MaxCompute の料金がどのように配分されているかを把握し、コストを削減するために、課金利用状況レコードをダウンロードし、Excel または MaxCompute SQL を使用して分析します。
MaxCompute は、コンピューティングリソースに対してサブスクリプションと従量課金の両方の課金方法をサポートしています。料金はプロジェクトごとに日次で計算され、日次請求書は翌日の 06:00 までに生成されます。料金の詳細については、「概要」をご参照ください。
従量課金の課金タイプ
以下の表では、各従量課金の課金タイプとその価格計算式をまとめています。最新の単価については、「コンピューティングの課金(従量課金)」、「ストレージ料金」、および「ダウンロード料金」をご参照ください。
| 課金タイプ | MeteringType の値 | 料金計算式 |
|---|---|---|
| SQL コンピューティング | ComputationSql | 入力データ (GB) x SQL の複雑性 x USD 0.0438/GB |
| ストレージ (標準、シングルゾーン) | Storage | 1日あたりの平均ストレージ (GB) x USD 0.0006/GB/日 |
| 長期保存ストレージ | ColdStorage | 1日あたりの平均ストレージ (GB) x 単価 |
| 低頻度アクセス (IA) ストレージ | LowFreqStorage | 1日あたりの平均ストレージ (GB) x 単価 |
| 長期保存ストレージアクセス | SqlLongterm | 入力データ (GB) x 単価 |
| IA ストレージアクセス | SqlLowFrequency | 入力データ (GB) x 単価 |
| インターネットダウンロード | DownloadEx | ダウンロードデータ (GB) x USD 0.1166/GB |
| MapReduce コンピューティング | MapReduce | 課金時間 x USD 0.0690/時間/タスク |
| Spark コンピューティング | spark | 課金時間 x USD 0.1041/時間/タスク |
| Tablestore 外部テーブル SQL | ComputationSqlOTS | 入力データ (GB) x USD 0.0044/GB |
| OSS 外部テーブル SQL | ComputationSqlOSS | 入力データ (GB) x USD 0.0044/GB |
ステップ 1:課金利用状況レコードのダウンロード
利用明細 ページに移動して、日次のリソース使用量レコードをダウンロードします。これらのレコードには、各日のストレージ料金やコンピューティング料金、およびそれらを生成したジョブなど、料金の発生方法が示されています。

次のパラメーターを設定します:

プロダクト: MaxCompute(Postpay) を選択します。
課金項目:
MaxCompute(Postpay):従量課金のコンピューティング、ストレージ、およびダウンロードの課金項目。
ODPSDataPlus:サブスクリプションプロジェクトにおける従量課金のストレージおよびダウンロード関連の課金項目。次のいずれかのシナリオでこのオプションを選択します:
リージョン内にサブスクリプションプロジェクトのみが存在し、従量課金プロジェクトがない場合。
2024年4月25日より前に、中国 (香港) リージョンまたは中国以外のリージョンにサブスクリプションプロジェクトと従量課金プロジェクトの両方が存在した場合。この場合、ODPSDataPlus はデフォルトでサブスクリプションコンピューティングクォータを使用するプロジェクトを対象とします。デフォルトで従量課金コンピューティングクォータを使用するプロジェクトのレコードをダウンロードするには、代わりに MaxCompute(Postpay) を選択します。
ODPS_QUOTA:使用しません。このオプションは無視してください。
ODPS_QUOTA_USAGE:コンピューティングまたはデータ転送に使用される弾性予約リソースの使用量レコード。
期間:課金データの開始日と終了日を指定します。> 注意: ジョブが12月1日に開始し、12月2日に完了する場合、開始日を12月1日に設定してください。そうしないと、ジョブのリソース使用量がダウンロードされたレコードに表示されません。このジョブのリソース消費レコードは、12月2日の請求書に表示されます。
時間単位:デフォルト値は時間です。
[CSV のエクスポート] をクリックします。エクスポートが完了したら、エクスポート履歴 ページに移動して利用状況レコードをダウンロードします。
ステップ 2 (任意):利用状況レコードの MaxCompute へのアップロード
このステップは、MaxCompute SQL を使用して分析する場合にのみ必要です。Excel のみで分析する場合は、ステップ 3 に進んでください。
MaxCompute クライアント (odpscmd) で
