概要
OpenSearch Vector Search Edition は、Alibaba Group によって開発された大規模分散検索エンジンです。 OpenSearch Vector Search Edition は、淘宝(タオバオ)、天猫(Tモール)、Cainiao、優酷(Youku)など、中国本土以外の地域のお客様に提供される e コマースプラットフォームを含む、Alibaba Group 全体に検索サービスを提供しています。 OpenSearch Vector Search Edition は、Alibaba Cloud OpenSearch のベースエンジンでもあります。 長年の開発を経て、OpenSearch Vector Search Edition は、高可用性、高適時性、費用対効果の高いビジネス要件を満たしています。 また、OpenSearch Vector Search Edition は、ビジネスの特徴に基づいてカスタム検索サービスを構築できる自動化された O&M システムも提供します。
アーキテクチャ
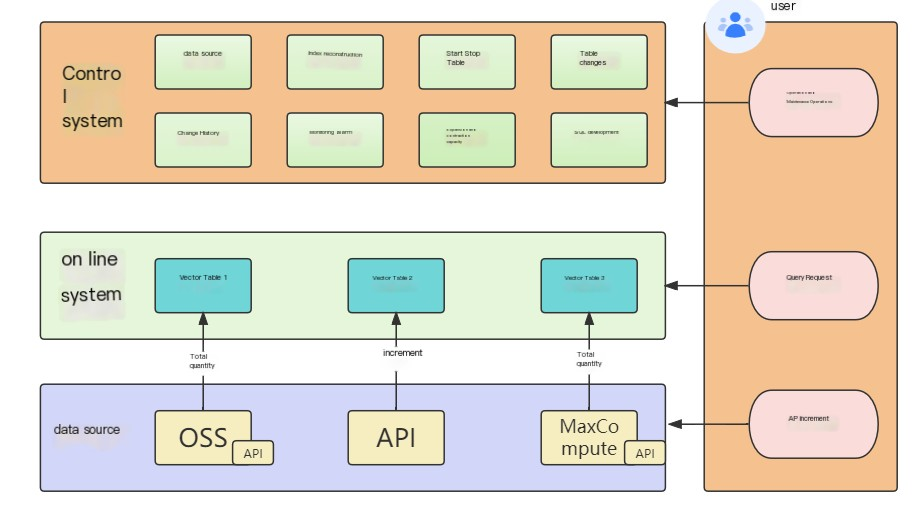
OpenSearch Vector Search Edition は、管理システム、オンライン検索システム、データソースという 3 つの主要コンポーネントで構成されています。 オンライン検索システムはインデックスを読み込み、ベクトル検索サービスを提供します。 データソースは、完全データのインポートと増分データのリアルタイム同期を行うように構成されています。 管理システムは、クラスターを簡単に作成および管理できる自動化された O&M サービスを提供します。
システムアーキテクチャ
オンライン検索システム
ユーザーにとって、オンライン検索システムはテーブルディメンションに基づいて使用されます。 API 操作を呼び出すことで、各ベクトルテーブルのデータを個別にクエリできます。 また、フィールドの設定、ベクトルインデックスの設定、データソースの設定、各テーブルのリアルタイムデータ同時実行制御など、各テーブルを個別に管理することもできます。
オンライン検索システムのバックエンドアーキテクチャは、Query Result Searcher(QRS)ワーカーと Searcher ワーカーで構成される分散アーキテクチャです。
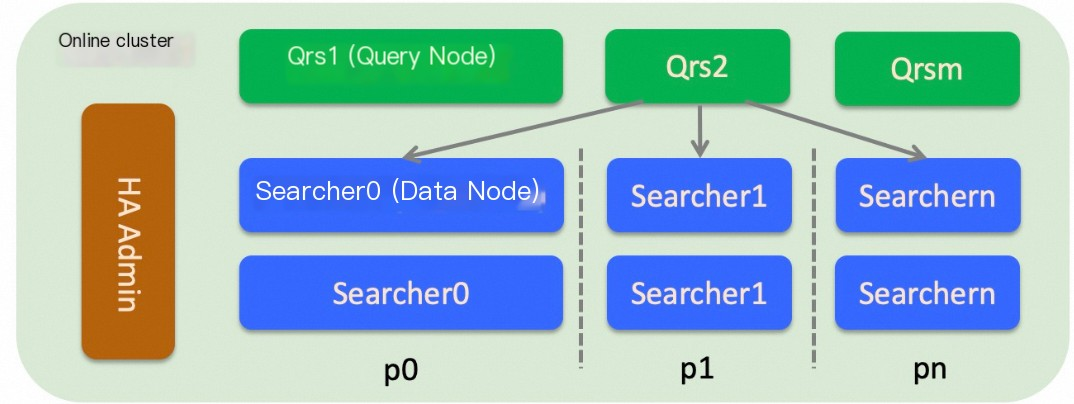
QRS ワーカーは、ユーザーが開始したクエリリクエストを解析、検証、または書き直し、解析されたリクエストを Searcher ワーカーに転送して実行し、Searcher ワーカーから返された結果を収集してマージします。 その後、QRS ワーカーは処理されたクエリ結果をユーザーに返します。 QRS ワーカーはユーザーデータを読み込まない計算ノードであるため、大量のメモリを占有しません。 QRS ワーカーのメモリ使用量は、大量のドキュメントが返される場合、または大量の統計エントリが生成される場合にのみ高くなります。 QRS ワーカーの処理能力がボトルネックに達した場合は、QRS ワーカーの数を増やすか、QRS ワーカーのスペックアップを行うことができます。
