MaxComputeでは、抽出、変換、読み込み (ETL) ツールKettleを使用してMaxComputeジョブをスケジュールできます。 Kettleを使用して、コントロールをドラッグしてデータ伝送トポロジを定義できます。 このトピックでは、Java Database Connectivity (JDBC) ドライバーを使用してKettleをMaxComputeプロジェクトに接続し、Kettleを使用してMaxComputeジョブをスケジュールする方法について説明します。
背景情報
Kettleは、Javaで書かれたオープンソースのETLツールです。 Windows、UNIX、およびLinuxオペレーティングシステムで実行でき、GUIを提供します。 Kettleは、データベースやオープンソースのビッグデータシステムなど、幅広い入出力データソースをサポートしています。 データベースには、Oracle、MySQL、およびDB2データベースが含まれます。 オープンソースのビッグデータシステムには、Hadoop分散ファイルシステム (HDFS) 、HBase、Cassandra、およびMongoDBシステムが含まれます。
Kettleでジョブを作成してMaxComputeプロジェクトに接続し、ETLワークフローに基づいてジョブをスケジュールすることができます。
前提条件
MaxComputeプロジェクトが作成されます。
詳細については、「MaxComputeプロジェクトの作成」をご参照ください。
MaxComputeプロジェクトへのアクセスに使用されるAlibaba CloudアカウントのAccessKeyペアが取得されます。
MaxComputeコンソールの右上隅にあるプロファイル画像をクリックし、AccessKey管理を選択してAccessKeyペアを取得します。
