関係グラフ内の無関係な人を削除します。
次の図に示すように、[最大接続サブグラフ] コンポーネントは、関連しない人を削除するために、相互リンクされた人の最大数を含むセットを見つけることができます。
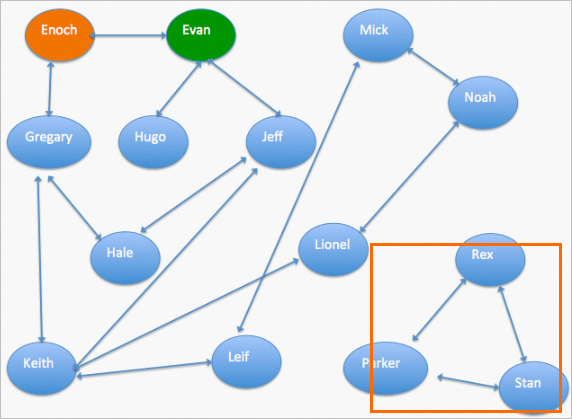
②
このセクションに表示されるコンポーネントは、2つの頂点間の距離を調べます。 次の図に示すように、[単一ソースの最短パス] コンポーネントの出力の [距離] フィールドは、目的の人に到達するためにEnochが連絡する必要がある人の数を示します。
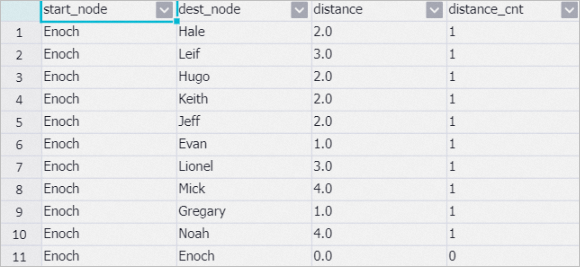
③
Data Sourceコンポーネントは、ラベル付きデータをインポートします。 重みフィールドは、人が詐欺師である確率を示す。 次に、Label Propagation Classificationコンポーネントは、ラベルなしの頂点のラベルを予測します。 最後に、SQL Scriptコンポーネントは結果をフィルタリングし、各人が詐欺師である確率を示します。
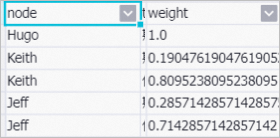
ラベル伝播分類は、半教師付き分類アルゴリズムである。 関係グラフとラベル付きデータを入力として使用し、ラベル付き頂点のラベルに基づいてラベルなし頂点のラベルを予測します。 ラベル伝播分類は、各頂点のラベルをその頂点の隣の頂点に伝播する。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅にある [
 ] をクリックします。
] をクリックします。 パイプラインの実行後、キャンバスで [SQLスクリプト] を右クリックし、[データの表示] を選択します。 表示されるタブで、各人が詐欺師である確率を表示します。