cGPUを使用して、GPUリソースを分離できます。 これにより、複数のコンテナが単一のGPUを共有できます。 cGPUは、Container Service for Kubernetes (ACK) のコンポーネントとして外部サービスを提供し、機械学習、深層学習、科学計算のシナリオなど、ハイパフォーマンスコンピューティング (HPC) 機能を必要とするシナリオに適用できます。 cGPUを使用して、GPUリソースを効率的に利用し、コンピューティングタスクを高速化できます。 このトピックでは、のcGPUをインストールして使用する方法について説明します。
cGPUを使用してGPUリソースを分離する場合、UVM (Unified Virtual memory) を使用してGPUメモリを要求することはできません。 したがって、Compute Unified Device Architecture (CUDA) APIのcudaMallocManaged() を呼び出してGPUメモリを要求することはできません。 他の方法を使用してGPUメモリをリクエストできます。 たとえば、cudaMalloc() を呼び出すことができます。 詳細については、「CUDA初心者向け統合メモリ」をご参照ください。
前提条件
操作を実行する前に、GPUアクセラレーションインスタンスが次の要件を満たしていることを確認してください。
インスタンスは、gn7i、gn6i、gn6v、gn6e、gn5i、gn5、ebmgn7i、ebmgn6i、ebmgn7e、およびebmgn6eのいずれかのインスタンスファミリーに属します。.
インスタンスによって実行されるOSは、CentOS、Ubuntu、またはAlibaba Cloud Linux (Alinux) です。
バージョン418.87.01以降のTeslaドライバがインスタンスにインストールされています。
バージョン19.03.5以降のDockerがインスタンスにインストールされています。
cGPUのインストール
エンタープライズユーザーでも個人ユーザーでも、ACKのDockerランタイム環境を使用してcGPUをインストールして使用することを推奨します。
バージョン1.5.7のcGPUをインストールすると、並列プロセスが互いに干渉するため、cGPUカーネルドライバーがロックされる可能性があります。 その結果、Linuxカーネルパニックの問題が発生します。 新しいビジネスによるカーネルの問題を防ぐために、バージョン1.5.8以降のcGPUをインストールするか、バージョン1.5.8以降にcGPUを更新することを推奨します。
クラスターを作成します。
詳細については、「マネージド Kubernetes クラスターの作成」をご参照ください。
[クラスター] ページで、管理するクラスターの名前をクリックします。 左側のウィンドウで、 を選択します。
[クラウドネイティブAI Suite] ページで、[デプロイ] をクリックします。
[基本機能] セクションで、[スケジューリングポリシー拡張 (バッチタスクスケジューリング、GPU共有、トポロジ対応のGPUスケジューリング)] を選択します。
ページの下部にある [クラウドネイティブAIスイートのデプロイ] をクリックします。
cGPUがインストールされた後、Cloud-native ai Suiteページでack-AI-installerコンポーネントが [デプロイ済み] 状態であることを確認できます。
cGPUの使用
このセクションでは、cGPUを使用して2つのコンテナーが1つのGPUを共有できるようにする方法の例を示します。 この例では、ecs.gn6i-c4g1.xlargeインスタンスが使用されています。
cGPUの実行
次のコマンドを実行してコンテナーを作成し、コンテナーに割り当てられるGPUメモリを指定します。
この例では、コンテナに割り当てられたGPUメモリを指定する
ALIYUN_COM_GPU_MEM_CONTAINERと、GPUメモリの合計を指定するALIYUN_COM_GPU_MEM_DEVが設定されています。 次のコンテナが作成されます。gpu_test1: このコンテナには6 GiBのGPUメモリが割り当てられています。