Searcher ワーカーは、インデックスデータを読み込み、クエリに基づいてドキュメントを取得し、ドキュメントをフィルタリング、収集、ソートします。 Searcher ワーカーのインデックスはシャーディングできます。 インデックスを複数のシャードに分割し、シャード内のフィールドを [ 0 , 65535 ] の範囲の値にハッシュできます。 インデックスを作成するときに、シャードの数を指定できます。 クラスターに大量のデータが含まれている場合、または高いクエリパフォーマンスが必要な場合は、シャーディングを実行して単一クエリの パフォーマンス を向上させることができます。 クラスターのクエリ パフォーマンス を向上させる場合、たとえば、クエリ/秒(QPS)を 1,000 から 10,000 に増やす場合は、レプリカの数を増やすことができます。 この場合、すべての Searcher ワーカーのデータを指定された数のシャードに分割する必要があります。 シャードのハッシュ値は、[ 0 , 65535 ] の完全な範囲を構成する必要があります。
Searcher ワーカーのリソース(CPU、メモリ、ディスクなど)は、テーブル間で共有されます。
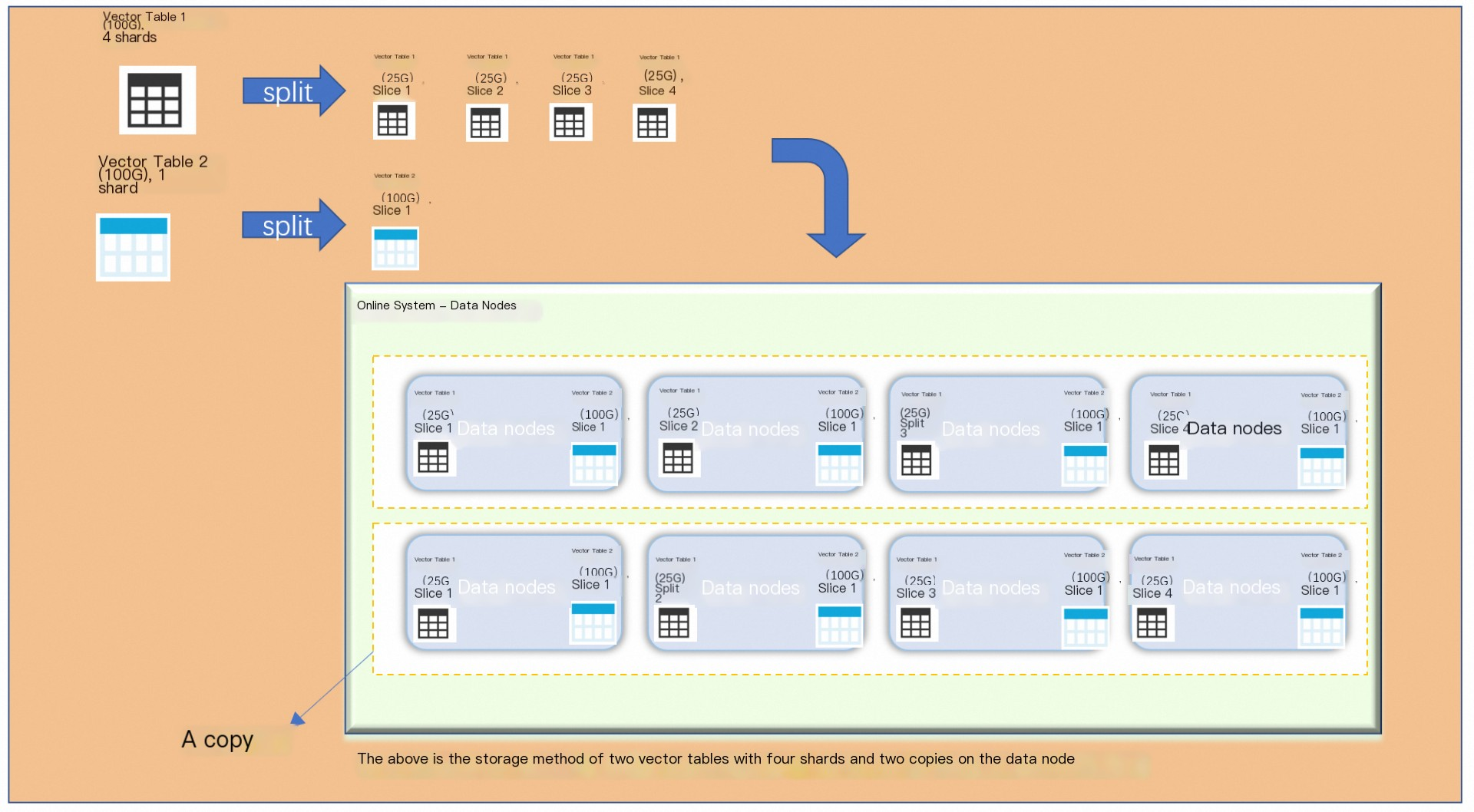
上の図は例を示しています。 ベクトルテーブル 1 には 4 つのシャードが含まれ、ベクトルテーブル 2 には 1 つのシャードが含まれています。 ベクトルテーブル 1 は、生成されたインデックスに基づいて、各シャードにデータを均等に分散します。 ベクトルテーブル 2 は、ブロードキャストテーブルとして各 Searcher ワーカーに完全なベクトルデータを格納します。
データソース
データソースを構成して、インデックスの再作成(完全インデックス作成)を実行することで生データのインデックスを構築し、インデックスの再作成後にインデックスデータをオンライン検索システムのテーブルにインポートしてデータを取得できます。 データソースはテーブルに対応します。 OpenSearch Vector Search Edition は、MaxCompute、Search、Advertisement、Recommendation Offline(SARO)、API などのデータソースタイプをサポートしています。 API データソースの生データは空です。 API データソースを使用する場合は、API 操作を呼び出すことで、すべてのデータをオンライン検索システムの対応するテーブルにプッシュする必要があります。
管理システム
管理システムは、OpenSearch Vector Search Edition インスタンスの O&M プラットフォームです。 このプラットフォームは、O&M コストの大幅な削減に役立ちます。
データ同期プロセス
完全インデックス作成
