ブルームフィルタは、効率的な確率的データ構造である。 MaxComputeでは、Bloomフィルターインデックスを使用して大規模なポイントクエリを実行できます。 これにより、クエリ中の不要なデータスキャンが削減され、クエリ全体の効率とパフォーマンスが向上します。 このトピックでは、Bloomフィルターインデックスの使用方法と例について説明します。
背景情報
大規模なポイントクエリは、通常、データウェアハウスの使用シナリオで実行されます。 ユーザーが大規模なポイントクエリを実行する場合、ランダムな列に基づいてフィルター条件を指定して、条件に一致するデータを取得できます。 ビッグデータシナリオでは、結果データは、多数のファイルに分散され得る。 したがって、高性能の大規模ポイントクエリには強力な検索機能が必要です。
MaxComputeは、テーブルまたはパーティションに基づいてデータを読み取ります。 ストレージ層でのPredicate pushdownは、テーブルまたはパーティション内のファイルのローカルメタデータに基づいてデータをフィルタリングします。 ANALYZEステートメントを実行して、ローカルメタデータを取得できます。 データが複数のファイルから取得されている場合、特定の列の最小値または最大値に基づくデータフィルタリングなど、ローカルメタデータに基づくデータフィルタリングには明らかな効果はありません。
クエリする列が固定されている場合は、クラスター化テーブルを使用してフィルタリングできます。 クラスタリングキーをフィルター条件として使用すると、クエリを高速化するために読み取る必要のないバケットとバケット内のデータをすばやくフィルター処理できます。 条件フィールドに基づいて集計などの操作を実行したり、他のテーブルとの関連付けを実行したりする場合は、クラスター化によって提供されるシャッフル削除機能を使用して、クラスター化されたテーブルの利点をさらに活用できます。 ただし、クラスター化されたテーブルには、次の欠点があります。
ハッシュクラスタ化テーブルの場合、クエリ条件にすべてのクラスタ化キーが含まれている場合にのみ、データをフィルタリングできます。 範囲クラスタ化テーブルの場合、クエリ条件にクラスタ化キーのプレフィックスが含まれ、クラスタ化キーが左から右に一致する場合にのみ、データフィルタリング効果が明らかになります。 クエリ条件にクラスタリングキーのプレフィックスが含まれていない場合、データフィルタリングの効果は明らかではありません。
クエリ条件にクラスタリングキーが含まれていない場合、データをフィルタリングできません。 したがって、クラスタ化テーブルは、固定条件のないクエリには役立ちません。
データを書き込むときは、特定のフィールドに基づいてデータをシャッフルする必要があります。 これはコストを増加させる。 歪んだキーが発生すると、タスクでロングテールが発生する可能性があります。
この欠点を克服するために、MaxComputeでは、大規模なポイントクエリが実行されるシナリオのBloomフィルターインデックスが導入されています。
前提条件
MaxComputeプロジェクトが作成されます。 詳細については、「MaxComputeプロジェクトの作成」をご参照ください。
プロジェクトでスキーマの進化が有効になっています。 プロジェクトでスキーマの進化が有効になっていない場合は、プロジェクトレベルで
setproject odps.schema.evolution.enable=true;コマンドを実行して、後続の操作を正常に実行できるようにする必要があります。 コマンドを実行しないと、次のようなエラーが報告されます。Failed to run ddltask - Schema evolution DDL is not enabled in project:default.
