このトピックでは、MaxComputeを使用してオフラインデータウェアハウスを構築し、GitHubのリアルタイムイベントデータに基づいてRealtime Compute for Apache Flink and Hologresを使用してリアルタイムデータウェアハウスを構築する方法について説明します。 このトピックでは、HologresとMaxComputeを使用してリアルタイムおよびオフラインのデータ分析を実行する方法についても説明します。 このプロセスは、オフラインとリアルタイムのデータ処理の統合と呼ばれます。
背景情報
デジタル化の発展に伴い、企業はデータの適時性に対する需要がますます高まっています。 オフラインモードで大規模なデータ処理を伴う従来のビジネスを除いて、ほとんどのビジネスでは、リアルタイム処理、リアルタイムストレージ、およびリアルタイム分析が必要です。 これらの要件を満たすために、Alibaba Cloudはオフラインとリアルタイムのデータ処理の統合を導入しています。
オフラインデータ処理とリアルタイムデータ処理の統合により、リアルタイムデータとオフラインデータを同じプラットフォームで管理および処理することができます。 このシームレスな統合により、データ分析の効率と精度が向上します。 オフラインとリアルタイムのデータ処理の統合には、次の利点があります。
高いデータ処理効率: リアルタイムデータとオフラインデータの両方が同じプラットフォームで管理および処理されます。 これにより、データ処理効率が大幅に向上し、データ送信および変換コストが削減されます。
高いデータ分析精度: リアルタイムデータとオフラインデータのハイブリッド分析は、より高い精度と精度を提供します。
システムの複雑さが低い: データ管理とデータ処理がより簡単で効率的です。
高いデータ価値: データ価値は、企業の意思決定を容易にするために十分に調査されます。
Alibaba Cloudの統合データウェアハウジングソリューションでは、MaxComputeはオフラインデータ分析に使用され、Hologresはリアルタイムデータ分析に使用され、Realtime Compute for Apache Flinkはリアルタイムデータ処理に使用されます。
アーキテクチャ
次の図は、MaxComputeとHologresを併用してGitHubパブリックイベントデータセットのデータをリアルタイムおよびオフラインで処理する統合データウェアハウジングソリューションのアーキテクチャを示しています。

Elastic Compute Service (ECS) インスタンスは、GitHubからリアルタイムおよびオフラインのイベントデータをデータソースとして収集します。 その後、リアルタイムデータとオフラインデータは別々に処理され、Hologresに書き込まれます。 Hologresは、外部アプリケーションにデータサービスを提供します。
リアルタイム処理: Realtime Compute for Apache Flinkは、Log Service内のデータのリアルタイム処理を実行し、処理されたデータをHologresに書き込みます。 Realtime Compute for Apache Flinkは、強力なストリームコンピューティングエンジンです。 Hologresは、リアルタイムのデータ書き込みと更新をサポートします。 Hologres内のデータは、データが書き込まれた直後に照会できます。 Realtime Compute for Apache FlinkとHologresはネイティブに統合されており、高スループット、低レイテンシ、モデリング、高品質のパフォーマンスを実現するリアルタイムのデータウェアハウスをサポートします。 リアルタイムデータウェアハウスは、最新のイベント抽出やホットイベント分析などのシナリオにおけるビジネスインサイトのリアルタイム要件を満たします。
オフライン処理: MaxComputeは大量のオフラインデータを処理およびアーカイブします。 Object Storage Service (OSS) は、Alibaba cloudが提供するクラウドストレージサービスです。 OSSは、さまざまな種類のデータを保存するために使用できます。 このプラクティスで参照される生データはJSON形式です。 OSSは、便利で安全、低コストで信頼性の高いストレージ機能を提供します。 MaxComputeは、データ分析に適したエンタープライズレベルのサービスとしてのソフトウェア (SaaS) データウェアハウスです。 MaxComputeは、外部テーブルを使用してOSSの半構造化データを直接読み取り、解析し、価値の高いデータを保存し、DataWorksを使用してデータを開発し、オフラインデータウェアハウスを構築できます。
Hologresは、基盤となるレイヤーでMaxComputeとシームレスに統合されます。 Hologresを使用すると、MaxComputeで大量の履歴データのクエリと分析を高速化して、履歴データの低頻度で高性能なクエリのビジネス要件を満たすことができます。 また、オフライン処理でリアルタイムデータを簡単に変更して、リアルタイムリンクで発生する可能性のあるデータ損失などの問題を解決することもできます。
統合データウェアハウジングソリューションには、次の利点があります。
安定した効率的なオフライン処理: データは1時間ごとに書き込みおよび更新できます。 複雑なコンピューティングと分析のために、大量のデータをバッチで処理できます。 これにより、コンピューティングコストが削減され、データ処理効率が向上します。
成熟したリアルタイム処理: リアルタイム書き込み、リアルタイムイベントコンピューティング、およびリアルタイム分析がサポートされています。 リアルタイムデータは秒単位で照会されます。
統合ストレージとサービス: Hologresはサービスの提供に使用されます。 Hologresはデータを集中的に保存し、オンライン分析処理 (OLAP) クエリとキーと値のペアのポイントクエリに統合SQLインターフェイスを提供します。
リアルタイムデータとオフラインデータの統合: 冗長データが少なくなります。 データはほとんど移行されず、修正できます。
ワンストップ開発は、数秒以内にデータクエリへの応答を実現し、データ処理ステータスを視覚化し、必要なコンポーネントと依存関係を削減します。 これにより、O&Mコストと人件費が大幅に削減されます。
Introduction to business and data
多数の開発者がGitHubでオープンソースプロジェクトを開発し、プロジェクトの開発中に多数のイベントを生成します。 GitHubは、各イベント、開発者、およびコードリポジトリのタイプと詳細を記録します。 GitHubは、アイテムをお気に入りに追加したときやコードを送信したときに生成されるイベントなど、公開イベントも公開します。 イベントタイプの詳細については、「Webhookイベントとペイロード」をご参照ください。
GitHubはAPIを使用して公開イベントを公開します。 APIは、5分前に発生したイベントのみを公開します。 詳細については、「イベント」をご参照ください。 APIを使用して、リアルタイムデータを取得できます。
GH Archiveプロジェクトは、GitHubの公開イベントを1時間ごとに要約し、開発者からのアクセスを許可します。 GHアーカイブプロジェクトの詳細については、「GHアーカイブ」をご参照ください。 GH Archiveプロジェクトからオフラインデータを取得できます。
Introduction to GitHub
GitHubはコード管理に使用され、開発者間のコミュニケーションのプラットフォームとしても機能します。 GitHubには、開発者、リポジトリ、組織の3つのレベル1エンティティオブジェクトが含まれます。
この方法では、イベントはエンティティオブジェクトとして保存および記録されます。

オリジナル公開イベントのデータ紹介
元のイベントのJSON形式のサンプルデータ:
{
"id": "19541192931",
"type": "WatchEvent",
"actor":
{
"id": 23286640,
"login": "herekeo",
"display_login": "herekeo",
"gravatar_id": "",
"url": "https://api.github.com/users/herekeo",
"avatar_url": "https://avatars.githubusercontent.com/u/23286640?"