maxcomputefeeという名前のテーブルを作成します:CREATE TABLE IF NOT EXISTS maxcomputefee ( projectid STRING COMMENT 'プロジェクト ID' ,feeid STRING COMMENT '計測 ID' ,meteringtime STRING COMMENT '計測時間' ,type STRING COMMENT '計測タイプ (Storage、ComputationSql、DownloadEx など)' ,starttime STRING COMMENT '開始時間' ,storage BIGINT COMMENT 'ストレージ' ,endtime STRING COMMENT '終了時間' ,computationsqlinput BIGINT COMMENT 'SQL 入力 (バイト)' ,computationsqlcomplexity DOUBLE COMMENT 'SQL の複雑性' ,uploadex BIGINT COMMENT 'UploadEx' ,download BIGINT COMMENT 'DownloadEx (バイト)' ,cu_usage DOUBLE COMMENT 'MRCompute (コア*秒)' ,Region STRING COMMENT 'リージョン' ,input_ots BIGINT COMMENT 'InputOTS (バイト)' ,input_oss BIGINT COMMENT 'InputOSS (バイト)' ,source_id STRING COMMENT 'DataWorks ノード ID' ,source_type STRING COMMENT '仕様タイプ' ,RecycleBinStorage BIGINT COMMENT 'ごみ箱ストレージ' ,JobOwner STRING COMMENT 'ジョブオーナー' ,Signature STRING COMMENT '署名' );
フィールドの説明
| フィールド | 説明 |
|---|---|
| ProjectId | ご利用の Alibaba Cloud アカウント、または現在の RAM ユーザーが所属する Alibaba Cloud アカウントに属する MaxCompute プロジェクトの ID または名前。 |
| MeteringId | 課金 ID。SQL コンピューティングタスクの場合、これはインスタンス ID です。アップロードまたはダウンロードタスクの場合、これは Tunnel セッション ID です。 |
| MeteringType | 課金タイプ。有効な値:Storage、ComputationSql、UploadIn、UploadEx、DownloadIn、DownloadEx。課金ルールで赤枠で囲まれた項目のみが課金されます。追加の値には、MapReduce、spark、ComputationSqlOTS、ComputationSqlOSS、ColdStorage (長期保存ストレージ)、LowFreqStorage (低頻度アクセスストレージ)、SqlLongterm (長期保存ストレージアクセス)、および SqlLowFrequency (IA ストレージアクセス) があります。 |
| Storage | 1時間あたりのデータ読み取り量 (バイト単位)。 |
| StartTime / EndTime | ジョブが開始または停止した時刻。ストレージデータは1時間ごとに収集されます。 |
| SQLInput(Byte) | 各 SQL 実行の入力データ量 (バイト単位)。 |
| SQLComplexity | SQL 文の複雑性乗数。これは SQL ジョブの課金要素の1つです。 |
| UploadEx / DownloadEx(Byte) | インターネット経由でアップロードまたはダウンロードされたデータ量 (バイト単位)。 |
| MRCompute(Core\*Second) | MapReduce または Spark ジョブの課金時間。計算式:コア数 x 実行時間 (秒)。課金のために結果を時間に変換します。 |
| InputOTS(Byte) / InputOSS(Byte) | 外部テーブルを介して Tablestore または Object Storage Service (OSS) から読み取られたデータ量 (バイト単位)。 |
| RecycleBinStorage | 1時間あたりのバックアップデータ読み取り量 (バイト単位)。 |
| Region | MaxCompute プロジェクトが存在するリージョン。 |
| JobOwner | ジョブをサブミットしたユーザー。 |
| Signature | SQL ジョブの内容の識別子。同一の SQL 内容を持つジョブは同じ署名を共有し、繰り返し実行されるジョブやスケジュールされたジョブを識別するのに役立ちます。 |
