このトピックでは、北京で1年間収集されたデータの分析に基づいて、かすんでいる天気を予測するモデルを構築する方法について説明します。 モデルは、曇った天候を引き起こす可能性が最も高い汚染物質を見つけるために使用することができます。 汚染物質は、PM 2.5の濃度に基づいて測定される。
データセット
次のサンプル実験では、2016中に北京で1時間ごとに収集される大気質データが使用されます。 次の表に、大気質データのフィールドを示します。
項目 | データ型 | 説明 |
time | STRING | 日付。 このフィールドはその日に正確です。 |
hour | STRING | データが収集された時間。 |
pm2 | STRING | PM 2.5インデックス。 |
pm10 | STRING | PM 10インデックス。 |
so2 | STRING | 二酸化硫黄指数。 |
co | STRING | 一酸化炭素指数。 |
no2 | STRING | 二酸化窒素指数。 |
ぼんやりとした天気を予測するモデルを構築する
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
では、大気質予測[プリセットテンプレート] タブのセクションで、作成.
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、作成した大気質予測テンプレートを開きます。
次の図に示すように、キャンバス上のパイプラインのコンポーネントを表示します。 システムは、プリセットテンプレートに基づいてパイプラインを自動的に作成します。
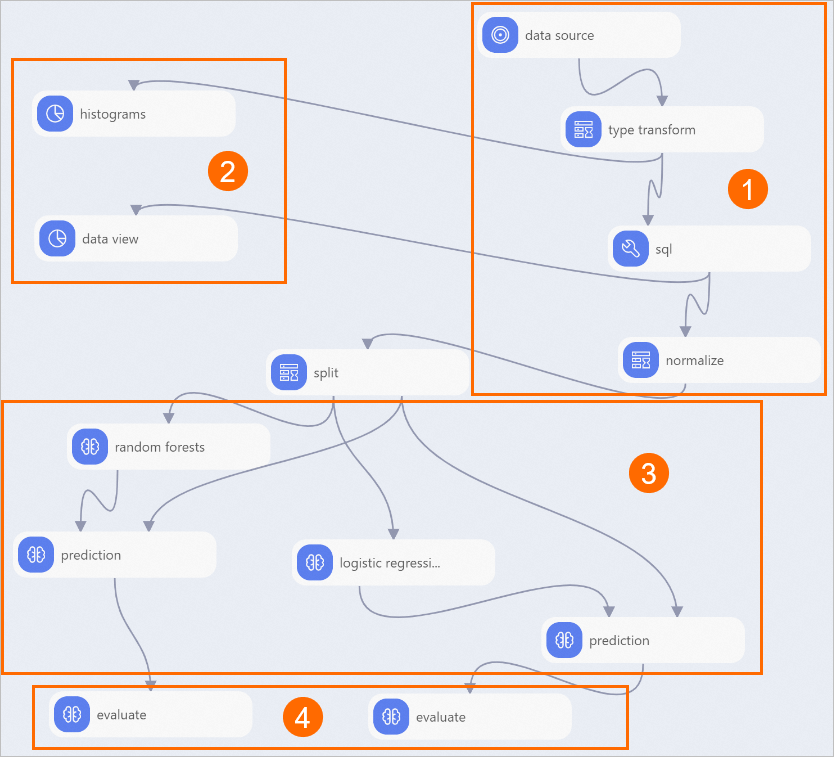
セクション
説明
①
このセクションに表示されるコンポーネントは、データを読み取り、前処理します。
data sourceコンポーネントは、ソースデータを読み取ります。
型変換コンポーネントは、STRING型のソースデータをDOUBLE型に変換します。
