このトピックでは、サービスをデプロイするときにトレース機能を有効にする方法について説明します。
背景情報
大規模言語モデル (LLM) 技術の普及に伴い、企業は LLM ベースのアプリケーションを構築する際に、予測不能な出力、複雑なコールチェーン、パフォーマンスボトルネックの特定困難、詳細な可観測性の欠如といった多くの課題に直面しています。これらの課題に対処するため、Elastic Algorithm Service (EAS) はトレーシングをサポートしています。
トレーシングの主な目的は、アプリケーションの可観測性を向上させ、LLM アプリケーションの評価を支援することです。トレーシングを有効にすると、EAS は Alibaba Cloud の Application Real-Time Monitoring Service (ARMS) と自動的に統合され、以下の機能を提供します。
呼び出しチェーンの可視化: 明確な呼び出しチェーンログを提供し、リクエストの完全なパスを可視化するのに役立ちます。
パフォーマンスモニタリング: 応答時間、トークン消費量、エラー数などの主要なパフォーマンス指標を追跡し、パフォーマンスボトルネックを迅速に特定するのに役立ちます。
問題の特定と根本原因の分析: Trace ID を使用して問題を迅速に特定し、コンテキスト情報を使用して根本原因の分析を実行します。
評価ツール: 呼び出しチェーンデータに基づく評価ツールを提供して、LLM アプリケーション出力の正確性と信頼性を検証します。
用語
トレース
トレースは、分散システムにおけるトランザクションまたはリクエストの完全な実行パスです。リクエストが異なるサービスやモジュールをどのように流れるかを記録します。トレースは複数のスパンで構成されます。トレースは、リクエストフローを可視化し、パフォーマンスボトルネックやエラーの原因を迅速に特定するのに役立ちます。TraceID はトレースの一意の識別子です。TraceID を使用して、特定の呼び出しの詳細とログをクエリできます。
スパン
スパンはトレースの基本単位です。特定の操作を表し、その操作の名前、開始時刻、終了時刻などの詳細を記録します。
Python プローブ
Python プローブは、Python アプリケーションから呼び出しチェーンデータとパフォーマンスメトリックを自動的に収集するツールです。EAS サービスをデプロイするときに、Python プローブをインストールしてトレースを有効にできます。
評価
評価は、複数のディメンションにわたってユーザーの質問に応答して LLM アプリケーションによって生成された回答を評価するプロセスです。特定の評価ディメンション名を確認するには、ビジネス マネージャーにお問い合わせください。
制限事項
この機能は、LangChain、LlamaIndex、または DashScope で開発された Python ベースの LLM アプリケーションのみをサポートします。
前提条件
