このトピックでは、MongoDB 4.4の機能について説明します。 Alibaba Cloudは、MongoDBの公式戦略パートナーであり、サービスにMongoDB 4.4を導入した最初のクラウドプロバイダーです。 2020年11月にApsaraDB for MongoDB V4.4をリリースしました。 MongoDB 4.4は2020年7月30日に正式にリリースされました。 以前のメジャーバージョンと比較して、MongoDB 4.4は、ユーザーの注目を集める以前のバージョンの主な問題に対処する完全に拡張されたバージョンです。
非表示インデックス
多数のインデックスは書き込みパフォーマンスを低下させますが、複雑なデータにより、O&Mエンジニアは潜在的に効果のないインデックスを削除することが困難になります。 有効なインデックスが偶然削除されると、ジッタが発生する可能性があります。 さらに、誤って削除されたインデックスを再作成するコストが高い。
これらの問題を解決するために、Alibaba CloudとMongoDBは戦略的パートナーとして隠しインデックス機能を共同で開発しました。 詳細については、ApsaraDB For MongoDBプロダクトページをご参照ください。 この機能を使用すると、collModコマンドを使用してインデックスを非表示にできます。 非表示インデックスは、後続のクエリでは使用されません。 隠しインデックスでエラーが発生しない場合は、インデックスを削除できます。
構文:
db.ru nCommand( {
collMod: 'testcoll' 、
index: {
keyPattern: 'key_1 '、
hidden: false
}
} )非表示のインデックスは、MongoDBのクエリプランナーにのみ表示されます。 インデックスは、一意のインデックス制約や有効期限 (TTL) などのいくつかのインデックス機能を保持します。
非表示のインデックスは、非表示になっても引き続き更新されるため、非表示にするとすぐにアクティブになります。
精製可能なシャードキー
シャードキーは、シャードクラスターで重要な役割を果たします。 シャードキーは、特定のワークロードの下でシャードクラスターをよりスケーラブルにすることができます。 ただし、MongoDBの実際の使用では、シャードキーを慎重に選択した場合でも、ワークロードの変更により、単一のシャードに大量のチャンクやクエリのホットスポットが発生する可能性があります。 ジャンボチャンクは、指定されたチャンクサイズを超えて成長するチャンクです。
MongoDB 4.0以前では、コレクションのシャードキーとシャードキー値は不変です。 MongoDB 4.2以降では、シャードキー値を変更できます。 ただし、シャードキー値を変更するには、分散トランザクションに基づいてシャード間でデータを移行する必要があります。 このメカニズムには高いパフォーマンスのオーバーヘッドがあり、ジャンボチャンクやクエリホットポットを防ぐことはできません。 たとえば、{customer_id:1} シャードキーを使用して注文コレクションをシャードする場合、各顧客による注文数が少ないため、企業の初期段階ではシャードキーで十分です。 しかし、企業が発展するにつれて、大勢の顧客がますます多くの注文を出すと、注文の収集に対して頻繁なクエリが行われ、単一シャードクエリのホットスポットが発生する可能性があります。 注文はcustomer_idフィールドと密接な関係があります。不均一なクエリはcustomer_idフィールドを変更しても解決できません。
この場合、MongoDB 4.4が提供するrefineCollectionShardKeyコマンドを使用して、既存のシャードキーに1つ以上のサフィックスフィールドを追加できます。 このようにして、よりきめ細かいデータ分散がドキュメントに使用され、巨大なチャンクが防止されます。 たとえば、refineCollectionShardKeyコマンドを使用して、シャードキーを {customer_id:1, order_id:1} に変更できます。 このようにして、単一シャードクエリのホットスポットを防ぐことができます。
refineCollectionShardKeyコマンドは、configサーバーノードのメタデータのみを変更し、データを移行しないため、パフォーマンスのオーバーヘッドが低くなります。 チャンクが他のシャードに分割または移行されると、データは徐々に分散されます。 シャードキーはインデックスでサポートされている必要があります。 refineCollectionShardKeyコマンドを実行する前に、新しいシャードキーをサポートするインデックスを作成する必要があります。
サフィックスフィールドは、すべてのドキュメントに格納されるわけではありません。 この問題を解決するために、MongoDB 4.4は欠落しているシャードキー機能を提供します。 シャードコレクションのドキュメントは、特定のシャードキーフィールドを見逃す可能性があります。 不足しているシャードキー機能の欠点は、ジャンボチャンクにつながる可能性があることです。 必要な場合を除き、この機能を使用しないことを推奨します。
複合ハッシュされたシャードキー
MongoDB 4.4より前のバージョンは、複合ハッシュインデックスをサポートしていません。 1つのフィールドで指定できるのはハッシュキーだけです。 これにより、データシャードにわたるコレクション内のデータ分布が不均一になる可能性があります。
MongoDB 4.4は、複合ハッシュインデックスをサポートします。 複合インデックス内の単一のハッシュフィールドをプレフィックスまたはサフィックスフィールドとして指定できます。
構文:
sh.shardCollection (
"examples.com poundHashedCollection" 、
{"region_id": 1, "city_id": 1, field1 " : " hashed "}
)
sh.shardCollection (
"examples.com poundHashedCollection" 、
{"_id" : "hashed", "fieldA" : 1}
) 以下のシナリオでは、複合ハッシュインデックスを最大限に活用できます。
関連する法律や規制を遵守するには、MongoDBが提供するゾーンシャーディング機能を使用して、ゾーン内に存在するシャード全体にデータを均等に分散する必要があります。
コレクションは、シャードキーとして単調に増加する値を使用します。 この場合、
customer_idフィールドの値は、{customer_id:1, order_id:1}シャードキーの単調増加数です。 最新の顧客からのデータも同じシャードに書き込まれるため、シャードが大きくなり、シャード間でデータが不均一に分散します。
複合ハッシュインデックスがサポートされていない場合は、単一のフィールドのハッシュ値を計算し、そのハッシュ値をインデックス値としてドキュメントの特別なフィールドに格納してから、レンジドシャーディング機能を使用してインデックス値をシャードキーとして指定する必要があります。
MongoDB 4.4では、フィールドをハッシュとして指定するだけで済みます。 上記の2番目のシナリオでは、シャードキーを {customer_id:'hashed', order_id:1} に設定するだけです。 これにより、ビジネスロジックが簡素化されます。
Hedged読み取り
ネットワーク待ち時間は、経済的損失を引き起こす可能性がある。 Googleのレポートによると、ページの読み込みに3秒以上かかると、訪問者の半数以上がページを離れることが示されています。 レポートの詳細については、すべてのマーケティング担当者が知っておくべき7ページの速度統計をご覧ください。 ネットワーク遅延を最小限に抑えるために、MongoDB 4.4はヘッジ読み取り機能を提供します。 シャードクラスターでは、mongosノードは、クエリされたシャードごとに2つのレプリカセットメンバーに読み取り操作をルーティングし、シャードごとに最初の回答者からクライアントに結果を返します。 このようにして、P95およびP99レイテンシが低減される。 P95およびP99レイテンシは、過去10秒間の要求の最も遅い5% および1% の平均レイテンシが制限内であることを示す。
Hedged Readは、Read Preferenceパラメーターの一部として操作ごとに指定されます。 特定の操作では、ヘッダー読み取りがサポートされます。 読み取り設定パラメーターを最も近いに設定すると、システムはヘッジされた読み取り機能を有効にします。 Read Preferenceパラメーターをprimaryに設定すると、ヘッジされた読み取り機能はサポートされません。 [読み取り設定] パラメーターを最も近い値またはプライマリ以外の値に設定した場合、hedgeOptionsパラメーターをtrueに設定して、ヘッジされた読み取り機能を有効にする必要があります。 構文:
db.collection.find({ }).readPref (
"secondary", // モード
[ { "datacenter": "B" }, { } ], // タグセット
{enabled: true } // ヘッジオプション
) ヘッジされた読み取り機能のmongosノードのサポートも有効にする必要があります。 サポートを有効にするには、readHedgingModeパラメーターをonに設定する必要があります。
構文:
db.adminCommand( { setParameter: 1, readHedgingMode: "on" } )レプリケーション待ち時間の短縮
MongoDB 4.4は、プライマリ /セカンダリレプリケーションのレイテンシを削減します。 プライマリ /セカンダリレプリケーションのレイテンシは、MongoDBの読み取り /書き込み操作に影響します。 一部のシナリオでは、セカンダリデータベースはプライマリデータベースの増分更新を短期間でレプリケートして適用する必要があります。 そうしないと、セカンダリデータベースは引き続き読み取りおよび書き込み操作を実行できません。 レイテンシが低いと、プライマリ /セカンダリの一貫性が向上します。
ストリーミング複製
MongoDB 4.4より前のバージョンでは、セカンダリデータベースはアップストリームデータをポーリングして増分更新を取得する必要があります。 アップストリームデータをポーリングするために、セカンダリデータベースはgetMoreコマンドをプライマリデータベースに送信してoplogコレクションをスキャンします。 oplogコレクションにエントリがある場合、セカンダリデータベースはoplogエントリのバッチをフェッチします。 バッチのサイズは最大16 MBです。 スキャンがoplogコレクションの最後に達すると、セカンダリデータベースはawaitDataパラメーターを使用してgetMoreコマンドをブロックします。 新しいデータがoplogコレクションに挿入されると、セカンダリデータベースはoplogエントリの次のバッチをフェッチします。 フェッチ動作は、ソースマシンと宛先マシンとの間の往復時間 (RTT) を必要とするOplogFetcherスレッドを使用する。 レプリカセットのネットワーク状態が悪い場合、ネットワーク遅延はレプリケーションのパフォーマンスを低下させます。
MongoDB 4.4では、プライマリデータベースは、セカンダリデータベースがアップストリームデータをポーリングするのを待つのではなく、セカンダリデータベースにoplogエントリの連続ストリームを送信します。 2次データベースがアップストリームデータをポーリングする方法と比較して、RTTの少なくとも半分がoplogエントリのバッチごとに保存されます。 次のシナリオでは、ストリーミングレプリケーションを最大限に活用できます。
書き込み操作でwriteConcernパラメーターを
"majority"に設定した場合、"majority" 書き込み操作は複数回レプリケーションを待機する必要があります。 レイテンシーの高いネットワーク条件下でも、ストリーミングレプリケーションは、「過半数」の書き込み操作を50% することで、平均パフォーマンスを向上させることができます。因果整合セッションを使用する場合は、セカンダリデータベースで独自の書き込み操作を読み取ることができます。 この機能では、セカンダリデータベースがプライマリデータベースのoplogコレクションを即座に複製する必要があります。
同時インデックス作成
MongoDB 4.4より前のバージョンでは、インデックスをセカンダリデータベースにレプリケートする前に、プライマリデータベースにインデックスを作成する必要があります。 セカンダリデータベースにインデックスを作成する方法は、バージョンによって異なります。 セカンダリデータベースのoplogコレクションへの影響は、セカンダリデータベースでインデックスを作成する方法によって異なります。
MongoDB 4.2では、フォアグラウンドインデックスとバックグラウンドインデックスが同じ方法で作成されます。 コレクションは、インデックス作成プロセスの最初と最後にのみ排他ロックを保持します。 このきめ細かいロック方法にもかかわらず、インデックス作成プロセスのCPUおよびI/Oオーバーヘッドにより、レプリケーションの待ち時間が発生します。 一部の特別な操作は、セカンダリデータベースのoplogコレクションにも影響する場合があります。 たとえば、collModコマンドを使用してコレクションのメタデータを変更すると、oplogコレクションがブロックされる可能性があります。 プライマリデータベースの履歴oplogコレクションがオーバーライドされているため、oplogコレクションは [復元] 状態になることもあります。
MongoDB 4.4では、プライマリデータベースとセカンダリデータベースにインデックスが同時に作成されます。 このようにして、一次 /二次レイテンシが低減される。 セカンダリデータベースは、インデックス作成プロセス中でも最新のデータを読み取ることができます。
インデックスは、投票ノードの過半数がインデックスの作成を完了した場合にのみ使用できます。 これにより、読み書き分離シナリオでインデックスが異なることによるパフォーマンスの違いを減らすことができます。
ミラー読み取り
ApsaraDB for MongoDBの一般的な現象の1つは、3ノードのレプリカセットインスタンスを購入するほとんどのユーザーがプライマリノードでのみ読み取りおよび書き込み操作を実行し、セカンダリノードは読み取りトラフィックを処理しないことです。 この場合、時折のフェイルオーバーは顕著なアクセス遅延を引き起こし、アクセス速度は一定期間後にのみ通常に戻すことができます。 アクセス遅延は、選択されたプライマリノードが初めて読み取りトラフィックを処理しているために発生します。 選択された一次ノードは、頻繁にアクセスされるデータの特性を確認せず、対応するキャッシュを持たない。 選択されたプライマリノードが読み取りトラフィックを処理した後、読み取り操作で多数のキャッシュミスが発生し、データをディスクからリロードする必要があります。 この結果、アクセス待ち時間が増大する。 この問題は、メモリ容量が大きいインスタンスでは明らかです。
MongoDB 4.4は、ミラー読み取り機能を提供します。 プライマリノードは、ミラーリングされた読み取りを使用して、受信した読み取り操作のサブセットをミラーリングし、選択可能なセカンダリデータベースのサブセットに送信できます。 これは、二次データベースがキャッシュを事前ウォームするのに役立つ。 ミラーリングされた読み取りは、火と忘却の操作です。 Fire-and-forget操作は、プライマリデータベースのパフォーマンスに影響を与えない非ブロック操作です。 ただし、セカンダリデータベースではワークロードが増加します。
mirrorReadsパラメーターを使用して、ミラーリングされた読み取りレートを指定できます。 デフォルトのレートは1% です。
構文:
db.adminCommand( { setParameter: 1, mirrorReads: { samplingRate: 0.10 } } )db.serverStatus( { mirroredReads: 1 } ) コマンドを使用して、ミラーリングされた読み取りの統計を収集することもできます。 構文:
SECONDARY> db.serverStatus( { mirroredReads: 1 } ).mirroredReads
{"seen" : NumberLong(2), "sent" : NumberLong(0) } 再開可能な初期同期
MongoDB 4.4より前のバージョンでは、ネットワークの中断が発生した場合、セカンダリデータベースは最初の完全同期プロセス全体を再起動する必要があります。 大量のデータがある場合、これはワークロードに大きな影響を与えます。