機能の説明
ポイントクエリは、基本的に要素がセットに存在するかどうかをチェックすることです。 Bloomフィルターを使用して、ポイントクエリを効率的に実行できます。 したがって、ブルームフィルタインデックスは、より細かいデータまたはファイルプルーニングをサポートするために、データベース技術とデータレイク技術の両方に導入される。
BTreeまたはRTreeインデックスなどのデータベースインデックスを使用して、データの行を特定します。 ビッグデータシナリオでは、インデックスの作成とメンテナンスの作業負荷を軽減するために、より軽量なインデックスが必要です。 スペース効率とクエリ効率の高いBloomフィルターインデックスは、ポイントクエリシナリオでのファイルの剪定に適しています。 そのため、MaxComputeではBloomフィルターインデックスが導入されます。
クラスター化テーブルと比較して、Bloomフィルターインデックスには次の利点があります。
高効率: Bloomフィルターインデックスは、最小限のコストで不要なデータを除外できます。
高い拡張性: テーブルの1つ以上の列にBloomフィルターインデックスを作成できます。 非クラスタリングキーのBloomフィルターインデックスを作成し、Bloomフィルターインデックスをクラスター化インデックスと共に使用することもできます。
明らかなフィルタリング効果: ブルームフィルタインデックスは、高濃度でデータ集約的なシナリオで明らかなデータフィルタリング効果を持ちます。
利点と欠点
利点
高効率: 挿入およびクエリ操作のリソース消費量は、通常のインデックスのリソース消費量よりも少なくなります。
省スペース: ビットアレイが使用されます。 2 32= 4294967296。 これは、4,200万ビットのビットアレイが512 MBのメモリスペースしか占有しないことを示しています。
説明ビット配列によって占有されるメモリスペースは、次の式を使用して計算されます。
4294967296/8/1024/1024 = 512 MB
デメリット
特定の偽陽性確率 (FPP) が存在する。 セット外の要素は、セット内の要素と誤って見なされる可能性があります。 ただし、ほとんどのシナリオでは、空のファイルを読み取るためのリソース消費は全体的な効率に影響を与えず、結果は最終的なビジネスの正確性に影響を与えません。
シナリオ
テーブル内の1つ以上の列を条件として使用してポイントクエリのフィルタリングを実行する場合、明らかなフィルタリング効果を持つクエリ列にBloomフィルターインデックスを作成できます。
クラスター化されたテーブルのフィールドに対して、クラスター化キー以外のポイントクエリのフィルタリングを実行する場合は、クエリ列にBloomフィルターインデックスを作成できます。
クラスタ化キー、ソートキー、またはZorder関数を使用してクラスタ化テーブル内のデータをソートした後、挿入された列にBloomフィルターインデックスを作成して、データをさらにフィルタリングできます。
制限事項
ブルームフィルタインデックスは、
=やinなどの等価比較演算子に適しています。 ブルームフィルタインデックスは、> 、>=、<、<=などの演算子が関与する範囲クエリと、IS NULLおよびIS not NULLが関与するクエリではサポートされません。フィルタリング効果は、データ分布に依存する。 データ分布が離散的である場合、Bloomフィルターインデックスを使用してもデータフィルター効果は明らかではありません。
ブルームフィルタインデックスは、DECIMAL、INTERVAL_DAY_TIME、INTERVAL_YEAR_MONTH、またはSTRUCT、MAP、ARRAY、JSONなどの複合型ではサポートされていません。
課金
Bloomフィルターインデックスが作成されると、インデックスはストレージスペースを占有します。 インデックスストレージは、Apsara Distributed File System (Pangu) のストレージ使用量に対して課金されます。 したがって、インデックスストレージは標準ストレージとして課金されます。
インデックスの作成と使用により、追加のコンピューティングワークロードがトリガーされます。 クエリの場合、システムは、インデックスファイルに基づいて、クエリ対象のデータが格納されているファイルに関する情報を計算します。 次に、システムは、クエリ実行計画段階でインデックス計算結果に基づいて入力データをさらにフィルタリングして、入力データの量を削減し、最終計算結果を取得する。 インデックス計算とクエリの両方にコンピューティング料金が発生します。
