このトピックでは、Deep Learning Containers (DLC) を使用して、PyTorchに基づくオフライン転送学習をトレーニングする方法について説明します。
ステップ1: データの準備
このトピックでは、トレーニングに使用されるデータは、パブリックストレージメディアに事前に保存されています。 データを直接ダウンロードでき、追加のデータを準備する必要はありません。
手順2: トレーニングコードとモデルストレージファイルの準備
このトピックでは、トレーニングコードパッケージはパブリックストレージメディアに事前に格納されています。 コードパッケージを直接ダウンロードでき、追加のコードを開発する必要はありません。
ステップ3: ジョブを作成する
[ジョブの作成] ページに移動します。
PAI コンソールにログインします。 リージョンとワークスペースを選択します。 次に、[ディープラーニングコンテナ (DLC) の入力] をクリックします。
[ディープラーニングコンテナ (DLC)] ページで、[ジョブの作成] をクリックします。
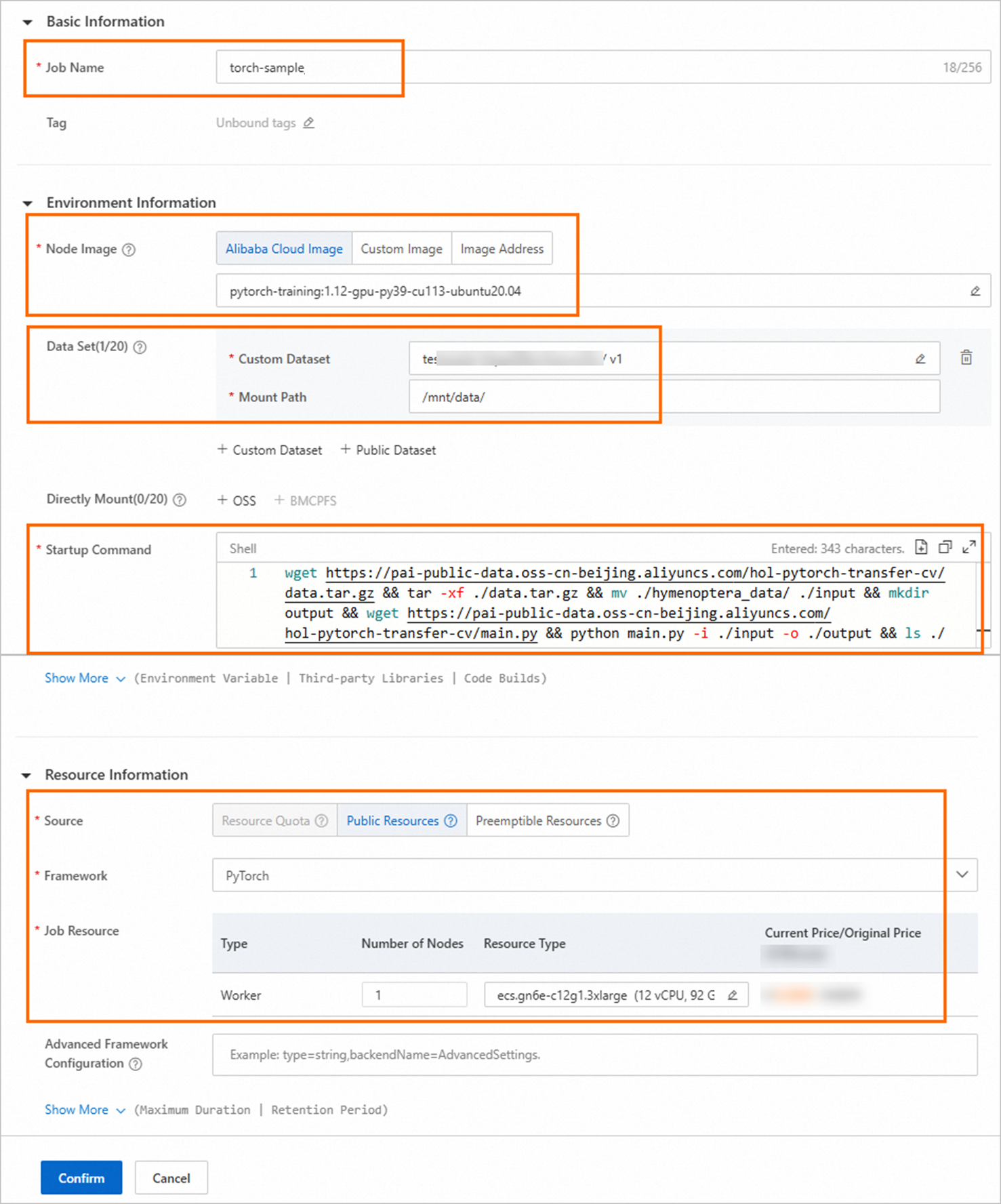
ジョブの作成ページで、次の表に示すパラメーターを設定し、残りのパラメーターにはデフォルト値を使用します。
パラメーター
説明
基本情報
ジョブ名
ジョブの名前を入力します。 例: トーチ-サンプル
環境情報
ノードイメージ
[Alibaba Cloudイメージ] をクリックし、PyTorchイメージを選択します。
データセット