},
"repo":
{
"id": 52760178,
"name": "crazyguitar/pysheeet",
"url": "https://api.github.com/repos/crazyguitar/pysheeet"
},
"payload":
{
"action": "started"
},
"public": true,
"created_at": "2022-01-01T00:03:04Z"
}この例では、発生しない、または記録されなくなったイベントを除いて、15種類の公開イベントが含まれます。 イベントタイプと説明の詳細については、「GitHubイベントタイプ」をご参照ください。
前提条件
ECSインスタンスが作成され、elastic IPアドレス (EIP) に関連付けられています。 ECSインスタンスを使用して、GitHub APIからリアルタイムのイベントデータを取得できます。 詳細については、「作成方法の概要」および「EIPの関連付けまたは関連付けの解除」をご参照ください。
OSSが有効化され、ossutilツールがECSインスタンスにインストールされます。 ossutilツールを使用して、JSON形式のデータをGH ArchiveからOSSに保存できます。 詳細については、「OSSの有効化」および「ossutilのインストール」をご参照ください。
MaxComputeが有効化され、MaxComputeプロジェクトが作成されます。 詳細については、「MaxComputeプロジェクトの作成」をご参照ください。
DataWorksがアクティブ化され、オフラインスケジューリングタスクを作成するためのワークスペースが作成されます。 詳細については、「ワークスペースの作成」をご参照ください。
Log Service が有効化されていること。 ECSインスタンスによって抽出されたデータを収集し、そのデータをログとして保存するために、プロジェクトとLogstoreが作成されます。 詳細については、「入門」をご参照ください。
Realtime Compute for Apache Flinkがアクティブ化され、log Serviceによって収集されたログデータをリアルタイムでHologresに書き込みます。 詳細については、「Realtime Compute For Apache Flinkの有効化」をご参照ください。
Hologresインスタンスが購入されました。 詳細については、「Hologresインスタンスの購入」をご参照ください。
オフラインデータウェアハウスの構築 (1時間ごとに更新)
ECSインスタンスを使用した生データファイルのダウンロードとOSSへのアップロード
ECSインスタンスを使用して、GH ArchiveからJSON形式のデータファイルをダウンロードできます。 履歴データをダウンロードする場合は、wgetコマンドを実行します。 たとえば、wget https://data.gharchive.org/{2012 .. 2022}-{01 .. 12}-{01 .. 31}-{0..23}.json.gzコマンドを実行して、2012年から2022年まで1時間ごとにアーカイブされたデータをダウンロードできます。 1時間ごとにアーカイブされるリアルタイムデータをダウンロードする場合は、次の手順を実行して、1時間ごとに実行されるスケジュールされたタスクを設定します。
次のコマンドを実行して、
download_code.shという名前のファイルを作成します。vim download_code.shファイルに
iを入力して編集モードに入り、スクリプトを実行します。 スクリプト例:説明スクリプトを実行する前に、ossutilツールがECSインスタンスにインストールされていることを確認する必要があります。 詳細については、「ossutilのインストール」をご参照ください。 この例では、OSSバケットの名前は
githubeventsです。d=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%-H') h=$(TZ=UTC date --date='1 hour ago' '+%Y-%m-%d-%H') url=https://data.gharchive.org/${d}.json.gz echo ${url} wget ${url} -P ./gh_data/ cd gh_data gzip -d ${d}.json echo ${d}.json # Use the ossutil tool to upload data to OSS. cd /root ./ossutil64 mkdir oss://githubevents/hr=${h} ./ossutil64 cp -r /hourlydata/gh_data oss://githubevents/hr=${h} -u echo oss uploaded successfully! rm -rf /hourlydata/gh_data/${d}.json echo ecs deleted!Escキーを押して編集モードを終了します。
:wqと入力し、Enterキーを押してスクリプトを保存して閉じます。次のコマンドを実行して、
download_code.shスクリプトが1時間ごとに10分に実行されるスケジュールタスクを設定します。crontab -e 10 * * * * cd /hourlydata && sh download_code.sh > download.log各時間の10分に、前の時間にアーカイブされたJSONファイルがダウンロードされ、ossの
OSS: // githubeventsパスに解凍されます。 MaxComputeが過去1時間にアーカイブされたファイルのみを読み取るようにするには、ファイルごとに'hr=% Y-% M-% D-% H'形式の名前のパーティションを作成することを推奨します。 これにより、MaxComputeは最新のパーティションからデータを読み取ります。
外部テーブルを使用したOSSからMaxComputeへのデータのインポート
DataWorksコンソールのMaxComputeクライアントまたはODPS SQLノードで次の手順を実行します。 詳細については、「MaxComputeクライアント (odpscmd) 」または「MaxCompute SQLタスクの開発」をご参照ください。
OSSに保存されているJSONファイルを変換するための
githubeventsという名前の外部テーブルを作成します。CREATE EXTERNAL TABLE IF NOT EXISTS githubevents ( col STRING ) PARTITIONED BY ( hr STRING ) STORED AS textfile LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/githubevents/' ;MaxComputeでOSS外部テーブルを作成する方法の詳細については、「OSS外部テーブルの作成」をご参照ください。
データを格納するための
dwd_github_events_odpsという名前のファクトテーブルを作成します。 サンプルデータ定義言語 (DDL) ステートメント:CREATE TABLE IF NOT EXISTS dwd_github_events_odps ( id BIGINT COMMENT 'The event ID' ,actor_id BIGINT COMMENT 'The ID of the event actor' ,actor_login STRING COMMENT 'The username of the event actor' ,repo_id BIGINT COMMENT 'The repository ID' ,repo_name STRING COMMENT 'The full repository name in the owner/Repository_name format' ,org_id BIGINT COMMENT 'The ID of the organization to which the repository belongs' ,org_login STRING COMMENT 'The name of the organization to which the repository belongs' ,`type` STRING COMMENT 'The event type' ,created_at DATETIME COMMENT 'The time when the event occurred' ,action