sqlコンポーネントは、label列の値を0または1のバイナリ値に変換します。 このパイプラインでは、pm2列はラベル列です。 pm2の列において、200より大きい値は、激しい曇りの天候を示す。 sqlコンポーネントは、pm2列の200を超える値を1としてマークし、200以下の値を0としてマークします。
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1};正規化コンポーネントは、異なる単位の汚染物質濃度を単位のない正規化値に変換します。
②
このセクションに表示されるコンポーネントは、統計分析を実行します。
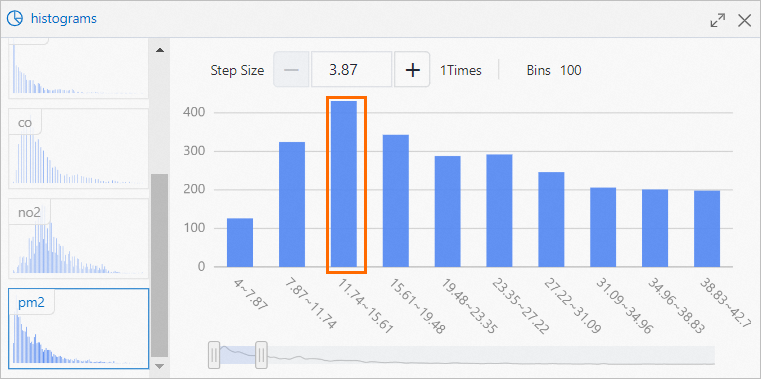
ヒストグラムコンポーネントは、各汚染物質の分布を視覚化します。
例えば、次の図は、PM 2.5濃度の大部分が低下する区間が11.74〜15.61であることを示している。 この区間におけるPM 2.5濃度の総数は430である。
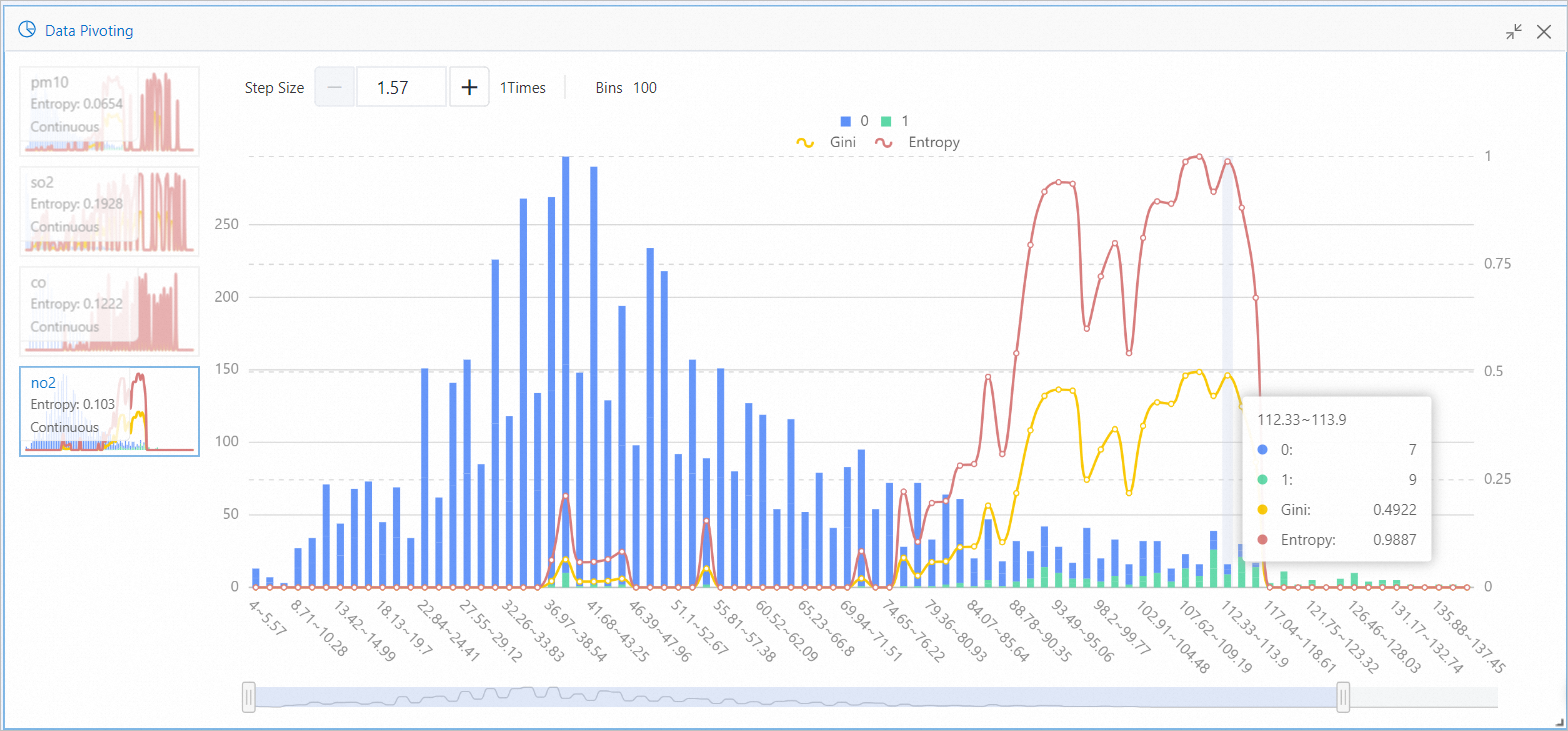
データビューコンポーネントは、結果に対する各汚染物質の異なる間隔の影響を視覚化します。
たとえば、次の図は二酸化窒素の濃度のデータを示しています。 二酸化窒素濃度が112.33〜113.9の区間で低下すると、ラベル列の7つの値が0に変換され、9つが1に変換されます。 これは、二酸化窒素濃度が112.33〜113.9の区間である場合には、荒天の発生確率が高いことを示している。 エントロピー及びGiniは、情報量の観点から、目標値に対する特徴区間の影響を示す。 大きいほど影響が大きいことを示す。
③
このセクションに表示されるコンポーネントは、モデルのトレーニングと予測を行います。 このパイプラインでは、ランダムフォレストとロジスティック回帰コンポーネントがモデルをトレーニングします。
④