ブルームフィルタインデックスは、サブスクリプションリソースを消費するジョブの実行を高速化できます。 インデックスの作成とインデックス計算の実行に使用されるリソースは、すべてサブスクリプションリソースです。 したがって、商品化はサブスクリプションジョブのコストを増加させません。
SQL操作はインデックス関連のタスクをトリガーします。 次の表に、SQL操作によってトリガーされるインデックス関連のタスクを示します。
SQL操作
トリガータスク
インデックス関連タスクに関連する入力データの量
課金
CREATE
DDL操作はインデックス作成タスクをトリガーしません。
非該当
料金は発生しません。
リビルド
インデックスが作成または再構築されます。
インデックスが存在する場合、REBUILD操作はインデックスの再構築をトリガーします。
インデックスが存在しない場合、REBUILD操作はインデックス作成をトリガーします。
インデックスを再構築すると、読み取り操作と書き込み操作がインデックス列と他の列に対して同時に実行されます。 したがって、入力データ量は、再構築されたインデックスのクエリ条件に基づいてデータがフィルタリングされた後の完全なデータの量です。
インデックスの課金式:
従量課金制SQLジョブの単価 × 複雑さ1 × インデックス関連タスクに関連する入力データの量SQLクエリの課金方法: 一般的なSQLジョブの従量課金ルールが適用されます。
INSERT
挿入されたデータに対してインデックスが作成される。
クエリに対してSELECTステートメントが実行されます。
SELECT文を使用して照会するテーブルのインデックス列のデータ量。
SELECT
インデックス計算を使用するクエリタスクは、後続のSELECTステートメントでデータをフィルタリングするために使用される情報を生成します。
SELECTステートメントは、作成されたインデックスに基づいて実行されます。
インデックスファイルのデータ量。
指示
このセクションでは、Bloomフィルターインデックスを生成、使用、クエリ、および削除する方法と、Bloomフィルターインデックスのプロパティを変更する方法について説明します。
Bloomフィルターインデックスの生成
Bloomフィルターインデックスの作成
構文:
CREATE BLOOMFILTER INDEX <index_name>
ON TABLE <table_name>
FOR COLUMNS(<column_name>)
IDXPROPERTIES('numitems'='xxx', 'fpp' = 'xx')
[COMMENT 'idxcomment']
;下表に、各パラメーターを説明します。
パラメーター | 説明 |
index_name | 指定されたインデックスの名前。 |
table_name | インデックスが属するテーブル名 |
column_name | インデックスを作成する列の名前。 |
numitems | ブルームフィルタに格納されている要素の推定数。 推定数は、ブルームフィルタの容量を反映する。 これにより、作成中に予想される数の要素を格納するのに十分なメモリスペースが確保されます。 このパラメーターは、ブルームフィルターで使用されるビットの総数に影響し、フィルターの品質にとって重要です。
値は0より大きくなければなりません。 インデックス列の個別の値の数に基づいて推定を実行できます。 最大値は10000000を超えることはできません。 |
fpp | FPP。 有効値: |
Bloomフィルターインデックスは、一度にテーブル内の1つの列に対してのみ作成できます。 テーブル内の複数の列に対してブルームフィルターインデックスを個別に作成できます。
Bloomフィルターインデックスのマージ
増分データに対して追加の操作を実行する必要はありません。 Bloomフィルターインデックスをマージするには、データ挿入文を実行するだけです。
構文:
INSERT OVERWRITE TABLE <table_name> [PARTITION <partition_spec>]
SELECT ......パラメーター:
table_name: インデックスが属するテーブルの名前。
pt_spec: データを挿入するパーティションに関する情報。 定数のみがサポートされています。 関数などの式はサポートされていません。 形式:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)