jar-with-dependenciesパッケージを含むMaxCompute JDBC driver V3.2.8以降のパッケージがダウンロードされます。このトピックでは、MaxCompute JDBCドライバーV3.2.9を使用します。
Kettleインストールパッケージがダウンロードされ、ローカルディレクトリに解凍されます。
Kettle 8.2.0.0-このトピックでは342を使用します。
手順
手順1: MaxCompute JDBCドライバのパッケージを保存する
MaxCompute JDBCドライバーのパッケージをKettleインストールディレクトリに保存します。 次に、このドライバを使用してKettleをMaxComputeプロジェクトに接続できます。
ステップ2: KettleをMaxComputeプロジェクトに接続する
KettleをMaxComputeプロジェクトに接続するための接続パラメーターを設定します。
ジョブスケジューリングワークフローを作成し、Spoonでジョブを設定します。
作成したワークフローに基づいてジョブを実行します。
SQLエディターを使用して、ジョブスケジューリング結果を照会します。
ステップ1: MaxCompute JDBCドライバのパッケージを保存する
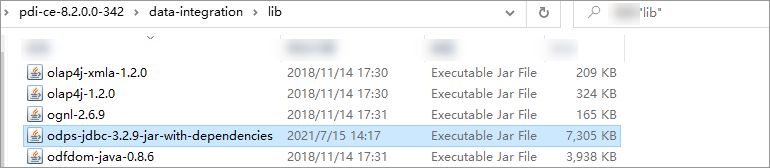
odps-jdbc-3.2.9-jar-with-dependencies.jarなどのMaxCompute JDBCドライバのパッケージを、Kettleインストールディレクトリdata-integration/libに保存します。
ステップ2: KettleをMaxComputeプロジェクトに接続する
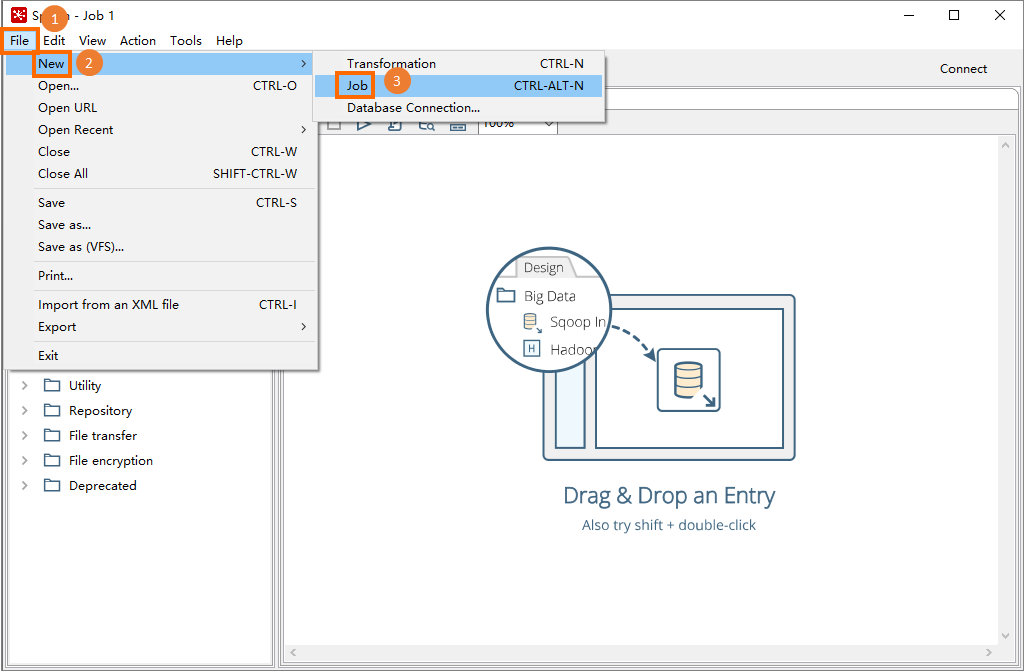
