パブリックイメージには、既知のセキュリティ脆弱性や設定の問題が含まれている場合があります。これらの問題を理解することで、潜在的なセキュリティリスクを特定し、適切な対策を講じて迅速に問題を特定し解決することができます。
Windows の既知の問題
Linux イメージの既知の問題
CentOS の問題
Debian の問題
Fedora CoreOS の問題
OpenSUSE の問題
Red Hat Enterprise Linux の問題
Red Hat Enterprise Linux 8 64 ビット:yum update コマンドでカーネルバージョンを更新できない
SUSE Linux Enterprise Server の問題
その他の問題
Windows オペレーティングシステムの既知の問題
Windows:メモリが 512 MB のインスタンスにおける機能上の問題
問題の説明
メモリが 512 MB の Elastic Compute Service (ECS) インスタンスで Windows Server Version 2004 Datacenter 64 ビット (簡体字中国語、UI なし) オペレーティングシステムを使用すると、問題が発生する場合があります。たとえば、インスタンス作成時に設定したパスワードが有効にならない、インスタンスのパスワードが変更できない、コマンドの実行に失敗するなどの問題です。
原因
ページングファイルが有効になっていないため、仮想メモリを割り当てることができません。その結果、プログラム実行時に例外が発生する可能性があります。
解決策
メモリサイズが小さいため、Pre-installation Environment (PE) ディスクをインスタンスにアタッチできません。また、インスタンス作成時に設定したパスワードが有効でないため、インスタンスにログインすることもできません。したがって、Cloud Assistant を使用してのみ、インスタンスのページングファイルを有効にできます。
以下のいずれかの方法で、Cloud Assistant を使用してコマンドを実行できます。
セッションマネージャーを使用してパスワードなしでインスタンスに接続し、コマンドを実行します。詳細については、「セッションマネージャーを使用してインスタンスに接続する」をご参照ください。
Cloud Assistant を使用してインスタンスにコマンドを送信します。詳細については、「リモートコマンドの送信」をご参照ください。
次のコマンドを実行して、ページングファイルの自動管理を有効にします。
Wmic ComputerSystem set AutomaticManagedPagefile=True説明コマンドの実行に失敗する場合があります。失敗した場合は、成功するまでコマンドを再試行してください。
また、
Wmic ComputerSystem get AutomaticManagedPagefileコマンドを実行して、ページングファイルが有効になっているかどうかを確認することもできます。次のメッセージが返された場合、ページングファイルは有効になっています。AutomaticManagedPagefile TRUE
インスタンスを再起動して、変更を有効にします。
Windows Server 2016:ソフトウェアインストールパッケージが応答しない
問題の説明
Windows Server 2016 でソフトウェアインストールパッケージをダウンロードして実行すると、オペレーティングシステムが応答しなくなります。
原因
セキュリティ上の理由から、Windows オペレーティングシステムは起動の Sysprep フェーズ中に ProtectYourPC セキュリティ設定を有効にします。オペレーティングシステムの起動後、SmartScreen システムプロセスが実行されます。SmartScreen システムプロセスは、悪意のある Web サイトや安全でないダウンロードからユーザーを保護するように設計されています。
インターネットからソフトウェアパッケージをダウンロードまたは実行しようとすると、パッケージには Web 識別子が含まれます。この識別子は、システムの SmartScreen プロセスをトリガーします。SmartScreen は、ソフトウェアがインターネットから提供されたものであり、十分な評価情報がない可能性があると認識し、その結果、ソフトウェアをブロックします。
解決策
この問題を解決するには、次のいずれかの方法を使用できます。
ソフトウェアパッケージのブロックを解除する
ソフトウェアパッケージのプロパティで、[ブロックの解除] を選択します。
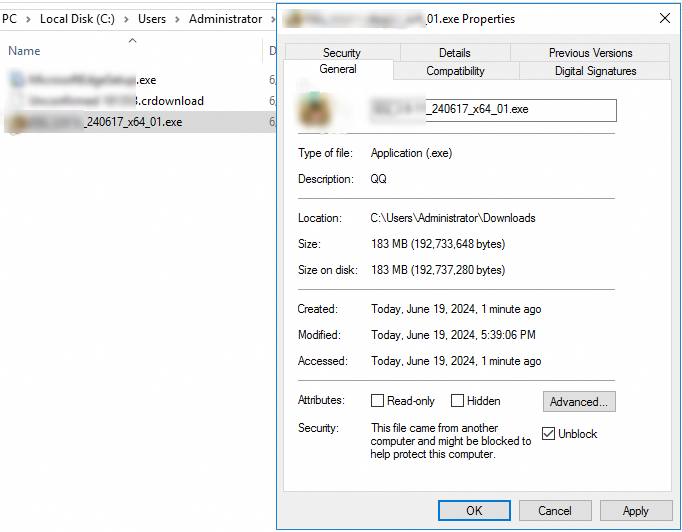
ソフトウェアパッケージを再度実行します。
SmartScreen フィルターを無効にする
C:\Windows\System32ディレクトリに移動します。SmartScreenSettings.exeファイルをダブルクリックします。[Windows SmartScreen] ダイアログボックスで、[何もしない (Windows SmartScreen をオフにする)] を選択し、[OK] をクリックします。
ソフトウェアパッケージを再度実行します。
グループポリシー設定を変更する
[ファイル名を指定して実行] ウィンドウを開き、
gpedit.mscと入力します。ローカルグループポリシーエディターで、[コンピューターの構成] > [Windows の設定] > [セキュリティの設定] > [ローカル ポリシー] > [セキュリティ オプション] に移動します。
[ユーザー アカウント制御: ビルトイン Administrator アカウントのための管理者承認モード] ポリシーを見つけて右クリックし、[プロパティ] を選択します。
[ローカル セキュリティの設定] タブで、[有効] を選択し、[OK] をクリックします。
システムを再起動して、設定を有効にします。
ソフトウェアパッケージを再度実行します。
Windows Server 2022:KB5034439 パッチのインストール失敗
問題の説明
Windows Server 2022 オペレーティングシステムで KB5034439 パッチのインストールに失敗します。
原因
KB5034439 は、2024 年 1 月に Microsoft がリリースした Windows 回復環境の更新プログラムです。更新ソースとして公式の Microsoft Windows Update サービスを使用すると、システムはこのパッチを検索してインストールしようとしますが、インストールに失敗する可能性があります。デフォルトでは、イメージは Alibaba Cloud WSUS 更新サーバーを使用しており、このサーバーはこのパッチを提供していません。この動作は想定どおりであり、通常の使用には影響しません。詳細については、Microsoft の公式ドキュメント「KB5034439: Windows Recovery Environment update for Windows Server 2022: January 9, 2024」をご参照ください。
