責任ある AI は、AI モデル開発者やビジネスリーダーにとって極めて重要です。これは、開発、トレーニング、ファインチューニング、評価、デプロイメントなど、AI モデルのライフサイクル全体における主要なプラクティスです。これにより、AI モデルが安全、安定、公正であり、倫理基準に準拠していることを保証できます。Platform for AI (PAI) は、Data Science Workshop (DSW) での責任ある AI ツールの統合をサポートしており、AI モデルに対する公平性分析、エラー分析、解釈可能性分析を可能にします。
仕組み
エラー分析は、責任ある AI のプラクティスの一環として、モデルのパフォーマンスを理解し、向上させるための重要なステップです。中核となる原則は、AI モデルの予測におけるエラーを体系的に特定、分析、解決し、その精度と公平性を向上させることです。エラー分析の中核となる原則は次のとおりです。
エラーの特定: モデルの予測エラーを特定します。これは通常、モデルの予測と真の値を比較して不一致を見つけることによって行われます。エラーは、誤検知 (false positive) や偽陰性 (false negative) など、さまざまなタイプに分類できます。
エラーの分類: これらのエラーをその特性に基づいて分類します。これにより、データの不均衡、不十分な特徴、モデルのバイアスなどの根本原因をより深く理解できます。このプロセスには、ドメインの専門知識と人間の判断が必要になる場合があります。
エラーの根本原因の分析: 各エラーカテゴリの背後にある理由を分析します。このステップは、モデルの最適化に直接情報を提供するため、非常に重要です。これには、データ品質、モデル設計、特徴エンジニアリング、またはデータ表現の分析が含まれる場合があります。
是正措置の実施: エラー分析の結果に基づいて、開発チームはモデルの問題に対処するための特定の措置を講じることができます。これらの措置には、データのクリーニング、データセットのリバランス、モデルアーキテクチャの変更、新しい特徴の導入、または異なるアルゴリズムの使用が含まれる場合があります。
反復と評価: エラー分析はワンタイムタスクではなく、継続的な反復プロセスです。モデルに修正を加えるたびに、再度エラー分析を実行して、変更が効果的であったか、パフォーマンスが向上したか、または新しい問題が発生したかを評価する必要があります。
文書化と報告: 透明性と解釈可能性を確保するために、エラー分析のプロセス、調査結果、および講じられた是正措置を徹底的に文書化します。これは、チームメンバーがモデルの制限を理解するのに役立ち、他のプロジェクトフェーズに貴重なフィードバックを提供します。
このトピックでは、国勢調査データセットに基づいて個人の年収が 50K を超えるかどうかを予測するという例のタスクを使用して、PAI の DSW で responsible-ai-toolbox を使用してモデルのエラー分析を実行する方法を説明します。
前提条件
DSW インスタンス。お持ちでない場合は、「DSW インスタンスの作成」をご参照ください。推奨される構成は次のとおりです。
推奨インスタンスタイプ: ecs.gn6v-c8g1.2xlarge
イメージ: Python 3.9 以降。このトピックでは、使用される公式イメージは tensorflow-pytorch-develop:2.14-pytorch2.1-gpu-py311-cu118-ubuntu22.04 です。
モデル: responsible-ai-toolbox は、Sklearn、PyTorch、および TensorFlow フレームワークに基づく回帰モデルと二項分類モデルをサポートします。
トレーニングデータセット: 独自のデータセットを使用することをお勧めします。例のデータセットを使用するには、「ステップ 3. データセットの準備」の手順に従ってください。
モデル: 独自のモデルを使用することをお勧めします。例のモデルを使用するには、「ステップ 5: モデルのトレーニング」の手順に従ってください。
ステップ 1: DSW ギャラリーに移動する
PAI コンソールにログオンします。
上部のナビゲーションバーで、必要に応じてリージョンを選択します。
左側のナビゲーションウィンドウで、[スタートガイド] > [Notebook ギャラリー] を選択し、「Responsible AI-Error Analysis」を検索して、対応するカードの [DSW で開く] をクリックします。