ARMS Application Monitoring を有効化していること。詳細については、「ARMS の有効化」をご参照ください。
LangStudio を有効化していること。詳細については、「PAI サービスアカウントの承認」をご参照ください。
Resource Access Management (RAM) ユーザーまたは RAM ロールを使用する場合、この機能を使用する前に、ユーザーまたはロールに
AliyunPAILLMTraceFullAccess権限を付与する必要があります。詳細については、「RAM ロールへの権限付与」および「RAM ユーザーへの権限付与」をご参照ください。
ステップ 1: 準備
サービスデプロイから呼び出し、トレース表示までの完全なウォークスルーを提供するために、このトピックでは簡単な予測サービスを例として使用します。
このコードは、Dashscope API に基づいて開発された簡単な予測サービス用です。Flask フレームワークを使用して Web サービスを構築し、Dashscope の Generation.call メソッドを呼び出してテキスト生成を実行します。初めて Dashscope を使用する前に、アクティベーションプロセスを完了し、API キーを取得する必要があります。詳細については、「初めて Tongyi Qianwen API を呼び出す」をご参照ください。次に、サービスをデプロイするときに、API サービスへの適切なアクセスを確保するために、DASHSCOPE_API_KEY を環境変数として設定する必要があります。次のコードは、app.py ファイルの例を示しています:
import os
import json
import flask
import dashscope
app = flask.Flask(__name__)
def run_query(query):
"""クエリを実行します。"""
response = dashscope.Generation.call(
api_key=os.getenv('DASHSCOPE_API_KEY'),
model="qwen-plus",
messages=[
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': query}
],
result_format='message'
)
return response
@app.route('/api/trace_demo', methods=['POST'])
def query():
"""
Post データ例:
{
"query": "capital of china"
}
"""
data = flask.request.get_data("utf-8")
query = json.loads(data).get('query', '')
response = run_query(query)
