結合する2つのテーブルにホットキー値が含まれている場合、ロングテールの問題が発生する可能性があります。 2つのテーブルからホットキー値を抽出し、ホットキー値の結合結果と非ホットキー値の結合結果を別々に計算してから、計算されたデータを結合することができます。 この場合、SKEWJOIN HINTを使用して、2つのテーブルからホットキー値を自動または手動で抽出し、ホットキー値と非ホットキー値の結合結果を別々に計算してから、計算されたデータを結合できます。 このようにして、JOIN動作が加速される。
使用状況
SKEWJOIN HINTは、スキュー結合ヒントを追加した後にのみ実行できます。/* + skewJoin(<table_name>[(<column1_name>[,<column2_name>,...]))][(<value11 >,< value12>)[,(<value21 >,< value22>)...])]* /にSELECTステートメントを使用します。 このヒントでは、table_nameはスキューされたテーブルの名前、colume_nameはスキューされた列の名前、valueはスキューされたキー値を示します。
-- Method 1: Include the alias of the table in SKEWJOIN HINT.
select /*+ skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1;
-- Method 2: Add a hint to specify the name of the table and the names of possibly skewed columns. For example, the following statement shows that Columns c0 and c1 in Table a are skewed columns.
select /*+ skewjoin(a(c0, c1)) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2;
-- Method 3: Add a hint to specify the name of table and the names of columns and provide the skewed key values. If skewed key values are of the STRING type, enclose each value with double quotation marks ("). In the following statement, (a.c0=1 and a.c1="2") and (a.c0=3 and a.c1="4") contain skewed key values.
select /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * from T0 a join T1 b on a.c0 = b.c0 and a.c1 = b.c1 and a.c2 = b.c2;方法3は、方法1および方法2よりも効率的である。
実装
ホットキー値は、テーブルに複数回表示されるキー値です。 次の図では、赤い部分にa.c0=1とa.c1=2の10,000レコードと、a.c0=3とa.c1 = 4の9,000レコードがあります。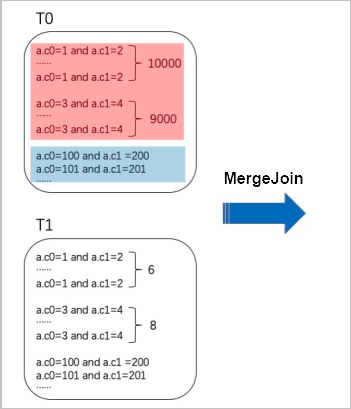
SKEWJOIN HINTを使用せず、T0テーブルとT1テーブルに大量のデータが含まれている場合、2つのテーブルに対して実行できるのはMERGE JOINステートメントだけです。 この場合、同じホットキー値が1つのノードにシャッフルされます。 その結果、データスキューが発生する。 SKEWJOIN HINTを使用した後、オプティマイザは集計を実行し、レコード数に基づいて上位20個のホットキー値を動的に取得します。 オプティマイザは、T0テーブルからホットキー値 (データa) と非ホットキー値 (データB) を別々に抽出し、T1テーブルからデータAと結合できる値 (データC) とデータaと結合できない値 (データD) を別々に抽出する。 次に、データAとデータC (データ量の少ない) に対してMAP JOIN文を実行し、データBとデータDに対してMERGE JOIN文を実行する。MAP JOIN文とMERGE JOIN文の結果に対してUNION文を実行し、次の図に示すように最終結果を生成する。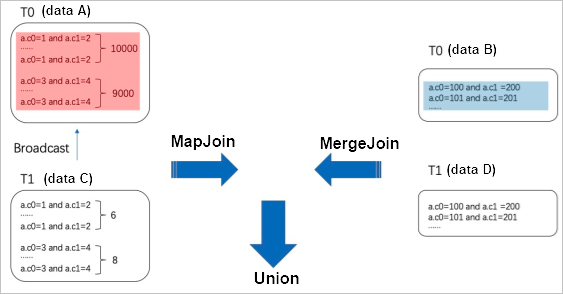