DSW インスタンスを選択し、[Notebook を開く] をクリックします。システムが「Responsible AI-Error Analysis」Notebook を開きます。
ステップ 2: 依存関係のインポート
後続の評価のために、responsible-ai-toolbox (raiwidgets) の依存関係パッケージをインストールします。
!pip install raiwidgets==0.34.1後続のトレーニングのために、Responsible AI と Sklearn の依存関係パッケージをインポートします。
# Responsible AI の依存関係をインポート
import zipfile
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
import pandas as pd
from lightgbm import LGBMClassifier
from raiutils.dataset import fetch_dataset
import sklearn
from packaging import version
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformerステップ 3: データセットの準備
必要なデータセットをダウンロードして解凍します。解凍後、ファイルにはトレーニングデータ adult-train.csv とテストデータ adult-test.csv が含まれます。
# データセットファイルの名前を指定します。
outdirname = 'responsibleai.12.28.21'
zipfilename = outdirname + '.zip'
# データセットをダウンロードして解凍します。
fetch_dataset('https://publictestdatasets.blob.core.windows.net/data/' + zipfilename, zipfilename)
with zipfile.ZipFile(zipfilename, 'r') as unzip:
unzip.extractall('.')ステップ 4: データのプリプロセス
トレーニングデータ
adult-train.csvとテストデータadult-test.csvを読み込みます。トレーニングデータとテストデータを特徴とターゲット変数に分割します。ターゲット変数は、モデルが予測する真の値です。特徴は、各データインスタンス内の他のすべての変数です。この例では、ターゲット変数は
incomeで、特徴にはworkclass、education、marital-statusなどが含まれます。トレーニングデータをトレーニング用に NumPy 配列形式に変換します。
# トレーニングデータとテストデータを読み込みます。
train_data = pd.read_csv('adult-train.csv', skipinitialspace=True)
test_data = pd.read_csv('adult-test.csv', skipinitialspace=True)
# 特徴とターゲット変数の列を定義します。
target_feature = 'income'
categorical_features = ['workclass', 'education', 'marital-status',
'occupation', 'relationship', 'race', 'gender', 'native-country']
# 特徴とターゲット変数を分割する関数を定義します。
def split_label(dataset, target_feature):
X = dataset.drop([target_feature], axis=1)
y = dataset[[target_feature]]
return X, y
# 特徴とターゲット変数を分割します。
X_train_original, y_train = split_label(train_data, target_feature)
X_test_original, y_test = split_label(test_data, target_feature)
# NumPy 配列に変換します。
y_train = y_train[target_feature].to_numpy()