return response.output.choices[0].message.content
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8000)
ステップ 2: トレースを有効にする
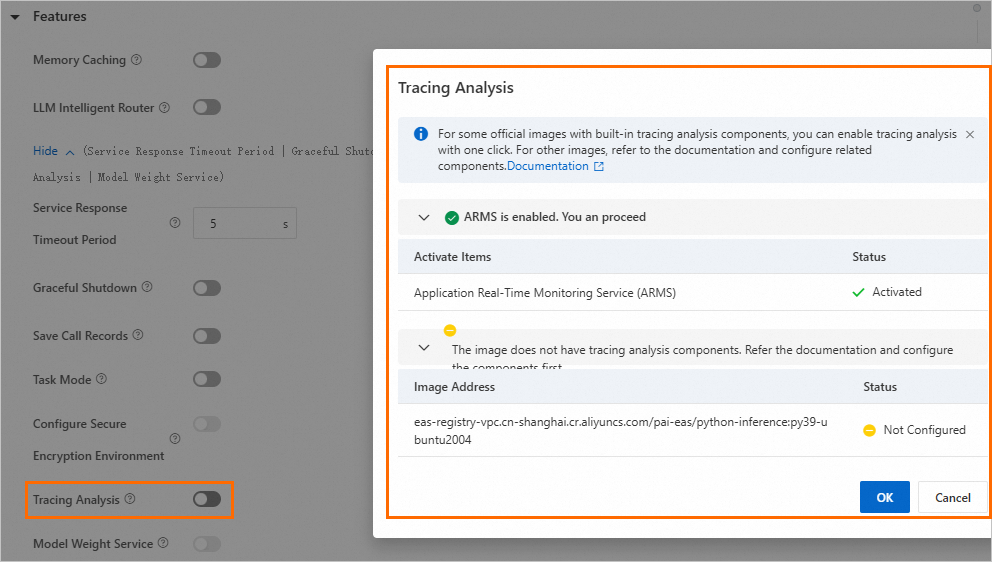
EAS サービスをデプロイする際、[サービス機能] セクションの [トレース] スイッチをオンにすることで、トレースを有効にできます。プロンプトに基づいて、使用中のイメージに組み込みのトレースコンポーネントが含まれているかを確認します。必要に応じて、コマンドを構成してプローブをインストールし、ARMS Python プローブを使用してアプリケーションを起動します。構成の詳細については、「Python プローブを手動でインストールする」をご参照ください。
組み込みのトレースコンポーネントを含むイメージを使用する場合: [トレース] スイッチをオンにすると、ワンクリックでトレースが有効になります。追加のパラメーター構成は必要ありません。
組み込みのトレースコンポーネントがないイメージを使用する場合:[Tracing] スイッチをオンにして、プロンプトに従ってサードパーティライブラリと起動コマンドを設定します。
パラメーター
説明
起動コマンド
aliyun-bootstrap -a install && aliyun-instrument python app.pyを追加します。このコマンドは、プローブをインストールし、ARMS Python プローブでアプリケーションを起動します。app.py は、予測サービスを提供するためにイメージで設定されたメインファイルです。また、Python Package Index (PyPI) リポジトリからプローブインストーラーをダウンロードするために、サードパーティライブラリの設定に aliyun-bootstrap を追加する必要があります。サードパーティライブラリ設定
aliyun-bootstrapを追加して、PyPI リポジトリからプローブインストーラーをダウンロードします。
このトピックでは、トレースコンポーネントが組み込まれていないイメージとサンプルコードを例として使用します。カスタム EAS サービスをデプロイするための主要なパラメーターを次の表に示します。具体的な手順については、「コンソールでサービスをデプロイする」をご参照ください。サービスがデプロイされた後、次の操作を実行できます:
Elastic Algorithm Service (EAS) ページでサービスのデプロイステータスを表示します。
ARMS コンソールのアプリケーションリストページで登録済みのアプリケーションを表示します。アプリケーション名は EAS サービス名と同じです。
パラメーター | 説明 | |
環境コンテキスト | デプロイ方法 | [イメージのデプロイメント] を選択します。 |