2022 年 6 月の Microsoft パッチが NAT が有効なサーバーで RRAS の問題を引き起こす
問題の説明:2022 年 6 月 23 日の Microsoft の発表によると、2022 年 6 月に Microsoft がリリースしたセキュリティパッチを Windows デバイスにインストールした後、次のリスクが発生する可能性があります:ネットワークアドレス変換 (NAT) が有効になっているルーティングとリモートアクセスサービス (RRAS) サーバーが接続を失い、サーバーに接続されているデバイスがインターネットに接続できなくなる可能性があります。
影響を受けるバージョン:
Windows Server 2022
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
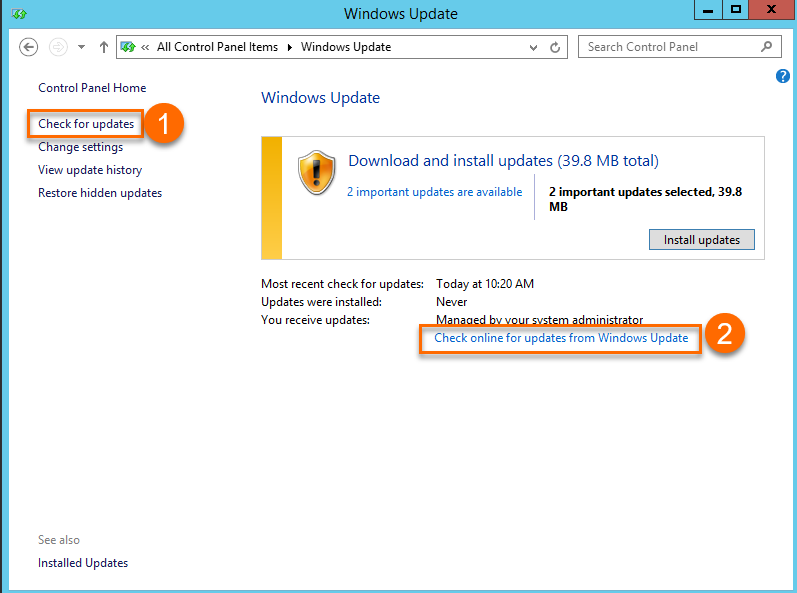
Windows Server 2012 R2 および Windows Server 2012 のシステム更新を確認する際は、①でマークされた [更新プログラムの確認] オプションを選択してください。①にリンクされている更新ソースは、内部の Alibaba Cloud Windows WSUS サーバーです。②にリンクされている更新ソースは、公式の Microsoft Windows Update サーバーです。特別な場合、セキュリティ更新プログラムが潜在的な問題を引き起こす可能性があります。これらの問題を回避するため、Microsoft からの Windows セキュリティ更新プログラムを確認し、チェックに合格した更新プログラムを内部 WSUS サーバーにリリースします。
解決策:関連する問題のあるパッチは、Alibaba Cloud が提供する WSUS サービスから削除されました。オペレーティングシステムが影響を受けないようにするには、問題のあるパッチが Windows デバイスにインストールされているかどうかを確認してください。Windows Server のバージョンに一致する CMD コマンドを実行して、パッチを確認できます。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5014738" Windows Server 2019: wmic qfe get hotfixid | find "5014692" Windows Server 2016: wmic qfe get hotfixid | find "5014702" Windows Server 2012: wmic qfe get hotfixid | find "5014747" Windows Server 2022: wmic qfe get hotfixid | find "5014678"確認の結果、問題のあるパッチがインストールされており、Windows サーバーで NAT や RRAS の障害などの問題が発生している場合は、パッチをアンインストールしてデバイスを通常の状態に戻すことを推奨します。Windows Server のバージョンに一致する CMD コマンドを実行して、パッチをアンインストールできます。
Windows Server 2012 R2: wusa /uninstall /kb:5014738 Windows Server 2019: wusa /uninstall /kb:5014692 Windows Server 2016: wusa /uninstall /kb:5014702 Windows Server 2012: wusa /uninstall /kb:5014747 Windows Server 2022: wusa /uninstall /kb:5014678説明この問題に関するさらなる更新と操作ガイダンスについては、Microsoft の公式ドキュメントをご参照ください。詳細については、「RRAS Servers can lose connectivity if NAT is enabled on the public interface」をご参照ください。
2022 年 1 月のパッチが Windows Server ドメインコントローラーで異常な動作を引き起こす
問題の説明:2022 年 1 月 13 日の Microsoft の発表によると、2022 年 1 月に Microsoft がリリースしたセキュリティパッチを Windows デバイスにインストールした後、次のリスクが発生する可能性があります:ドメインコントローラーが再起動できない、または再起動ループに入る、Hyper-V の仮想マシン (VM) が起動に失敗する、または IPsec VPN 接続が失敗する。
影響を受けるバージョン:
Windows Server 2022
Windows Server, version 20H2
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
Windows Server 2012 R2 および Windows Server 2012 のシステム更新を確認する際は、①でマークされた [更新プログラムの確認] オプションを選択してください。①にリンクされている更新ソースは、内部の Alibaba Cloud Windows WSUS サーバーです。②にリンクされている更新ソースは、公式の Microsoft Windows Update サーバーです。特別な場合、セキュリティ更新プログラムが潜在的な問題を引き起こす可能性があります。これらの問題を回避するため、Microsoft からの Windows セキュリティ更新プログラムを確認し、チェックに合格した更新プログラムを内部 WSUS サーバーにリリースします。