y_test = y_test[target_feature].to_numpy()
# テストサンプルを定義します。
test_data_sample = test_data.sample(n=500, random_state=5)独自のデータセットを読み込むこともできます。CSV 形式のデータセットのコマンドは次のとおりです。
import pandas as pd
# CSV 形式で独自のデータセットを読み込みます。
# pandas を使用して CSV ファイルを読み取ります。
try:
data = pd.read_csv(filename)
except:
passステップ 5: モデルのトレーニング
この例では、Scikit-learn に基づくデータトレーニングパイプラインを定義し、二項分類モデルをトレーニングします。
# scikit-learn のバージョンに基づいて ohe_params パラメーターを定義します。
if version.parse(sklearn.__version__) < version.parse('1.2'):
ohe_params = {"sparse": False}
else:
ohe_params = {"sparse_output": False}
# 特徴変換のための分類パイプラインを定義します。入力パラメーター X はトレーニングデータを表します。
def create_classification_pipeline(X):
pipe_cfg = {
'num_cols': X.dtypes[X.dtypes == 'int64'].index.values.tolist(),
'cat_cols': X.dtypes[X.dtypes == 'object'].index.values.tolist(),
}
num_pipe = Pipeline([
('num_imputer', SimpleImputer(strategy='median')),
('num_scaler', StandardScaler())
])
cat_pipe = Pipeline([
('cat_imputer', SimpleImputer(strategy='constant', fill_value='?')),
('cat_encoder', OneHotEncoder(handle_unknown='ignore', **ohe_params))
])
feat_pipe = ColumnTransformer([
('num_pipe', num_pipe, pipe_cfg['num_cols']),
('cat_pipe', cat_pipe, pipe_cfg['cat_cols'])
])
pipeline = Pipeline(steps=[('preprocessor', feat_pipe),
('model', LGBMClassifier(random_state=0))])
return pipeline
# 分類モデルのトレーニングパイプラインを作成します。
pipeline = create_classification_pipeline(X_train_original)
# モデルをトレーニングします。
model = pipeline.fit(X_train_original, y_train)ステップ 6: 責任ある AI コンポーネントの追加
次のスクリプトを実行して、エラー分析コンポーネントを Responsible AI に追加し、rai_insights でインサイトを計算します。
# RAI ダッシュボードコンポーネントをインポートします。
from raiwidgets import ResponsibleAIDashboard
from responsibleai import RAIInsights
# RAIInsights オブジェクトを定義します。
from responsibleai.feature_metadata import FeatureMetadata
feature_metadata = FeatureMetadata(categorical_features=categorical_features, dropped_features=[])
rai_insights = RAIInsights(model, train_data, test_data_sample, target_feature, 'classification',