OpenSearch Vector Search Edition は、複数バージョンのインデックスをサポートしています。 各インデックスバージョンは、生データのコピーに基づいて構築されます。 デフォルトでは、API データソースの生データは空です。 インデックスの再作成がトリガーされるたびに、完全インデックス作成が実行されます。 完全インデックス作成は常駐ジョブではありません。 データが処理され、完全インデックスが生成されると、プロセスは終了します。 その後、完全インデックスがオンラインクラスターに適用され、データが取得されます。
複数バージョンのインデックスにより、データが複数回変更されてもデータの整合性が確保されます。 インデックススキーマまたはデータ構造が変更されると、新しいバージョンのインデックスは以前のバージョンのインデックスから分離されます。 この場合、データの変更でエラーが発生した場合、データを以前のバージョンにロールバックできます。
完全インデックスを構築するには、データ処理、インデックス構築、インデックスマージなど、いくつかの手順が必要です。 各ステップのインデックス処理の同時実行性を設定して、完全インデックス作成を高速化できます。
リアルタイム増分インデックス作成
完全インデックスが構築されると、各インデックスバージョンには常駐の増分インデックス作成プロセスがあります。 増分データは、データ更新ノードを使用して同期されます。
API 操作を呼び出すことで、MaxCompute、Object Storage Service (OSS)、API データソースからテーブルに増分データをプッシュできます。 データ更新ノードは増分データを使用します。 その後、Searcher ワーカーはデータ取得のためにリアルタイムでインデックスを構築します。
増分インデックス作成は常駐ジョブです。 テーブルの各完全インデックス作成は、増分インデックス作成プロセスに対応します。 データ更新ノードの数を調整して、リアルタイムデータの処理能力を向上させることができます。
OpenSearch Vector Search Edition のメリット
安定性
OpenSearch Vector Search Edition の基盤レイヤーは、C++ プログラミング言語を使用して開発されています。 10 年以上の開発を経て、OpenSearch Vector Search Edition は、さまざまなコア 業務システム に安定した検索サービスを提供しています。 OpenSearch Vector Search Edition は、高い安定性が求められるコア検索 シナリオ に適しています。
効率性
OpenSearch Vector Search Edition は、大量のデータを取得できる分散検索エンジンです。 OpenSearch Vector Search Edition は、リアルタイムのデータ更新をサポートしています。 データ更新は数秒以内に反映されます。 したがって、OpenSearch Vector Search Edition は、時間に制約のあるクエリおよび検索 シナリオ に適しています。
費用対効果
OpenSearch Vector Search Edition は、インデックス圧縮と複数値インデックス読み込みテストの複数のポリシーをサポートしており、費用対効果の高い方法でクエリ要件を満たすことができます。