解決策:関連する問題のあるパッチは、Alibaba Cloud が提供する WSUS サービスから削除されました。オペレーティングシステムが影響を受けないようにするには、問題のあるパッチが Windows デバイスにインストールされているかどうかを確認してください。Windows Server のバージョンに一致する CMD コマンドを実行して、パッチを確認できます。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5009624" Windows Server 2019: wmic qfe get hotfixid | find "5009557" Windows Server 2016: wmic qfe get hotfixid | find "5009546" Windows Server 2012: wmic qfe get hotfixid | find "5009586" Windows Server 2022: wmic qfe get hotfixid | find "5009555"確認の結果、問題のあるパッチがインストールされており、Windows デバイスがドメインコントローラーを使用できない、または VM を起動できない場合は、パッチをアンインストールしてデバイスを通常の状態に戻すことを推奨します。Windows Server のバージョンに一致する CMD コマンドを実行して、パッチをアンインストールできます。
Windows Server 2012 R2: wusa /uninstall /kb:5009624 Windows Server 2019: wusa /uninstall /kb:5009557 Windows Server 2016: wusa /uninstall /kb:5009546 Windows Server 2012: wusa /uninstall /kb:5009586 Windows Server 2022: wusa /uninstall /kb:5009555説明この問題に関するさらなる更新と操作ガイダンスについては、Microsoft の公式ドキュメントをご参照ください。詳細については、「RRAS Servers can lose connectivity if NAT is enabled on the public interface」をご参照ください。
Windows Server 2012 R2:.NET Framework 3.5 のインストール失敗
問題:Windows Server 2012 R2 で、2023 年 6 月のパッチ KB5027141、2023 年 7 月のパッチ KB5028872、2023 年 8 月のパッチ KB5028970、または 2023 年 9 月のパッチ KB5029915 がデフォルトでインストールされているイメージを使用すると、.NET Framework 3.5 をインストールできません。
重要Windows Server 2012 R2 オペレーティングシステムを引き続き使用する場合は、ECS コンソールに移動し、.NET Framework 3.5 がプリインストールされている Windows Server 2012 R2 コミュニティイメージを使用して ECS インスタンスを作成することを推奨します。イメージ名は win2012r2_9600_x64_dtc_zh-cn_40G_.Net3.5_alibase_20231204.vhd および win2012r2_9600_x64_dtc_en-us_40G_.Net3.5_alibase_20231204.vhd です。これら 2 つのイメージを見つける方法については、「イメージの検索」をご参照ください。
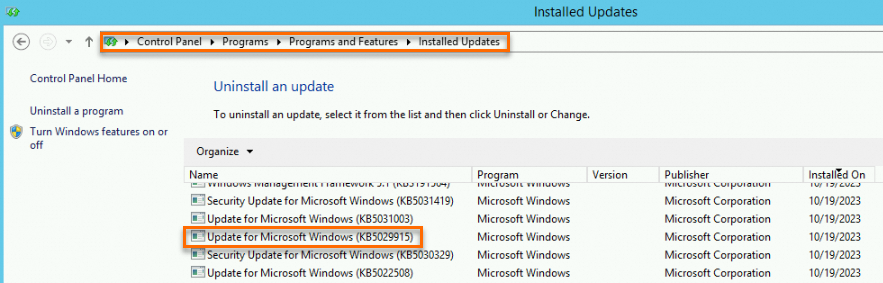
解決策:
コントロールパネルで KB5027141、KB5028872、KB5028970、または KB5029915 パッチを見つけ、パッチを右クリックして [アンインストール] を選択して手動でアンインストールします。たとえば、次の図に示すパスから KB5029915 パッチをアンインストールできます。
ECS インスタンスを再起動します。
詳細については、「インスタンスの再起動」をご参照ください。
次のいずれかの方法で .NET Framework 3.5 をインストールできます。
サーバーマネージャー UI からインストールする
[サーバー マネージャー] で、[役割と機能の追加] をクリックします。
ウィザードに従い、デフォルトの設定を使用します。[機能] ページで、[.NET Framework 3.5 の機能] を選択します。

インストールが完了するまで、ウィザードに従って結果を確認します。
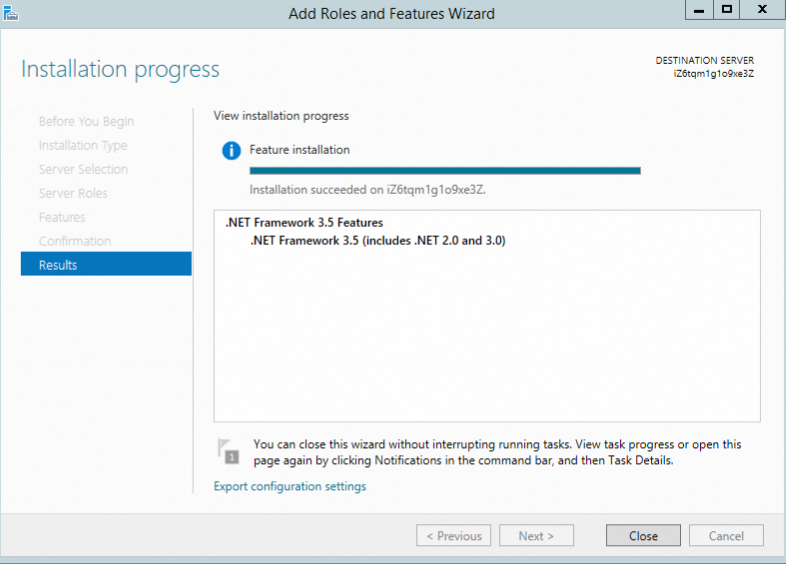
PowerShell コマンドを実行してインストールする
次のいずれかのコマンドを実行できます。
Dism /Online /Enable-Feature /FeatureName:NetFX3 /All
Install-WindowsFeature -Name NET-Framework-Features
Windows Server 2025:.NET Framework 3.5 のインストール失敗
問題の説明:Windows Server 2025 で .NET Framework 3.5 をインストールしようとすると、インストールに失敗します。

解決策:Windows Server 2025 は Alibaba Cloud WSUS 更新ソースを使用します。この更新ソースは Windows Server 2025 の機能更新をサポートしていません。解決策の詳細については、「Windows Server 2012 R2 以降を実行しているインスタンスで .NET Framework 3.5 または言語パックのインストールに失敗する問題を解決する方法」をご参照ください。
Windows SSD が HDD として表示される
説明:
コンソールで Windows インスタンスを購入し、標準 SSD をアタッチします。オペレーティングシステムのタスクマネージャーでは、SSD が HDD として識別されます。
原因:
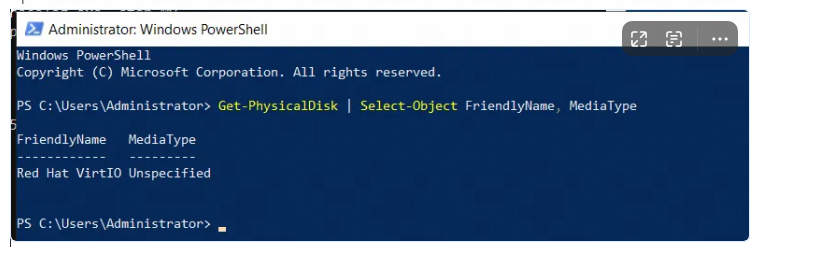
Windows は、INQUIRY コマンドによって返される MEDIUM ROTATION RATE の値に基づいてディスクタイプを決定します。システムがディスクを SSD または HDD として識別するためには、ドライバーがこの値を正しく報告する必要があります。MEDIUM ROTATION RATE が報告されない場合、システムはディスクタイプを「未指定」として表示し、デフォルトで HDD となります。Windows Server 2025 のタスクマネージャーが SSD を HDD として表示する問題は、Microsoft のパッチのバグでした。Microsoft はこのバグを 2025 年 6 月のパッチで修正しました。
解決策:
この問題は、基盤となるプロトコルの制限によって引き起こされます。virtio ブロックドライバーは、ディスクが SSD か HDD かを判断できません。このような場合、オペレーティングシステムはディスクを HDD として表示します。インスタンスは実際には標準 SSD を使用しています。ディスクのパフォーマンスと使用には影響しません。