STRING COMMENT 'The event action' ,iss_or_pr_id BIGINT COMMENT 'The ID of the issue or pull_request' ,number BIGINT COMMENT 'The sequence number of issue or pull_request request' ,comment_id BIGINT COMMENT 'The comment ID' ,commit_id STRING COMMENT 'The commit ID' ,member_id BIGINT COMMENT 'The member ID' ,rev_or_push_or_rel_id BIGINT COMMENT 'The ID of the review, push, or release' ,ref STRING COMMENT 'The name of the resource that is created or deleted' ,ref_type STRING COMMENT 'The type of the resource that is created or deleted' ,state STRING COMMENT 'The status of the issue, pull_request, or pull_request_review request' ,author_association STRING COMMENT 'The relationship between the actor and the repository' ,language STRING COMMENT 'The language that is used to merge request code' ,merged BOOLEAN COMMENT 'Specifies whether merge is allowed' ,merged_at DATETIME COMMENT 'The time when code is merged' ,additions BIGINT COMMENT 'The number of rows added to the code' ,deletions BIGINT COMMENT 'The number of rows deleted from the code' ,changed_files BIGINT COMMENT 'The number of files changed by the pull request' ,push_size BIGINT COMMENT 'The push size' ,push_distinct_size BIGINT COMMENT 'The different push sizes' ,hr STRING COMMENT 'The hour in which the event occurred. For example, if the event occurred at 00:23, the value of this parameter is 00. ,`month` STRING COMMENT 'The month in which the event occurred. For example, if the event occurred in October 2015, the value of this parameter is 2015-10.' ,`year` STRING COMMENT 'The year in which the event occurred. For example, if the event occurred in year 2015, the value of this parameter is 2015.' ) PARTITIONED BY ( ds STRING COMMENT 'The day on which the event occurred. The value of this parameter is in the yyyy-mm-dd format.' ) ;JSON形式のデータを解析し、ファクトテーブルに書き込みます。
次のコマンドを実行してパーティションを追加し、JSON形式のデータを解析し、解析したデータを
dwd_github_events_odpsテーブルに書き込みます。msck repair table githubevents add partitions; set odps.sql.hive.compatible = true; set odps.sql.split.hive.bridge = true; INSERT into TABLE dwd_github_events_odps PARTITION(ds) SELECT CAST(GET_JSON_OBJECT(col,'$.id') AS BIGINT ) AS id ,CAST(GET_JSON_OBJECT(col,'$.actor.id')AS BIGINT) AS actor_id ,GET_JSON_OBJECT(col,'$.actor.login') AS actor_login ,CAST(GET_JSON_OBJECT(col,'$.repo.id')AS BIGINT) AS repo_id ,GET_JSON_OBJECT(col,'$.repo.name') AS repo_name ,CAST(GET_JSON_OBJECT(col,'$.org.id')AS BIGINT) AS org_id ,GET_JSON_OBJECT(col,'$.org.login') AS org_login ,GET_JSON_OBJECT(col,'$.type') as type ,to_date(GET_JSON_OBJECT(col,'$.created_at'), 'yyyy-mm-ddThh:mi:ssZ') AS created_at ,GET_JSON_OBJECT(col,'$.payload.action') AS action ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.id')AS BIGINT) END AS iss_or_pr_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.number')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.issue.number')AS BIGINT) ELSE CAST(GET_JSON_OBJECT(col,'$.payload.number')AS BIGINT) END AS number ,CAST(GET_JSON_OBJECT(col,'$.payload.comment.id')AS BIGINT) AS comment_id ,GET_JSON_OBJECT(col,'$.payload.comment.commit_id') AS commit_id ,CAST(GET_JSON_OBJECT(col,'$.payload.member.id')AS BIGINT) AS member_id ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.review.id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="PushEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.push_id')AS BIGINT) WHEN GET_JSON_OBJECT(col,'$.type')="ReleaseEvent" THEN CAST(GET_JSON_OBJECT(col,'$.payload.release.id')AS BIGINT) END AS rev_or_push_or_rel_id ,GET_JSON_OBJECT(col,'$.payload.ref') AS ref ,GET_JSON_OBJECT(col,'$.payload.ref_type') AS ref_type ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.state') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.state') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.state') END AS state ,case WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestEvent" THEN GET_JSON_OBJECT(col,'$.payload.pull_request.