Machine Learning Platform for AI (PAI) は、機能エンコード、モデルトレーニング、モデル評価などの包括的な機能を提供します。 システム異常のフィーチャを抽出してラベル付けすることで、モデルを作成できます。 次に、モデルを使用してシステムメトリックを監視し、システム異常を予測できます。
背景情報
ユーザシステムは、異常に遭遇することがある。 例えば、O&MシステムのCPU使用率が急増したり、システムが不正な情報で溢れてしまったりする。 ユーザーシステムのメトリックをリアルタイムで監視し、予防措置を講じて、異常なメトリックに対するリアルタイムのアラートを実装できれば、ユーザーシステムがリスクにさらされる可能性がはるかに低くなります。
解決策
PAIは、メトリックモニタリングに基づく分類アルゴリズムのセットを提供する。 これらのアルゴリズムを使用してバイナリ分類モデルを作成し、メトリックを監視し、システムの異常をさらに検出できます。 次に、モデルをオンラインシステムにデプロイして、ニアラインリスク管理を実装できます。 PAIのこれらの分類アルゴリズムを使用してモデルを作成するには、次の条件を満たす必要があります。
機械学習の古典的なアルゴリズム、特に機能工学とバイナリ分類アルゴリズムの知識を習得します。
あなたは1〜2日間開発に完全に従事することができます。
異常または正常のラベルが付いたデータレコードが1,000以上あります。
データセット
このトピックで説明するパイプラインは、22,544データレコードを含むシステムレベルの監視ログに基づいています。 これらのデータレコードのうち、9,711はシステムの異常を記録する。 次の図は、パイプラインで使用されるサンプルデータを示しています。 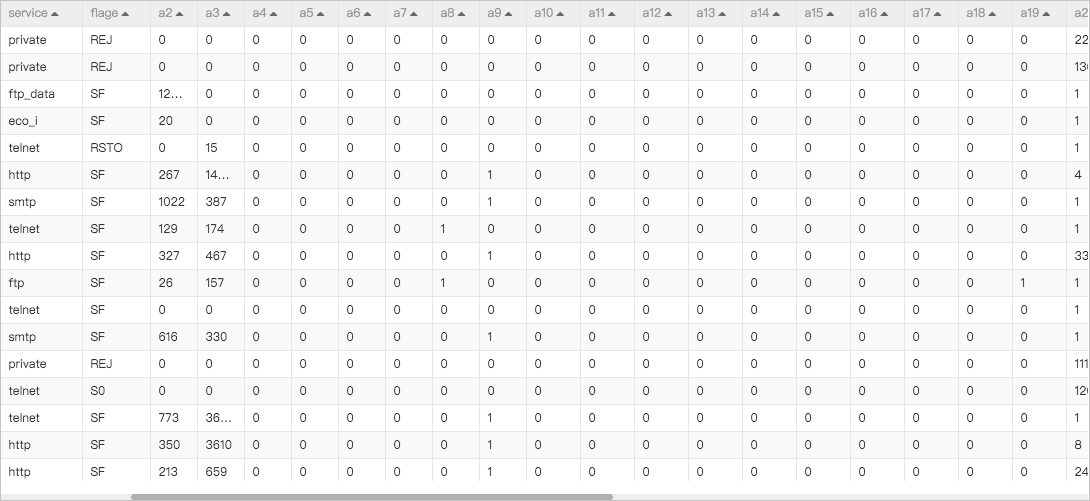
パラメーター | 説明 |
protocol_type | ネットワーク接続に使用されるプロトコル。 例: tcp、icmp、またはudp |
service | サービスプロトコル。 例: http、finger、pop、private、smtp |
フラゲ | 接続ステータス。 例: SF、RSTO、またはREJ。 |
a2 ~ a38 | システムメトリック。 |
class | ラベルフィールド。 有効な値: normalとanomaly。 データレコードのクラスの値が正常である場合、データレコードは正常なシステムイベントを記録します。 データレコードのクラスの値が異常である場合、データレコードはシステム異常を記録します。 |
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
[可視化モデリング (デザイナー)] ページの [プリセットテンプレート] タブで、異常な行動リスク管理テンプレートをクリックし、作成.