feature_metadata=feature_metadata)
# エラー分析コンポーネントを追加します。
rai_insights.error_analysis.add()
# RAI 計算を実行します。
rai_insights.compute()ステップ 7: 責任ある AI ダッシュボードの作成
さまざまなフィルターを適用して、さまざまなコホートを作成します。これらのフィルター処理されたコホートに対してエラー分析を実行できます。例:
年齢が 65 歳未満で、週あたりの労働時間が 40 時間超。
marital-statusが "Never-married" または "Divorced"。データグループインデックスが 20 未満。
予測 Y が
>50K。真の Y が
>50K。
ResponsibleAIDashboardをインポートし、responsible-ai-toolbox を使用してモデルを分析します。
from raiutils.cohort import Cohort, CohortFilter, CohortFilterMethods
import os
from urllib.parse import urlparse
# 年齢が 65 歳未満で、週あたりの労働時間が 40 時間超
cohort_filter_age = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[65],
column='age')
cohort_filter_hours_per_week = CohortFilter(
method=CohortFilterMethods.METHOD_GREATER,
arg=[40],
column='hours-per-week')
user_cohort_age_and_hours_per_week = Cohort(name='Cohort Age and Hours-Per-Week')
user_cohort_age_and_hours_per_week.add_cohort_filter(cohort_filter_age)
user_cohort_age_and_hours_per_week.add_cohort_filter(cohort_filter_hours_per_week)
# marital-status が "Never-married" または "Divorced"
cohort_filter_marital_status = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=["Never-married", "Divorced"],
column='marital-status')
user_cohort_marital_status = Cohort(name='Cohort Marital-Status')
user_cohort_marital_status.add_cohort_filter(cohort_filter_marital_status)
# データグループインデックスが 20 未満。
cohort_filter_index = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[20],
column='Index')
user_cohort_index = Cohort(name='Cohort Index')
user_cohort_index.add_cohort_filter(cohort_filter_index)
# 予測 Y が '>50K'
cohort_filter_predicted_y = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=['>50K'],
column='Predicted Y')
user_cohort_predicted_y = Cohort(name='Cohort Predicted Y')
user_cohort_predicted_y.add_cohort_filter(cohort_filter_predicted_y)
# 真の Y が '>50K'
cohort_filter_true_y = CohortFilter(
method=CohortFilterMethods.METHOD_INCLUDES,
arg=['>50K'],