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssuesEvent" THEN GET_JSON_OBJECT(col,'$.payload.issue.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="IssueCommentEvent" THEN GET_JSON_OBJECT(col,'$.payload.comment.author_association') WHEN GET_JSON_OBJECT(col,'$.type')="PullRequestReviewEvent" THEN GET_JSON_OBJECT(col,'$.payload.review.author_association') END AS author_association ,GET_JSON_OBJECT(col,'$.payload.pull_request.base.repo.language') AS language ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.merged') AS BOOLEAN) AS merged ,to_date(GET_JSON_OBJECT(col,'$.payload.pull_request.merged_at'), 'yyyy-mm-ddThh:mi:ssZ') AS merged_at ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.additions')AS BIGINT) AS additions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.deletions')AS BIGINT) AS deletions ,CAST(GET_JSON_OBJECT(col,'$.payload.pull_request.changed_files')AS BIGINT) AS changed_files ,CAST(GET_JSON_OBJECT(col,'$.payload.size')AS BIGINT) AS push_size ,CAST(GET_JSON_OBJECT(col,'$.payload.distinct_size')AS BIGINT) AS push_distinct_size ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),12,2) as hr ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,7),'/','-') as month ,SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,4) as year ,REPLACE(SUBSTR(GET_JSON_OBJECT(col,'$.created_at'),1,10),'/','-') as ds from githubevents where hr = cast(to_char(dateadd(getdate(),-9,'hh'), 'yyyy-mm-dd-hh') as string);データの照会
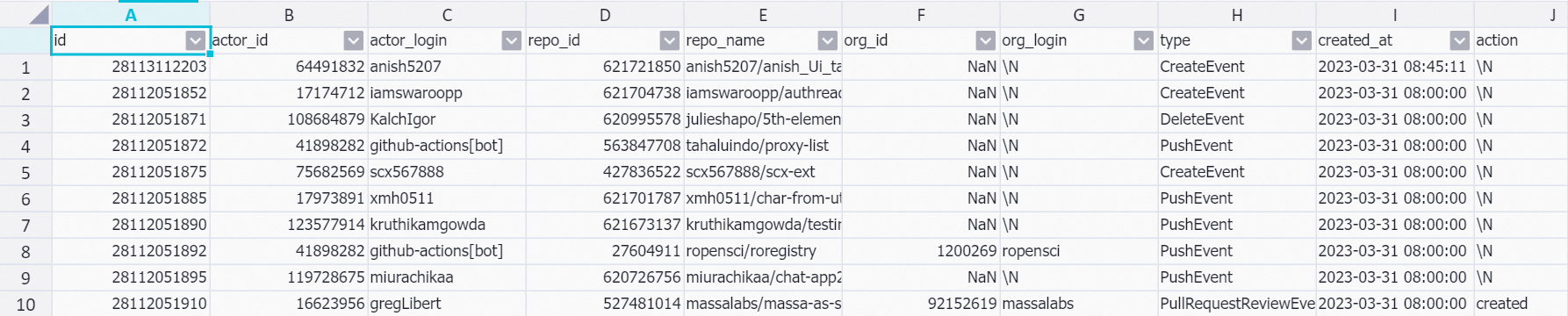
次のコマンドを実行して、
dwd_github_events_odpsテーブルからデータを照会します。set odps.sql.allow.fullscan=true; select * from dwd_github_events_odps limit 10;次の図に、返される結果を示します。
リアルタイムデータウェアハウスの構築
ECSインスタンスを使用したリアルタイムデータの収集
ECSインスタンスを使用して、GitHub APIからリアルタイムのイベントデータを抽出できます。 このセクションでは、GitHub APIからリアルタイムデータを収集する方法について説明します。
この例では、1分以内に生成されたリアルタイムのイベントデータがGitHub APIから収集され、JSON形式で保存されます。
スクリプトの実行によって収集されたリアルタイムのイベントデータが完全でない場合があります。
GitHub APIからデータを継続的に収集する場合は、AcceptパラメーターとAuthorizationパラメーターを指定する必要があります。 Acceptの値は固定です。 権限付与の値は、GitHubから適用したアクセストークンから取得できます。 アクセストークンの作成方法の詳細については、「個人用アクセストークンの作成」をご参照ください。
次のコマンドを実行して、
download_realtime_data.pyという名前のファイルを作成します。vim download_realtime_data.py編集モードに入るには、ファイルに
iを入力します。 次に、次のサンプルコードを追加します。#!python import requests import json import sys import time # Obtain the URL of the GitHub API. def get_next_link(resp): resp_link = resp.headers['link'] link = '' for l in resp_link.split(', '): link = l.split('; ')[0][1:-1] rel = l.split('; ')[1] if rel == 'rel="next"': return link return None # Collect one page of data from the GitHub API. def download(link, fname): # Define Accept and Authorization for the GitHub API. headers = {"Accept": "application/vnd.github+json"[, "Authorization": "Bearer <github_api_token>"]} resp = requests.get(link, headers=headers) if int(resp.status_code) != 200: return None with open(fname, 'a') as f: for j in resp.json(): f.write(json.dumps(j)) f.write('\n') print('downloaded {} events to {}'.format(len(resp.json()), fname)) return resp # Collect multiple pages of data from the GitHub API. def download_all_data(fname): link = 'https://api.github.com/events?per_page=100&page=1' while True: resp = download(link, fname) if resp is None: break link = get_next_link(resp) if link is None: break # Define the current time. def get_current_ms(): return round(time.time()*1000) # Set the duration of each script execution to 1 minute. def main(fname): current_ms = get_current_ms() while get_current_ms() - current_ms < 60*1000: download_all_data(fname) time.sleep(0.1) # Execute the script. if __name__ == '__main__': if len(sys.argv) < 2: print('usage: python {} <log_file>'.format(sys.argv[0])) exit(0) main(sys.argv[1])Escキーを押して編集モードを終了します。