Bloomフィルターインデックスを持つテーブルにデータを挿入すると、データファイルのローカルのBloomフィルターインデックスデータが増分的に生成され、ストレージ層での述語のプッシュダウンがサポートされます。 次に、システムはBloomfilterAutoMergeTaskを開始して、Bloomフィルターインデックスを新しいBloomフィルターインデックスファイルに自動的にマージします。 このようにして、システムは計画段階でデータをフィルタリングして、タスクに必要なリソースをより正確に開始できます。 LogViewの [Json Summary] タブに次のキーワードが表示されている場合、Bloomフィルターインデックスは正常にマージされます。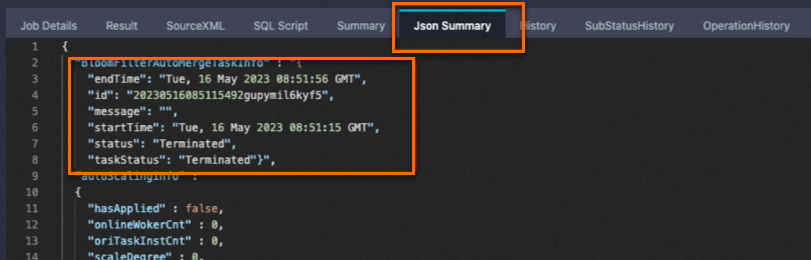
LogViewの [SubStatusHistory] タブで、Bloomフィルターインデックスのマージにかかった時間を表示できます。
データ書き込みタスクは、マージ操作が成功したかどうかにかかわらず、期待どおりに完了します。
システム上の理由でBloomフィルターインデックスのマージに失敗した場合、計画段階で新しいデータをフィルターすることはできません。 新しいデータのローカルブルームフィルタインデックスデータは、データをフィルタリングするためのストレージレイヤでの述語プッシュダウンを依然としてサポートすることができる。 実行計画を使用して、Bloomフィルターインデックスが使用されているかどうかを判断できます。 Bloomフィルターインデックスが使用されていない場合は、クエリ中に無効なパーティションインデックスを再構築できます。
動的パーティションは自動マージをサポートしていません。 データの書き込み後、更新されたパーティションのインデックスを手動で再構築する必要があります。
上の図に示す自動マージタスクのステータスがFailedの場合、次のマージ文を明示的に実行する必要があります。 一度に再構築できるパーティションインデックスは1つだけです。
ALTERTABLE <table_name> [PARTITION <partition_spec>] REBUILD BLOOMFILTER INDEX;
Bloomフィルターインデックスの使用
データをクエリする前に、次のコマンドを実行して、Bloomフィルターインデックス機能を有効にします。
SET odps.sql.enable.bloom.filter.index=true;Bloomフィルターインデックス機能を有効にすると、クエリ中にファイルプルーニング用のジョブが追加されます。 プルーニングされたファイルには、タスクが読み取る必要のあるデータが含まれます。
odps.sql.enable.bloom.filter.indexパラメーターを指定しない場合、計画段階でファイルプルーニングを実行できません。 しかしながら、システムは、ローカルブルームフィルタインデックスデータに基づいてデータをフィルタリングするために、ストレージレイヤにおいて述語プッシュダウンを依然として使用することができる。 ベータリリース中、odps.sql.enable.bloom.filter.indexパラメーターのデフォルト値はfalseです。 ベータリリース後、オンライン使用状況に応じてデフォルト値がtrueに変更される場合があります。
場合によっては、ブルームフィルタインデックスに基づくデータフィルタリングは、明らかな効果を有さない。 たとえば、結果データが複数の結果ファイルに分散されている場合、ファイルプルーニングを実行してファイルを効果的にフィルタリングすることはできません。 この場合、このパラメーターをtrueに設定すると、追加のインデックス検索タスクが実行されます。 この結果、タスクの性能が低下するおそれがある。 この状況では、このパラメーターをfalseに設定できます。
次のコードは、Bloomフィルターインデックスを有効にする方法の例を示しています。
SET odps.sql.enable.bloom.filter.index=true;
SELECT * FROM bloomfilter_index_test WHERE key=392 AND value="val_392";次のLogViewスナップショットは、job_1がファイルの剪定にBloomフィルターインデックスを使用するインデックスジョブであることを示しています。
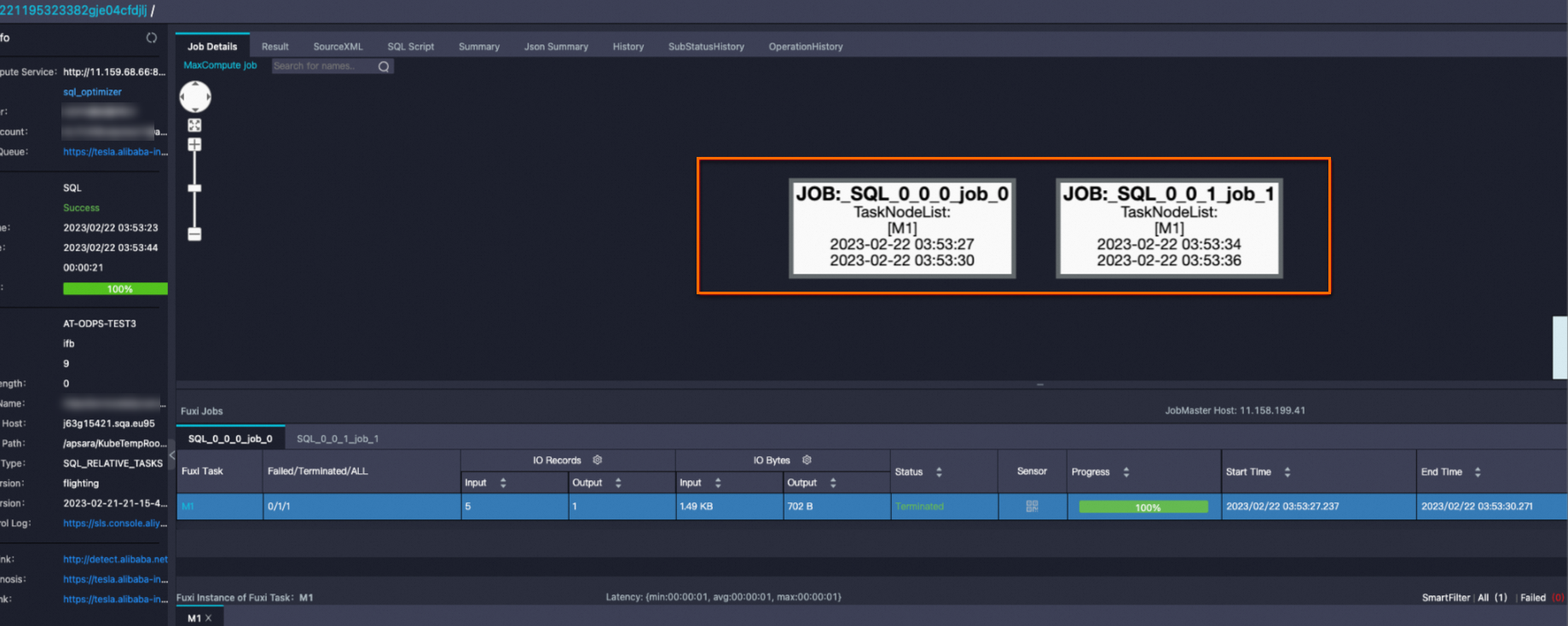
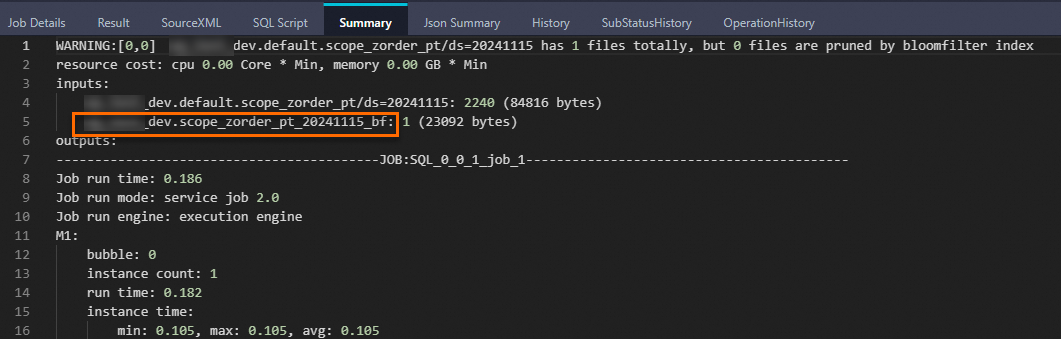
[サマリ] タブの名前にbfが付いているテーブルは、Bloomフィルターインデックスファイルに対応する仮想テーブルです。