data-integrationディレクトリで、Spoon.bat(Windows) またはSpoon(macOS) をダブルクリックしてSpoonを起動します。スプーンのメインメニューバーで、 を選択してケトルジョブを作成します。 このジョブを使用して、ジョブスケジューリングワークフローを作成できます。
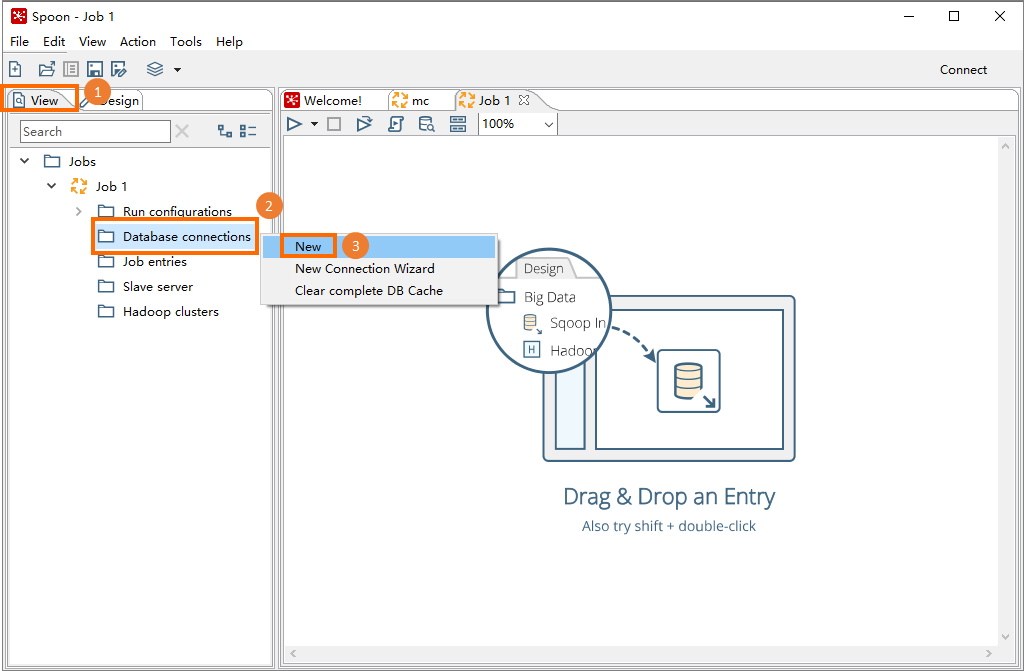
左側のウィンドウで、[表示] タブをクリックします。 表示されるナビゲーションツリーで、[データベース接続] を右クリックし、[新規] を選択します。
表示されるダイアログボックスで、[全般] タブをクリックし、接続パラメーターを設定します。 下表に、各パラメーターを説明します。
パラメーター
説明
接続名
確立するデータ接続の名前 (MaxComputeなど) 。 このパラメータは、異なるデータベースへの接続を区別するために使用されます。
回線のタイプ
確立するデータ接続のタイプ。 ドロップダウンリストから [Generic database] を選択します。
アクセス方法
接続方法。 ドロップダウンリストから [ネイティブ (JDBC)] を選択します。
方言
SQLの方言。 ドロップダウンリストからHadoop Hive 2を選択します。
カスタム接続URL
MaxComputeプロジェクトへの接続に使用されるURL。 形式は
jdbc:odps:<MaxCompute_endpoint>?project=<MaxCompute_project_name>です。 このパラメーターを設定するときに、角括弧 (<>) を削除します。 パラメーター:<MaxCompute_endpoint>: 必須です。 MaxComputeのエンドポイント。 MaxComputeプロジェクトが存在するリージョンに基づいて、このパラメーターを設定します。
