環境変数の設定
ALIBABA_CLOUD_ACCESS_KEY_ID および ALIBABA_CLOUD_ACCESS_KEY_SECRET 環境変数を設定します。
Alibaba Cloud アカウントの AccessKey ペアは、すべての API 操作へのアクセスに使用できます。Resource Access Management (RAM) ユーザーを使用して API 操作を呼び出すか、日常の O&M を実行することを推奨します。RAM ユーザーの使用方法の詳細については、「RAM ユーザーの作成」をご参照ください。
AccessKey ペアの作成方法の詳細については、「AccessKey ペアの作成」をご参照ください。
RAM ユーザーの AccessKey ペアを使用する場合は、Alibaba Cloud アカウントを使用して、必要な権限が AliyunServiceRoleForOpenSearch ロールに付与されていることを確認してください。詳細については、「AliyunServiceRoleForOpenSearch」および「アクセス権限付与ルール」をご参照ください。
プロジェクトコードなど、他人が容易にアクセスできる資料に AccessKey ペアを含めないことを推奨します。そうしないと、AccessKey ペアが漏洩し、アカウント内のリソースが安全でなくなる可能性があります。
Linux および macOS
次のコマンドを実行します。
<access_key_id>と<access_key_secret>を、使用する RAM ユーザーの AccessKey ID と AccessKey Secret に置き換えます。export ALIBABA_CLOUD_ACCESS_KEY_ID=<access_key_id> export ALIBABA_CLOUD_ACCESS_KEY_SECRET=<access_key_secret>Windows
環境変数ファイルを作成し、ALIBABA_CLOUD_ACCESS_KEY_ID および ALIBABA_CLOUD_ACCESS_KEY_SECRET 環境変数をファイルに追加し、環境変数を AccessKey ID と AccessKey Secret に設定します。
Windows を再起動して、AccessKey ペアを有効にします。
OpenSearch SDK for Java V4.0.0 を使用して検索機能を実装するためのデモコード
注: エラーが発生したかどうかは、ステータス情報ではなく、エラーコードとメッセージに基づいて判断してください。
エラーの詳細については、「エラーコード」をご参照ください。
SDK デモ:
実際の使用では、次のパラメーターを使用する必要があるパラメーターに置き換える必要があります。
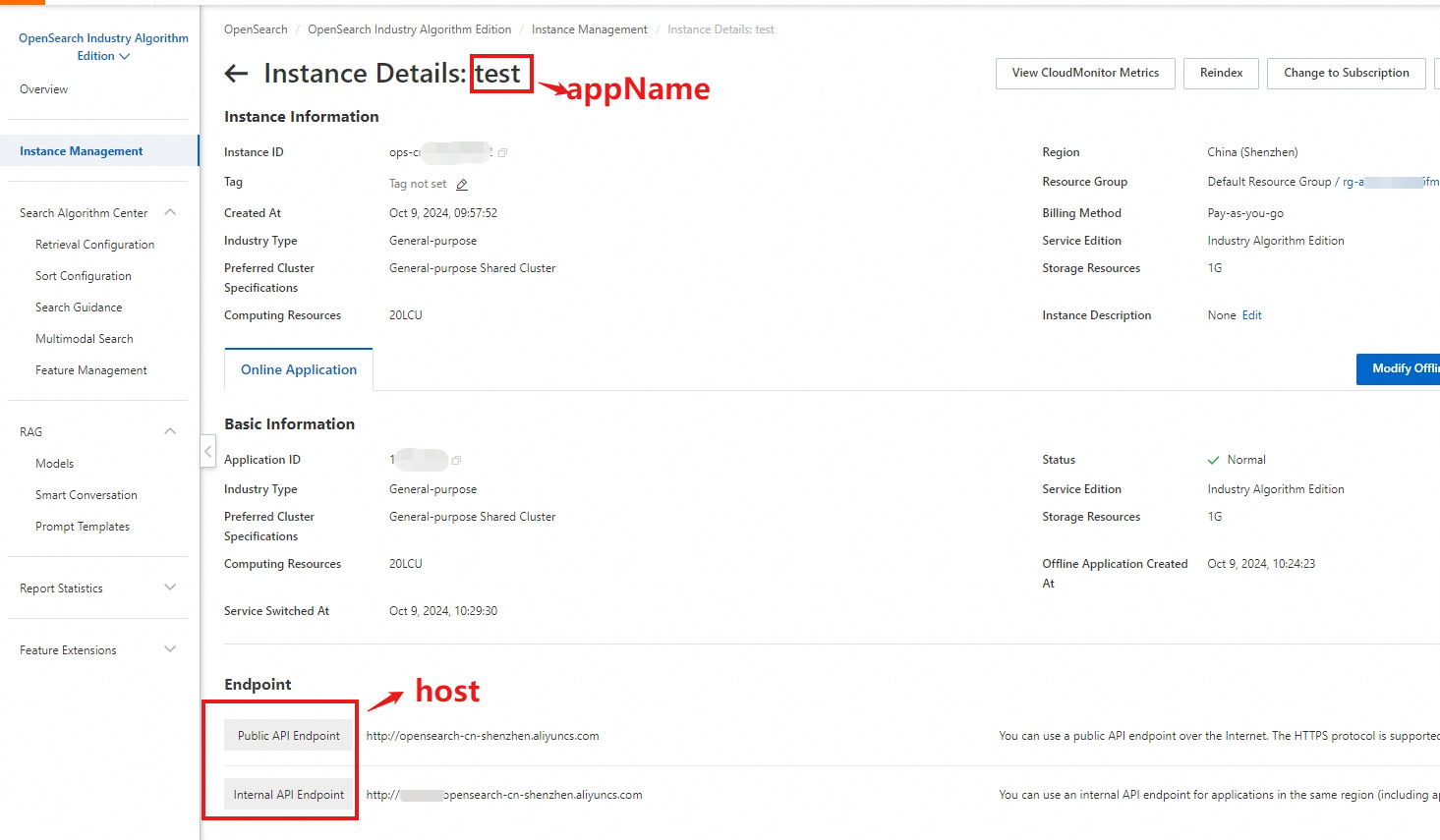
appName: インスタンスの名前。
host: OpenSearch API を呼び出すために使用されるエンドポイント。インターネットまたは VPC (virtual private cloud) 経由で API を呼び出すことができます。
package com.aliyun.opensearch;
import com.aliyun.opensearch.sdk.dependencies.com.google.common.collect.Lists;
import com.aliyun.opensearch.sdk.dependencies.org.json.JSONObject;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import com.aliyun.opensearch.sdk.generated.search.*;
import com.aliyun.opensearch.sdk.generated.search.general.SearchResult;
import com.aliyun.opensearch.search.SearchParamsBuilder;
import com.aliyun.opensearch.search.SearchResultDebug;
import java.nio.charset.Charset;
public class testSearch {
private static String appName = "管理する OpenSearch アプリケーションの名前";
private static String host = "お使いのリージョンの OpenSearch API のエンドポイント";
public static void main(String[] args) {
// AccessKey ペアを指定します。
// 環境変数から AccessKey ID と AccessKey Secret を取得します。このコードを実行する前に、環境変数を設定する必要があります。
String accesskey = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID");
String secret = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET");
// ファイルのエンコード形式とデフォルトのエンコード形式を取得します。
System.out.println(
String.format("file.encoding: %s", System.getProperty("file.encoding"))
);
System.out.println(
String.format("defaultCharset: %s", Charset.defaultCharset().name())
);
// OpenSearch オブジェクトを作成します。
OpenSearch openSearch = new OpenSearch(accesskey, secret, host);
// OpenSearch オブジェクトをパラメーターとして使用して、OpenSearchClient オブジェクトを作成します。
OpenSearchClient serviceClient = new OpenSearchClient(openSearch);
// OpenSearchClient オブジェクトをパラメーターとして使用して、SearcherClient オブジェクトを作成します。
SearcherClient searcherClient = new SearcherClient(serviceClient);
// Config オブジェクトを作成し、config 句を使用して、アプリケーション名、ページング関連のパラメーター、返される結果のデータ形式などのパラメーターを設定します。
Config config = new Config(Lists.newArrayList(appName));
config.setStart(0);
config.setHits(5);
// 返される結果のデータ形式を指定します。サポートされている形式は、XML、JSON、FULLJSON です。この例では、データ形式は FULLJSON に設定されています。
config.setSearchFormat(SearchFormat.FULLJSON);
// 検索結果で返されるフィールドを指定します。
config.setFetchFields(
Lists.newArrayList(
"id",
"name",
"phone",
"int_arr",
"literal_arr",
"float_arr",
"cate_id"
)
);
// 注: config 句の rerank_size パラメーターは、Rank クラスの setReRankSize メソッドを使用して指定されます。
// kvpairs 句を指定します。この例では、uniq プラグインが distinct 句に追加されます。これにより、setReserved パラメーターが false に設定されている場合に、total および viewtotal パラメーターの値が正確であることが保証されます。
//config.setKvpairs("duniqfield:cate_id");
// SearchParams オブジェクトを作成します。
SearchParams searchParams = new SearchParams(config);
// query 句を指定します。複数のキーワードを指定して、複数のインデックスフィールドに基づいてクエリを実行できます。この場合、1 つの setQuery 呼び出しでインデックスフィールドを指定する必要があります。OR で 2 つのインデックスフィールドを接続できます。次のコードに例を示します。各インデックスフィールドを個別の setQuery 呼び出しで指定すると、最後の句が前の句を上書きします。
searchParams.setQuery("name:'opensearch' OR title:'opensearch'");
// Distinct オブジェクトを作成します。
Distinct dist = new Distinct();
dist.setKey("cate_id"); // distinct 抽出に使用するフィールドを指定します。
dist.setDistCount(1); // 毎回抽出されるドキュメントの数を指定します。
dist.setDistTimes(1); // 抽出回数を指定します。
dist.setReserved(false); // 抽出後に残りのドキュメントを保持するかどうかを指定します。
dist.setUpdateTotalHit(false); // setreserved パラメーターが false に設定されている場合に、totalHits パラメーターの値から破棄されたドキュメントの数を減算するかどうかを指定します。
dist.setDistFilter("cate_id<=3"); // 抽出するドキュメントを選択するために使用するフィルター条件を指定します。
dist.setGrade("1.2"); // distinct 抽出のしきい値を指定します。
// duniqfield パラメーターは、config 句の kvpairs 句の形式で指定されます。
// Distinct オブジェクトをクエリパラメーターとして追加します。
searchParams.addToDistincts(dist);
// Aggregate オブジェクトを作成します。
Aggregate agg = new Aggregate();
agg.setGroupKey("cate_id"); // 集約するフィールドを指定します。
agg.setAggFun("count()"); // 集約関数を指定します。
agg.setAggFilter("cate_id=1"); // 集約フィルターを指定します。
agg.setRange("0~10"); // 集約範囲を指定します。
agg.setAggSamplerThresHold("5"); // サンプリングされた集約のしきい値を設定します。
agg.setAggSamplerStep("5"); // サンプリングされた集約のしきい値を指定します。
agg.setMaxGroup("5"); // 返されるグループの最大数を指定します。
// Aggregate オブジェクトをクエリパラメーターとして追加します。
//searchParams.addToAggregates(agg);
// 複数の統計フィールドを指定します。
Set<Aggregate> Aggregates = new HashSet();
Aggregate aggregate1 = new Aggregate();
aggregate1.setGroupKey("cate_id");
aggregate1.setAggFun("count()");
Aggregates.add(aggregate1);
Aggregate aggregate2 = new Aggregate();
aggregate2.setGroupKey("cate_id_1");
aggregate2.setAggFun("count()");
Aggregates.add(aggregate2);
searchParams.setAggregates(Aggregates);
// biz パラメーターを指定します。
Map hashMap = new HashMap();
hashMap.put("biz", "type:web");
searchParams.setCustomParam(hashMap);
// フィルター条件を指定します。
// searchParams.setFilter("id > \"0\""); // SearchParamsBuilder クラスを使用してフィルター条件を設定することもできます。
// ソート条件を指定します。
Sort sorter = new Sort();
sorter.addToSortFields(new SortField("id", Order.DECREASE)); // ドキュメントのソート基準となるフィールドとソート方法を指定します。この例では、ドキュメントは id フィールドに基づいて降順にソートされます。
sorter.addToSortFields(new SortField("RANK", Order.INCREASE)); // 複数のドキュメントが同じ id フィールドの値を持つ場合、RANK フィールドに基づいてドキュメントを昇順にソートします。
// この例では、ドキュメントは tag_match フィールドに基づいてソートされます。キーと値のペアは config 句に設定する必要があります。
//sorter.addToSortFields(new SortField("tag_match(\"kk1\",int_array,10,\"max\",\"false\",\"false\")", Order.INCREASE));
//config.setKvpairs("kk1:10");
// ソート条件をクエリパラメーターとして追加します。
searchParams.setSort(sorter);
// 基本ソート式と高度ソート式を指定します。この例では、デフォルトの式が使用されます。
Rank rank = new Rank();
rank.setFirstRankName("default");
rank.setSecondRankName("default");
rank.setReRankSize(5); // 高度ソート式に基づいてソートされるドキュメントの数を指定します。
// Aggregate オブジェクトをクエリパラメーターとして追加します。
searchParams.setRank(rank);
// re_search パラメーターを指定します。
//strategy:threshold,params:total_hits#10 => "strategy:threshold" はクエリ戦略を示します。サポートされている戦略は 1 つだけです。
// total_hits パラメーターを使用してしきい値を設定します。クエリの最初の実行で total_hits パラメーターの値が指定されたしきい値より小さい場合、クエリが再度実行されます。
Map<String, String> reSearchParams = new HashMap<String, String>();
reSearchParams.put("re_search", "strategy:threshold,params:total_hits#10");
// 検索候補に関連付けられているクエリの from_request_id パラメーターを指定します。
reSearchParams.put("from_request_id", "159851481919726888064081");
//searchParams.setCustomParam(reSearchParams);
// Summary オブジェクトを作成します。この例では、SearchParamsBuilder オブジェクトを使用して、検索結果のサマリーがクエリパラメーターとして追加されます。
Summary summ = new Summary("name");
summ.setSummary_field("name");// サマリーを生成する基準となるフィールドを指定します。フィールドは、分析できるようにテキスト型である必要があります。
summ.setSummary_len("50");// 各スニペットの長さを指定します。
summ.setSummary_element("em"); // 検索クエリを赤でハイライトするために使用される HTML タグの名前を指定します。
summ.setSummary_ellipsis("..."); // セグメントを接続するために使用されるコネクタを指定します。
summ.setSummary_snippet("1");// 各クエリがヒットできるサマリースニペットの数を指定します。
// Summary オブジェクトをクエリパラメーターとして追加します。
//searchParams.addToSummaries(summ);
// raw_query パラメーターを追加します。パラメーターの値は、検索クエリの値と同じでなければなりません。
searchParams.setRawQuery("opensearch");
// SearchParamsBuilder オブジェクトを作成します。SearchParams のユーティリティクラスとして、SearchParamsBuilder クラスを使用すると、クエリ関連のパラメーターを簡単に設定できます。
SearchParamsBuilder paramsBuilder = SearchParamsBuilder.create(
searchParams
);
// SearchParamsBuilder オブジェクトを使用して、作成された検索結果のサマリーをクエリパラメーターとして追加します。
paramsBuilder.addSummary("name", 50, "em", "...", 1);
// フィルター条件を指定します。
paramsBuilder.addFilter("id>=0", "AND");
// disable パラメーターを指定して、再検索機能を無効にします:
//searchParams.putToCustomParam("disable", "re_search");
try {
// クエリを実行して結果を返します。エラーが発生したかどうかは、エラーコードとメッセージに基づいて判断します。エラーの詳細については、「エラーコード」のトピックをご参照ください。
SearchResult searchResult = searcherClient.execute(paramsBuilder);
String result = searchResult.getResult();
JSONObject obj = new JSONObject(result);
// 検索結果を表示します。
System.out.println(obj.toString());
// デバッグのためにリクエストアドレスに関する情報が必要になる場合があります。
SearchResultDebug searchdebugrst = searcherClient.executeDebug(
searchParams
);
// 最後のクエリのリクエスト文字列を表示します。
System.out.println(searchdebugrst.getRequestUrl());
} catch (OpenSearchException e) {
e.printStackTrace();
} catch (OpenSearchClientException e) {
e.printStackTrace();
}
}
}
クエリ句の詳細については、「句」をご参照ください。