イメージ構成 | このトピックでは、デフォルトのイメージ を使用します。 [イメージ URL] タブで準備したカスタムイメージを入力することもできます。 | |
直接マウント | サンプルコードファイルはイメージに統合されていないため、サービスインスタンスにマウントする必要があります。Object Storage Service (OSS) からのマウントを例にとります。[OSS] をクリックし、次のパラメーターを設定します:
カスタムイメージを使用し、予測サービスのメインファイルをイメージにすでに設定している場合は、この設定をスキップできます。 | |
起動コマンド | このトピックでは、コマンドを | |
環境変数 | サンプルコードは Dashscope API を呼び出すため、[追加] をクリックして次の環境変数を設定します:
| |
サードパーティライブラリ設定 | サードパーティライブラリを | |
サービス登録 | VPC | トレース機能を使用するには、VPC を設定する必要があります。リージョンで [VPC]、[VSwitch]、および [セキュリティグループ] を選択します。 デフォルトでは、EAS サービスはインターネットにアクセスできません。Dashscope API を呼び出す必要があるサンプルコードを実行するには、EAS サービス用にインターネットアクセスを持つ VPC を設定する必要があります。これにより、サービスがインターネットにアクセスできるようになります。具体的な手順については、「シナリオ 1: EAS サービスにインターネットへのアクセスを許可する」をご参照ください。 |
VSwitch | ||
セキュリティグループ名 | ||
サービス機能 | トレーシング | [トレーシング] スイッチをオンにし、 [環境コンテキスト] セクションでサードパーティライブラリと起動コマンドを設定します。 |
ステップ 3: トレースの表示
トレースに基づく評価ツールは、開発者が LLM アプリケーションの出力の正確性と信頼性を検証するのに役立ちます。次のステップを実行します:
EAS サービスの呼び出し
このトピックでは、オンラインデバッグを例として使用します。API を使用して EAS サービスを呼び出すこともできます。詳細については、「API 呼び出し」をご参照ください。
[Elastic Algorithm Service (EAS)] ページで、ターゲットサービスを見つけ、[操作] 列の
 > [オンラインデバッグ] をクリックします。
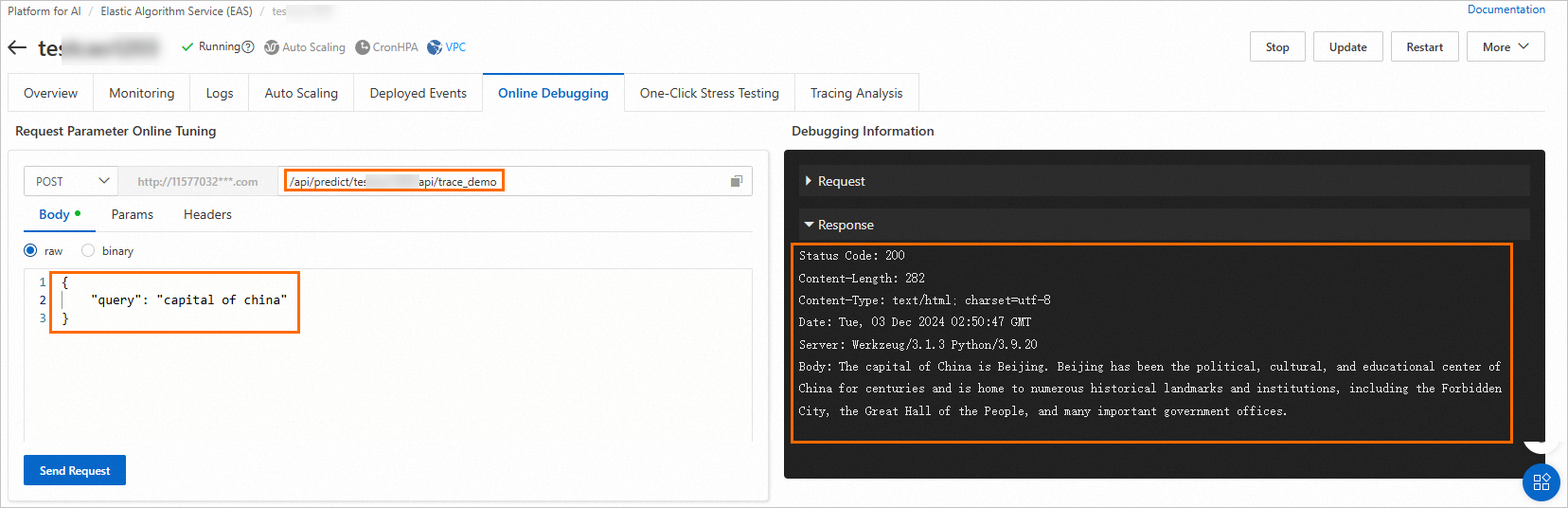
> [オンラインデバッグ] をクリックします。[本文] タブで、定義した予測サービスに基づいて指定されたアドレスにリクエストデータを送信します。
このトピックでは、サンプルの app.py ファイルで定義されたサービスインターフェイスを使用します。次の図に結果の例を示します:
トレース情報の表示