Linux イメージの既知の問題
CentOS の問題
CentOS 8.0 パブリックイメージの命名問題
問題の説明:centos_8_0_x64_20G_alibase_20200218.vhd パブリックイメージから作成されたインスタンスに接続すると、インスタンスのオペレーティングシステムのバージョンが CentOS 8.1 であることがわかります。
testuser@ecshost:~$ lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 8.1.1911 (Core) Release: 8.1.1911 Codename: Core原因:イメージはパブリックイメージリストで利用可能であり、最新のコミュニティ更新パッケージで更新されています。バージョンも 8.1 にアップグレードされています。したがって、実際のバージョンは 8.1 です。
影響を受けるイメージ ID:centos_8_0_x64_20G_alibase_20200218.vhd。
解決策:CentOS 8.0 を使用するには、RunInstances などの API 操作を呼び出し、
ImageId=centos_8_0_x64_20G_alibase_20191225.vhdを設定して ECS インスタンスを作成できます。
CentOS 7:特定のイメージ ID の更新によって引き起こされる問題
問題の説明:特定の CentOS 7 パブリックイメージの ID が更新されました。これは、自動化された O&M 中にイメージ ID を取得するためのポリシーに影響を与える可能性があります。
影響を受けるイメージ:CentOS 7.5 および CentOS 7.6
原因:最新バージョンの CentOS 7.5 および CentOS 7.6 パブリックイメージで使用されるイメージ ID は、
%OS type%_%Major version%_%Minor version%_%Special field%_alibase_%Date%.%Format%の形式です。たとえば、CentOS 7.5 のイメージ ID プレフィックスはcentos_7_05_64からcentos_7_5_x64に更新されます。イメージ ID の変更によって影響を受ける可能性のある自動化された O&M ポリシーを調整する必要があります。イメージ ID の詳細については、「2023 年のリリースノート」をご参照ください。
CentOS 7:インスタンスの再起動後にホスト名が大文字から小文字に変わる
問題の説明:CentOS 7 を実行している一部のインスタンスを初めて再起動すると、ホスト名が大文字から小文字に変わります。次の表にいくつかの例を示します。
ホスト名の例
最初の再起動後の例
その後の再起動でも小文字のまま
iZm5e1qe*****sxx1ps5zX
izm5e1qe*****sxx1ps5zx
はい
ZZHost
zzhost
はい
NetworkNode
networknode
はい
影響を受けるイメージ:次の CentOS パブリックイメージと、それらから作成されたすべてのカスタムイメージ。
centos_7_2_64_40G_base_20170222.vhd
centos_7_3_64_40G_base_20170322.vhd
centos_7_03_64_40G_alibase_20170503.vhd
centos_7_03_64_40G_alibase_20170523.vhd
centos_7_03_64_40G_alibase_20170625.vhd
centos_7_03_64_40G_alibase_20170710.vhd
centos_7_02_64_20G_alibase_20170818.vhd
centos_7_03_64_20G_alibase_20170818.vhd
centos_7_04_64_20G_alibase_201701015.vhd
影響を受けるホスト名の種類:アプリケーションがホスト名の大文字と小文字を区別する場合、インスタンスを再起動した後にビジネスに影響が出る可能性があります。次の解決策を使用して、これらの種類のホスト名を修正できます。
ホスト名の種類
影響
影響を受けるタイミング
このドキュメントを読み続ける
コンソールまたは API 操作を呼び出してインスタンスを作成する際に、ホスト名に大文字が含まれている。
はい
インスタンスの初回再起動時。
はい
コンソールまたは API 操作を呼び出してインスタンスを作成する際に、ホスト名に小文字のみが含まれている。
いいえ
該当なし
いいえ
ホスト名に大文字が含まれており、インスタンスにログインした後にホスト名を変更した。
いいえ
該当なし
はい
解決策:インスタンスを再起動した後も大文字のホスト名を保持するには、次の手順を実行します。
インスタンスに接続します。
詳細については、「接続ツールの選択」をご参照ください。
現在のホスト名を表示します。
[testuser@izbp193*****3i161uynzzx ~]# hostname izbp193*****3i161uynzzx次のコマンドを実行して、ホスト名を永続化します。
hostnamectl set-hostname --static iZbp193*****3i161uynzzX次のコマンドを実行して、更新されたホスト名を表示します。
[testuser@izbp193*****3i161uynzzx ~]# hostname iZbp193*****3i161uynzzX
次のステップ:カスタムイメージを使用している場合は、cloud-init ソフトウェアを最新バージョンに更新してから、別のカスタムイメージを作成します。これにより、問題のあるカスタムイメージを使用して新しいインスタンスを作成する際に同じ問題が発生するのを防ぎます。詳細については、「cloud-init のインストール」および「インスタンスからのカスタムイメージの作成」をご参照ください。
CentOS 6.8:NFS クライアントがインストールされたインスタンスがクラッシュする
問題の説明:NFS クライアントがロードされた CentOS 6.8 インスタンスが長時間の待機状態に入ります。この問題は、インスタンスを再起動することによってのみ解決できます。
原因:カーネルバージョン 2.6.32-696 から 2.6.32-696.10 で NFS サービスを使用すると、通信遅延のグリッチ (電子パルス) が発生した場合、カーネルの nfsclient が TCP 接続を積極的に切断します。NFS サーバーの応答が遅い場合、nfsclient によって開始された接続が FIN_WAIT2 状態で行き詰まる可能性があります。通常、FIN_WAIT2 状態の接続はデフォルトで 1 分後にタイムアウトして回収され、nfsclient は接続を再開できます。しかし、これらのカーネルバージョンの TCP 実装の欠陥により、FIN_WAIT2 状態の接続は決してタイムアウトしません。その結果、nfsclient の TCP 接続は決して閉じることができず、新しい接続を開始できず、ユーザーリクエストはハングして回復できなくなります。これを修正する唯一の方法は、ECS インスタンスを再起動することです。
