このトピックでは、BigDL Privacy Preserving Machine Learning(BigDL PPML)を使用して、Intel® TDX 対応 g8i インスタンス上で、分散型のエンドツーエンドでセキュアな Apache Spark ビッグデータ分析アプリケーションを実行する方法について説明します。
背景情報
企業がデータと計算リソースをクラウドに移行するにつれて、データのプライバシーと機密性の保護は、ビッグデータ分析と AI アプリケーションにとって重要な課題となっています。
BigDL PPML を使用すると、転送中および使用中のデータを保護し、アプリケーションの整合性を保証しながら、Alibaba Cloud TDX インスタンス上で標準のビッグデータおよび AI アプリケーション(Apache Spark、Apache Flink、Tensorflow、PyTorch など)を実行できます。詳細については、「BigDL-PPML」をご参照ください。
Intel® Trusted Domain Extensions(Intel® TDX)は、データを保護するためのハードウェア支援セキュリティを提供します。ファームウェア、ホストのセキュリティステータスとは無関係であり、物理マシン上に機密コンピューティング環境を構築できます。
Alibaba Cloud g8i インスタンスは、Intel® TDX 対応インスタンス(以下、TDX インスタンス)であり、TDX 機密コンピューティング機能を提供し、ハードウェアで強化された保護を備えた、より安全で信頼性の高い機密環境を作成します。 TDX インスタンスは、マルウェア攻撃に関連するリスクを軽減し、高レベルのデータプライバシーとアプリケーションの整合性を実現します。
BigDL PPML は、Intel® TDX に基づいて開発されたソリューションであり、データ分析と AI アプリケーションを保護します。
アーキテクチャ
BigDL PPML を使用することにより、コードを変更することなく、Apache Spark、Apache Flink、Tensorflow、PyTorch などの既存の分散ビッグデータ分析および AI アプリケーションを機密環境で実行できます。ビッグデータ分析および AI アプリケーションは、TDX インスタンスに基づく Kubernetes クラスタ上で実行され、計算とメモリは Intel® TDX によって保護されます。 BigDL PPML は、基盤となるレイヤーで分散アプリケーション向けの以下のエンドツーエンドのセキュリティメカニズムを有効にします。
TDX インスタンスに基づく Kubernetes クラスタで、信頼できるクラスタ環境を提供および証明するセキュリティメカニズム。
Key Management Service(KMS):キーを管理し、キーを使用して分散データを暗号化および復号します。
セキュアな分散コンピューティングと通信。
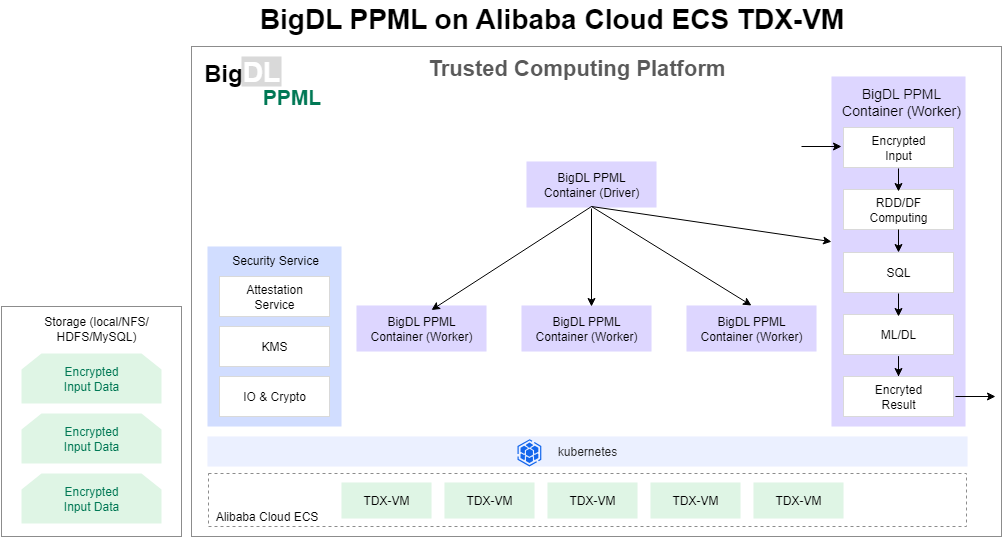
BigDL PPML は、前の図に示すように、Intel® TDX 対応インスタンスに基づいてデプロイされた Kubernetes クラスタ内のエンドツーエンドのビッグデータおよび AI パイプラインを保護します。すべてのデータは暗号化され、データレイクとデータウェアハウスに保存されます。
BigDL PPML ワーカーは、暗号化された入力データを読み込み、リモートアテステーションを実行するか、KMS を使用してデータキーを取得し、キーを使用して TDX インスタンス上の入力データを復号します。
BigDL PPML ワーカーは、ビッグデータおよび AI コンピューティングフレームワークを使用して、分散方式でデータを前処理し、モデルをトレーニングし、モデルを使用して推論を実行します。
BigDL PPML ワーカーは、最終結果、出力データ、またはモデルを暗号化し、分散ストレージに書き込みます。
ノード間で転送されるデータは、Advanced Encryption Standard(AES)や Transport Layer Security などのセキュリティプロトコルに基づいて転送中に暗号化され、データのエンドツーエンドのセキュリティとプライバシーを確保します。
手順
このセクションでは、TDX インスタンス上で分散型のエンドツーエンドでセキュアなビッグデータ分析アプリケーションを実行する方法について説明します。この例では、Apache Spark ビッグデータ分析アプリケーションと Simple Query の例を使用します。ビッグデータおよび AI アプリケーションの使用方法については、「BigDL PPML チュートリアルと例」をご参照ください。