次の Tunnel コマンドを実行して、課金利用状況レコードをアップロードします: > 注意: CSV ファイルの列数とデータ型は、
maxcomputefeeテーブルのものと一致する必要があります。一致しない場合、データのアップロードは失敗します。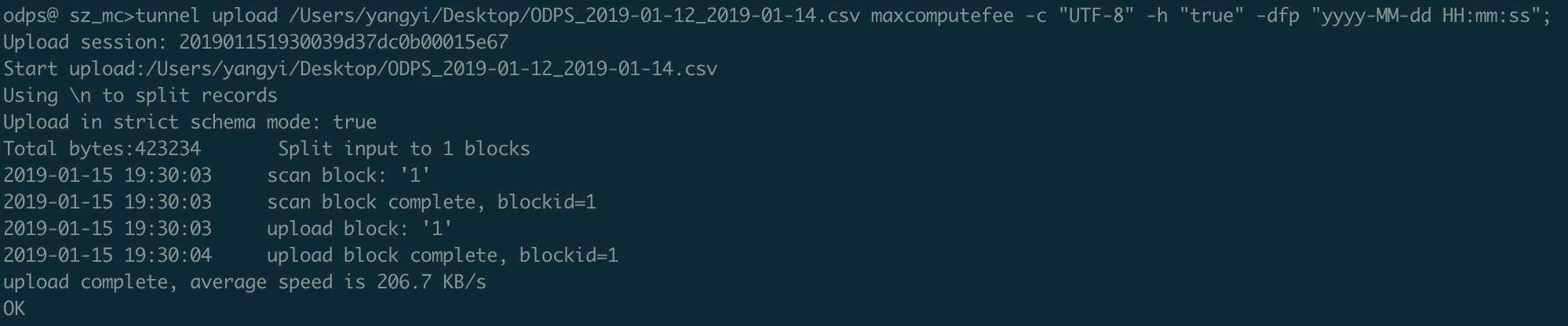 > 注意: > - Tunnel コマンドの詳細については、「Tunnel コマンド」をご参照ください。 > - DataWorks のデータインポート機能を使用して課金レコードをアップロードすることもできます。詳細については、「DataWorks の使用 (オフラインおよびリアルタイム)」をご参照ください。
> 注意: > - Tunnel コマンドの詳細については、「Tunnel コマンド」をご参照ください。 > - DataWorks のデータインポート機能を使用して課金レコードをアップロードすることもできます。詳細については、「DataWorks の使用 (オフラインおよびリアルタイム)」をご参照ください。tunnel upload ODPS_2019-01-12_2019-01-14.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";すべてのレコードがアップロードされたことを確認します:

SELECT * FROM maxcomputefee limit 10;
ステップ 3:課金利用状況レコードの分析
SQL ジョブ料金
数式: 入力データ (GB) x SQL の複雑性 x USD 0.0438/GB
Excel を使用する方法: MeteringType が ComputationSql のレコードをフィルタリングします。料金でソートして、予期せず高額なジョブや大量のジョブを特定します。各ジョブの料金を次のように計算します:
料金 = SQLInput(Byte) / 1024 / 1024 / 1024 x SQL の複雑性 x USD 0.0438
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- SQL ジョブを料金で降順にソートし、最も高額なジョブを見つけます。
SELECT to_char(endtime,'yyyymmdd') as ds,feeid as instanceid
,projectid
,computationsqlcomplexity -- SQL の複雑性
,SUM((computationsqlinput / 1024 / 1024 / 1024)) as computationsqlinput -- 入力データ量 (GB)
,SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.0438 AS sqlmoney
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND to_char(endtime,'yyyymmdd') >= '20190112'
GROUP BY to_char(endtime,'yyyymmdd'),feeid
,projectid
,computationsqlcomplexity
ORDER BY sqlmoney DESC
LIMIT 10000
;最適化のヒント:
高額なジョブの料金を削減するには、入力データ量を減らすか、SQL の複雑性を下げます。
dsフィールドで結果を集計して、一定期間の日次料金の傾向を分析します。Excel や Quick BI などのツールで傾向をプロットします。
高コストなジョブの背後にある DataWorks ノードの特定:
MaxCompute クライアント (odpscmd) または DataWorks コンソールで
wait <instanceid>;コマンドを実行して、LogView URL を取得します。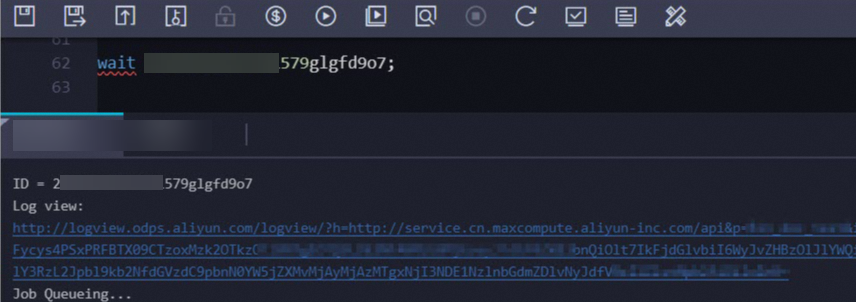
次のコマンドでジョブの詳細を表示します:出力例:
DESC instance 2016070102275442go3xxxxxx;ID 2016070102275442go3xxxxxx Owner ALIYUN$***@aliyun-inner.com StartTime 2016-07-01 10:27:54 EndTime 2016-07-01 10:28:16 Status Terminated console_query_task_1467340078684 Success Query select count(*) from src where ds='20160628';ブラウザで LogView URL を開きます。[SourceXML] タブをクリックし、SKYNET_NODENAME パラメーターの値を見つけます。