異なるリージョンのMaxComputeのエンドポイントの詳細については、「エンドポイント」をご参照ください。
<MaxCompute_project_name>: 必須です。 MaxCompute プロジェクトの名前を設定します。
このパラメーターには、MaxComputeプロジェクトが対応するDataWorksワークスペースではなく、MaxComputeプロジェクトの名前を指定します。
MaxComputeコンソールで、上部のナビゲーションバーでMaxComputeプロジェクトが存在するリージョンを選択し、[プロジェクト管理] タブでMaxComputeプロジェクトの名前を表示します。
カスタムドライバークラス名
MaxComputeプロジェクトへの接続に使用されるドライバー。 このパラメーターをcom.aliyun.odps.jdbc.OdpsDriverに設定します。
ユーザー名
MaxComputeプロジェクトへのアクセスに使用されるAccessKey ID。
MaxComputeコンソールの右上隅にあるプロファイル画像をクリックし、AccessKey管理を選択してAccessKey IDを取得します。
Password
AccessKey IDに対応するAccessKeyシークレット。
[テスト] をクリックします。 次の図に示すメッセージが表示されたら、[OK] および [完了] をクリックします。
ステップ3: ジョブスケジューリングワークフローの作成
スプーンでは、[デザイン] タブでコアオブジェクト (ジョブ) を作成して関連付け、ジョブスケジューリングワークフローを作成できます。