デフォルトでは、トレースデータは生成されてから 30 日間保存されます。保存期間を延長するには、ARMS チームに連絡してカスタム設定を依頼してください。
トレーシング タブの トレースクエリ タブに切り替えて、トレース情報を表示します。
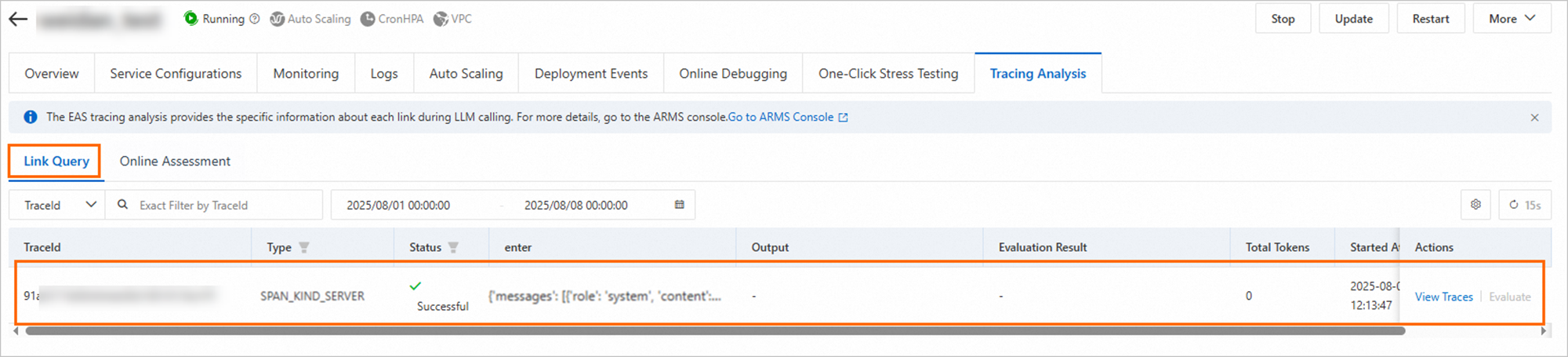
ターゲットトレースを見つけ、[操作] 列の [トレースの表示] をクリックして [トレース詳細] ページに移動します。
このページのトレースデータにより、サービスの入力、出力、および関連するログ情報を表示できます。
注:RAM ユーザーまたは RAM ロールを使用する場合、この機能を使用するには
AliyunARMSReadOnlyAccess権限を付与する必要があります。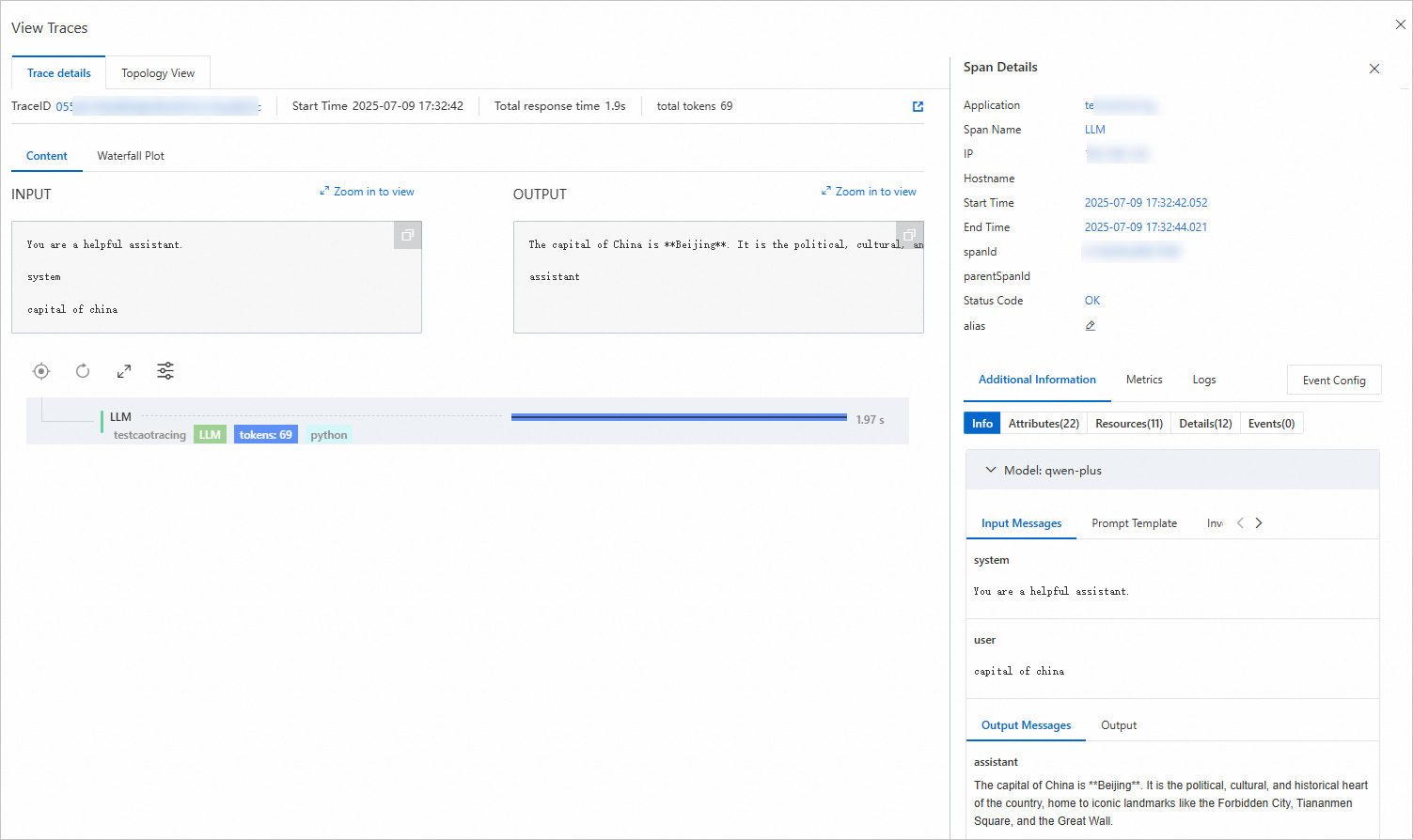
トレース詳細を共有するには、共有アイコン
 をクリックして、ワンタイムアドレスを生成します。
をクリックして、ワンタイムアドレスを生成します。注:RAM ユーザーまたは RAM ロールを使用する場合、この機能を使用する前に
cms:CreateTicket権限を付与する必要があります。
ステップ 4: アプリケーションのパフォーマンスを評価する
EAS は、トレースに基づいて LLM アプリケーションの出力の正確性と信頼性を検証するための評価ツールを提供します。次の 2 つの評価メソッドがサポートされています:
方法 1: 単一トレースの評価: EAS サービスから評価するトレースを手動で選択します。この方法は、特定のトレースをデバッグし、そのロジックが正しく、パフォーマンスが期待どおりであることを確認するための開発またはテストフェーズに適しています。
方法 2: オンラインでのバッチトレース評価: 実行中の EAS サービスによって生成されたサンプリングされたトレースを定期的に評価します。この方法は、大規模なパフォーマンステストや機能検証シナリオに適しており、システム全体のステータスとトレース連携の有効性を理解するのに役立ちます。
デフォルトでは、トレースデータは生成されてから 30 日間保存されます。保存期間を延長するには、ARMS チームに連絡してカスタム設定を依頼してください。
方法 1: 単一のトレースを評価する
[トレース] タブの [トレースクエリ] タブで、ターゲットトレースを見つけ、[操作] 列の [評価] をクリックします。次に、[評価] 設定パネルで、次のパラメーターを設定します。
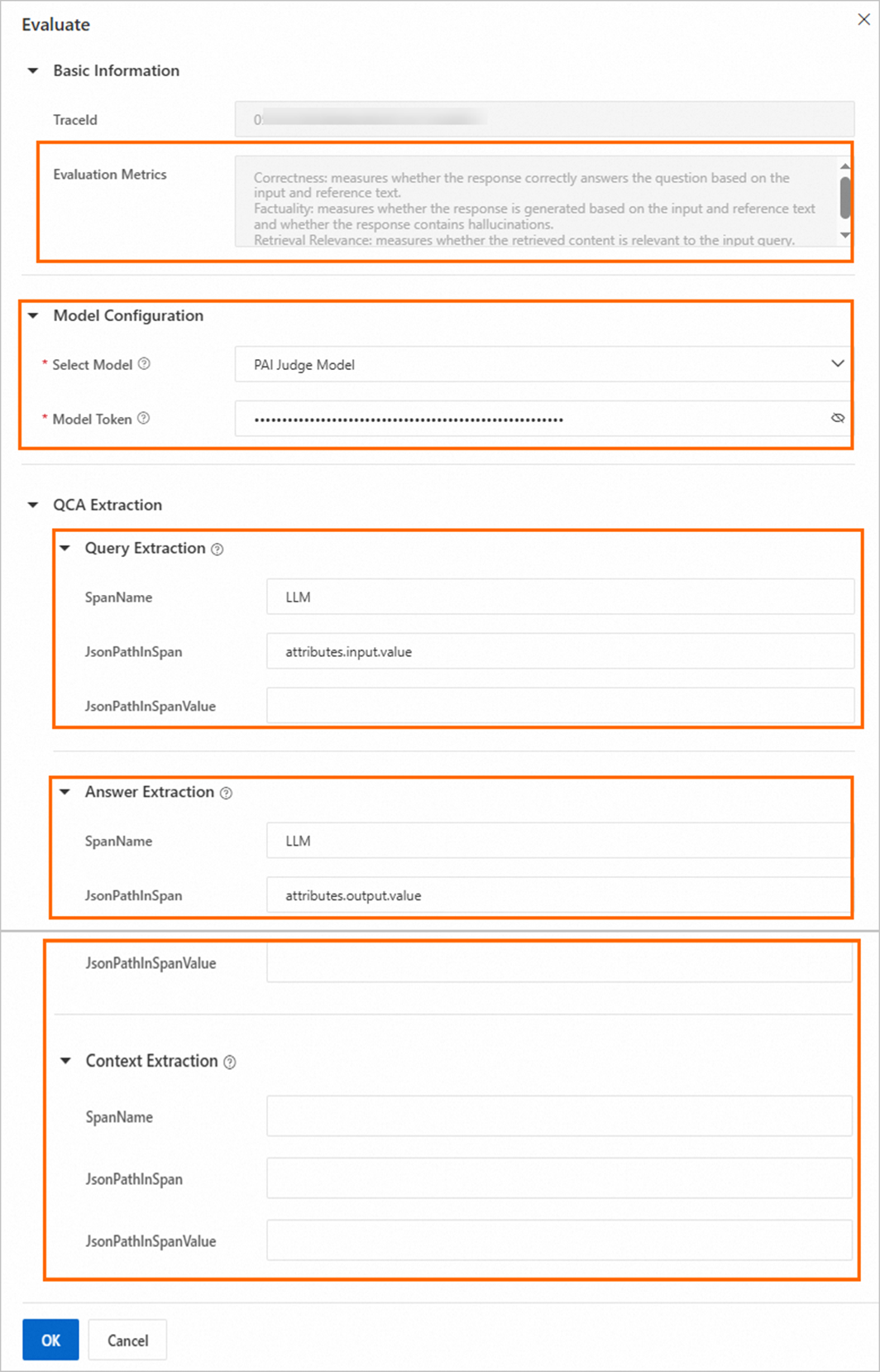
評価メトリック: これは固定の構成であり、変更できません。評価は次のディメンションに基づいて実行されます。
評価メトリック
説明
正確性
入力と参照テキストに基づいて、回答が質問に正しく対処しているかどうかを判断します。
忠実度
回答が入力と参照テキストに基づいて生成されているか、幻覚が含まれているかを判断します。