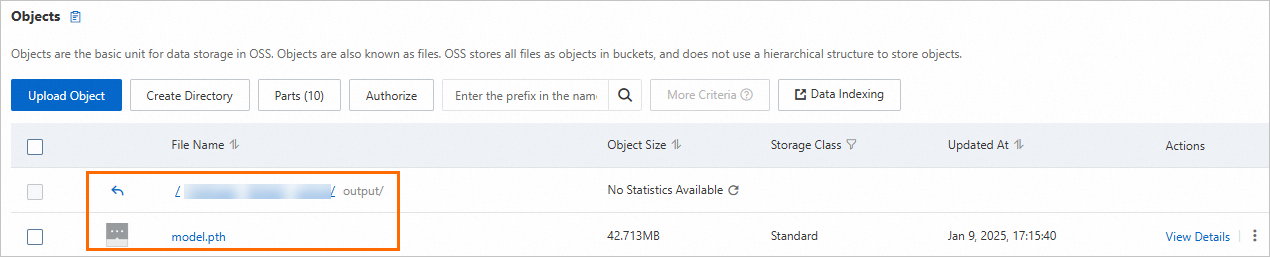
トレーニング結果をローカルマシンに保存する場合は、カスタムデータセットをマウントして、結果をデータセットのファイルシステムに保存できます。 OSSデータセットを例に取ります。 [カスタムデータセット] をクリックし、次のパラメーターを設定します。
カスタムデータセット: 作成したOSSデータセットを選択します。 データセットの作成方法の詳細については、「データセットの作成と管理」をご参照ください。
マウントパス:
/mnt/data/に設定します。
Startupコマンド
次のコマンドを入力して、データのダウンロード、コードパッケージのダウンロード、トレーニングジョブの実行、モデルの確認、およびトレーニング結果をマウントされたデータセットに保存する手順を実行します。
wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/data.tar.gz && tar -xf ./data.tar.gz && mv ./hymenoptera_data/ ./input && mkdir output && wget https://pai-public-data.oss-cn-beijing.aliyuncs.com/hol-pytorch-transfer-cv/main.py && python main.py -i ./input -o ./output && ls ./outputリソース情報
ソース
[パブリックリソース] を選択します。