MongoDB 4.4では、セカンダリデータベースは同期プロセスの再開を試みることができます。 指定された期間中にセカンダリデータベースが最初の完全同期プロセスを再開できない場合、システムは新しいソースを選択し、完全同期プロセスを最初から再開します。 デフォルトでは、セカンダリデータベースは24時間の初期同期を再開しようとします。 replication.initialSyncTransientErrorRetryPeriodSecondsパラメーターを使用して、セカンダリデータベースが同期プロセスを再開しようとしたときに同期ソースを変更できます。
ネットワークで非一時的な接続エラーが発生した場合、セカンダリデータベースは最初の完全同期プロセス全体を再開する必要があります。
時間ベースのoplog保持
MongoDBでは、oplogコレクションはデータベース内のデータを変更するすべての操作を記録します。 oplogコレクションは、レプリケーション、増分バックアップ、データ移行、およびデータサブスクリプションに使用できる重要なインフラストラクチャです。
oplogコレクションは上限付きコレクションです。 MongoDBの3.6以降、replSetResizeOplogコマンドを使用してoplogコレクションのサイズを変更できます。 ただし、正確な増分oplogエントリを取得することはできません。 次のシナリオでは、時間ベースのoplog保持機能を使用できます。
セカンダリノードは、メンテナンスのために02:00:00から04:00:00までシャットダウンされる予定です。 この期間中、アップストリームデータベースは、oplogコレクションがないために完全な同期をトリガーする可能性があります。 完全な同期は防止される必要がある。
例外が発生した場合、ダウンストリームデータベースのデータ購読コンポーネントがサービスを提供できない場合があります。 サービスは最大3時間以内に復元され、増分データが再び取得されます。 この場合、上流のデータベースに増分データがないことを防ぐ必要があります。
ほとんどのシナリオでは、最後の期間に生成されたoplogエントリを保持する必要があります。 しかしながら、最後の期間に生成されたoplogエントリの数を決定することは困難である。
MongoDB 4.4では、storage.oplogMinRetentionHoursパラメーターを使用して、oplogエントリを保持する最小時間数を指定できます。 replSetResizeOplogコマンドを使用して、最小時間数を変更できます。 構文:
// まず、現在の設定値を表示する
db.getSiblingDB("admin").serverStatus().oplogTruncation.oplogMinRetentionHours
// 変更
db.adminCommand({
"replSetResizeOplog" : 1、
"minRetentionHours" : 2
}) Union
MongoDB 4.4より前のバージョンは、SQL for unionクエリのLEFT OUTER JOIN機能に似た $lookupステージを提供します。 MongoDB 4.4では、$unionWithステージは、SQLのUNION ALL演算子と同様の機能を提供します。 $lookupステージを使用して、複数のコレクションのパイプライン結果を1つの結果セットに結合し、指定した条件に基づいてデータをクエリおよびフィルタリングできます。 $unionWithステージは、シャードコレクションに対するクエリのサポートが $lookupステージとは異なります。 複数の $unionWithステージを使用して、複数のコレクションと集計パイプラインをブレンドできます。 構文:
{ $unionWith: { coll: "<collection>", pipeline: [ <stage1>, ... ] } }パイプラインパラメーターで異なるステージを指定して、集計前に指定したコレクションに基づいてデータをフィルタリングすることもできます。 この方法は柔軟に使用できます。 たとえば、ビジネスの注文データをテーブルごとに異なるコレクションに格納する必要があるとします。 構文:
db.orders_april.insertMany([
{ _id:1、item: "A" 、quantity: 100} 、
{ _id:2、item: "B" 、quantity: 30} 、]);
db.orders_may.insertMany([