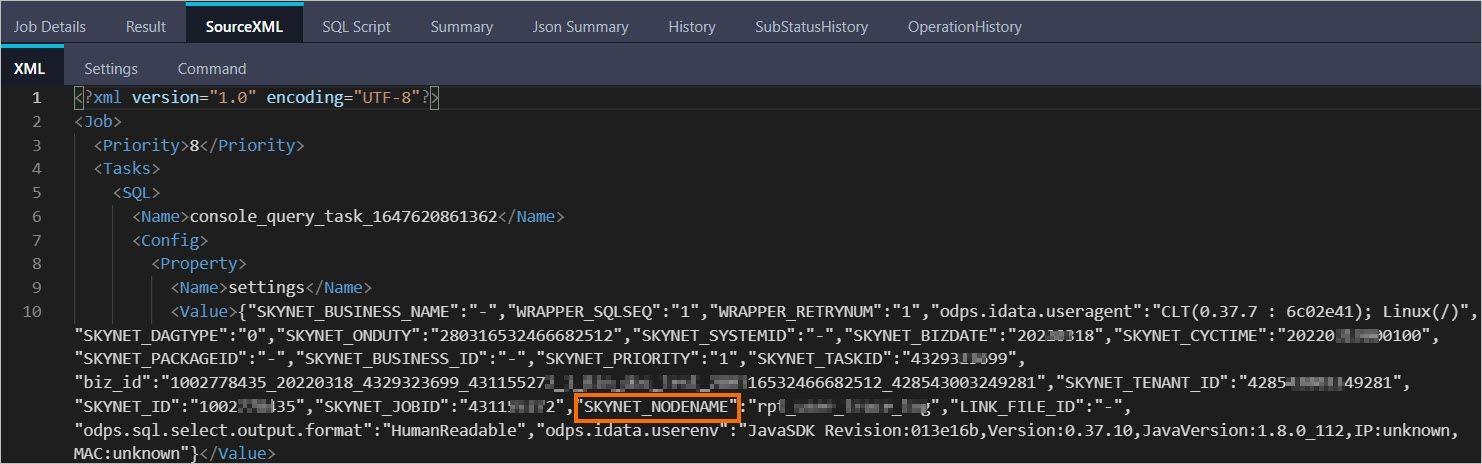 > 注意: > - LogView の詳細については、「LogView V2.0 を使用してジョブ情報を表示する」をご参照ください。 > - SKYNET_NODENAME パラメーターが空の場合は、[SQL スクリプト] タブをクリックしてコードスニペットを取得します。そのスニペットを使用して DataWorks コンソールでノードを検索します。詳細については、「DataWorks コード検索」をご参照ください。
> 注意: > - LogView の詳細については、「LogView V2.0 を使用してジョブ情報を表示する」をご参照ください。 > - SKYNET_NODENAME パラメーターが空の場合は、[SQL スクリプト] タブをクリックしてコードスニペットを取得します。そのスニペットを使用して DataWorks コンソールでノードを検索します。詳細については、「DataWorks コード検索」をご参照ください。SKYNET_NODENAME の値を使用して DataWorks コンソールでノードを検索し、最適化します。
ジョブ数の傾向
料金の増加は、繰り返しの操作や誤ったスケジュール設定によって引き起こされるジョブ数の急増と相関することがよくあります。
Excel を使用する方法: MeteringType が ComputationSql のレコードをフィルタリングします。各プロジェクトの日ごとのジョブ数をカウントし、異常な急増がないか確認します。
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- 日次ジョブ数の傾向を分析します。
SELECT TO_CHAR(endtime,'yyyymmdd') AS ds
,projectid
,COUNT(*) AS tasknum
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND TO_CHAR(endtime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(endtime,'yyyymmdd')
,projectid
ORDER BY tasknum DESC
LIMIT 10000
;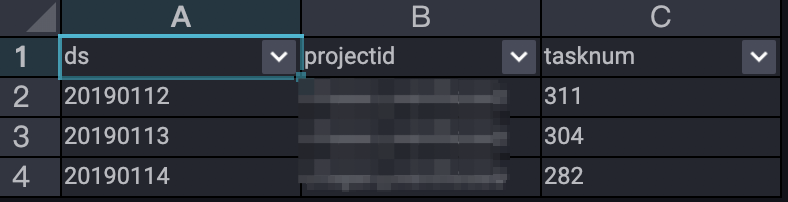
この結果は、2019年1月12日から1月14日までのジョブサブミットの傾向を示しています。
ストレージ料金
小規模プロジェクトの最低料金
MeteringType が Storage のレコードを表示します。maxcompute_doc のような、データがわずか 508 バイトのプロジェクトでも、ストレージ課金ルール に従い、512 MB までのストレージは一律の最低料金で課金されるため、CNY 0.01 が請求されます。
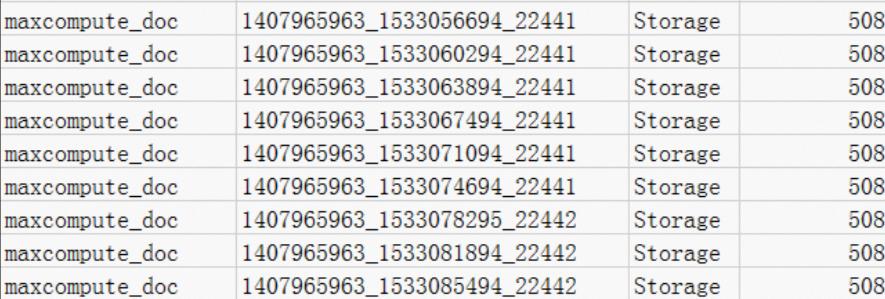
データがテスト目的でのみ使用される場合:
Drop Table文を実行してテーブルデータを削除します。プロジェクト全体が不要になった場合は、MaxCompute コンソールにログインし、[プロジェクト] ページでプロジェクトを削除します。
1日未満で保存されたデータ
MeteringType が Storage のレコードを表示します。例えば、alian プロジェクトは 333,507,833,900 バイトのデータを保存し、08:00 にアップロードされました。課金は 09:07 から開始され、結果として 15 時間分のストレージ料金が発生します。> 注意: 課金サイクルが1日の場合、課金は各日の終わりに停止します。最後の時間単位のレコードは、その日の請求書には含まれません。
ストレージ課金ルール に従って、平均ストレージと日次料金を計算します:
-- 平均ストレージ 333507833900 バイト x 15 / 1024 / 1024 / 1024 / 24 = 194.127109076362103 GB -- 日次ストレージ料金 (標準ストレージ:USD 0.0006/GB/日) 194.127109076362103 GB x USD 0.0006/GB/日 = USD 0.1165/日
SQL を使用したストレージ料金の分析
数式: 段階的料金が適用されます。0.5 GB 未満のストレージ:CNY 0.01/GB/日。0.5 GB 以上のストレージ:CNY 0.004/GB/日。
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- ストレージ料金を分析します。
SELECT t.ds
,t.projectid
,t.storage
,CASE WHEN t.storage < 0.5 THEN t.storage*0.01 --- プロジェクトの実際に使用されたストレージ容量が 0 MB より大きく 512 MB 以下の場合、ストレージ容量の単価は CNY 0.01/GB/日です。
WHEN t.storage >= 0.5 THEN t.storage*0.004 --- プロジェクトの実際に使用されたストレージ容量が 512 MB より大きい場合、ストレージ容量の単価は CNY 0.004/GB/日です。