注意事項
JOINステートメントにSKEWJOIN HINTを使用する場合は、次の制限事項に注意してください。
INNER JOIN: INNER joinステートメントで、左または右のテーブルにスキュー結合ヒントを指定できます。
LEFT JOIN、SEMI JOIN、ANTI JOIN: スキュー結合ヒントは、左側のテーブルに対してのみ指定できます。
RIGHT JOIN: スキュー結合ヒントは、正しいテーブルに対してのみ指定できます。
FULL JOIN: Skew joinヒントはサポートされていません。
集計は、スキュー結合ヒントが追加された後に実行され、結合操作が遅くなります。 したがって、データスキューの原因となるjoin文にのみスキュー結合ヒントを追加することをお勧めします。 テーブルaのa join Bのクエリにスキュー結合ヒントが追加された場合、
MapJoin union all MergeJoinに似た物理実行プランが強制的に生成されます。 拡張されたMAPJOINサブプランは、Top 20(A) MapJoin (B Semi Join Top20(A))に似ています。Top20 (a)を使用してデータをフィルタリングした後も、テーブルBに大量のデータが含まれている場合、MAPJOINを使用してハッシュ結合とハッシュテーブルを作成するときに、メモリ不足 (OOM) エラーが発生する可能性があります。左側結合キーのデータ型は、SKEWJOIN HINTが追加されるJoin文の右側結合キーのデータ型と同じである必要があります。 データ型が異なる場合、SKEWJOIN HINTは無効になります。 上記の例では、a.c0とb.c0のデータ型は同じである必要があり、a.c1とb.c1のデータ型は同じである必要があります。 データ型の一貫性を確保するために、CAST関数を使用してサブクエリの結合キーを変換できます。 次のコードは例を示しています。
create table T0(c0 int, c1 int, c2 int, c3 int); create table T1(c0 string, c1 int, c2 int); -- Method 1: select /*+ skewjoin(a) */ * from T0 a join T1 b on cast(a.c0 as string) = cast(b.c0 as string) and a.c1 = b.c1; -- Method 2: select /*+ skewjoin(b) */ * from (select cast(a.c0 as string) as c00 from T0 a) b join T1 c on b.c00 = c.c0;スキュー結合ヒントが追加された後、オプティマイザは集計を実行して最初のN個のホットキー値を取得します。
set odps.optimizer.skew.join.topk.num = xx;コマンドを実行して、オプティマイザが取得できるホットキー値の数を指定できます。Skew結合ヒントを使用すると、joinステートメントに含まれる左または右のテーブルにのみヒントを追加できます。
SKEWJOIN HINTが追加されたJOIN文には、
left key = right keyを含める必要があります。 CARTESIAN JOINステートメントにSKEWJOIN HINTを追加することはできません。次のステートメントは、SKEWJOIN HINTを他のヒントとともに使用する方法を示しています。 MAPJOIN HINTが追加されたJOIN文にはSKEWJOIN HINTは追加できません。
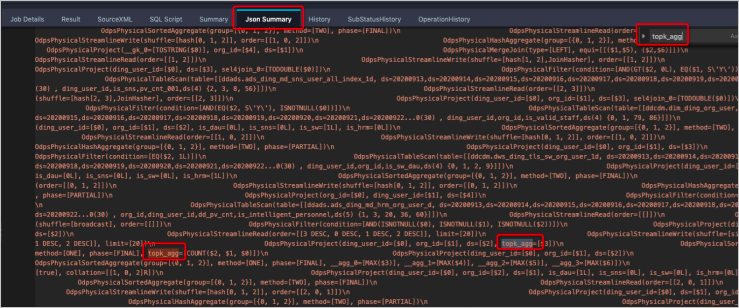
select /*+ mapjoin(c), skewjoin(a) */ * from T0 a join T1 b on a.c0 = b.c3 join T2 c on a.c0 = c.c7;LogViewの [Json Summary] タブで、topk_aggフィールドを検索できます。 次の図に示すように、このようなフィールドが存在する場合は、SKEWJOIN HINTが有効になります。