影響を受けるイメージ ID:centos_6_08_32_40G_alibase_20170710.vhd および centos_6_08_64_20G_alibase_20170824.vhd。
解決策:yum update コマンドを実行して、システムカーネルをバージョン 2.6.32-696.11 以降にアップグレードできます。
重要インスタンスで操作を実行する前に、スナップショットを作成してデータをバックアップしていることを確認してください。詳細については、「スナップショットの作成」をご参照ください。
Debian の問題
Debian 9.6:クラシックネットワーク内のインスタンスにおけるネットワーク設定の問題
問題の説明:Debian 9 パブリックイメージから作成されたクラシックネットワークタイプのインスタンスに ping を実行できません。
原因:Debian システムでは、systemd-networkd サービスがデフォルトで無効になっています。クラシックネットワークタイプのインスタンスは、動的ホスト構成プロトコル (DHCP) モードで IP アドレスを自動的に割り当てることができません。
影響を受けるイメージ ID:debian_9_06_64_20G_alibase_20181212.vhd。
解決策:この問題を解決するには、次のコマンドを順番に実行する必要があります。
systemctl enable systemd-networkdsystemctl start systemd-networkd
Fedora CoreOS の問題
Fedora CoreOS カスタムイメージから作成されたインスタンスのホスト名が有効にならない
問題の説明:Fedora CoreOS イメージを選択して ECS インスタンス A を作成し、インスタンス A からカスタムイメージを作成し、そのカスタムイメージを使用して新しい ECS インスタンス B を作成します。インスタンス B に設定したホスト名は有効になりません。インスタンス B にログインして確認すると、インスタンス B のホスト名はインスタンス A と同じです。
たとえば、ホスト名が
test001の Fedora CoreOS ECS インスタンス (インスタンス A) があるとします。次に、このインスタンスのカスタムイメージを使用して新しい ECS インスタンス (インスタンス B) を作成し、インスタンス作成時にインスタンス Bのホスト名をtest002に設定します。インスタンス Bを正常に作成してリモート接続した後、インスタンス Bのホスト名は依然としてtest001です。原因:Alibaba Cloud パブリックイメージとして提供される Fedora CoreOS イメージは、インスタンスの初期化にオペレーティングシステムの公式 Ignition サービスを使用します。Ignition サービスは、Fedora CoreOS および Red Hat Enterprise Linux CoreOS がシステム起動時に initramfs でディスクを操作するために使用するプログラムです。ECS インスタンスが初めて起動するとき、Ignition の
coreos-ignition-firstboot-complete.serviceは、空のファイルである /boot/ignition.firstboot ファイルの存在をチェックして、インスタンスを初期化するかどうかを判断します。ファイルが存在する場合、インスタンスは初期化され、ホスト名の設定などが含まれ、/boot/ignition.firstboot ファイルは削除されます。Fedora CoreOS インスタンスは作成後に少なくとも 1 回起動されているため、対応するカスタムイメージ内の /boot/ignition.firstboot ファイルは削除されています。このカスタムイメージを使用して新しい ECS インスタンスを作成すると、インスタンスは最初の起動時に初期化されず、ホスト名は変更されません。
解決策:
説明インスタンスのデータセキュリティを確保するため、操作を実行する前にインスタンスのスナップショットを作成することを推奨します。データ例外が発生した場合、スナップショットを使用してディスクを通常の状態にロールバックできます。詳細については、「スナップショットの作成」をご参照ください。
Fedora CoreOS インスタンスからカスタムイメージを作成する前に、
root(管理者) 権限を使用して /boot ディレクトリに /ignition.firstboot ファイルを作成します。コマンドライン操作は次のとおりです。/boot を読み書きモードで再マウントします。
sudo mount /boot -o rw,remount/ignition.firstboot ファイルを作成します。
sudo touch /boot/ignition.firstboot/boot を読み取り専用モードで再マウントします。
sudo mount /boot -o ro,remount
Ignition の設定の詳細については、「Ignition 設定リファレンス」をご参照ください。
OpenSUSE の問題
OpenSUSE 15:カーネルの更新により起動中にシステムがハングする可能性がある
問題の説明:OpenSUSE カーネルをバージョン
4.12.14-lp151.28.52-defaultにアップグレードした後、特定の CPU タイプでインスタンスが起動時にハングすることがあります。既知の CPU タイプはIntel® Xeon® CPU E5-2682 v4 @ 2.50GHzです。対応するコールトレースのデバッグ結果は次のとおりです。[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **原因:新しいカーネルバージョンが CPU マイクロコードと互換性がありません。詳細については、「起動ハング問題」をご参照ください。
影響を受けるイメージ:opensuse_15_1_x64_20G_alibase_20200520.vhd。
解決策:/boot/grub2/grub.cfg ファイルで、