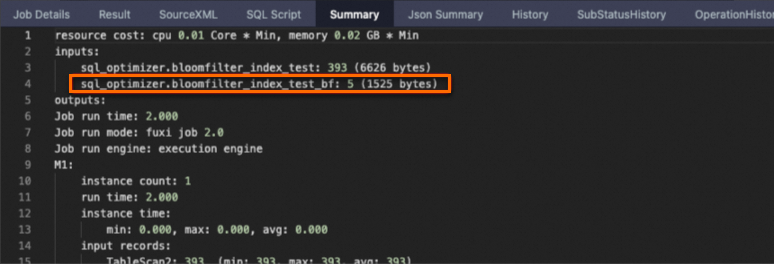
大量のデータが存在する場合、生成されるブルームフィルタインデックスファイルのサイズが過度に大きくなり得る。 この場合、MaxComputeはファイルプルーニングの分散ジョブを開始します。
テーブルのBloomフィルターインデックスの照会
SHOW INDEXES ON <table_name>;パラメーター:
table_name: インデックスが属するテーブルの名前。
Bloomフィルターインデックスの削除
DROP INDEX [IF EXISTS] <idx_name> ON TABLE <table_name>;パラメーター:
idx_name: インデックスの名前。
table_name: インデックスが属するテーブルの名前。
Bloomフィルターインデックスのプロパティの変更
ALTER INDEX <idx_name> ON <table_name>
SET IDXPROPERTIES(['comment' = 'a'], ['fpp' = '0.01']);パラメーター:
idx_name: インデックスの名前。
table_name: インデックスが属するテーブルの名前。
例
例1: 共通のパーティションテーブルに基づいてブルームフィルターインデックスを作成する
データを準備します。
SET odps.namespace.schema=true; SELECT * FROM bigdata_public_dataset.TPCDS_10G.call_center;call_center_testという名前のパーティションテーブルを作成します。
CREATE TABLE IF NOT EXISTS call_center_test( cc_call_center_sk BIGINT NOT NULL, cc_call_center_id CHAR(16) NOT NULL, cc_rec_start_date DATE, cc_rec_end_date DATE, cc_closed_date_sk BIGINT, cc_open_date_sk BIGINT, cc_name VARCHAR(50), cc_class VARCHAR(50), cc_employees BIGINT, cc_sq_ft BIGINT, cc_hours CHAR(20), cc_manager VARCHAR(40), cc_mkt_id BIGINT, cc_mkt_class CHAR(50), cc_mkt_desc VARCHAR(100), cc_market_manager VARCHAR(40), cc_division BIGINT, cc_division_name VARCHAR(50), cc_company BIGINT, cc_company_name CHAR(50), cc_street_number CHAR(10), cc_street_name VARCHAR(60), cc_street_type CHAR(15), cc_suite_number CHAR(10), cc_city VARCHAR(60), cc_county VARCHAR(30), cc_state CHAR(2), cc_zip CHAR(10), cc_country VARCHAR(20), cc_gmt_offset DECIMAL(5,2), cc_tax_percentage DECIMAL(5,2) ) PARTITIONED BY (ds STRING ) ;インデックスを作成します。
CREATE BLOOMFILTER INDEX call_center_test_idx01 ON table call_center_test FOR columns(cc_call_center_sk) IDXPROPERTIES('fpp' = '0.03', 'numitems'='1000000') COMMENT 'cc_call_center_sk index';データをインポートする。
パブリックデータセットの
bigdata_public_dataset.TPCDS_10G.call_centerテーブルのデータをcall_center_testテーブルにインポートします。SET odps.namespace.schema=true; INSERT OVERWRITE TABLE call_center_test PARTITION (ds='20241115') SELECT * FROM bigdata_public_dataset.TPCDS_10G.call_center LIMIT 10000;LogViewの [Json Summary] タブに次のキーワードが表示されている場合、Bloomフィルターインデックスは正常にマージされます。