{ _id:1、item: "C" 、quantity: 20} 、
{ _id:2、item: "A" 、quantity: 50} 、]);
db.orders_june.insertMany([
{ _id:1、item: "C" 、quantity: 100} 、
{ _id:2、item: "D" 、quantity: 10} 、]); MongoDB 4.4より前のバージョンでは、第2四半期に異なる製品の売上レポートが必要な場合は、すべてのデータを自分で読み取り、アプリケーションレイヤーでデータを集約する必要があります。 または、データウェアハウスを使用してデータを分析する必要があります。 MongoDB 4.4では、単一の集計文を使用してデータを集計するだけで済みます。 構文:
db.orders_april.aggregate( [
{ $unionWith: "orders_may"} 、
{ $unionWith: "orders_june"} 、
{ $group: { _id: "$item" 、合計: { $sum: "$quantity" } } } 、
{ $sort: { total: -1 }}
] ) カスタム集計式
MongoDB 4.4より前のバージョンで複雑なクエリを実行するには、findコマンドで $where演算子を使用します。 または、MapReduceコマンドを使用して、サーバー上でJavaScriptファイルを実行することもできます。 ただし、これらの方法では集約パイプラインを使用できません。
MongoDB 4.4では、$where演算子およびMapReduceコマンドの代わりに、$accumulatorおよび $function集計パイプライン演算子を使用できます。 JavaScriptで独自のカスタム式を定義し、集計パイプラインの一部としてデータベースサーバーで式を実行できます。 このように、集約パイプラインフレームワークは、複雑なクエリを集約するのに便利になり、ユーザーエクスペリエンスが向上します。
$accumulator演算子は、MapReduceコマンドと同様に機能します。 init関数は、入力ドキュメントの状態を初期化するために使用されます。 次に、accumulate関数を使用して、各入力ドキュメントの状態を更新し、merge関数を実行するかどうかを判断します。
たとえば、シャードコレクションで $accumulator演算子を使用する場合、複数の状態をマージするにはmerge関数が必要です。 finalize関数も指定した場合、マージ関数は、すべてのドキュメントが処理された後、finalize関数の結果に基づいて、マージされた状態の結合結果を返します。
$function演算子は、$where演算子と同様に機能します。 追加の利点は、$function演算子が他の集計パイプライン演算子と連携できることです。 findコマンドで $function演算子を $expr演算子と一緒に使用することもできます。 この演算子の組み合わせは、$where演算子に相当します。 MongoDBの公式マニュアルでは、$function演算子の使用も提案されています。
新しい集計パイプライン演算子
MongoDB 4.4は、$accumulatorおよび $function演算子に加えて、複数の目的で新しい集計パイプライン演算子を提供します。 たとえば、文字列を操作して、配列の最後の要素を取得できます。 ドキュメントまたはバイナリ文字列のサイズを取得することもできます。 次の表に、新しい集計パイプライン演算子を示します。
演算子 | 説明 |
$アキュムレータ | ユーザー定義のアキュムレータ演算子の結果を返します。 |
$binarySize | 指定された文字列またはバイナリオブジェクトのサイズを返します。 単位:バイト |
$bsonSize | 指定されたBinary Javascript Object Notation (BSON) でエンコードされたドキュメントのサイズを返します。 単位:バイト |
$ファースト | 配列の最初の要素を返します。 |
$関数 | カスタム集計式を定義します。 |
$最後 | 配列の最後の要素を返します。 |
$isNumber | 指定された式が整数型、小数型、double型、またはlong型の場合、ブール値 |