:wqと入力し、Enterキーを押してスクリプトを保存して閉じます。run_py.shという名前のファイルを作成し、そのファイルを使用してdownload_realtime_data.pyファイルでスクリプトを実行し、収集したデータを実行時間に基づいて個別に保存します。 サンプルコード:python /root/download_realtime_data.py /root/gh_realtime_data/$(date '+%Y-%m-%d-%H:%M:%S').json履歴データの削除に使用する
delete_log.shファイルを作成します。 サンプルコード:d=$(TZ=UTC date --date='2 day ago' '+%Y-%m-%d') rm -f /root/gh_realtime_data/*${d}*.json次のコマンドを実行して、GitHubデータを毎分収集し、履歴データを毎日削除します。
crontab -e * * * * * bash /root/run_py.sh 1 1 * * * bash /root/delete_log.sh
Log Serviceを使用したECSインスタンスからのデータ収集
Log Serviceを使用して、ECSインスタンスによって抽出されたリアルタイムのイベントデータを収集し、そのデータをログとして保存できます。
Log Serviceは、ECSインスタンスからログデータを収集するためのLogtailを提供します。 このトピックのサンプルデータはJSON形式です。 LogtailのJSONモードを使用すると、ECSインスタンスから増分JSONログをすばやく収集できます。 詳細については、「JSONモードでのログの収集」をご参照ください。 このトピックでは、Log Serviceを使用して、最上位レベルに属する生データのキーと値のペアを解析します。
この例では、Logtailは収集されたデータを /root/gh_realtime_data/** ディレクトリの *.jsonファイルに記録します。
設定が完了すると、Log ServiceはECSインスタンスから増分イベントデータを継続的に収集します。 収集したデータの例を次の図に示します。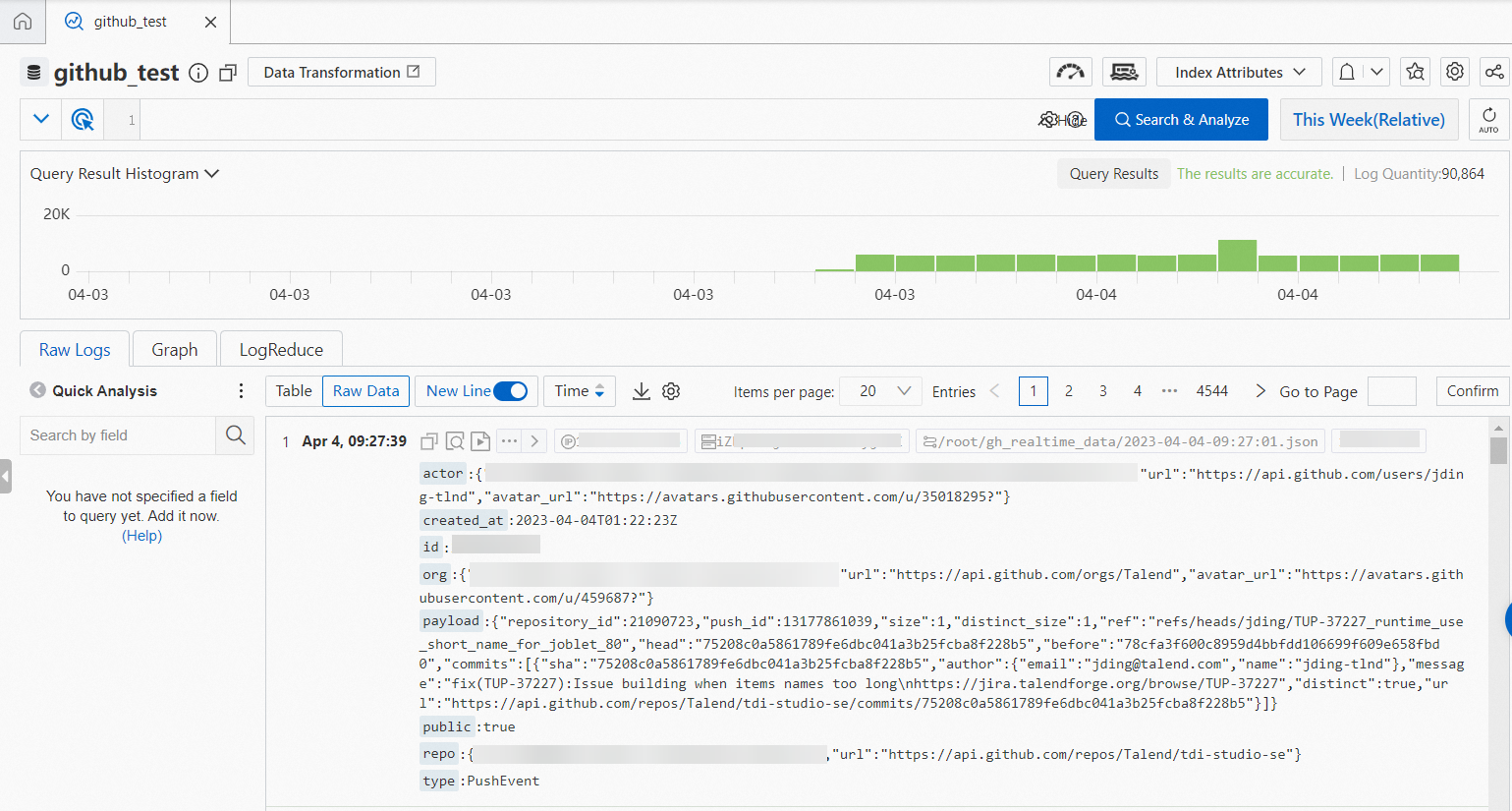
Realtime Compute for Apache Flinkを使用してLog ServiceからHologresにデータを書き込む
Realtime Compute for Apache Flinkを使用して、log Serviceによって収集されたログデータをリアルタイムでHologresに書き込むことができます。 このプロセスでは、Log ServiceソーステーブルとHologres結果テーブルがRealtime Compute for Apache Flinkで使用されます。 詳細については、「Simple Log Serviceからのデータのインポート」をご参照ください。
Hologres内部テーブルを作成します。
この例では、JSON形式の生データの一部のキーのみがHologres内部テーブルに保持されます。
IDで指定されたイベントidが配布キーとして設定され、dsで指定された日付がパーティションキーとして設定され、created_atで指定されたイベント発生時刻がevent_time_columnとして設定されます。idとdsは主キーです。 クエリ要件に基づいて、Hologres内部テーブルの他のフィールドのインデックスを作成できます。 これにより、クエリの効率が向上します。 インデックスの詳細については、「CREATE TABLE」をご参照ください。 サンプルDDL文:DROP TABLE IF EXISTS gh_realtime_data; BEGIN; CREATE TABLE gh_realtime_data ( id bigint, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id text, member_id bigint, rev_or_push_or_rel_id bigint, ref text, ref_type text, state text, author_association text, language text, merged boolean, merged_at timestamp with time zone, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr text, month text, year text, ds text, PRIMARY KEY (id,ds) ) PARTITION BY LIST (ds); CALL set_table_property('public.gh_realtime_data', 'distribution_key', 'id'); CALL set_table_property('public.gh_realtime_data', 'event_time_column', 'created_at'); CALL set_table_property('public.gh_realtime_data', 'clustering_key', 'created_at'); COMMENT ON COLUMN public.gh_realtime_data.id IS 'The event ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_id IS 'The actor ID'; COMMENT ON COLUMN public.gh_realtime_data.actor_login IS 'The username of the event actor'; COMMENT ON COLUMN public.gh_realtime_data.repo_id IS 'repoID'; COMMENT ON COLUMN public.gh_realtime_data.repo_name IS 'The repository name'; COMMENT ON COLUMN public.gh_realtime_data.org_id IS 'The ID of the organization to which the repository belongs'; COMMENT ON COLUMN public.gh_realtime_data.org_login IS 'The name of the organization to which the repository belongs'; COMMENT ON COLUMN public.gh_realtime_data.type IS 'The event type'; COMMENT ON COLUMN public.gh_realtime_data.created_at IS 'The time when the event occurred.'; COMMENT ON COLUMN public.gh_realtime_data.action IS 'The event action'; COMMENT ON COLUMN public.gh_realtime_data.iss_or_pr_id IS 'The ID of the issue or pull_request'; COMMENT ON COLUMN public.gh_realtime_data.number IS 'The sequence number of issue or pull_request'; COMMENT ON COLUMN public.gh_realtime_data.comment_id IS 'The comment ID'; COMMENT ON COLUMN public.gh_realtime_data.commit_id IS 'The commit ID'; COMMENT ON COLUMN public.gh_realtime_data.member_id IS 'The member ID'; COMMENT ON COLUMN public.gh_realtime_data.rev_or_push_or_rel_id IS 'The ID of the review, push, or release'; COMMENT ON COLUMN public.gh_realtime_data.ref