sudo docker run -d -t --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name gpu_test1 -v /mnt:/mnt -e ALIYUN_COM_GPU_MEM_CONTAINER=6 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3gpu_test2: このコンテナには8 GiBのgpuメモリが割り当てられています。
sudo docker run -d -t --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --name gpu_test2 -v /mnt:/mnt -e ALIYUN_COM_GPU_MEM_CONTAINER=8 -e ALIYUN_COM_GPU_MEM_DEV=15 nvcr.io/nvidia/tensorflow:19.10-py3
説明上記のコマンドでは、TensorFlowイメージ
nvcr.io/nvidia/tensorflow:19.10-py3が使用されています。 ビジネス要件に基づいて、イメージをコンテナーイメージに置き換えます。 TensorFlowイメージを使用してTensorFlow深層学習フレームワークを構築する方法の詳細については、「深層学習開発のためのNGC環境のデプロイ」をご参照ください。次のコマンドを実行して、GPUメモリなどのコンテナーに関するGPU情報を表示します。
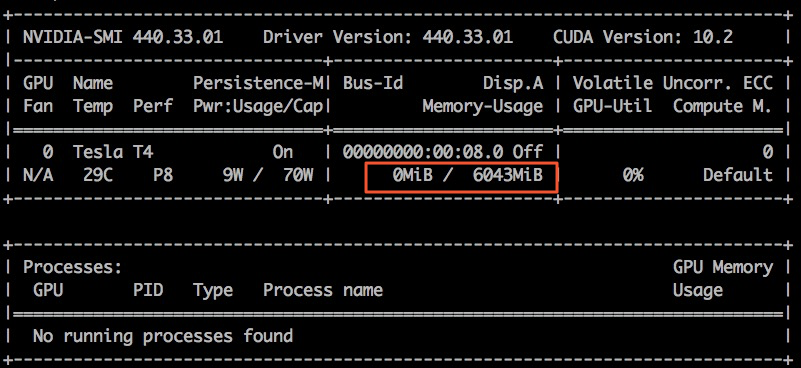
sudo docker exec -i gpu_test1 nvidia-smiこの例では、gpu_test1コンテナが使用されています。 次の図は、コンテナのGPUメモリがMiB 6,043であることを示しています。
procfsノードを使用したcGPUの表示
cGPUランタイムは、/proc/cgpu_kmディレクトリに複数のprocファイルシステム (procfs) ノードを生成し、ノードを自動的に管理します。 procfsノードを使用して、cGPU情報を表示し、cGPU設定を構成できます。
次のコマンドを実行して、procfsノードに関する情報を表示します。
ls /proc/cgpu_km/コマンドの出力を次の図に示します。

次のコマンドを実行して、GPUのディレクトリにあるパラメーターを表示します。
この例では、0 GPUディレクトリが使用されます。
ls /proc/cgpu_km/0コマンドの出力を次の図に示します。

次のコマンドを実行して、コンテナーのディレクトリにあるパラメーターを表示します。
この例では、012b2edccd7aコンテナディレクトリが使用されます。
ls /proc/cgpu_km/0/012b2edccd7aコマンドの出力を次の図に示します。

(オプション) 次のコマンドを実行してcGPUを設定します。
procfsノードを理解したら、GPU高速化インスタンスでコマンドを実行して操作を実行できます。 たとえば、スケジューリングポリシーを変更したり、重みを変更したりできます。 コマンドのサンプルを次の表に示します。
コマンド
効果
エコー2 > /proc/cgpu_km/0 /ポリシー
スケジューリングポリシーを重みベースのプリエンプティブスケジューリングに変更します。
cat /proc/cgpu_km/0/free_weight
GPUで使用可能な重みを照会します。
free_weightが0に設定されている場合、新しく作成されたコンテナの重みは0です。 この場合、コンテナーはGPUの計算能力を得ることができず、GPUの計算能力を必要とするアプリケーションの実行には使用できません。cat /proc/cgpu_km/0/$dockerid/weight
指定されたコンテナの重量を照会します。