[パイプラインの作成] ダイアログボックスで、次のパラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインの実行中に生成された一時データとモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、[異常な動作リスク制御] パイプラインをダブルクリックしてパイプラインを開きます。
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、組み込みテンプレートに基づいてパイプラインを自動的に作成します。
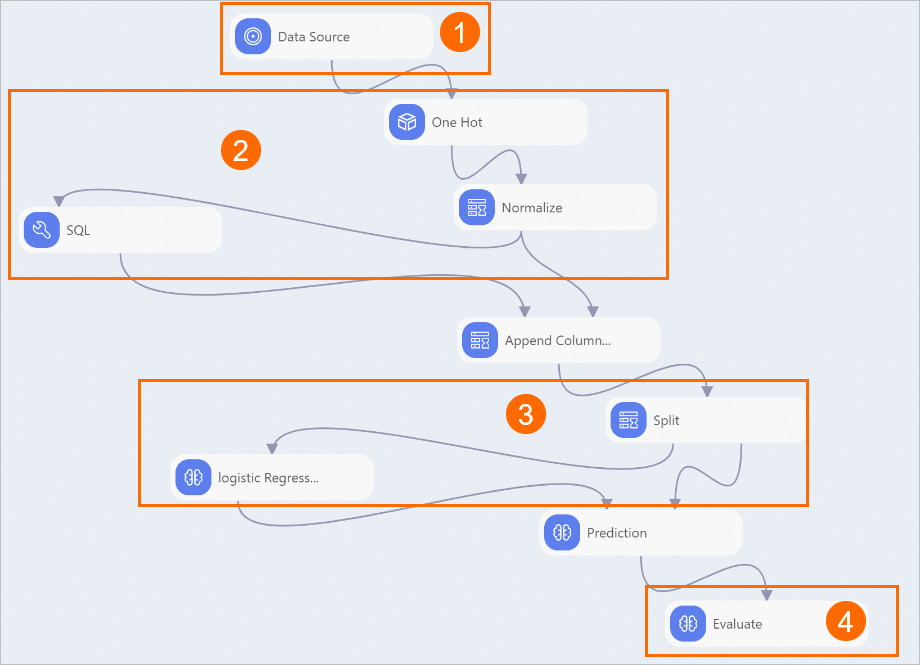
セクション
説明
①
このセクションに表示されるコンポーネントは、パイプラインで使用されるデータセットをインポートします。
②
このセクションに表示されるコンポーネントは、フィーチャエンジニアリングを実行します。
One Hot Encodingコンポーネントは、STRING型の特徴データを数値型のデータに変換します。
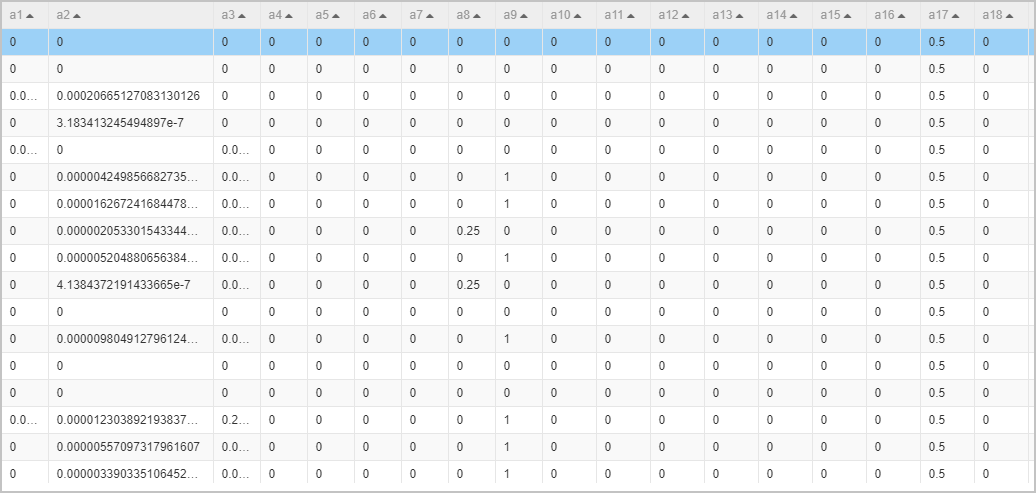
正規化コンポーネントは、次元の影響を排除するために、すべてのデータを0〜1の範囲内に制限します。 正規化されたデータを次の図に示します。
SQL Scriptコンポーネントは、SQL文を実行して、ソースデータのクラスの値を照会します。 SQL文は、classの値anomalを1に、classの値normalを0に変換します。 この例では、SQL Script-1コンポーネントは次のSQL文を実行します。
select (case class when 'anomaly' then 1 else 0 end) as class from ${t1};
③
このセクションに表示されるコンポーネントは、バイナリ分類アルゴリズムのロジスティック回帰を使用して、正常なシステムイベントとシステム異常に関するデータに基づいて監視モデルをトレーニングします。
④
バイナリ分類評価コンポーネントは、曲線下面積 (AUC) 、コルモゴロフ・スミルノフ (KS) 値、F1スコアなどの指標を使用してモデルの品質を評価します。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅にある [
 ] をクリックします。
] をクリックします。 パイプラインの実行が停止したら、[バイナリ分類評価] コンポーネントを右クリックします。 表示されるショートカットメニューで、[Visual Analysis] をクリックします。
[評価] ダイアログボックスで、[インデックスデータ] タブをクリックして、モデルの評価に使用されるインデックスを表示します。
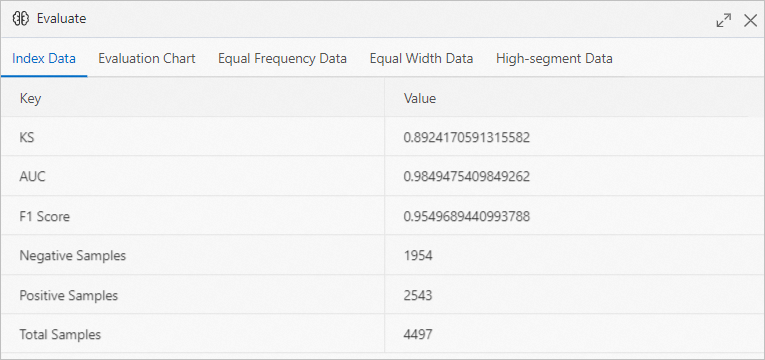 評価チャートでは、AUCの値が0.9よりも大きく、モデルの予測精度が90% よりも高いことを示しています。
評価チャートでは、AUCの値が0.9よりも大きく、モデルの予測精度が90% よりも高いことを示しています。