IS 'The name of the resource that is created or deleted'; COMMENT ON COLUMN public.gh_realtime_data.ref_type IS 'The type of the resource that is created or deleted'; COMMENT ON COLUMN public.gh_realtime_data.state IS 'The status of the issue, pull_request, or pull_request_review request'; COMMENT ON COLUMN public.gh_realtime_data.author_association IS 'The relationship between the actor and the repository'; COMMENT ON COLUMN public.gh_realtime_data.language IS 'The programming language'; COMMENT ON COLUMN public.gh_realtime_data.merged IS 'Specifies whether merge is allowed'; COMMENT ON COLUMN public.gh_realtime_data.merged_at IS 'The time when code is merged'; COMMENT ON COLUMN public.gh_realtime_data.additions IS 'The number of rows added to the code'; COMMENT ON COLUMN public.gh_realtime_data.deletions IS 'The number of rows deleted from the code'; COMMENT ON COLUMN public.gh_realtime_data.changed_files IS 'The number of files changed by the pull request'; COMMENT ON COLUMN public.gh_realtime_data.push_size IS 'The push size'; COMMENT ON COLUMN public.gh_realtime_data.push_distinct_size IS 'The different push sizes'; COMMENT ON COLUMN public.gh_realtime_data.hr IS 'The hour in which the event occurred. For example, if the event occurred at 00:23, the value of this parameter is 00.'; COMMENT ON COLUMN public.gh_realtime_data.month IS 'The month in which the event occurred. For example, if the event occurred in October 2015, the value of this parameter is 2015-10.'; COMMENT ON COLUMN public.gh_realtime_data.year IS 'The year in which the event occurred. For example, if the event occurred in year 2015, the value of this parameter is 2015.'; COMMENT ON COLUMN public.gh_realtime_data.ds IS 'The day on which the event occurred. The value of this parameter is in the yyyy-mm-dd format.'; COMMIT;Realtime Compute for Apache Flinkを使用してリアルタイムデータを書き込みます。
Realtime Compute for Apache Flinkを使用して、Log Serviceからのデータをさらに解析し、解析されたデータをリアルタイムでHologresに書き込むことができます。 Realtime Compute for Apache Flinkで次のステートメントを実行して、Hologresに書き込むデータをフィルタリングします。 データフィルタリングでは、
created_atで指定されたイベントIDやイベント発生時刻などのダーティデータは破棄されます。 最近発生したイベントのデータのみが格納されます。CREATE TEMPORARY TABLE sls_input ( actor varchar, created_at varchar, id bigint, org varchar, payload varchar, public varchar, repo varchar, type varchar ) WITH ( 'connector' = 'sls', 'endpoint' = '<endpoint>',-- The internal endpoint that is used to access Log Service. 'accesssid'= '<accesskey id>',-- The AccessKey ID of your account. 'accesskey' = '<accesskey secret>',-- The AccessKey secret of your account. 'project' = '<project name>',-- The name of the project of Log Service. 'logstore' = '<logstore name>'-- The name of the Logstore in Log Service. ); CREATE TEMPORARY TABLE hologres_sink ( id bigint, actor_id bigint, actor_login string, repo_id bigint, repo_name string, org_id bigint, org_login string, type string, created_at timestamp, action string, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id string, member_id bigint, rev_or_push_or_rel_id bigint, `ref` string, ref_type string, state string, author_association string, `language` string, merged boolean, merged_at timestamp, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr string, `month` string, `year` string, ds string ) with ( 'connector' = 'hologres', 'dbname' = '<hologres dbname>', -- The name of the Hologres database. 'tablename' = '<hologres tablename>', -- The name of the Hologres table to which you want to write data. 'username' = '<accesskey id>', -- The AccessKey ID of your Alibaba Cloud account. 'password' = '<accesskey secret>', -- The AccessKey secret of your Alibaba Cloud account. 'endpoint' = '<endpoint>', -- The virtual private cloud (VPC) endpoint of your Hologres instance. 'jdbcretrycount' = '1', -- The maximum number of retries allowed if a connection fails. 