エコー4 > /proc/cgpu_km/0/$dockerid /重量
コンテナーがGPUの計算能力を取得する際の重みを変更します。
cGPU-smiを使用したcgpuコンテナの表示
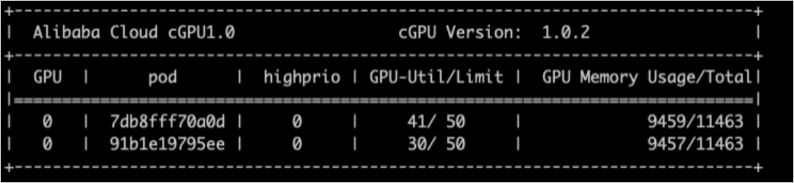
cgpu-smiを使用して、cGPUが使用されているコンテナに関する情報を表示できます。 この情報には、コンテナID、GPU使用率、計算能力制限、GPUメモリ使用率、および割り当てられたメモリの合計が含まれます。
cgpu-smiは、cGPUに関するサンプルモニタリング情報を提供します。 Kubernetesアプリケーションをデプロイする際に、サンプルモニタリング情報を参照または使用して、カスタム開発と統合を実行できます。
次の図は、cgpu-smiによって提供されるサンプルモニタリング情報を示しています。
cGPUの更新またはアンインストール
cGPUの更新
cGPUはコールドアップデートとホットアップデートをサポートしています。
コールドアップデート
cGPUがDockerに使用されていない場合は、cGPUでコールドアップデートを実行できます。 次の操作を実行します。
次のコマンドを実行して、実行中のすべてのコンテナを停止します。
sudo docker stop $(docker ps -a | awk '{ print $1}' | tail -n +2)次のコマンドを実行して、cGPUを最新バージョンに更新します。
sudo sh upgrade.sh
ホットアップデート
cGPUがDockerに使用されている場合、cGPUカーネルドライバーでホットアップデートを実行できます。 更新可能なバージョンには特定の制限が課されます。 サポートが必要な場合は、Alibaba Cloudのアフターサービスエンジニアにお問い合わせください。
cGPUのアンインストール
ノードから以前のバージョンのcGPUをアンインストールする方法の詳細については、「CLIを使用したノードのcGPUバージョンのアップグレード」をご参照ください。
cGPUの使用例
cGPUを使用した計算能力のスケジュール
cGPUがcgpu_kmモジュールをロードすると、cGPUはコンテナの最大数 (max_inst) に基づいて各GPUのタイムスライス (X ms) を設定し、GPUの計算能力をコンテナに割り当てます。 以下の例では、スライス1、スライス2、及びスライスN個のタイムスライスが使用される。 次の例は、異なるスケジューリングポリシーを使用してGPUコンピューティングパワーを割り当てる方法を示しています。
公正共有スケジューリング (ポリシー=0)
コンテナを作成すると、cGPUはタイムスライスをコンテナに割り当てます。 cGPUはスライス1からスケジューリングを開始します。 スケジューリングタスクは、物理GPUに提出され、タイムスライス (X ms) 内のコンテナ内で実行される。 次いで、cGPUは、次のタイムスライスに移動する。 各コンテナは、
1/max_instである同じ計算能力を得る。 詳細は以下の図をご参照ください。
プリエンプティブスケジューリング (ポリシー=1)
コンテナを作成すると、cGPUはタイムスライスをコンテナに割り当てます。 cGPUはスライス1からスケジューリングを開始します。 ただし、スライス1内でコンテナが使用されていない場合、またはGPUデバイスがコンテナ内のプロセスによって開始されていない場合、cGPUはスライス1内のスケジューリングをスキップして次のタイムスライスに移動します。
例:
Docker 1という名前のコンテナのみを作成し、Slice 1を割り当てて、コンテナ内で2つのTensorFlowプロセスを実行します。 この場合、Docker 1は、物理GPU全体の計算能力を得ることができる。
次に、Docker 2という名前のコンテナを作成し、Slice 2をコンテナに割り当てます。 GPUデバイスがDocker 2のプロセスによって起動されていない場合、cGPUはスライス2内のDocker 2のスケジューリングをスキップします。