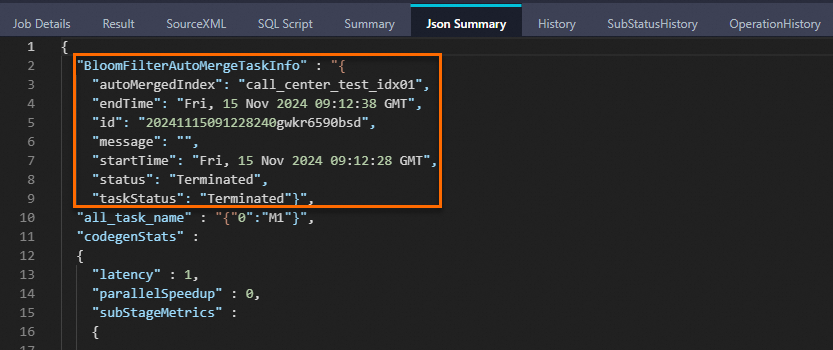
データの照会
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM call_center_test WHERE cc_call_center_sk =10 AND ds='20241115';次の応答が返されます。
+-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+----------------------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+ | cc_call_center_sk | cc_call_center_id | cc_rec_start_date | cc_rec_end_date | cc_closed_date_sk | cc_open_date_sk | cc_name | cc_class | cc_employees | cc_sq_ft | cc_hours | cc_manager | cc_mkt_id | cc_mkt_class | cc_mkt_desc | cc_market_manager | cc_division | cc_division_name | cc_company | cc_company_name | cc_street_number | cc_street_name | cc_street_type | cc_suite_number | cc_city | cc_county | cc_state | cc_zip | cc_country | cc_gmt_offset | cc_tax_percentage | ds | +-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+--------------+-------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+ | 10 | AAAAAAAAKAAAAAAA | 1998-01-01 | 2000-01-01 | NULL | 2451050 | Hawaii/Alaska | large | 187 | 95744 | 8AM-8AM | Gregory Altman | 2 | Just back responses ought | As existing eyebrows miss as the matters. Realistic stories may not face almost by a | James Mcdonald | 3 | pri | 3 | pri | 457 | 1st | Boulevard | Suite B | Midway | Walker County | AL | 31904 | United States | -6 | 0.02 | 20241115 | +-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+----------------------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+次のLogViewスナップショットは、Bloomフィルターインデックスが有効になったことを示しています。 名前の末尾に
bfが付いているテーブルは、Bloomフィルターインデックスファイルに対応する仮想テーブルです。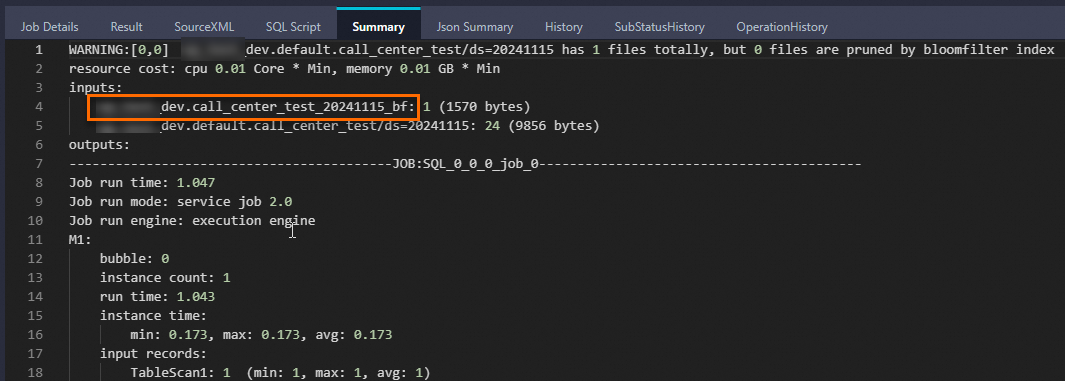
テーブルのBloomフィルターインデックスを照会します。
SHOW INDEXES ON call_center_test;次の応答が返されます。
ID = 20241115093930589g9biyii**** {"Indexes": [{ "id": "aabdaeb10a7b4e99a94716dabad8****", "indexColumns": [{"name": "cc_call_center_sk"}], "name": "call_center_test_idx01", "properties": { "comment": "cc_call_center_sk index", "fpp": "0.03", "numitems": "1000000"}, "type": "BLOOMFILTER"}]} OKBloomフィルターインデックスのプロパティを変更します。