'partitionrouter' = 'true', -- Specifies whether to write data to a partitioned table. 'createparttable' = 'true', -- Specifies whether to automatically create partitions. 'mutatetype' = 'insertorignore' -- The data writing mode. ); INSERT INTO hologres_sink SELECT id ,CAST(JSON_VALUE(actor, '$.id') AS bigint) AS actor_id ,JSON_VALUE(actor, '$.login') AS actor_login ,CAST(JSON_VALUE(repo, '$.id') AS bigint) AS repo_id ,JSON_VALUE(repo, '$.name') AS repo_name ,CAST(JSON_VALUE(org, '$.id') AS bigint) AS org_id ,JSON_VALUE(org, '$.login') AS org_login ,type ,TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS created_at ,JSON_VALUE(payload, '$.action') AS action ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.id') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.id') AS bigint) END AS iss_or_pr_id ,CASE WHEN type='PullRequestEvent' THEN CAST(JSON_VALUE(payload, '$.pull_request.number') AS bigint) WHEN type='IssuesEvent' THEN CAST(JSON_VALUE(payload, '$.issue.number') AS bigint) ELSE CAST(JSON_VALUE(payload, '$.number') AS bigint) END AS number ,CAST(JSON_VALUE(payload, '$.comment.id') AS bigint) AS comment_id ,JSON_VALUE(payload, '$.comment.commit_id') AS commit_id ,CAST(JSON_VALUE(payload, '$.member.id') AS bigint) AS member_id ,CASE WHEN type='PullRequestReviewEvent' THEN CAST(JSON_VALUE(payload, '$.review.id') AS bigint) WHEN type='PushEvent' THEN CAST(JSON_VALUE(payload, '$.push_id') AS bigint) WHEN type='ReleaseEvent' THEN CAST(JSON_VALUE(payload, '$.release.id') AS bigint) END AS rev_or_push_or_rel_id ,JSON_VALUE(payload, '$.ref') AS `ref` ,JSON_VALUE(payload, '$.ref_type') AS ref_type ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.state') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.state') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.state') END AS state ,CASE WHEN type='PullRequestEvent' THEN JSON_VALUE(payload, '$.pull_request.author_association') WHEN type='IssuesEvent' THEN JSON_VALUE(payload, '$.issue.author_association') WHEN type='IssueCommentEvent' THEN JSON_VALUE(payload, '$.comment.author_association') WHEN type='PullRequestReviewEvent' THEN JSON_VALUE(payload, '$.review.author_association') END AS author_association ,JSON_VALUE(payload, '$.pull_request.base.repo.language') AS `language` ,CAST(JSON_VALUE(payload, '$.pull_request.merged') AS boolean) AS merged ,TO_TIMESTAMP_TZ(replace(JSON_VALUE(payload, '$.pull_request.merged_at'),'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC') AS merged_at ,CAST(JSON_VALUE(payload, '$.pull_request.additions') AS bigint) AS additions ,CAST(JSON_VALUE(payload, '$.pull_request.deletions') AS bigint) AS deletions ,CAST(JSON_VALUE(payload, '$.pull_request.changed_files') AS bigint) AS changed_files ,CAST(JSON_VALUE(payload, '$.size') AS bigint) AS push_size ,CAST(JSON_VALUE(payload, '$.distinct_size') AS bigint) AS push_distinct_size ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),12,2) as hr ,REPLACE(SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,7),'/','-') as `month` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,4) as `year` ,SUBSTRING(TO_TIMESTAMP_TZ(replace(created_at,'T',' '), 'yyyy-MM-dd HH:mm:ss', 'UTC'),1,10) as ds FROM sls_input WHERE id IS NOT NULL AND created_at IS NOT NULL AND to_date(replace(created_at,'T',' ')) >= date_add(CURRENT_DATE, -1) ;パラメーターの詳細については、「Log Serviceソーステーブルの作成」および「Hologres結果テーブルの作成」をご参照ください。
説明GitHubは、生のイベントデータをUTCタイムゾーンに記録し、データにタイムゾーンプロパティを含めません。 ただし、HologresはデフォルトでUTC + 8タイムゾーンを使用します。 Realtime Compute for Apache Flinkを使用してリアルタイムデータをHologresに書き込む場合、次の操作を実行してデータのタイムゾーンを変換する必要があります。Flink SQLのソーステーブルのデータにUTCタイムゾーンプロパティを追加します。 [デプロイ開始設定] ページの [Flink設定] セクションで、
table.local-time-zone:Asia/Shanghaiステートメントを追加して、Realtime Compute for Apache FlinkのタイムゾーンをAsia/Shanghaiに設定します。データの照会