linuxで始まる行にカーネルパラメーターidle=nomwaitを追加します。次の例は、変更されたファイルの内容を示しています。menuentry 'openSUSE Leap 15.1' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-20f5f35a-fbab-4c9c-8532-bb6c66ce****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 20f5f35a-fbab-4c9c-8532-bb6c66ce**** else search --no-floppy --fs-uuid --set=root 20f5f35a-fbab-4c9c-8532-bb6c66ce**** fi echo 'Loading Linux 4.12.14-lp151.28.52-default ...' linux /boot/vmlinuz-4.12.14-lp151.28.52-default root=UUID=20f5f35a-fbab-4c9c-8532-bb6c66ce**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 splash=silent mitigations=auto quiet idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-lp151.28.52-default }
Red Hat Enterprise Linux の問題
Red Hat Enterprise Linux 8 64 ビット:yum update コマンドでカーネルバージョンを更新できない
問題の説明:Red Hat Enterprise Linux 8 64 ビットオペレーティングシステムを実行している ECS インスタンスで、yum update コマンドを実行してカーネルバージョンを更新し、インスタンスを再起動します。カーネルバージョンが古いバージョンのままであることがわかります。
原因:RHEL 8 64 ビットオペレーティングシステムでは、GRand Unified Bootloader (GRUB) 2 の環境変数を格納する /boot/grub2/grubenv ファイルのサイズが異常です。ファイルサイズが標準の 1,024 バイトではないため、カーネルバージョンの更新に失敗します。
解決策:カーネルバージョンを更新した後、新しいカーネルバージョンをデフォルトの起動バージョンとして設定する必要があります。完全な操作は次のとおりです。
次のコマンドを実行して、カーネルバージョンを更新します。
yum update kernel -y次のコマンドを実行して、現在のオペレーティングシステムのカーネル起動パラメーターを取得します。
grub2-editenv list | grep kernelopts次のコマンドを実行して、古い /grubenv ファイルをバックアップします。
mv /boot/grub2/grubenv /home/grubenv.bak次のコマンドを実行して、新しい /grubenv ファイルを生成します。
grub2-editenv /boot/grub2/grubenv create次のコマンドを実行して、新しいカーネルバージョンをデフォルトの起動バージョンとして設定します。
この例では、更新された新しいカーネルバージョンは
/boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64です。grubby --set-default /boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64次のコマンドを実行して、カーネル起動パラメーターを設定します。
- set kerneloptsパラメーターは、ステップ 2 で取得した現在のオペレーティングシステムのカーネル起動パラメーターの値に手動で設定する必要があります。grub2-editenv - set kernelopts="root=UUID=0dd6268d-9bde-40e1-b010-0d3574b4**** ro crashkernel=auto net.ifnames=0 vga=792 console=tty0 console=ttyS0,115200n8 noibrs nosmt"次のコマンドを実行して、ECS インスタンスを新しいカーネルバージョンに再起動します。
reboot警告再起動操作はインスタンスを短時間停止させ、インスタンスで実行中のサービスを中断させる可能性があります。オフピーク時にインスタンスを再起動することを推奨します。
SUSE Linux Enterprise Server の問題
SUSE Linux Enterprise Server:SMT サーバーに接続できない
問題の説明:SUSE Linux Enterprise Server または SUSE Linux Enterprise Server for SAP の有料 Alibaba Cloud イメージを購入して使用すると、SMT サーバーがタイムアウトしたり、例外が発生したりすることがあります。コンポーネントをダウンロードまたは更新しようとすると、次のようなエラーメッセージが返されます。
登録サーバーから「このサーバーは、このサービスへのアクセスが許可されていることを確認できませんでした。」(500) が返されました
サービス 'SMT-http_mirrors_cloud_aliyuncs_com' のリポジトリインデックスファイルの取得に問題が発生しました ****
影響を受けるイメージ:SUSE Linux Enterprise Server および SUSE Linux Enterprise Server for SAP
解決策:SMT サービスを再登録してアクティベートする必要があります。
次のコマンドを順番に実行して、SMT サービスを再登録してアクティベートします。
SUSEConnect -d SUSEConnect --cleanup systemctl restart guestregister次のコマンドを実行して、SMT サービスのアクティベーションステータスを確認します。
SUSEConnect -s次のようなコマンド出力が返された場合、SMT サービスは正常にアクティベートされています。
[{"identifier":"SLES_SAP","version":"12.5","arch":"x86_64","status":"Registered"}]
SUSE Linux Enterprise Server 12 SP5:カーネルの更新により起動中にシステムがハングする可能性がある