column='True Y')
user_cohort_true_y = Cohort(name='Cohort True Y')
user_cohort_true_y.add_cohort_filter(cohort_filter_true_y)
cohort_list = [user_cohort_age_and_hours_per_week,
user_cohort_marital_status,
user_cohort_index,
user_cohort_predicted_y,
user_cohort_true_y]
# 責任ある AI ダッシュボードを作成します。
metric_frame_tf = ResponsibleAIDashboard(rai_insights, cohort_list=cohort_list, feature_flights="dataBalanceExperience")
# リダイレクト用の URL を設定します。
metric_frame_tf.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_tf.config['baseUrl']).port,
os.environ.get('dsw_region') )ステップ 8: 責任ある AI ダッシュボードでのエラー分析
URL をクリックして、責任ある AI ダッシュボードにアクセスします。

エラー分析を表示します。
ツリーマップ
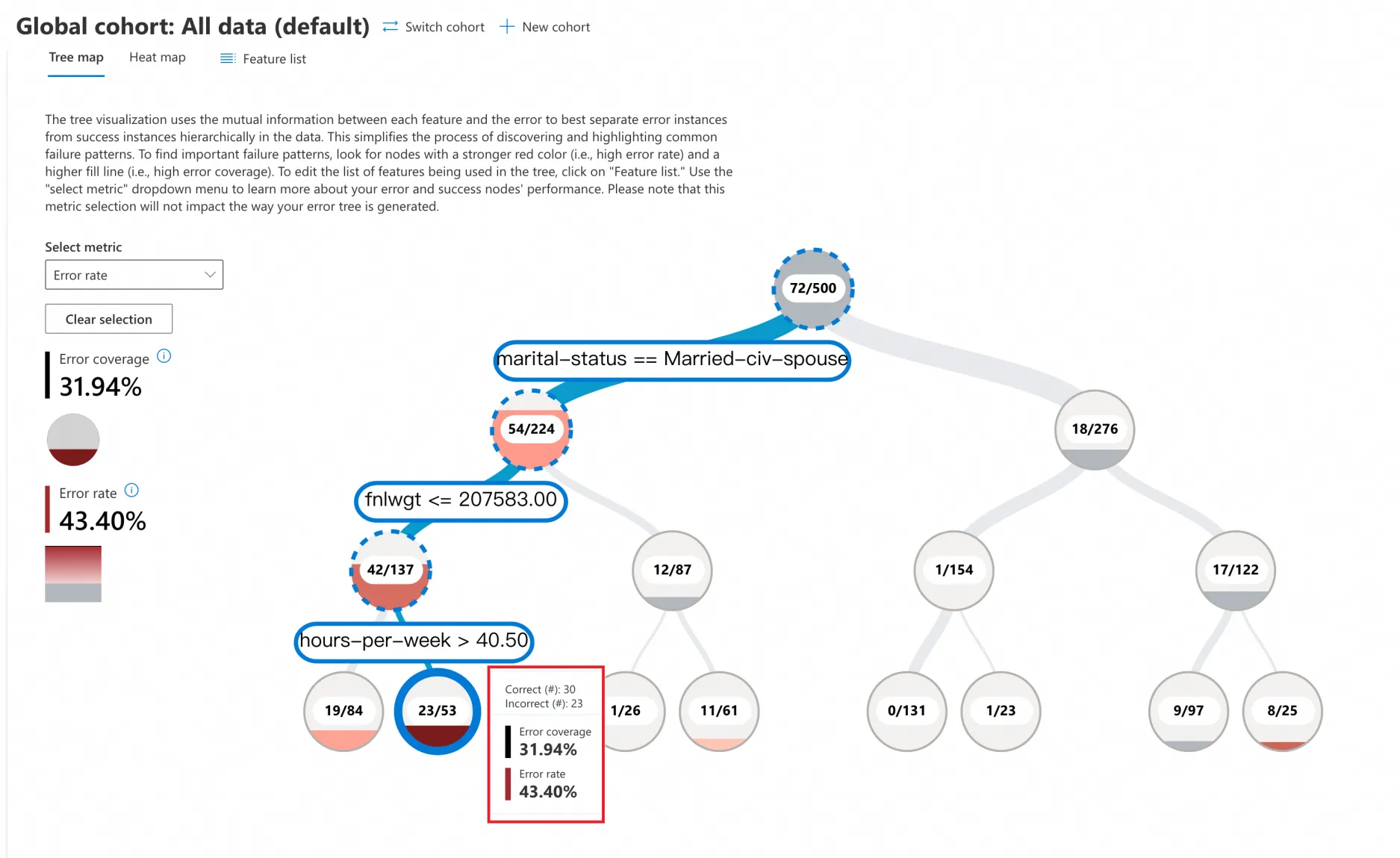
[ツリーマップ] をクリックし、[メトリックの選択] ドロップダウンで [エラー率] を選択します。エラー分析のツリービューでは、モデルの特徴のさまざまな値に基づいてデータが二分木に分割されます。たとえば、ツリーのルートノードの下にある 2 つのブランチは、以下を表します。
marital-status == Married-civ-spouse(54/224)
marital-status != Married-civ-spouse(18/276)
この例には 500 個のサンプルと 72 個の予測エラーが含まれており、エラー率は 72/500 = 14.4% です。二分木の各ノードは、ブランチの条件を満たすデータポイントの総数、予測エラーの数、エラー率を示します。
赤いノードに注目してください。赤色が濃いほど、エラー率が高いことを示します。
この例では、最も濃い赤色のリーフノードをクリックすると、これらの条件を満たすデータに対するモデルの予測エラー率が 43.40% にもなることがわかります。
marital-status == Married-civ-spouse
fnlwgt <= 207583
hours-per-week > 40.5
ヒートマップ
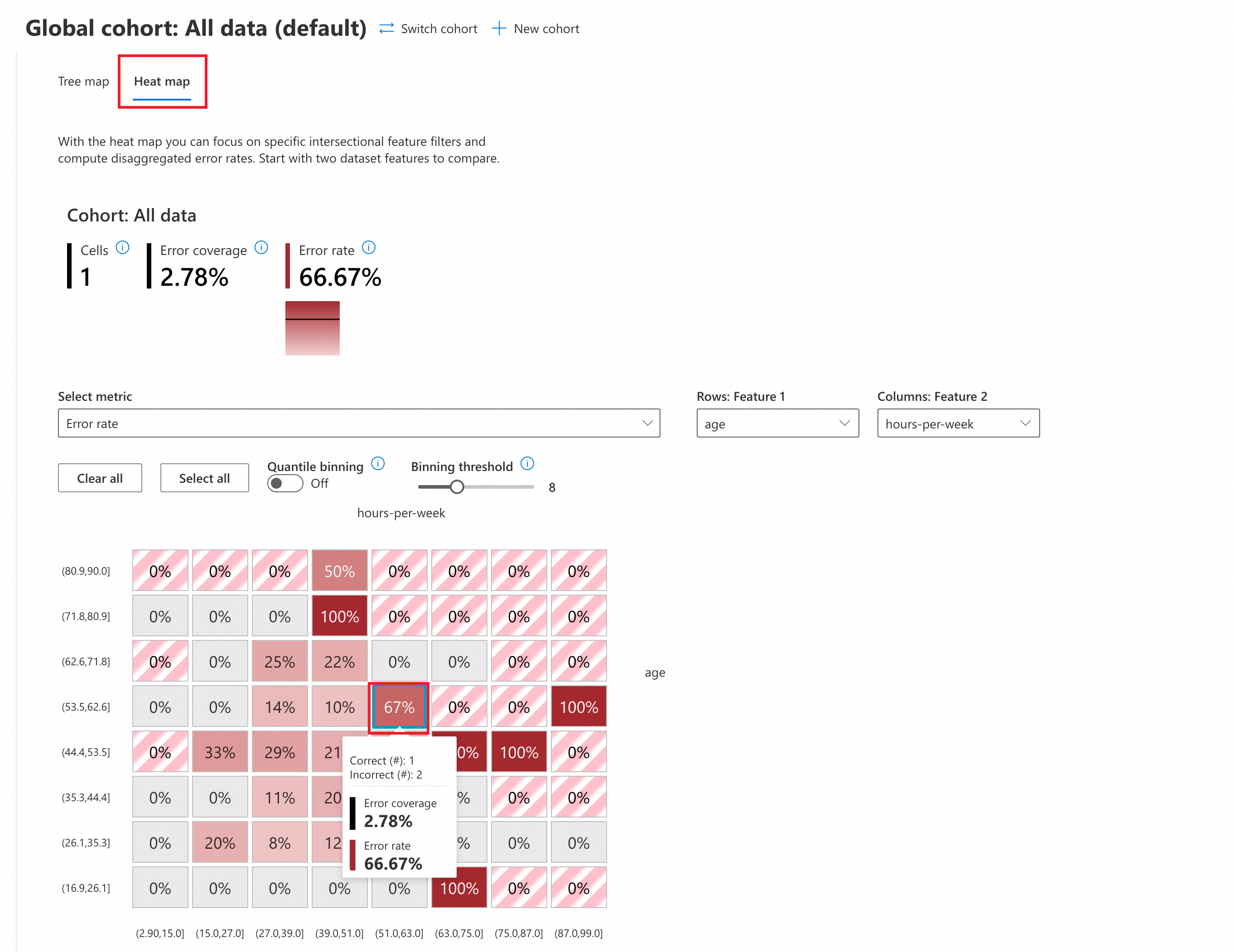
[ヒートマップ] をクリックしてヒートマップビューに切り替えます。[メトリックの選択] ドロップダウンで [エラー率] を選択してエラー分析を実行します。
(オプション) パラメーターを構成します。
分位数ビニング: このメソッドは、連続変数をいくつかの間隔に分割し、各間隔に同じ数のデータポイントが含まれるようにします。
オフ: デフォルトの均一ビニング戦略を使用します。この戦略では、各間隔の長さが同じになります。
オン: 分位数ビニングを有効にします。各間隔に同じ数のデータポイントが含まれるようになり、間隔全体でデータが均等に分散されます。
ビニングしきい値: データ間隔の数を設定します。しきい値を調整すると、間隔の数が変わります (この例では、デフォルトは 8 で、
ageとhours-per-weekを 8 つの等しい間隔に分割します)。
ヒートマップでは、相互分析のために 2 つの入力特徴を選択できます。この例では、ヒートマップ分析に
ageとhours-per-weekを使用します。赤いセルに注目してください。赤色が濃いほど、エラー率が高いことを示します。
分析によると、2 つの特徴が次の範囲に分類される場合、エラー率が最も高くなります (最大 100%)。
age [71.8,80.9], hours-per-week[39.0,51.0]
age [44.4,53.5], hours-per-week[75.0,87.0]
age [16.9,26.1], hours-per-week[63.0,75.0]
...