Realtime Compute for Apache Flinkを使用して、Log ServiceからHologresに書き込まれたデータを照会できます。 ビジネス要件に基づいてデータを開発することもできます。
SELECT * FROM public.gh_realtime_data limit 10;次の図に、返される結果を示します。

オフラインデータを使用してリアルタイムデータを修正
このトピックで説明するシナリオでは、リアルタイムデータが完全でない場合があります。 オフラインデータを使用して、リアルタイムデータを修正できます。 前日に生成されたリアルタイムデータを修正する方法について説明します。 ビジネス要件に基づいてデータ修正期間を変更できます。
Hologresで外部テーブルを作成し、MaxComputeからオフラインデータを取得します。
IMPORT FOREIGN SCHEMA <maxcompute_project_name> LIMIT to ( <foreign_table_name> ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'update',if_unsupported_type 'error');パラメーターの詳細については、「IMPORT FOREIGN SCHEMA」をご参照ください。
一時テーブルを作成し、オフラインデータを使用して、前日に生成されたリアルタイムデータを修正します。
-- Drop a temporary table if it exists. DROP TABLE IF EXISTS gh_realtime_data_tmp; -- Create a temporary table. SET hg_experimental_enable_create_table_like_properties = ON; CALL HG_CREATE_TABLE_LIKE ('gh_realtime_data_tmp', 'select * from gh_realtime_data'); -- Insert data into the temporary table and update statistics. INSERT INTO gh_realtime_data_tmp SELECT * FROM <foreign_table_name> WHERE ds = current_date - interval '1 day' ON CONFLICT (id, ds) DO NOTHING; ANALYZE gh_realtime_data_tmp; -- Replace the original child table with the temporary child table. BEGIN; DROP TABLE IF EXISTS "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data_tmp RENAME TO "gh_realtime_data_<yesterday_date>"; ALTER TABLE gh_realtime_data ATTACH PARTITION "gh_realtime_data_<yesterday_date>" FOR VALUES IN ('<yesterday_date>'); COMMIT;
データ分析
大量のデータは、さまざまなデータ分析に使用できます。 データウェアハウスを設計するときに、ビジネスで必要な時間範囲に基づいてデータレイヤーを定義できます。 データウェアハウスは、リアルタイムデータ分析、オフラインデータ分析、およびオフラインとリアルタイムのデータ処理の統合に関する要件を満たすことができます。
このセクションでは、前のセクションで取得したリアルタイムデータを分析する方法について説明します。 指定されたコードリポジトリ内のデータに対して分析を実行したり、開発者としてデータ分析を実行したりすることもできます。
当日に発生した公開イベントの総数を照会します。
SELECT count(*) FROM gh_realtime_data WHERE created_at >= date_trunc('day', now());次の応答が返されます。
count ------ 1006前日に最も多くのイベントが発生した上位プロジェクトを照会します。
SELECT repo_name, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;次の応答が返されます。
repo_name events ----------------------------------------+------ leo424y/heysiri.ml 29 arm-on/plan 10 Christoffel-T/fiverr-pat-20230331 9 mate-academy/react_dynamic-list-of-goods 9 openvinotoolkit/openvino 7前日に最も多くのイベントを開始したトップ開発者を照会します。
SELECT actor_login, COUNT(*) AS events FROM gh_realtime_data WHERE created_at >= now() - interval '1 day' AND actor_login NOT LIKE '%[bot]' GROUP BY actor_login ORDER BY events DESC LIMIT 5;次の応答が返されます。
actor_login events ------------------+------ direwolf-github 13 arm-on 10 sergii-nosachenko 9 Christoffel-T 9 yangwang201911 7過去1時間で最も人気のあるプログラミング言語を照会します。
SELECT language, count(*) total FROM gh_realtime_data WHERE created_at > now() - interval '1 hour' AND language IS NOT NULL GROUP BY language ORDER BY total DESC LIMIT 10;次の応答が返されます。
language total -----------+---- JavaScript 25 C++ 15 Python 14 TypeScript 13 Java 8 PHP 8リポジトリを前日にお気に入りに追加した回数で降順にランク付けします。
説明この例では、リポジトリがお気に入りから削除される回数は計算されません。
SELECT repo_id, repo_name, COUNT(actor_login) total FROM gh_realtime_data WHERE type = 'WatchEvent' AND created_at > now() - interval '1 day' GROUP BY repo_id, repo_name ORDER BY total DESC LIMIT 10;次の応答が返されます。
repo_id repo_name total ---------+----------------------------------+----- 618058471 facebookresearch/segment-anything 4 619959033 nomic-ai/gpt4all 1 97249406 denysdovhan/wtfjs 1 9791525 digininja/DVWA 1 168118422 aylei/interview 1 343520006 joehillen/sysz 1 162279822 agalwood/Motrix 1 577723410 huggingface/swift-coreml-diffusers 1 609539715 e2b-dev/e2b 1 254839429 maniackk/KKCallStack 1当日に関係するアクティブなアクターの数とアクティブなリポジトリの数を照会します。
SELECT uniq (actor_id) actor_num, uniq (repo_id) repo_num FROM gh_realtime_data WHERE created_at > date_trunc('day', now());次の応答が返されます。
actor_num repo_num ---------+-------- 743 816