問題の説明:SUSE Linux Enterprise Server (SLES) 12 SP5 より前のカーネルバージョンを SLES 12 SP5 にアップグレードした後、または SLES 12 SP5 の内部カーネルバージョンをアップグレードした後、特定の CPU タイプでインスタンスが起動時にハングすることがあります。既知の CPU タイプは
Intel® Xeon® CPU E5-2682 v4 @ 2.50GHzおよびIntel® Xeon® CPU E7-8880 v4 @ 2.20GHzです。対応するコールトレースのデバッグ結果は次のとおりです。[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **原因:新しいカーネルバージョンが CPU マイクロコードと互換性がありません。
解決策:
/boot/grub2/grub.cfgファイルで、linuxで始まる行にカーネルパラメーターidle=nomwaitを追加します。次の例は、変更されたファイルの内容を示しています。menuentry 'SLES 12-SP5' --class sles --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-fd7bda55-42d3-4fe9-a2b0-45efdced****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' fd7bda55-42d3-4fe9-a2b0-45efdced**** else search --no-floppy --fs-uuid --set=root fd7bda55-42d3-4fe9-a2b0-45efdced**** fi echo 'Loading Linux 4.12.14-122.26-default ...' linux /boot/vmlinuz-4.12.14-122.26-default root=UUID=fd7bda55-42d3-4fe9-a2b0-45efdced**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 mitigations=auto splash=silent quiet showopts idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-122.26-default }
その他の問題
最近のカーネルバージョンを実行する特定のインスタンスタイプのインスタンスを起動すると、コールトレースが発生する可能性がある
問題の説明:高バージョンのカーネル (たとえば、カーネルバージョン
4.18.0-240.1.1.el8_3.x86_64の RHEL 8.3 または CentOS 8.3) を実行する特定のインスタンスタイプ (たとえば、ecs.i2.4xlarge) のインスタンスを起動すると、以下に示すようなコールトレースが発生することがあります。Dec 28 17:43:45 localhost SELinux: Initializing. Dec 28 17:43:45 localhost kernel: Dentry cache hash table entries: 8388608 (order: 14, 67108864 bytes) Dec 28 17:43:45 localhost kernel: Inode-cache hash table entries: 4194304 (order: 13, 33554432 bytes) Dec 28 17:43:45 localhost kernel: Mount-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: Mountpoint-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: unchecked MSR access error: WRMSR to 0x3a (tried to write 0x000000000000****) at rIP: 0xffffffff8f26**** (native_write_msr+0x4/0x20) Dec 28 17:43:45 localhost kernel: Call Trace: Dec 28 17:43:45 localhost kernel: init_ia32_feat_ctl+0x73/0x28b Dec 28 17:43:45 localhost kernel: init_intel+0xdf/0x400 Dec 28 17:43:45 localhost kernel: identify_cpu+0x1f1/0x510 Dec 28 17:43:45 localhost kernel: identify_boot_cpu+0xc/0x77 Dec 28 17:43:45 localhost kernel: check_bugs+0x28/0xa9a Dec 28 17:43:45 localhost kernel: ? __slab_alloc+0x29/0x30 Dec 28 17:43:45 localhost kernel: ? kmem_cache_alloc+0x1aa/0x1b0 Dec 28 17:43:45 localhost kernel: start_kernel+0x4fa/0x53e Dec 28 17:43:45 localhost kernel: secondary_startup_64+0xb7/0xc0 Dec 28 17:43:45 localhost kernel: Last level iTLB entries: 4KB 64, 2MB 8, 4MB 8 Dec 28 17:43:45 localhost kernel: Last level dTLB entries: 4KB 64, 2MB 0, 4MB 0, 1GB 4 Dec 28 17:43:45 localhost kernel: FEATURE SPEC_CTRL Present Dec 28 17:43:45 localhost kernel: FEATURE IBPB_SUPPORT Present原因:これらのカーネルバージョンのコミュニティ更新には、モデル固有レジスタ (MSR) への書き込みを試みるパッチが含まれています。しかし、ecs.i2.4xlarge などの一部のインスタンスタイプは、仮想化バージョンのために MSR への書き込みをサポートしておらず、このコールトレースが発生します。
解決策:このコールトレースは、システムの通常の使用や安定性には影響しません。このエラーは無視できます。
特定の Linux カーネルバージョンと hfg6 高クロック速度汎用インスタンスファミリー間の互換性の問題により、カーネルパニックが発生する可能性がある