検索の関連性
取得した結果が入力された質問に関連しているかどうかを判断します。次の 4 つのメトリックが含まれます:
nDCG: 正規化減損累積利得
ヒット率
Precision@K
MRR: 平均逆順位
モデル設定: トレースの評価に使用される大規模言語モデル (LLM) です。初期設定後、この設定は後続の評価のために自動的にバックフィルされます。
パラメーター
説明
モデル選択
次の 2 つのモデルがサポートされています:
PAI Judge モデル
qwen-max (Model Studio モデル)
説明Model Studio モデルを使用するには、EAS のインターネット接続を設定する必要があります。
Model Studio モデルの呼び出しは別途請求されます。詳細については、「課金」をご参照ください。
モデルトークン
選択したモデルのトークンを入力します:
Judge モデル: Judge モデル ページに移動し、PAI Judge モデルを有効化してトークンを取得します。
qwen-max: Model Studio の qwen-max モデルのトークンを取得する方法については、「初めて Tongyi Qianwen API を呼び出す」をご参照ください。
抽出設定: [クエリ抽出設定]、[回答抽出設定]、および [コンテキスト抽出設定] セクションで、対応するコンテンツを抽出するには、次の表のパラメーターを設定します:
クエリ抽出設定: ユーザーのクエリコンテンツ (入力) を抽出します。
回答抽出設定: システムが生成した回答 (出力) を抽出します。
コンテキスト抽出設定: システムに提供されたテキストまたは背景情報 (ドキュメント) を抽出します。
パラメーター
説明
SpanName
SpanName に一致するスパンを検索します。
JsonPathInSpan
フォーマットは a.b.c です。このパラメーターは空にできません。一致したスパンの指定された要素から値を抽出します。
JsonPathInSpanValue
フォーマットは a.b.c です。このパラメーターは空にできます。JsonPathInSpan に対応する要素が見つかった後、要素のコンテンツが JSON 文字列の場合、JsonPathInSpanValue を使用して対応する値を抽出します。
[操作] 列の [トレースの表示] をクリックして、[トレース詳細] ページから設定内容を取得できます。次の表に設定例を示します:
抽出設定
取得方法
値の例
クエリ抽出設定
このトピックでは、JsonPathInSpanValue に値がない例を示します:
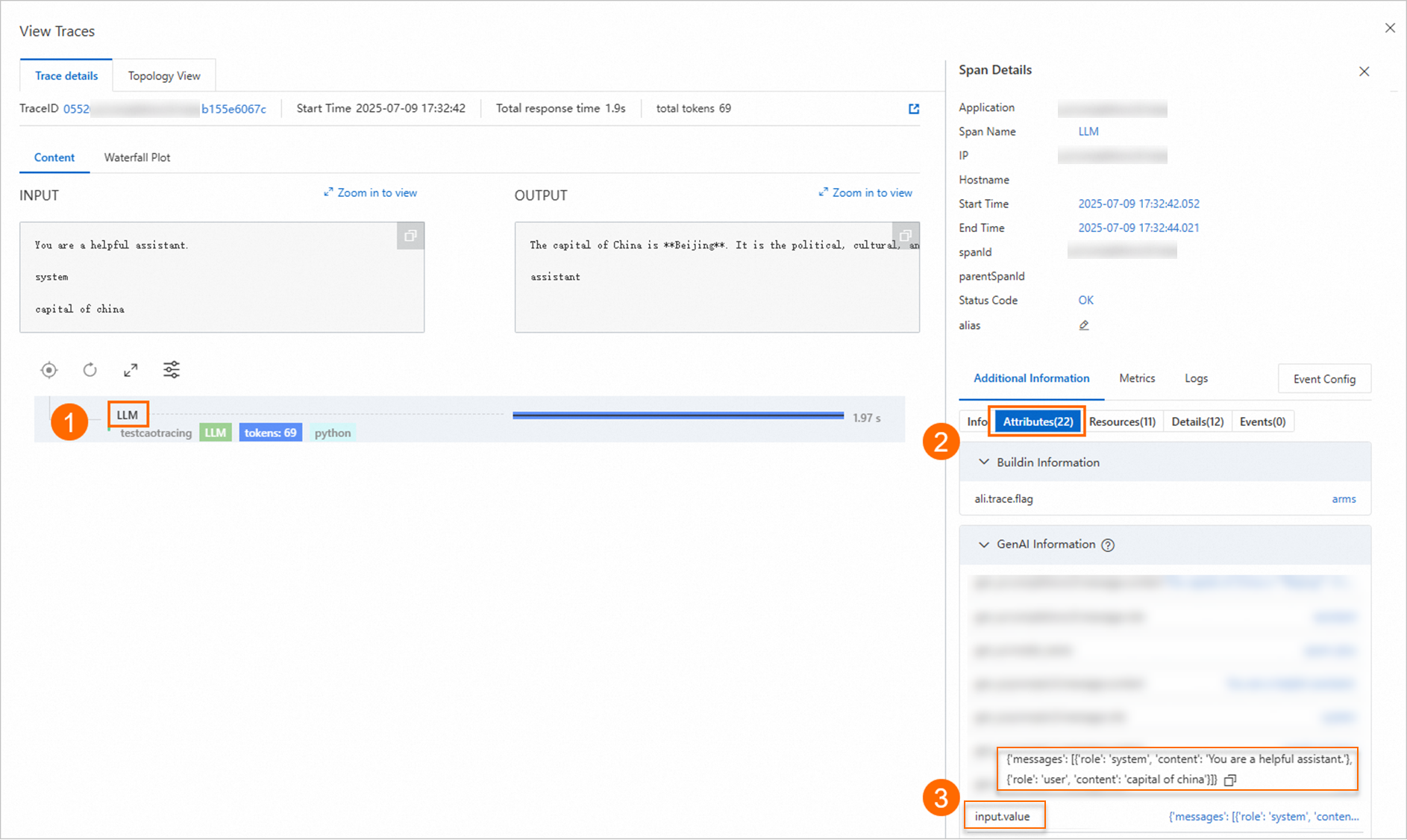
JsonPathInSpanValue に値がある例については、次の図をご参照ください。
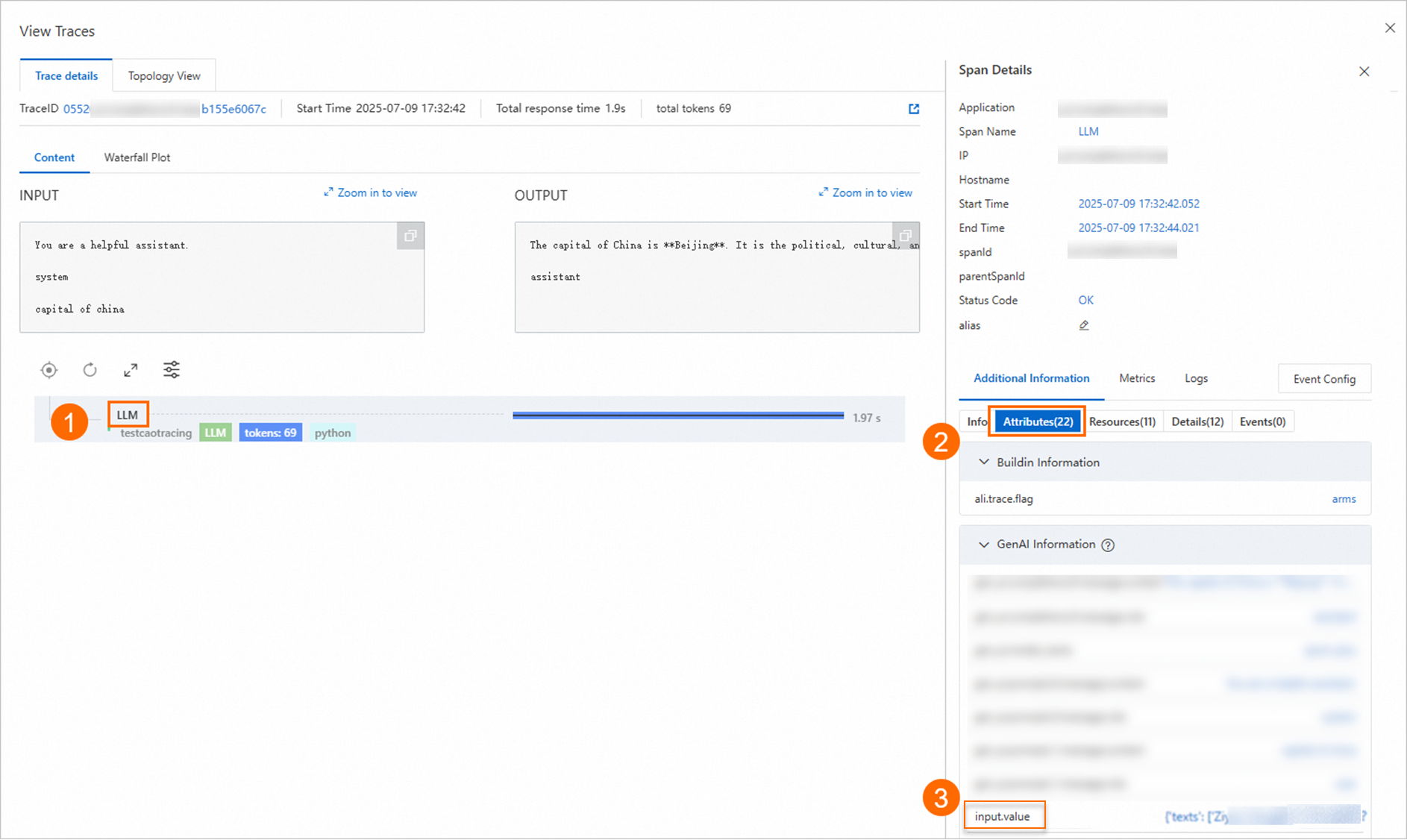
JsonPathInSpanValue に値がない