GPUデバイスがDocker 2のプロセスによって起動された場合、cGPUはスライス1とスライス2内でスケジューリングを実行します。 Docker 1とDocker 2は、物理GPUの最大半分の計算能力を得ることができます。 詳細は以下の図をご参照ください。

重みベースのプリエンプティブスケジューリング (ポリシー=2)
コンテナーの作成時にALIYUN_COM_GPU_SCHD_WEIGHTが1より大きい値に設定されている場合、重みベースのプリエンプティブスケジューリングが使用されます。 cGPUは、コンテナの数 (max_inst) に基づいて、物理GPUの計算能力をmax_inst部分に分割する。 ALIYUN_COM_GPU_SCHD_WEIGHTが1より大きい値に設定されている場合、cGPUは複数のタイムスライスをより大きいタイムスライスに結合し、そのタイムスライスをコンテナに割り当てます。
サンプル設定:
Docker 1: ALIYUN_COM_GPU_SCHD_WEIGHT = m
Docker 2: ALIYUN_COM_GPU_SCHD_WEIGHT = n
スケジューリング結果:
Docker 1のみが実行されている場合、Docker 1は物理GPU全体の計算能力を先取りします。
Docker 1とDocker 2が実行されている場合、Docker 1とDocker 2は理論上の比率m:nで計算能力を取得します。 プリエンプティブスケジューリングと比較して、Docker 2は、GPUデバイスがDocker 2のプロセスによって起動されていない場合でも、n個のタイムスライスを消費します。
説明m:nを2:1と8:4に設定すると、コンテナの実行パフォーマンスが異なります。 m:nを2:1とした場合の1秒以内のタイムスライス数は、m:nを8:4とした場合の1秒以内のタイムスライス数の4倍である。

重みベースのプリエンプティブスケジューリングは、コンテナが取得できる理論上の最大GPU計算能力を制限します。 ただし、NVIDIA V100 GPUなどの強力なコンピューティング能力を提供するGPUでは、小さなGPUメモリが使用される場合、コンピューティングタスクは単一のタイムスライス内でのみ完了できます。 この場合、m:nが8:4に設定されると、残りのタイムスライスの間、GPU計算能力はアイドル状態になり、理論上の最大GPU計算能力の制限は無効になる。
固定スケジューリング (ポリシー=3)
max_instと一緒にALIYUN_COM_GPU_SCHD_WEIGHTを使用して、計算能力の割合を修正できます。
ソフトスケジューリング (ポリシー=4)
コンテナを作成すると、cGPUはタイムスライスをコンテナに割り当てます。 プリエンプティブスケジューリングと比較して、ソフトスケジューリングはよりソフトな方法でGPUリソースを分離します。 詳細については、「プリエンプティブスケジューリング (policy = 1) 」をご参照ください。
ネイティブスケジューリング (ポリシー=5)
このポリシーを使用して、GPUメモリのみを分離できます。 ポリシーが使用されると、計算能力はNVIDIA GPUドライバーの組み込みスケジューリング方法に基づいてスケジュールされます。
コンピューティングパワーのスケジューリングポリシーは、Tesla P4、Tesla P100、Tesla T4、Tesla V100、Tesla A10および GPUを含む、すべてのAlibaba Cloud異種GPUアクセラレーションインスタンスおよびインスタンスに使用されるNVIDIA GPUでサポートされています。 この例では、Tesla A10 GPUで構成されたGPUアクセラレーションインスタンスを共有する2つのコンテナーがテストされます。 コンテナの計算能力比は1:2です。 各コンテナは12 GiBのGPUメモリを取得します。
次の性能テストデータは参照だけのために提供されます。