フレームワーク
[PyTorch] を選択します。
求人リソース
ノード数: 値を1に設定します。
インスタンスタイプ:
 をクリックし、インスタンスタイプを選択します。 たとえば、ecs.gn6e-c12g1.3xlargeです。 現在のリージョンでタイプを使用できない場合は、別のリージョンでジョブを作成できます。 従量課金をサポートするリージョンについては、「Deep Learning Containers (DLC) 」をご参照ください。
をクリックし、インスタンスタイプを選択します。 たとえば、ecs.gn6e-c12g1.3xlargeです。 現在のリージョンでタイプを使用できない場合は、別のリージョンでジョブを作成できます。 従量課金をサポートするリージョンについては、「Deep Learning Containers (DLC) 」をご参照ください。
OKをクリックします。
ディープラーニングコンテナ (DLC) ページが表示されます。
ステップ4: トレーニングジョブの詳細とログを表示する
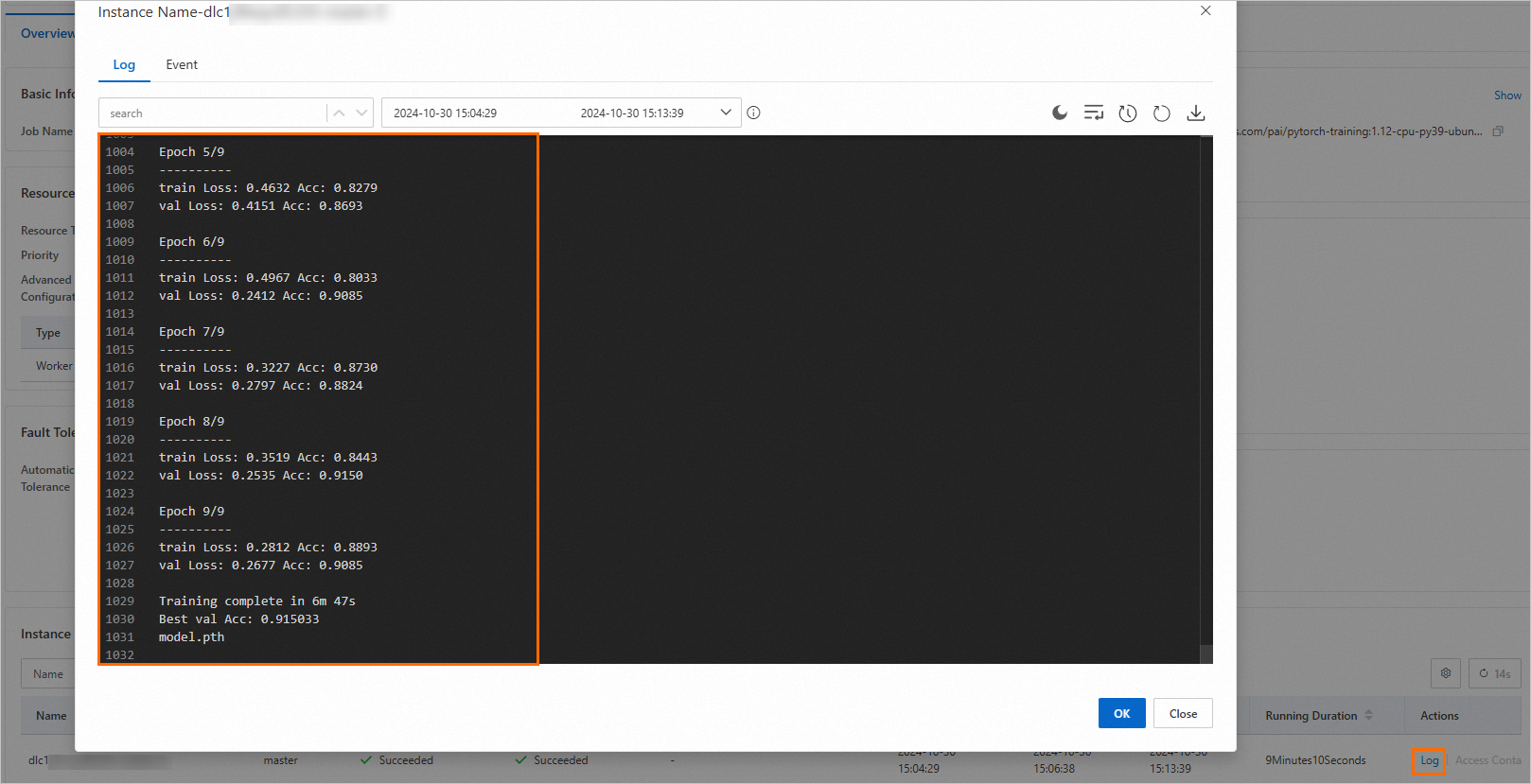
ディープラーニングコンテナ (DLC)ページで、ジョブ名をクリックします。
ジョブの詳細ページで、ジョブの基本情報とリソース情報を表示します。
ジョブ詳細ページの下部にあるインスタンスセクションで、目的のノードを見つけて、アクション列のログをクリックしてノードのログを表示します。
マウントされたデータセットのファイルシステムに移動して結果を表示します。 OSSを例にとる: