このトピックでは、DataWorks データ統合のデータ同期機能を使用して、パーティションを自動的に作成し、ビッグデータコンピューティングサービスである RDS から MaxCompute にデータを動的に移行する方法について説明します。
準備
DataWorks 環境を準備します。
DataWorks でワークフローを作成します。この例では、DataWorks の基本モードを使用します。詳細については、「ワークフローの作成」をご参照ください。
データソースを追加します。
ソースとして MySQL データソースを追加します。詳細については、「MySQL データソースの設定」をご参照ください。
RDS からデータを受信する宛先として MaxCompute データソースを追加します。詳細については、「MaxCompute データソースの設定」をご参照ください。
パーティションの自動作成
前提条件を完了すると、RDS から MaxCompute に毎日データを同期し、日次パーティションを自動的に作成できます。データ同期タスクの操作と構成の詳細については、「DataWorks でのデータ開発と O&M」をご参照ください。
この例では、DataWorks の基本モードを使用します。ワークスペースを作成するとき、[DataStudio のパブリックプレビューに参加] オプションはデフォルトで選択解除されています。この例は、パブリックプレビューのワークスペースには適用されません。
DataWorks コンソールにログインします。
MaxCompute で宛先テーブルを作成します。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。
ワークスペースの [アクション] 列で、[クイックアクセス] > [データ開発] をクリックします。
ワークフローを右クリックし、 を選択します。
[テーブルの作成] ページで、エンジンインスタンス、スキーマ、パスを選択し、[テーブル名] を入力してから [作成] をクリックします。
テーブル編集ページで、
 アイコンをクリックして DDL モードに切り替えます。
アイコンをクリックして DDL モードに切り替えます。[DDL] ダイアログボックスで、次の文を入力してテーブルを作成し、[テーブルスキーマの生成] をクリックします。表示される [確認] ダイアログボックスで、[OK] をクリックします。
CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT 'ユーザー ID', gender STRING COMMENT '性別', age_range STRING COMMENT '年齢範囲', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );[本番環境に送信] をクリックします。
オフライン同期ノードを作成します。
データ分析ページに移動します。指定したワークフローを右クリックし、 を選択します。
[ノードの作成] ダイアログボックスで、[ノード名] を入力し、[送信] をクリックします。
データソース、リソースグループ、宛先を選択し、接続性をテストします。
データソース: 作成した MySQL データソースを選択します。
リソースグループ: データ統合専用リソースグループを選択します。
宛先: 作成した MaxCompute データソースを選択します。
[次へ] をクリックしてタスクを構成します。

パーティションパラメーターを構成します。
右側のナビゲーションウィンドウで、[スケジュール] をクリックします。
[スケジューリングパラメーター] セクションで、パラメーターを設定します。デフォルトでは、パラメーター値はシステム時間パラメーター
${bizdate}です。値は yyyymmdd フォーマットです。説明デフォルトのパラメーター値は、[宛先] セクションの [パーティション情報] の値に対応します。移行タスクがスケジュールされて実行されると、宛先テーブルのパーティション値は、タスク実行日の前日の日付に自動的に置き換えられます。デフォルトでは、タスクは前日の業務データを処理します。この日付はデータタイムスタンプとも呼ばれます。タスク実行日をパーティション値として使用するには、カスタムパラメーターを使用する必要があります。
カスタムパラメーター設定: 日付を指定し、フォーマットを構成できます。次の例は、これを行う方法を示しています。
N 年後:
$[add_months(yyyymmdd,12*N)]N 年前:
$[add_months(yyyymmdd,-12*N)]N か月前:
$[add_months(yyyymmdd,-N)]N 週間後:
$[yyyymmdd+7*N]N か月後:
$[add_months(yyyymmdd,N)]N 週間前:
$[yyyymmdd-7*N]N 日後:
$[yyyymmdd+N]N 日前:
$[yyyymmdd-N]N 時間後:
$[hh24miss+N/24]N 時間前:
$[hh24miss-N/24]N 分後:
$[hh24miss+N/24/60]N 分前:
$[hh24miss-N/24/60]
説明角括弧 ([]) を使用して、カスタム変数の値を計算する数式を編集します。たとえば、
key1=$[yyyy-mm-dd]です。デフォルトでは、カスタム変数の単位は日です。たとえば、
$[hh24miss-N/24/60]は(yyyymmddhh24miss-(N/24/60 × 1 日))の結果を示します。結果は hh24miss フォーマットです。add_months の単位は月です。たとえば、
$[add_months(yyyymmdd,12*N)-M/24/60]は(yyyymmddhh24miss-(12 × N × 1 か月))-(M/24/60 × 1 日)の結果を示します。結果はyyyymmddフォーマットです。
 アイコンをクリックしてコードを実行します。
アイコンをクリックしてコードを実行します。[操作ログ] で結果を表示できます。
データバックフィル実験
現在の実行日より前に生成された大量の既存データがある場合は、自動同期とパーティション分割を実行する必要があります。これを行うには、DataWorks の [オペレーションセンター] に移動し、現在のデータ同期ノードを選択して、[データバックフィル] 機能を使用します。
RDS の既存データを日付でフィルタリングします。
同期ノードの [データソース] セクションで [データフィルタリング] 条件を設定できます。たとえば、条件を
${bizdate}に設定します。データバックフィルを実行します。詳細については、「データバックフィル操作の実行とデータバックフィルインスタンスの表示 (新バージョン)」をご参照ください。
実行ログで RDS からのデータ抽出の結果を表示します。
実行ログには、MaxCompute がパーティションを自動的に作成したことが示されます。
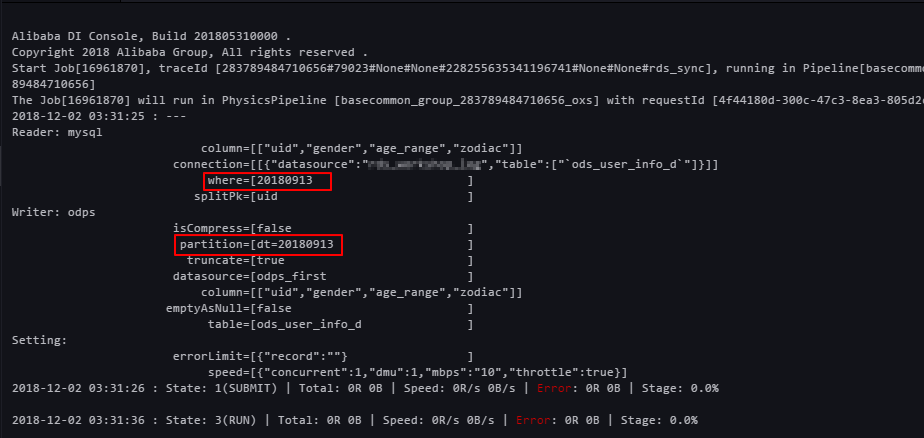
結果を検証します。MaxCompute クライアントで次のコマンドを実行して、データ書き込みステータスを表示します。
SELECT count(*) from ods_user_info_d where dt = 20180913;
ハッシュを使用して非日付フィールドによるパーティション分割を実装する
大量のデータがある場合、または日付フィールドの代わりに都道府県などの非日付フィールドに基づいて初期の完全データセットをパーティション分割する場合、データ統合はパーティションを自動的に作成できません。この場合、RDS のフィールドにハッシュ関数を適用して、同じフィールド値を持つレコードを対応する MaxCompute パーティションに自動的に格納できます。
すべてのデータを MaxCompute の一時テーブルに同期し、SQL スクリプトノードを作成します。次のコマンドを実行します。
drop table if exists ods_user_t; CREATE TABLE ods_user_t ( dt STRING, uid STRING, gender STRING, age_range STRING, zodiac STRING); --MaxCompute テーブルのデータを一時テーブルに格納します。 insert overwrite table ods_user_t select dt,uid,gender,age_range,zodiac from ods_user_info_d;mysql_to_odps という名前の単純な同期タスクノードを作成します。このタスクは、パーティションを設定せずに、すべてのデータを RDS から MaxCompute に同期します。
SQL 文を使用して、データを宛先テーブルに動的にパーティション分割します。次のコマンドは一例です。
drop table if exists ods_user_d; //ODPS パーティションテーブル (宛先テーブル) を作成します。 CREATE TABLE ods_user_d ( uid STRING, gender STRING, age_range STRING, zodiac STRING ) PARTITIONED BY ( dt STRING ); //動的パーティション分割 SQL 文を実行します。システムは、一時テーブルの dt フィールドに基づいてパーティションを自動的に作成します。dt フィールドの一意の値ごとに、その値でパーティションが作成されます。 //たとえば、dt フィールドの一部のデータが 20181025 の場合、ODPS パーティションテーブルにパーティション dt=20181025 が自動的に作成されます。 //動的パーティション分割 SQL 文は次のとおりです。 //dt フィールドが SELECT 文に追加され、このフィールドに基づいてパーティションが自動的に作成されるように指定されていることに注意してください。 insert overwrite table ods_user_d partition(dt)select dt,uid,gender,age_range,zodiac from ods_user_t; //インポートが完了したら、一時テーブルを削除してストレージコストを節約できます。 drop table if exists ods_user_t;MaxCompute では、SQL 文を使用してデータ同期を完了できます。
3 つのノードがワークフローで順次実行されるように構成します。
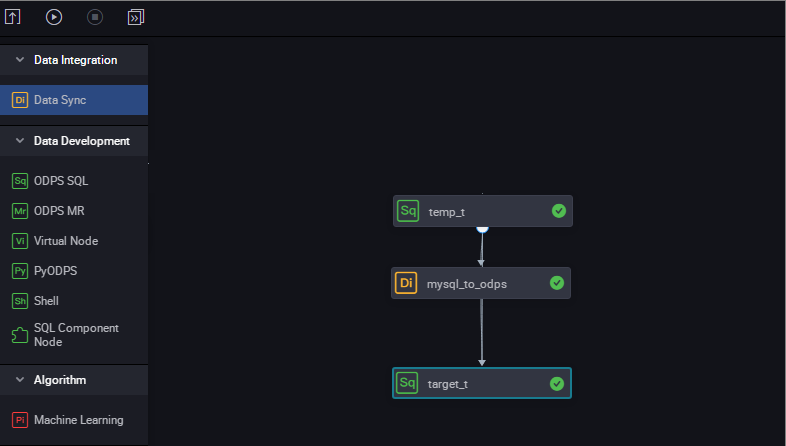
実行の進行状況を表示します。最後のノードの動的パーティション分割プロセスに特に注意してください。

結果を検証します。MaxCompute クライアントで次のコマンドを実行して、データ書き込みステータスを表示します。
SELECT count(*) from ods_user_d where dt = 20180913;