このセクションに表示されるコンポーネントは、モデルを評価します。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅で、実行アイコンが表示されます。
パイプラインの実行後、ランダムフォレストコンポーネントの下流コンポーネントとして接続されているevaluateコンポーネントを右クリックします。 表示されるショートカットメニューで、[Visual Analysis] をクリックします。
では、評価セクションをクリックし、評価チャートタブでトレーニングされたモデルの予測結果を表示します。ランダムな森林コンポーネントを使用します。
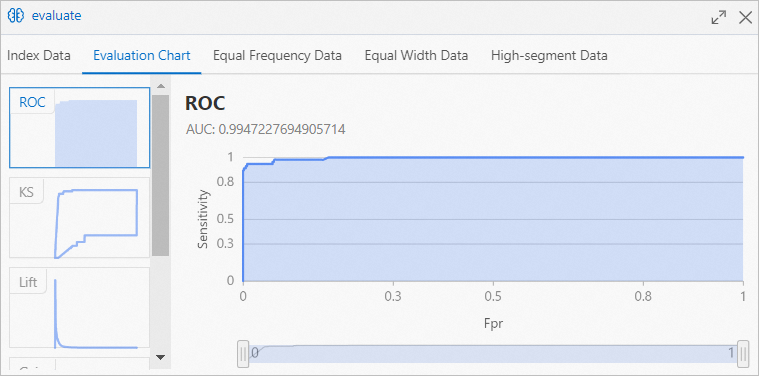 前の図の曲線下面積 (AUC) 値は、大気質予測のための訓練されたモデルの精度が99% よりも高いことを示しています。 このモデルは、ランダムフォレストコンポーネントによってトレーニングされます。
前の図の曲線下面積 (AUC) 値は、大気質予測のための訓練されたモデルの精度が99% よりも高いことを示しています。 このモデルは、ランダムフォレストコンポーネントによってトレーニングされます。 ロジスティック回帰コンポーネントの下流コンポーネントとして接続されているevaluateコンポーネントを右クリックします。 表示されるショートカットメニューで、[Visual Analysis] をクリックします。
では、評価セクションをクリックし、評価チャートタブでトレーニングされたモデルの予測結果を表示します。ロジスティック回帰コンポーネントを使用します。
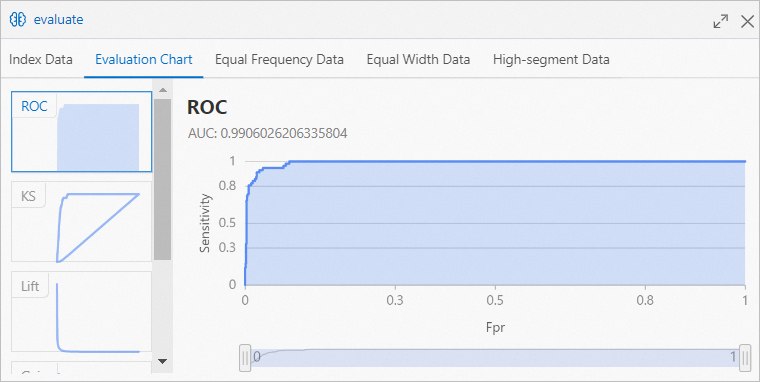 前の図のAUC値は、かすんでいる天気予報のモデルの精度が98% よりも高いことを示しています。 このモデルは、ロジスティック回帰コンポーネントを使用します。
前の図のAUC値は、かすんでいる天気予報のモデルの精度が98% よりも高いことを示しています。 このモデルは、ロジスティック回帰コンポーネントを使用します。