テスト1: TensorFlowフレームワークを使用して異なるbatch_size値でトレーニングされたResNet50モデルのパフォーマンスデータを比較します。 FP16精度が使用されます。 次のセクションはテスト結果を示します。
フレームワーク
モデル
batch_size
精度
Docker 1の1秒あたりのイメージ数
Docker 2の1秒あたりのイメージ数
TensorFlow
ResNet50
16
FP16
151
307
TensorFlow
ResNet50
32
FP16
204
418
TensorFlow
ResNet50
64
FP16
247
503
TensorFlow
ResNet50
128
FP16
257
516
テスト2: TensorRTフレームワークを使用して異なるbatch_size値でトレーニングされたResNet50モデルのパフォーマンスデータを比較します。 FP16精度が使用されます。 次のセクションはテスト結果を示します。
フレームワーク
モデル
batch_size
精度
Docker 1の1秒あたりのイメージ数
Docker 2の1秒あたりのイメージ数
TensorRT
ResNet50
1
FP16
568.05
1132.08
TensorRT
ResNet50
2
FP16
940.36
1884.12
TensorRT
ResNet50
4
FP16
1304.03
2571.91
TensorRT
ResNet50
8
FP16
1586.87
3055.66
TensorRT
ResNet50
16
FP16
1783.91
3381.72
TensorRT
ResNet50
32
FP16
1989.28
3695.88
TensorRT
ResNet50
64
FP16
2105.81
3889.35
TensorRT
ResNet50
128
FP16
2205.25
3901.94
cGPUを使用して複数のGPUにメモリを割り当てる
次の例では、4つのGPUが設定されています。 GPU0、GPU1、GPU2、およびGPU3は、メモリの3 GiB、4 GiB、5 GiB、および6 GiBを別々に割り当てられる。 サンプルコード:
docker run -d -t --runtime=nvidia --name gpu_test0123 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -v /mnt:/mnt -e ALIYUN_COM_GPU_MEM_CONTAINER=3,4,5,6 -e ALIYUN_COM_GPU_MEM_DEV=23 -e NVIDIA_VISIBLE_DEVICES=0,1,2,3 nvcr.io/nvidia/tensorflow:21.03-tf1-py3
docker exec -i gpu_test0123 nvidia-smi次のコマンド出力は、GPUのメモリの詳細を示しています。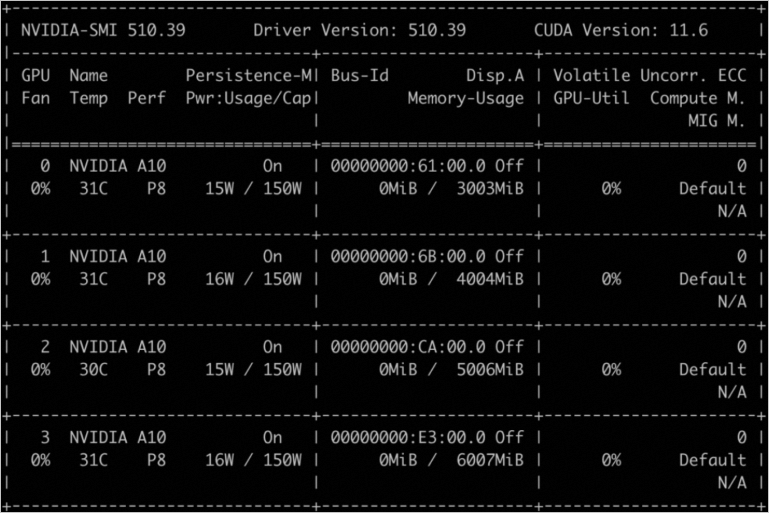
ALIYUN_COM_GPU_MEM_CONTAINERを使用して、複数のGPUにメモリを割り当てることができます。 次の表に、ALIYUN_COM_GPU_MEM_CONTAINERの値を示します。
値 | 説明 |
ALIYUN_COM_GPU_MEM_CONTAINER=3 | 4つのGPUのそれぞれのメモリは3 GiBに設定されています。 |
ALIYUN_COM_GPU_MEM_CONTAINER=3,1 | 4つのGPUのメモリは、順に、3 GiB、1 GiB、1 GiB、および1 GiBに設定される。 |
ALIYUN_COM_GPU_MEM_CONTAINER=3,4,5,6 | 4つのGPUのメモリは、順に3 GiB、4 GiB、5 GiB、および6 GiBに設定される。 |
ALIYUN_COM_GPU_MEM_CONTAINER指定なし | cGPUは無効です。 |
ALIYUN_COM_GPU_MEM_CONTAINER=0 | |
ALIYUN_COM_GPU_MEM_CONTAINER=1,0,0 |