SpanName: LLM
JsonPathInSpan: attributes.input.value
JsonPathInSpanValue: JsonPathInSpan 要素のコンテンツは JSON 文字列ではないため、このパラメーターは空です。
JsonPathInSpanValue に値がある
SpanName: LLM
JsonPathInSpan:
attributes.input.valueJsonPathInSpanValue: JsonPathInSpan 要素のコンテンツは JSON 文字列であるため、ここに
text[0]を入力します。
回答抽出設定
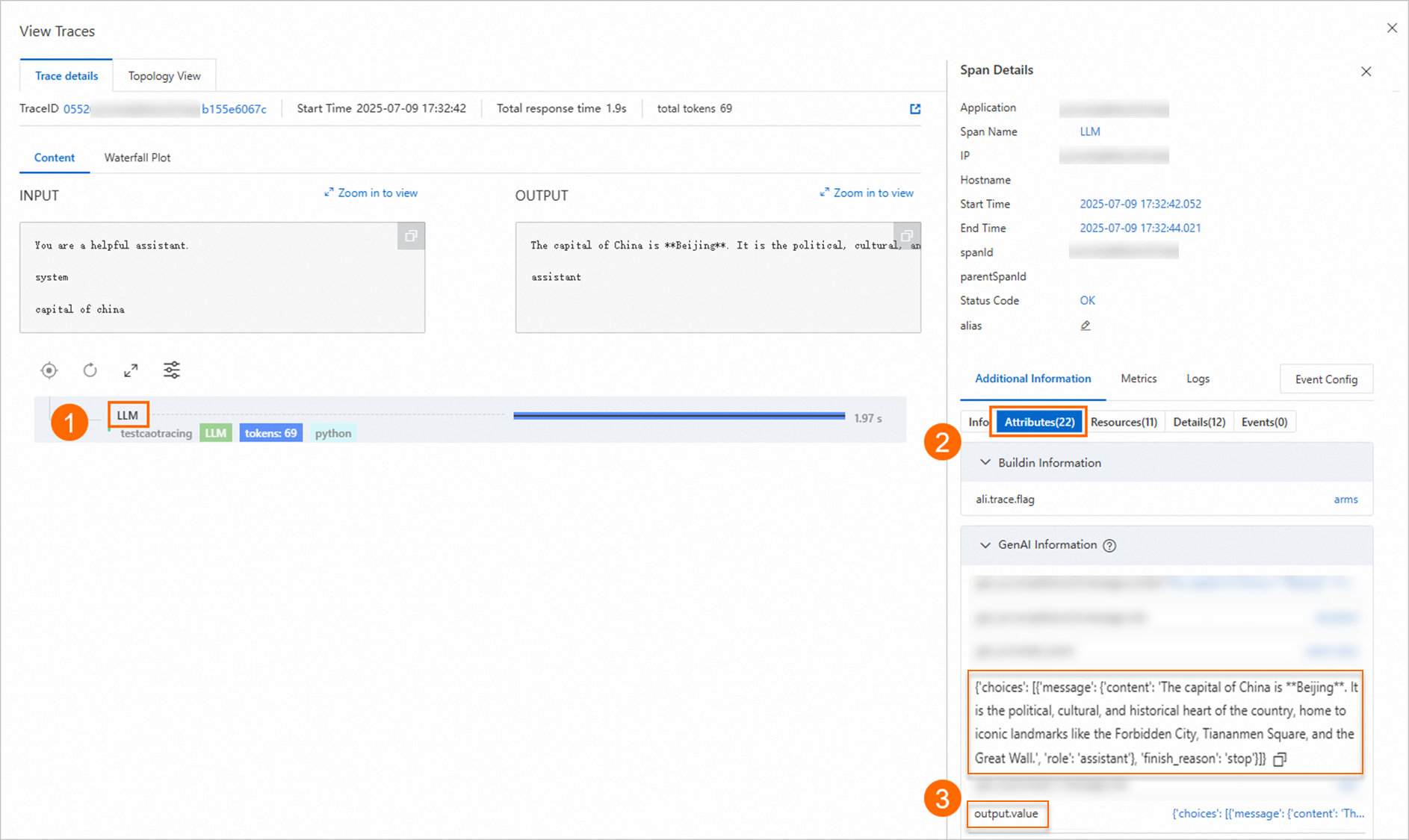
SpanName: LLM
JsonPathInSpan:
attributes.output.valueJsonPathInSpanValue: このパラメーターは空です。
コンテキスト抽出設定
このトピックのサンプルサービスには、コンテキスト抽出設定は含まれていません。コンテキスト抽出設定の例については、次の図をご参照ください:
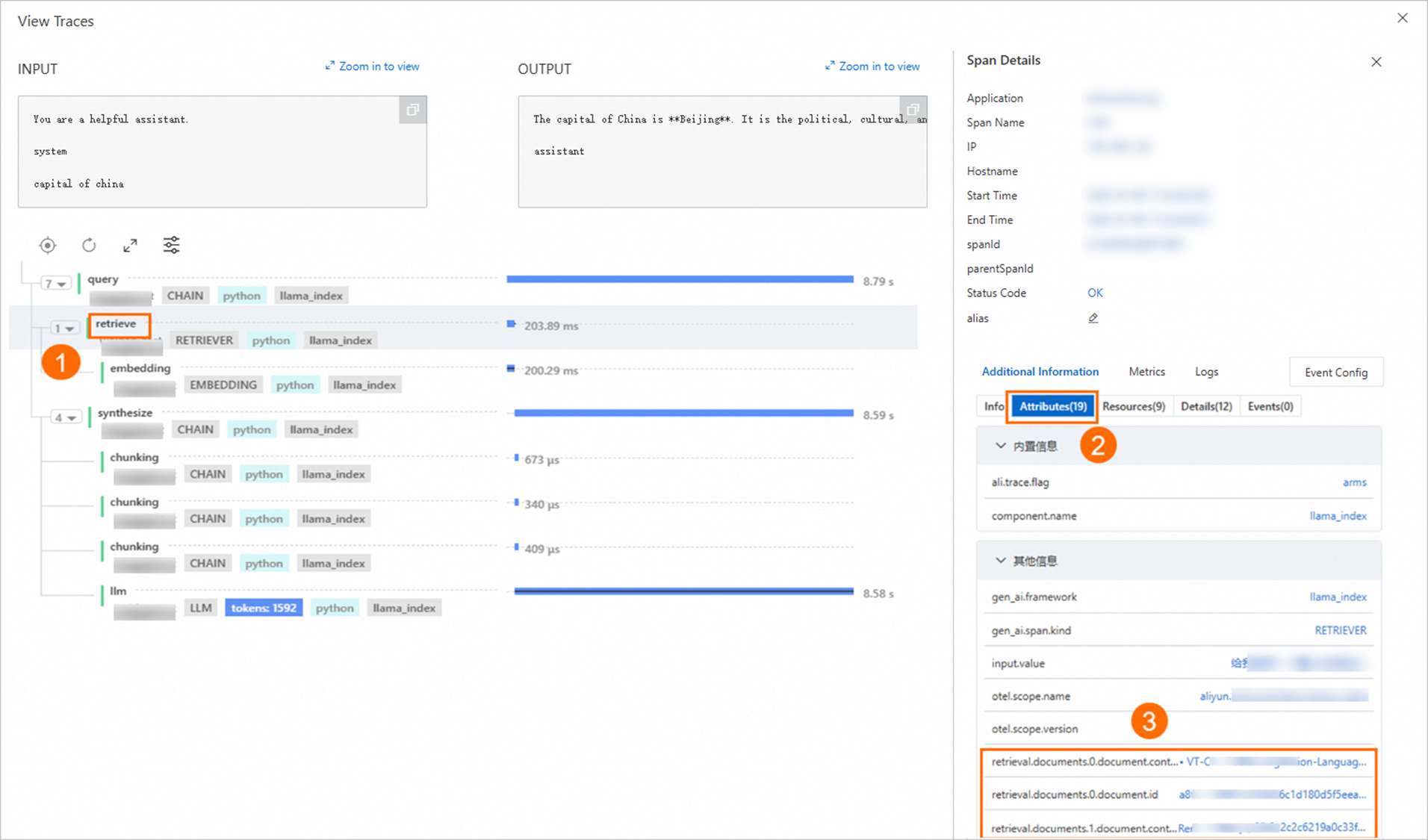
SpanName: retrieve
JsonPathInSpan:
attributes.retrieval.documents[*].document.content重要コンテキスト設定のみがアスタリスク (*) の使用をサポートします。
JsonPathInSpanValue: JsonPathInSpan 要素のコンテンツは JSON 文字列ではないため、このパラメーターは空です。
パラメーターを構成した後、[OK] をクリックします。
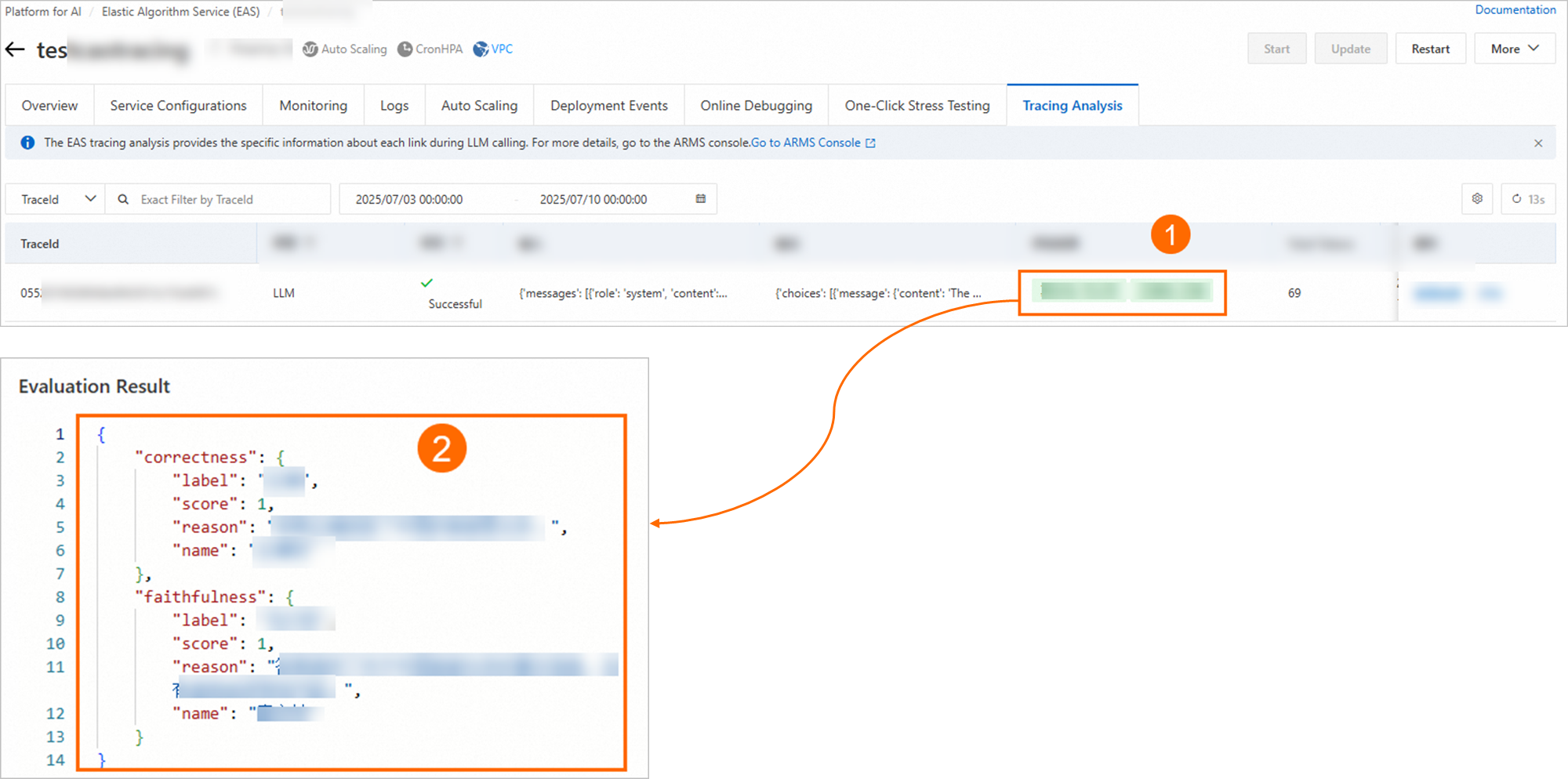
次の図に示すように、[評価結果] 列に結果が表示されたら、評価は成功です。評価結果をクリックして詳細を表示できます。
方法 2: オンラインでトレースをバッチ評価する
[トレース] タブの [オンライン評価] タブで、[評価の作成] をクリックします。
[評価タスクの作成] ページで、次のパラメーターを設定し、[OK] をクリックします。
パラメーター
説明
基本設定
タスク名
インターフェイスのプロンプトに基づいてカスタムタスク名を入力します。
評価設定
評価メトリック
これは固定の構成であり、変更できません。評価は次のディメンションに基づいて実行されます:
正しさ: 入力と参照テキストに基づいて、回答が質問に正しく対処しているかどうかを判断します。
忠実度: 回答が入力と参照テキストに基づいて生成されているか、幻覚が含まれているかを判断します。
取得関連性: 取得したコンテンツが入力された質問に関連しているかどうかを判断します。次の 4 つのメトリックが含まれます:
nDCG: 正規化減損累積利得
ヒット率
Precision@K