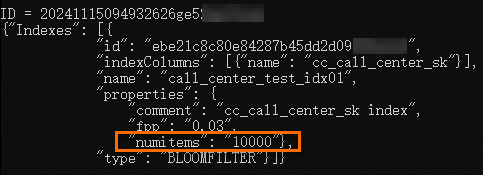
前の手順で返された情報に基づいて、
numitemsの元のプロパティ値が1000000されます。 次のステートメントを実行して、プロパティ値を10000に変更し、変更結果を表示します。-- Change the property value. ALTER INDEX call_center_test_idx01 ON call_center_test SET IDXPROPERTIES('fpp' = '0.03', 'numitems'='10000'); -- View the property. SHOW INDEXES ON call_center_test;次の結果が返されます。
例2: ハッシュクラスタ化パーティションテーブルに基づいてBloomフィルターインデックスを作成する
データを準備します。
scope_tmpという名前のテーブルを作成します。
CREATE TABLE if NOT EXISTS scope_tmp( phone STRING, card STRING, machine STRING, geohash STRING);MaxComputeクライアント (odpscmd) でTunnelコマンドを実行し、scope_tmpテーブルにデータをアップロードします。 次のサンプルコマンドを使用して、MaxComputeクライアントの
binディレクトリにscope2.csvファイルをアップロードします。Tunnel upload scope2.csv scope_tmp;
scope_hash_ptという名前のパーティションテーブルを作成します。
CREATE TABLE scope_hash_pt ( phone STRING, card STRING, machine STRING, geohash STRING ) PARTITIONED BY (ds STRING) clustered by (phone) sorted by (card) into 512 buckets;scope_hash_ptパーティションテーブルのインデックスを作成します。
CREATE BLOOMFILTER INDEX scope_hash_pt_index01 ON TABLE scope_hash_pt FOR columns(card) IDXPROPERTIES('fpp' = '0.03', 'numitems'='1000000') COMMENT 'card index';データをインポートする。
INSERT OVERWRITE TABLE scope_hash_pt PARTITION (ds='20241115') SELECT * FROM scope_tmp;LogViewの [Json Summary] タブに次のキーワードが表示されている場合、Bloomフィルターインデックスは正常にマージされます。
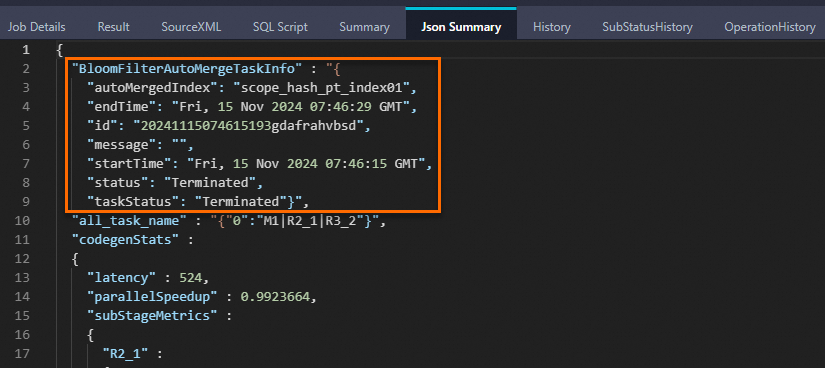
scope_hash_ptテーブルのデータを照会します。
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM scope_hash_pt WHERE card='073415764266290' and ds='20241115';次の応答が返されます。
+-------------+-----------------+----------------+------------+------------+ | phone | card | machine | geohash | ds | +-------------+-----------------+----------------+------------+------------+ | 1576426**** | 073415764266290 | 51133960245770 | fWbDDsf | 20241115 | +-------------+-----------------+----------------+------------+------------+次のLogViewスナップショットは、Bloomフィルターインデックスが有効になったことを示しています。 名前の末尾に
bfが付いているテーブルは、Bloomフィルターインデックスファイルに対応する仮想テーブルです。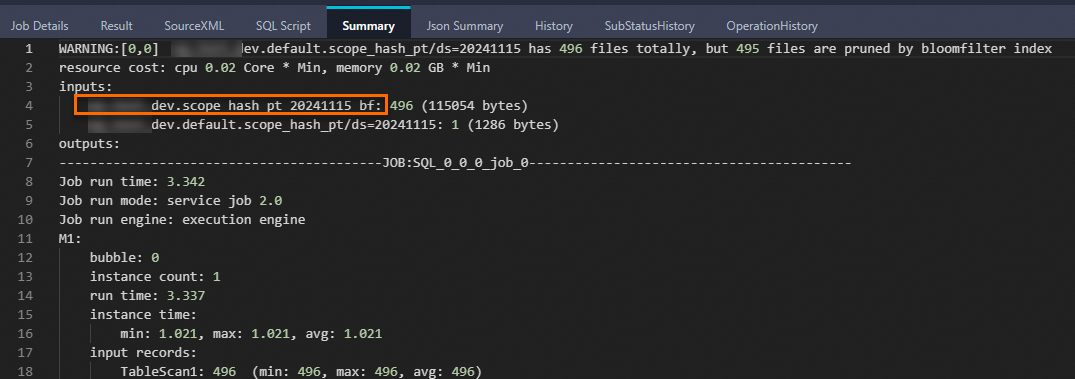