END storage_fee
FROM (
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24 AS storage
FROM maxcomputefee
WHERE TYPE = 'Storage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid
) t
ORDER BY storage_fee DESC
;
最適化のヒント: ストレージ料金を削減するには、テーブルのライフサイクルを指定し、不要な一時テーブルを削除します。
長期保存および IA ストレージ料金
以下の SQL クエリの単価は、最新の料金を反映していない可能性があります。これらのクエリを使用する前に、ストレージ料金 ページで長期保存ストレージ、IA ストレージ、およびそれらのデータアクセス料金の現在の単価を確認し、クエリ内の価格乗数を適宜更新してください。
以下のクエリは、長期保存ストレージ (MeteringType: ColdStorage)、低頻度アクセスストレージ (MeteringType: LowFreqStorage)、およびそれぞれのデータアクセス料金 (SqlLongterm および SqlLowFrequency) の料金を分析します。ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- 長期保存ストレージ料金を分析します。
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24*0.0011 AS longTerm_storage
FROM maxcomputefee
WHERE TYPE = 'ColdStorage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- IA ストレージ料金を分析します。
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24*0.0011 AS lowFre_storage
FROM maxcomputefee
WHERE TYPE = 'LowFreqStorage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- 長期保存ストレージアクセス料金を分析します。
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(computationsqlinput/1024/1024/1024)*0.522 AS longTerm_IO
FROM maxcomputefee
WHERE TYPE = 'SqlLongterm'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- IA ストレージアクセス料金を分析します。
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(computationsqlinput/1024/1024/1024)*0.522 AS lowFre_IO
FROM maxcomputefee
WHERE TYPE = 'SqlLowFrequency'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;ダウンロード料金
数式: ダウンロードデータ (GB) x USD 0.1166/GB
Excel を使用する方法: MeteringType が DownloadEx のレコードをフィルタリングします。例えば、0.036 GB (38,199,736 バイト) のダウンロードトラフィックを示すレコードは、以下の料金になります:
(38,199,736 / 1024 / 1024 / 1024) x USD 0.1166 = USD 0.004
完全な料金ルールについては、「ダウンロード料金 (従量課金)」をご参照ください。
最適化のヒント: ご利用の Tunnel サービスがインターネットアクセス料金を発生させているかどうかを確認してください。エンドポイントの詳細については、「エンドポイント」をご参照ください。例えば、蘇州 (中国 (上海) リージョンの一部) にいて大量のデータをダウンロードする必要がある場合、中国 (上海) リージョンの Elastic Compute Service (ECS) インスタンスを使用して、まずデータを VM にダウンロードすることで、インターネットダウンロード料金を回避できます。
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- ダウンロード料金を分析します。