問題の説明:Linux コミュニティの一部のシステム (CentOS 8、SUSE Linux Enterprise Server 15 SP2、OpenSUSE 15.2 など) では、hfg6 高周波汎用インスタンスファミリーのインスタンスで新しいカーネルバージョンにアップグレードすると、カーネルパニックが発生することがあります。コールトレースデバッグの例は次のとおりです。
原因:hfg6 高周波汎用インスタンスファミリーと一部の Linux カーネルバージョンとの間に互換性の問題があります。
解決策:
SUSE Linux Enterprise Server 15 SP2 および OpenSUSE 15.2 の最新カーネルバージョンでは、この問題が修正されています。コミット内容は次のとおりです。アップグレードした最新カーネルバージョンにこの内容が含まれている場合、hfg6 インスタンスファミリーと互換性があります。
commit 1e33d5975b49472e286bd7002ad0f689af33fab8 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:51:09 2020 +0200 x86, sched: Bail out of frequency invariance if turbo_freq/base_freq gives 0 (bsc#1176925). suse-commit: a66109f44265ff3f3278fb34646152bc2b3224a5 commit dafb858aa4c0e6b0ce6a7ebec5e206f4b3cfc11c Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:16:50 2020 +0200 x86, sched: Bail out of frequency invariance if turbo frequency is unknown (bsc#1176925). suse-commit: 53cd83ab2b10e7a524cb5a287cd61f38ce06aab7 commit 22d60a7b159c7851c33c45ada126be8139d68b87 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:10:30 2020 +0200 x86, sched: check for counters overflow in frequency invariant accounting (bsc#1176925).yum update コマンドを使用して CentOS 8 システムを hfg6 高周波汎用インスタンスファミリーのインスタンスでカーネルバージョン
kernel-4.18.0-240以降にアップグレードすると、カーネルパニックが発生することがあります。この問題が発生した場合は、以前のカーネルバージョンにロールバックしてください。
pip リクエストのタイムアウト
問題の説明:pip リクエストが時々タイムアウトしたり、失敗したりします。
影響を受けるイメージ:CentOS、Debian、Ubuntu、SUSE、OpenSUSE、および Alibaba Cloud Linux。
原因:Alibaba Cloud は次の 3 つの pip ソースアドレスを提供しています。デフォルトのエンドポイントは mirrors.aliyun.com です。このエンドポイントにアクセスするインスタンスは、インターネットにアクセスできる必要があります。ご利用のインスタンスにパブリック IP アドレスが割り当てられていない場合、pip リクエストはタイムアウトします。
(デフォルト) インターネット:mirrors.aliyun.com
VPC 内部ネットワーク:mirrors.cloud.aliyuncs.com
クラシックネットワーク内部ネットワーク:mirrors.aliyuncs.com
解決策:この問題を解決するには、次のいずれかの方法を使用できます。
方法 1
EIP をアタッチして、インスタンスにパブリック IP アドレスを割り当てます。詳細については、「クラウドリソースへの EIP のアタッチ」をご参照ください。
サブスクリプションインスタンスの場合、インスタンスのスペックアップまたはスペックダウンによってパブリック IP アドレスを再割り当てすることもできます。詳細については、「サブスクリプションインスタンスのインスタンスタイプのアップグレード」をご参照ください。
方法 2
pip の応答が遅延する場合、ECS インスタンスで fix_pypi.sh スクリプトを実行してから、pip 操作を再試行できます。手順は次のとおりです。
インスタンスに接続します。
詳細については、「VNC を使用したインスタンスへの接続」をご参照ください。
次のコマンドを実行して、スクリプトファイルを取得します。
wget http://image-offline.oss-cn-hangzhou.aliyuncs.com/fix/fix_pypi.shスクリプトを実行します。
VPC インスタンス:コマンド
bash fix_pypi.sh "mirrors.cloud.aliyuncs.com"を実行します。クラシックネットワークインスタンス:コマンド
bash fix_pypi.sh "mirrors.aliyuncs.com"を実行します。
pip 操作を再試行します。
fix_pypi.sh スクリプトの内容は次のとおりです。
#!/bin/bash function config_pip() { pypi_source=$1 if [[ ! -f ~/.pydistutils.cfg ]]; then cat > ~/.pydistutils.cfg << EOF [easy_install] index-url=http://$pypi_source/pypi/simple/ EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pydistutils.cfg fi if [[ ! -f ~/.pip/pip.conf ]]; then mkdir -p ~/.pip cat > ~/.pip/pip.conf << EOF [global] index-url=http://$pypi_source/pypi/simple/ [install] trusted-host=$pypi_source EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pip/pip.conf sed -i "s#trusted-host.*#trusted-host=$pypi_source#" ~/.pip/pip.conf fi } config_pip $1