例3: パーティションテーブルのZorderデータソートに基づいてBloomフィルターインデックスを作成する
データを準備します。 詳細については、「例2: ハッシュクラスター化パーティションテーブルに基づいてブルームフィルターインデックスを作成する」の手順1をご参照ください。
scope_zorder_ptという名前のパーティションテーブルを作成します。
CREATE TABLE scope_zorder_pt( phone STRING, card STRING, machine STRING, geohash STRING, zvalue BIGINT ) PARTITIONED BY (ds STRING) ;インデックスを作成します。
CREATE BLOOMFILTER INDEX scope_zorder_pt_index01 ON TABLE scope_zorder_pt FOR COLUMNS (card) IDXPROPERTIES('fpp' = '0.05', 'numitems'='1000000') COMMENT 'idxcomment';データをインポートする。
次のJARパッケージをダウンロードし、コンピューターの
D:\に保存します。次のコマンドを実行して、2つのJARパッケージをリソースとしてアップロードします。
-- Add resources. ADD JAR D:\odps-zorder-1.0-SNAPSHOT.jar; ADD JAR D:\odps-zorder-1.0-SNAPSHOT-jar-with-dependencies.jar;次のステートメントを実行して関数を作成します。
CREATE FUNCTION zorder AS 'com.aliyun.odps.zorder.evaluateZValue2WithSize' USING ' odps-zorder-1.0-SNAPSHOT-jar-with-dependencies.jar';関数を使用して、scope_zorder_ptパーティションテーブルにデータを書き込みます。
-- Set the odps.sql.validate.orderby.limit parameter to false. SET odps.sql.validate.orderby.limit=false; -- Write data. INSERT OVERWRITE TABLE scope_zorder_pt PARTITION (ds='20241115') SELECT *,zorder(HASH(phone), 100000000, HASH(card), 100000000) AS zvalue FROM scope_tmp ORDER BY zvalue;LogViewの [Json Summary] タブに次のキーワードが表示されている場合、Bloomフィルターインデックスは正常にマージされます。
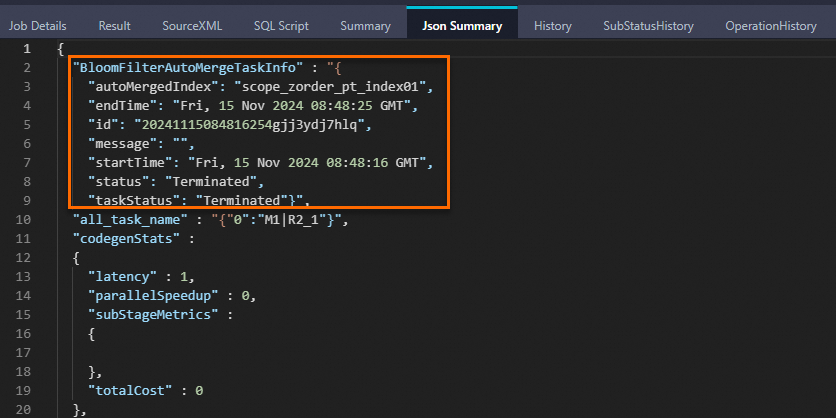
データの照会
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM scope_zorder_pt WHERE card='073415764266290' AND ds='20241115';次の応答が返されます。
+-------------+-----------------+----------------+------------+---------------------+------------+ | phone | card | machine | geohash | zvalue | ds | +-------------+-----------------+----------------+------------+---------------------+------------+ | 1576426**** | 073415764266290 | 51133960245770 | fWbDDsf | 3590549286038929408 | 20241115 | +-------------+-----------------+----------------+------------+---------------------+------------+次のLogViewスナップショットは、Bloomフィルターインデックスが有効になったことを示しています。 名前の末尾に
bfが付いているテーブルは、Bloomフィルターインデックスファイルに対応する仮想テーブルです。