MRR: 平均逆順位
モデル選択
次の 2 つのモデルがサポートされています:
PAI Judge モデル
qwen-max (Model Studio モデル)
説明Model Studio モデルを使用するには、EAS のインターネット接続を設定する必要があります。
Model Studio モデルの呼び出しは別途請求されます。詳細については、「課金」をご参照ください。
モデルトークン
選択したモデルのトークンを入力します:
Judge モデル: Judge モデル ページに移動し、PAI Judge モデルを有効化してトークンを取得します。
qwen-max: Model Studio の qwen-max モデルのトークンを取得する方法については、「初めて Tongyi Qianwen API を呼び出す」をご参照ください。
サンプリング開始時刻と終了時刻
サンプリングの開始日と終了日を選択します。
サンプリングポリシー
次の 2 つのサンプリングポリシーがサポートされています:
時間枠ベースのサンプリング:x 分ごとに 1 つのトレースをサンプリングします。
確率ベースのサンプリング:指定された割合のトレースをランダムにサンプリングします。
QCA 抽出設定: トレースデータは JSON 形式の文字列です。QCA 抽出設定は、JSON 文字列内の QCA のパスを指定します。パスに対応する値が QCA の具体的な内容です。
クエリ抽出設定
クエリ抽出設定: ユーザーのクエリコンテンツ (入力) を抽出します。
回答抽出設定: システムが生成した回答 (出力) を抽出します。
コンテキスト抽出設定: システムに提供されたテキストまたは背景情報 (ドキュメント) を抽出します。
SpanName、JsonPathInSpan、および JsonPathInSpanValue パラメーターを設定して、対応するコンテンツを抽出します。これらのパラメーターの設定方法の詳細については、「抽出設定」をご参照ください。
回答抽出設定
コンテキスト抽出設定
評価タスクの[ステータス]が[完了]になると、すべてのサンプリング評価操作が完了し、タスクは新しい評価結果を生成しなくなります。
評価が完了すると、評価タスクの[評価結果]列で結果を表示できます。また、タスク名をクリックして詳細を表示することもできます。
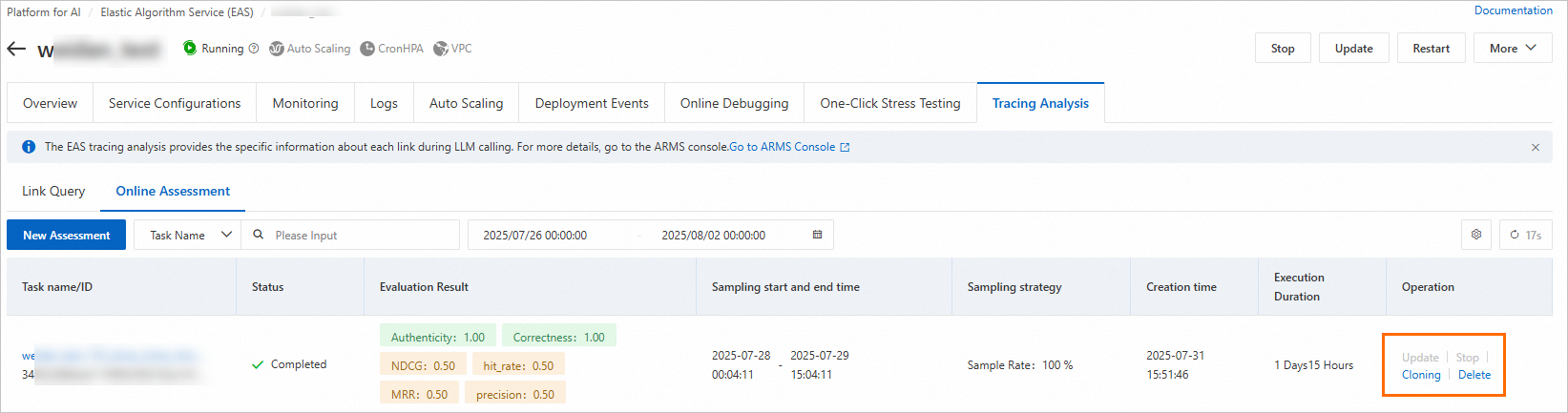
評価結果の表示: システムは、成功したトレースに基づいて評価結果の平均値を動的に計算して表示します。値が 1 に近いほど、関連性が高いことを示します。
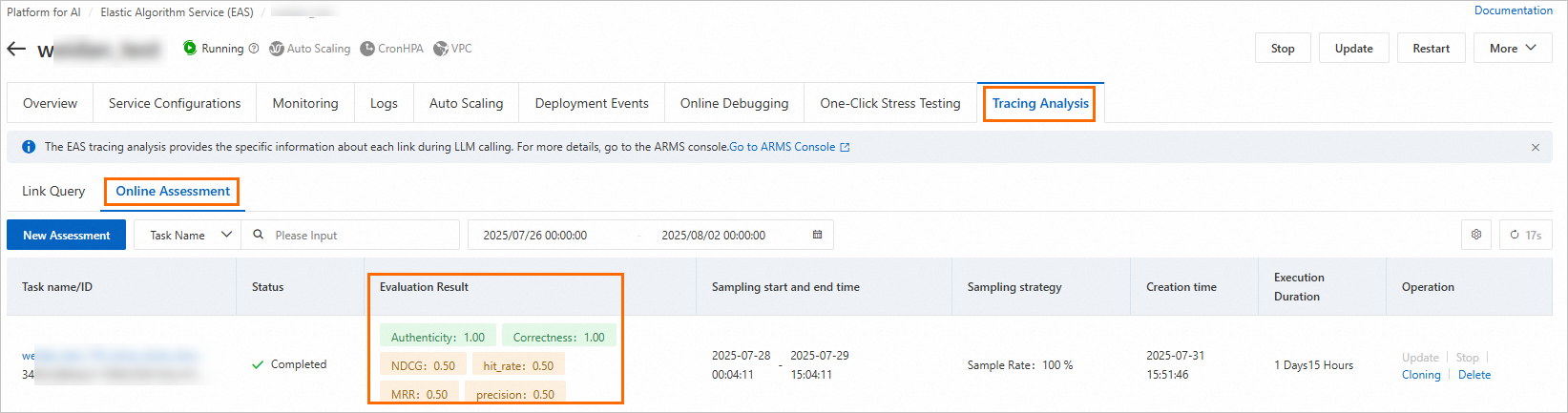
評価詳細の表示:
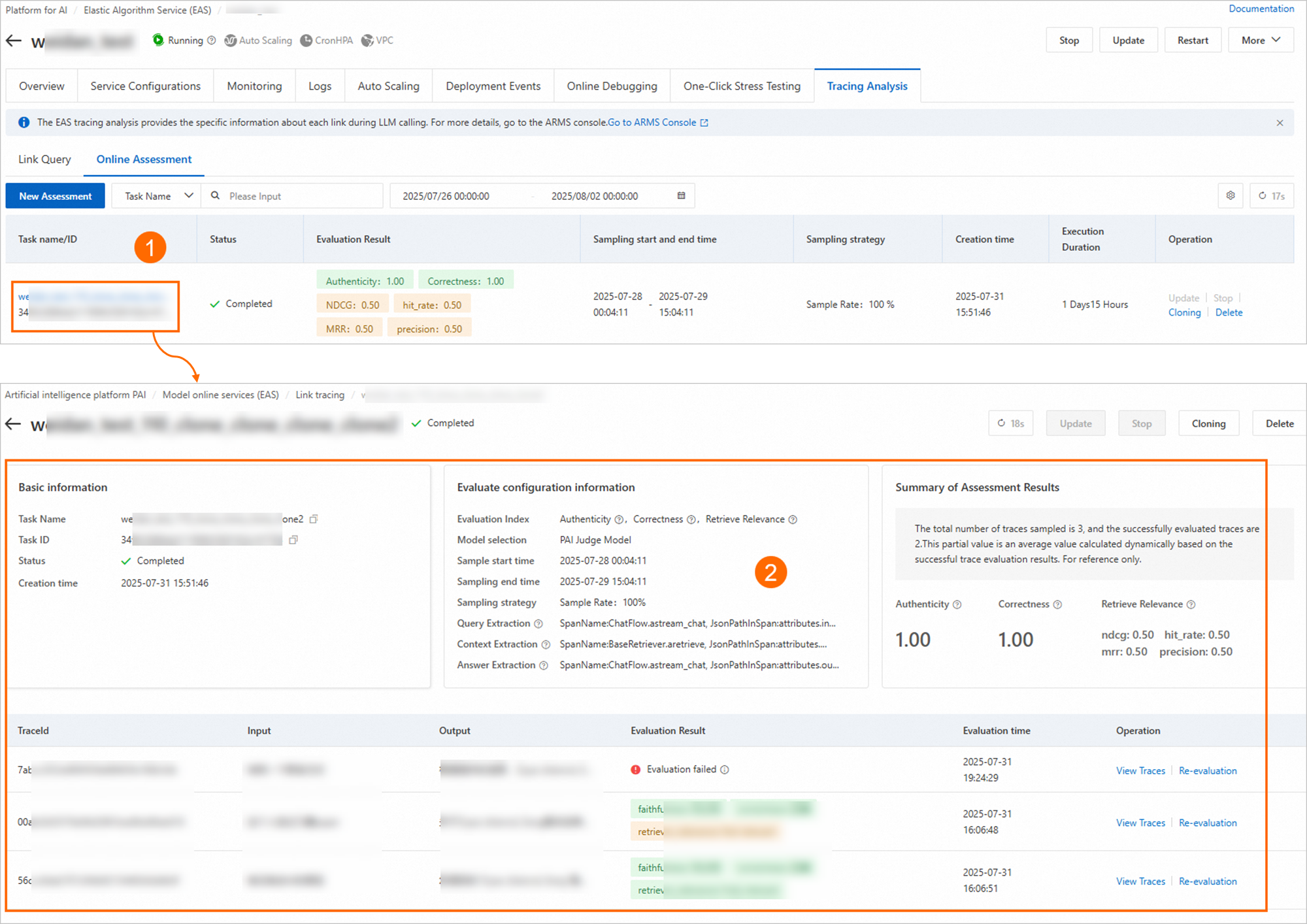
その後、評価タスクの更新、停止、削除、クローンなどの管理操作を実行できます。クローンは、タスク設定をコピーして新しい評価タスクを作成するだけです。