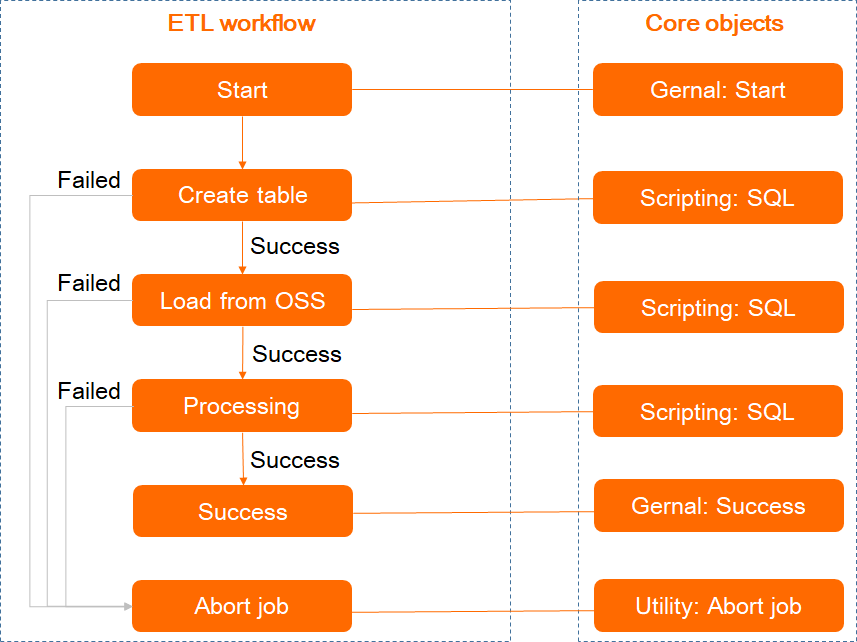
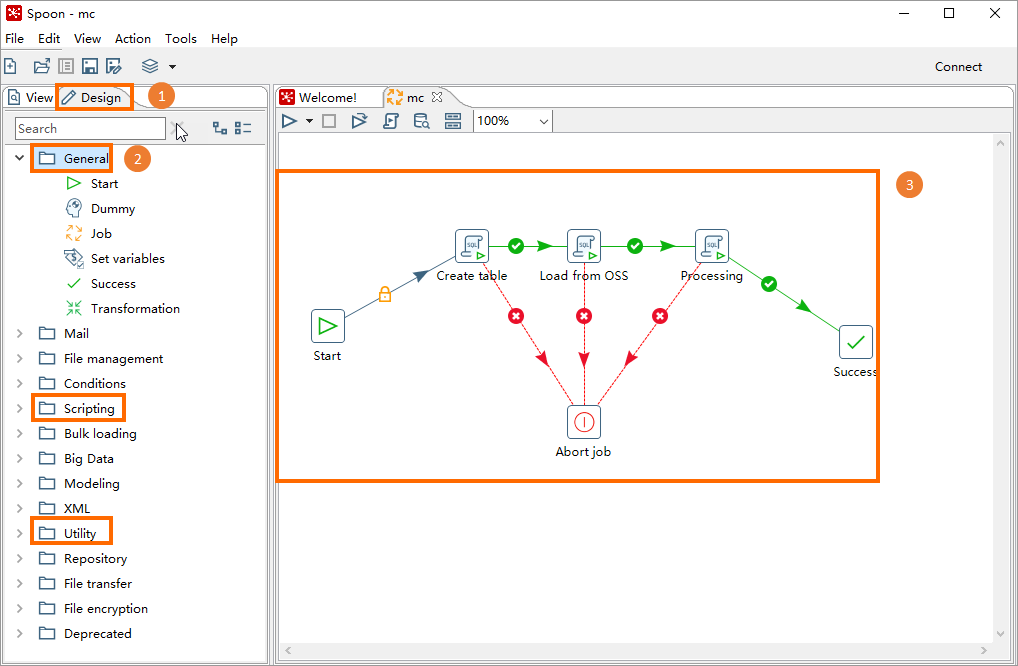
この手順では、LOADコマンドを使用してObject Storage Service (OSS) からデータをロードし、MaxCompute内部テーブルにデータを書き込むETLワークフローを作成する方法について説明します。 サンプルデータの詳細については、「組み込みエクストラクタまたはストレージハンドラを使用したデータのインポート」をご参照ください。 次の図は、ETLワークフローに含まれるコアオブジェクトを示しています。 これらのコアオブジェクトは、タイプに基づいて分類されます。
スプーンで、デザインタブをクリックします。
左側のナビゲーションウィンドウで、前の図に示すコアオブジェクトを右側のジョブウィンドウにドラッグし、次の図に示す構造に基づいて線を使用してこれらのコアオブジェクトを接続します。
2つのコアオブジェクトを接続するには、コアオブジェクトを選択し、Shiftキーを押してこのオブジェクトをターゲットオブジェクトに接続します。
右側のウィンドウでコアオブジェクト (スクリプト) を右クリックし、[編集] を選択します。 [SQL] ダイアログボックスで、次の表に示すパラメーターを設定し、[OK] をクリックします。 すべてのコアオブジェクト (スクリプト) を順番に設定します。 下表に、各パラメーターを説明します。
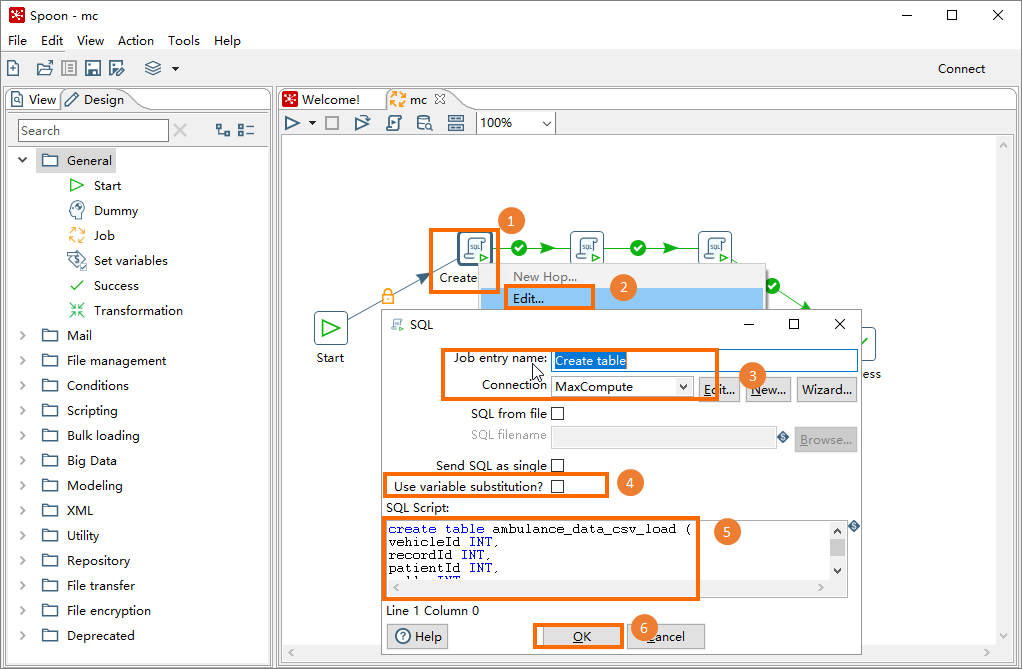
パラメーター
説明
求人エントリ名
スケジュールするジョブの名前 (テーブルの作成、OSSからのロード、処理など) 。
接続