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,SUM((download/1024/1024/1024)*0.1166) AS download_fee
FROM maxcomputefee
WHERE type = 'DownloadEx'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
ORDER BY download_fee DESC
;MapReduce ジョブ料金
数式: 課金時間 x USD 0.0690/時間/タスク
Excel を使用する方法: MeteringType が MapReduce のレコードをフィルタリングします。以下を使用して料金を計算し、ソートします:
料金 = コア数 x 実行時間 (秒) / 3600 x USD 0.0690
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- MapReduce ジョブの料金を分析します。
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(cu_usage/3600)*0.0690 AS mr_fee
FROM maxcomputefee
WHERE type = 'MapReduce'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,cu_usage
ORDER BY mr_fee DESC
;Spark ジョブ料金
数式: 課金時間 x USD 0.1041/時間/タスク
Excel を使用する方法: MeteringType が spark のレコードをフィルタリングします。料金を次のように計算します:
料金 = コア数 x 実行時間 (秒) / 3600 x USD 0.1041
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- Spark ジョブの料金を分析します。
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(cu_usage/3600)*0.1041 AS mr_fee
FROM maxcomputefee
WHERE type = 'spark'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,cu_usage
ORDER BY mr_fee DESC
;外部テーブル料金 (Tablestore および OSS)
数式: 入力データ (GB) x USD 0.0044/GB
Excel を使用する方法: MeteringType が ComputationSqlOTS または ComputationSqlOSS のレコードをフィルタリングします。料金を次のように計算します:
料金 = SQLInput(Byte) / 1024 / 1024 / 1024 x USD 0.0044
以下の SQL クエリに記載されている単価 (0.03) は、現在の公式単価 (USD 0.0044/GB) と一致しません。クエリ内の価格乗数を更新し、「コンピューティング料金(従量課金)」 ページに記載されている現在の料金と一致させてください。
SQL を使用する方法: ステップ 2 のデータアップロードが完了し、maxcomputefee テーブルが存在することを確認してください。
-- Tablestore 外部テーブルを使用する SQL ジョブの料金を分析します。
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(computationsqlinput/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSqlOTS'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,computationsqlinput
ORDER BY ots_fee DESC
;
-- OSS 外部テーブルを使用する SQL ジョブの料金を分析します。
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(computationsqlinput/1024/1024/1024)*1*0.03 AS oss_fee
FROM maxcomputefee
WHERE type = 'ComputationSqlOSS'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,computationsqlinput
ORDER BY oss_fee DESC
;関連ドキュメント
TO_CHAR は MaxCompute SQL の日付または文字列関数です。詳細については、「TO_CHAR」をご参照ください。
請求の変動とコスト分析の詳細については、「請求明細の表示」をご参照ください。