このトピックでは、テイクアウトプラットフォームからのレビューに基づいて世論リスク管理を実装する方法について説明します。
背景情報
多くの商人は、オンラインプラットフォームを使用して消費者から製品フィードバックを受け取ります。 消費者からのフィードバックには、肯定的および否定的なフィードバック、つまり賞賛と批判が含まれます。 商人は、消費者のフィードバックに基づいて、製品の品質が消費者のニーズを満たしているかどうかを知ることができます。 商人は、消費者レビューコンテンツを分析することによって消費者意見トレンドを取得し、そのトレンドを製品の研究開発のガイドとして使用できます。
オンラインレビュープラットフォームでは、毎日多数のレビューが提出されています。 伝統的に、商人は手動で世論を収集します。 この方法は非効率的であり、データ量が多い場合、世論に関する統計を正確に収集することができない。 したがって、商人は、世論の傾向を決定するために、世論に関する統計を自動的に収集するアプローチを必要とする。 Machine Learning Platform for AI (PAI) は、テキストのベクトル化と分類に基づいて開発された一連のアルゴリズムを提供します。 これらのアルゴリズムは、履歴ラベルを有する肯定的および否定的レビューに基づいて分類モデルを作成することができる。 モデルを使用して、新しいレビューの傾向を自動的に予測できます。 テイクアウトプラットフォームからの11,987ラベル付きレビューに基づいて開発された全体的なモデリングフレームワークは、Machine Learning Designerで事前設定されています。 このフレームワークは、約75% の精度で肯定的および否定的な世論の自動リスク管理を実装します。
Machine Learning Designerでプリセットされているパイプラインテンプレートを使用して、1〜2日以内に世論リスク管理のソリューションを開発できます。 次に、ソリューションを使用して、一度に多数のレビューを分析できます。 モデルの予測精度は、レビューの数に比例します。 このソリューションは、スパムの分類やニュースに対する肯定的および否定的な意見の分類などのテキスト分析に適用できます。
データセット
このトピックで説明するパイプラインは、テイクアウトプラットフォームから収集されたマスクされた実際のデータに基づいています。 次の表に、データのフィールドを示します。
項目 | データ型 | 説明 |
ラベル | DOUBLE | レビューが肯定的か否定的かを示します。 有効な値:
|
審査 | STRING | レビューの内容。 |
テイクアウトプラットフォームからのレビューに基づいて世論リスク管理を実装する
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
このタブで、[テイクアウェイレビューに基づくパブリックオピニオンリスク管理] テンプレートを見つけ、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、[テイクアウェイレビューに基づくパブリックオピニオンリスク管理] パイプラインをダブルクリックしてパイプラインを開きます。
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、組み込みテンプレートに基づいてパイプラインを自動的に作成します。
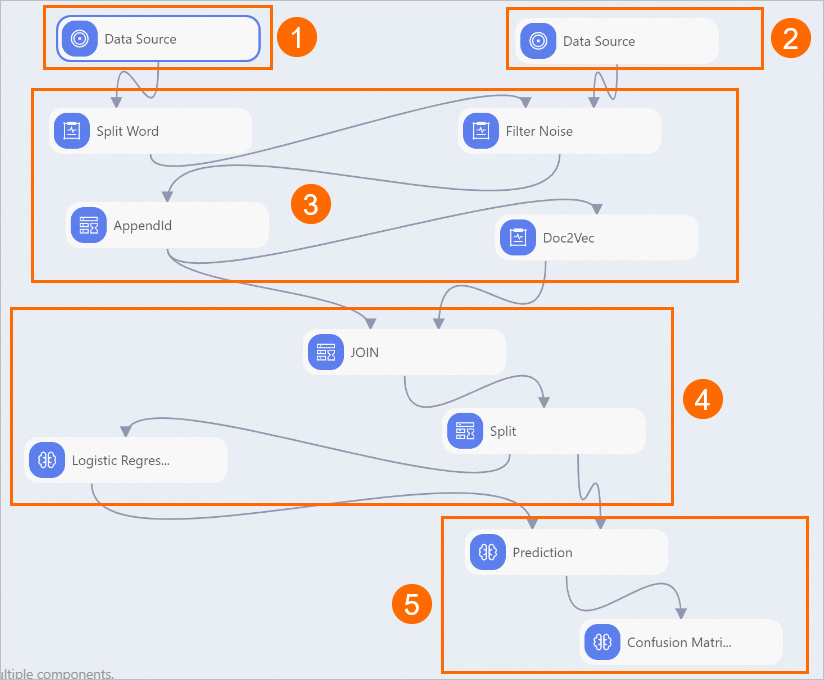
セクション
説明
①
このセクションに表示されるコンポーネントは、レビューデータをインポートします。
②
このセクションに表示されるコンポーネントは、ストップワードをインポートします。 ストップワードには、補助動詞と句読点が含まれます。 次の図に示すように、ストップワードテーブルを手動でアップロードする必要があります。

③
このセクションに表示されるコンポーネントは、テキストをベクトル化します。 Doc2Vec-1コンポーネントは、Doc2Vecアルゴリズムを使用して、各レビューを意味ベクトルに変換します。 各行はベクトルを表し、各ベクトルはレビューの意味を表します。 パイプラインの実行後、キャンバス上で [Doc2Vec] を右クリックし、 を選択します。 表示されるタブで、テキストベクトルテーブルを表示します。
④
このセクションに表示されるコンポーネントは、バイナリ分類モデルを生成します。 Split-1コンポーネントは、分割アルゴリズムを使用して、ベクトル化されたテキストをトレーニングデータセットと予測データセットに分割します。 次に、バイナリ分類のロジスティック回帰-1コンポーネントは、ロジスティック回帰アルゴリズムを使用して、トレーニングデータセットに基づいてバイナリ分類モデルをトレーニングします。 モデルは、レビューが肯定的であるか否定的であるかを判定できる。
⑤
このセクションに表示されるコンポーネントでは、コンフュージョンマトリックスを使用してモデルの品質を評価します。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅にある [
 ] をクリックします。
] をクリックします。 キャンバスで [Confusion Matrix] を右クリックし、[Visual Analysis] をクリックします。
[混乱マトリックス] セクションで、[統計] タブをクリックし、モデル統計を表示します。