MaxComputeなどのデータ接続の名前。 このトピックでは、データ接続はステップ2で作成したものです。 この接続は、MaxComputeプロジェクトに接続するために使用されます。
SQLを単一として送信
このオプションは選択しないでください。
SQLスクリプト
スケジュールするジョブに対応するSQLスクリプト。 このトピックでは、次のスクリプトを使用しています。
テーブルの作成
CREATE TABLE ambulance_data_csv_load ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongtitue DOUBLE, recordTime STRING, direction STRING);OSSからのロード
LOAD OVERWRITE TABLE ambulance_data_csv_load FROM LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/' STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxx:role/aliyunodpsdefaultrole', --AliyunODPSDefaultRole的ARN信息,可通过RAM角色管理页面获取。 'odps.text.option.delimiter'=',' );処理中
INSERT OVERWRITE TABLE ambulance_data_csv SELECT * FROM ambulance_data_csv_load;
ステップ4: ジョブスケジューリングワークフローの実行
ジョブタブの左上隅にある
 アイコンをクリックします。 [実行オプション] ダイアログボックスで、[実行] をクリックします。
アイコンをクリックします。 [実行オプション] ダイアログボックスで、[実行] をクリックします。 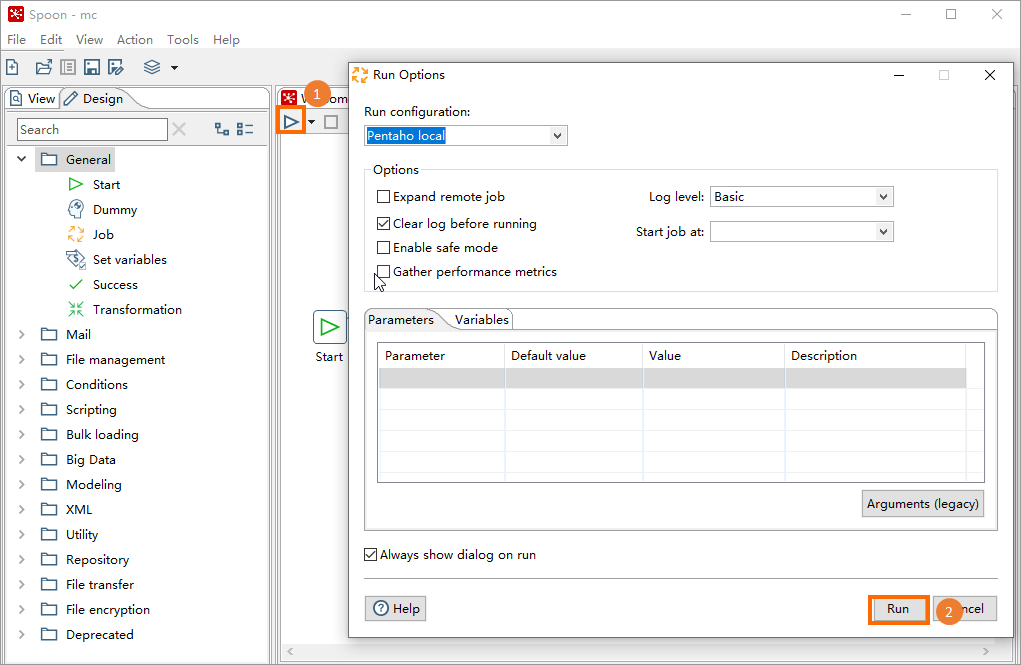
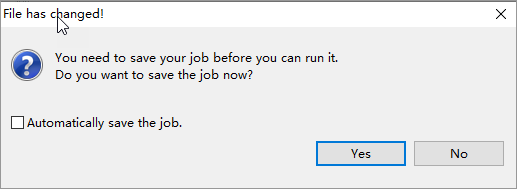
オプション: 次の図に示すメッセージが表示されたら、[はい] をクリックし、プロンプトに従ってワークフローにmcなどの名前を付けます。
[実行結果] セクションの有向非巡回グラフ (DAG) または情報に基づいて、ワークフローのステータスを照会します。 次の図に示す実行結果が表示された場合、ジョブスケジューリングワークフローは完了です。
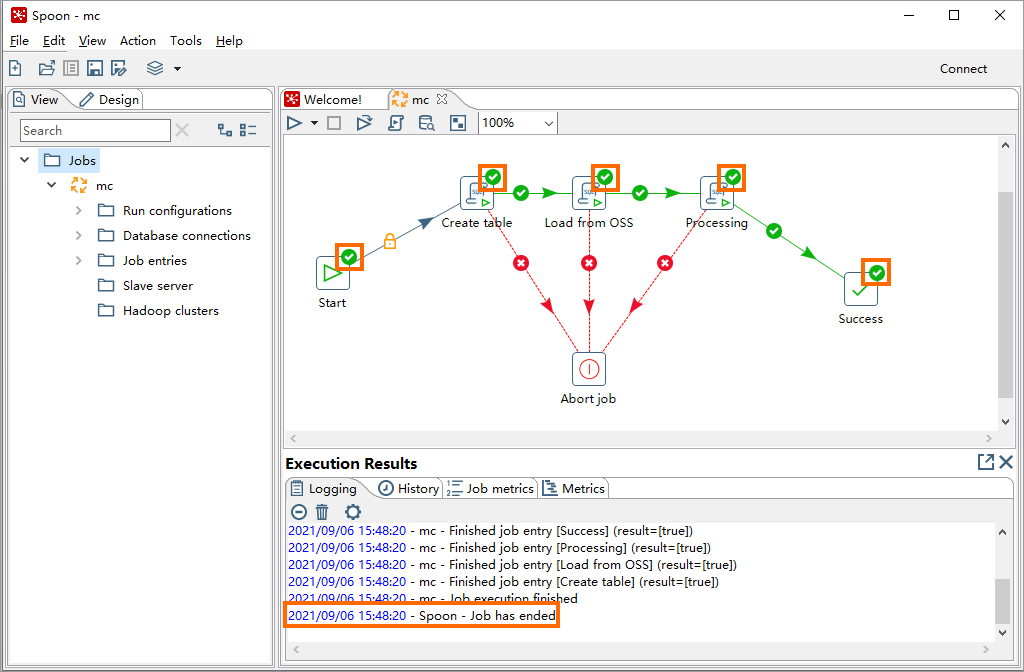
ステップ5: ジョブスケジューリング結果を表示する
ジョブスケジューリングワークフローが完了したら、SQLスクリプトを使用して、データがMaxComputeテーブルに書き込まれているかどうかを確認します。
スプーンで、[表示] タブをクリックし、作成したKettleジョブ (mcなど) の下にある [データベース接続] をクリックします。
、確立したデータ接続 (MaxComputeなど) を右クリックし、[SQL Editor] を選択します。
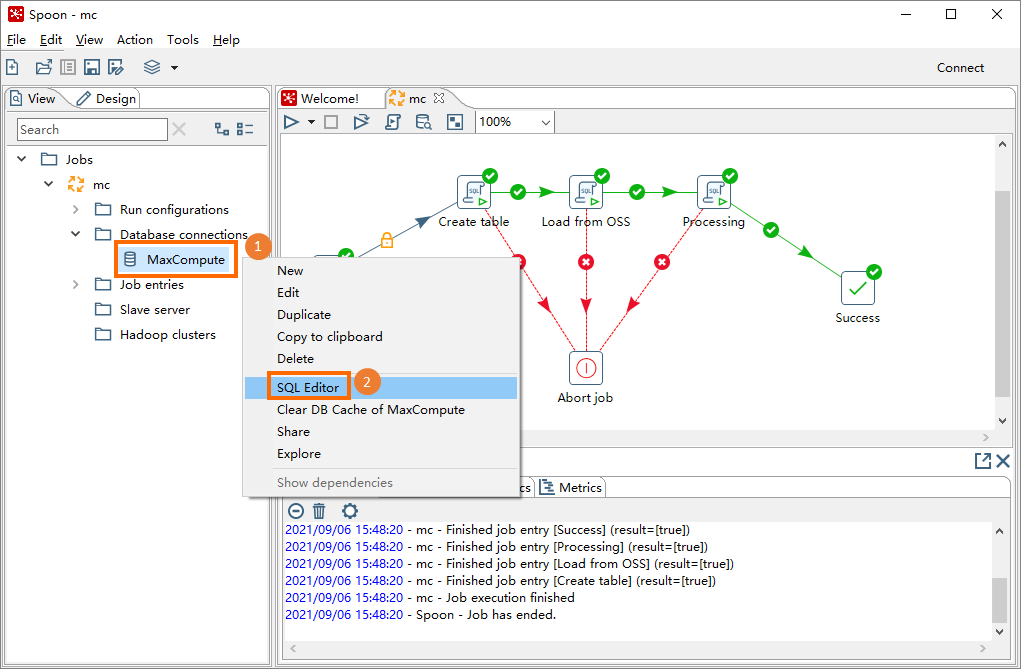
[Simple SQL editor] ダイアログボックスで、SQLスクリプトを入力し、[Execute] をクリックします。 次に、[プレビューデータの検証] ダイアログボックスでクエリ結果を表示できます。
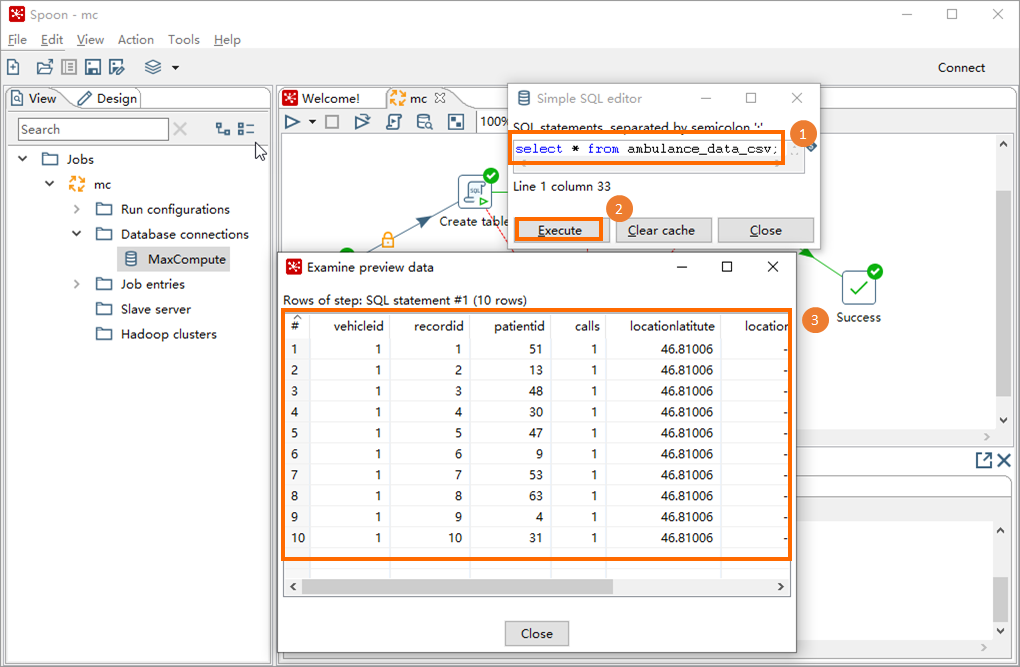 サンプルSQLスクリプト:
サンプルSQLスクリプト:SELECT * FROM ambulance_data_csv;