$replaceOne | 指定された文字列と一致する最初のインスタンスを置き換えます。 |
$replaceAll | 指定した文字列と一致するすべてのインスタンスを置き換えます。 |
接続の監視とプール
MongoDB 4.4では、ドライバーを使用して接続プール動作を設定および監視できます。 接続プールに関連付けられているイベントをサブスクライブするには、標準APIが必要です。 イベントには、接続プールでの接続の確立と終了、接続プールのクリアが含まれます。 また、APIを使用して、プールに許可される接続の最大数または最小数、接続を維持できる最大時間、スレッドが接続が利用可能になるまで待機できる最大時間など、接続プールのオプションを設定することもできます。 詳細については、「接続のモニタリングとプール」をご参照ください。
グローバルな読み書きの懸念
MongoDB 4.4より前のバージョンでは、操作にreadConcernまたはwriteConcernパラメーターを指定しない場合、デフォルト値が使用されます。 readConcernのデフォルト値はlocalですが、writeConcernのデフォルト値は {w: 1} です。 これらのデフォルト値は変更できません。 たとえば、すべてのinsert操作で "majority" 書き込みの懸念を使用する場合は、すべてのMongoDBアクセスコードでwriteConcernパラメーターを {w: majority} に設定する必要があります。
MongoDB 4.4では、setDefaultRWConcernコマンドを使用して、グローバルデフォルトのreadConcernおよびwriteConcern設定を指定できます。 構文:
db.adminCommand({
"setDefaultRWConcern" : 1、
"defaultWriteConcern" : {
"w" : "majority"
},
"defaultReadConcern" : { "level" : "majority"}
}) getDefaultRWConcernコマンドを使用して、readConcernおよびwriteConcernパラメーターの現在のグローバルデフォルト設定を取得することもできます。
低速クエリログまたは診断ログもMongoDB 4.4に保存されている場合、readConcernまたはwriteConcernで指定された読み取りまたは書き込みの懸念の出所がログに記録されます。 次の表は、読み取りまたは書き込みの懸念の可能な出所を示しています。
来歴 | 説明 |
clientSupplied | 読み取りまたは書き込みの懸念は、アプリケーションで指定されます。 |
customDefault | 読み取りまたは書き込みの懸念は、 |
implicitDefault | 読み取りまたは書き込みの懸念は、他のすべての読み取りまたは書き込みの懸念の仕様がない場合にサーバーから発生します。 |
別の可能な出所は、書き込みの懸念に利用できます。
来歴 | 説明 |
getLastErrorDefaults | 書き込みの懸念は、レプリカセットの |
新しいMongoDBシェル (ベータ版)
MongoDB Shellは、MongoDBで最も一般的なDevOpsツールの1つです。 MongoDB 4.4では、新しいバージョンのMongoDB Shellに、構文の強調表示、コマンドのオートコンプリート、読みやすいエラーメッセージなどのユーザビリティ機能が強化されています。 新しいバージョンはベータ版で利用可能です。 より多くのコマンドが開発されています。 新しいMongoDBシェルは試用目的でのみ使用することをお勧めします。 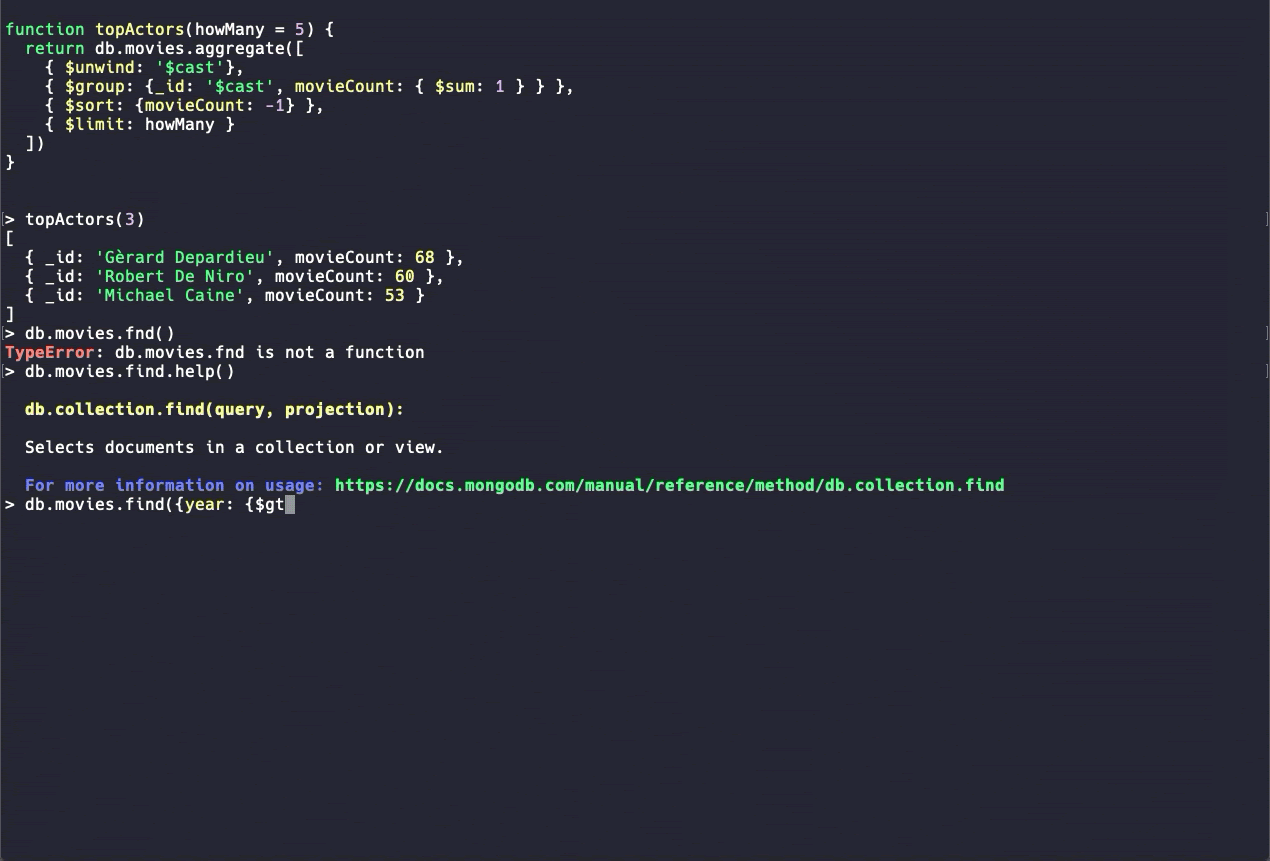
概要
MongoDB 4.4はメンテナンスリリースです。 上記の主な機能に加えて、$indexStats集約演算子の最適化、TCP高速オープン (TFO) 接続のサポート、インデックス削除の最適化などの一般的な改善が提供されています。 構造化ログ (logv2) やセキュリティのための新しい認証メカニズムなど、いくつかの大きな機能強化も利用できます。 詳細については、MongoDB 4.4のリリースノートをご参照ください。