ステップ 1:Kubernetes クラスタとランタイム環境をデプロイする
このトピックでは、マスターノードと 2 つのワーカーノードで構成される Kubernetes クラスタを使用します。クラスタ内のノード数は、購入した TDX インスタンスの数と同じである必要があります。ビジネス要件に基づいて、特定の数のノードで構成される Kubernetes クラスタを作成できます。
Intel® TDX 対応 g8i インスタンスを作成します。
詳細については、「カスタム起動タブでインスタンスを作成する」をご参照ください。次のパラメータに注意してください。
インスタンスタイプ:Simple Query の例をサポートするインスタンスタイプを選択します。 Simple Query の例をサポートするには、インスタンスタイプに少なくとも 32 個の vCPU と 64 GiB のメモリが必要です。このトピックでは、ecs.g8i.8xlarge インスタンスタイプを使用します。
イメージ:Alibaba Cloud Linux 3.2104 LTS 64 ビットを選択します。
パブリック IP アドレス:パブリック IPv4 アドレスの割り当てを選択します。
数量:3 と入力します。
インスタンスに接続します。
詳細については、「ECS インスタンスに接続する方法」をご参照ください。
Kubernetes クラスタをデプロイし、セキュリティ設定を構成します。
g8i インスタンスに Kubernetes クラスタをデプロイします。
詳細については、「kubeadm を使用したクラスタの作成」をご参照ください。
Kubernetes クラスタのマスターノードで、次のコマンドを実行してセキュリティ設定(ロールベースのアクセス制御設定)を構成します。
kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
PersistentVolume を作成します。
ルートユーザーとして次のコマンドを実行して、pv-volume.yaml ファイルを作成します。
vim pv-volume.yamlI キーを押して、
[挿入モード]に入ります。pv-volume.yaml に次のコンテンツを追加します。
apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume labels: type: local spec: storageClassName: manual capacity: storage: 10Gi accessModes: - ReadWriteOnce hostPath: path: "/mnt/data"Esc キーを押し、
:wqと入力して変更を保存し、[挿入モード]を終了します。次のコマンドを実行して PersistentVolume を作成し、PersistentVolume を表示します。
kubectl apply -f pv-volume.yaml kubectl get pv task-pv-volume
PersistentVolumeClaim を作成します。
ルートユーザーとして次のコマンドを実行して、pv-claim.yaml ファイルを作成します。
vim pv-claim.yamlI キーを押して、
[挿入モード]に入ります。pv-claim.yaml に次のコンテンツを追加します。
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pv-claim spec: storageClassName: manual accessModes: - ReadWriteOnce resources: requests: storage: 3GiEsc キーを押し、
:wqと入力して変更を保存し、[挿入モード]を終了します。次のコマンドを実行して PersistentVolumeClaim を作成し、PersistentVolumeClaim を表示します。
kubectl apply -f pv-claim.yaml kubectl get pvc task-pv-claim
ステップ 2:トレーニングデータを暗号化する
Kubernetes クラスタの各ノードで次のコマンドを実行して、BigDL PPML イメージを取得します。
このイメージは、標準の Apache Spark アプリケーションを実行するために使用され、データの暗号化および復号機能を提供します。
docker pull intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOTトレーニングデータセットファイル people.csv を生成します。
Kubernetes クラスタのマスターノードで次のコマンドを実行して、トレーニングスクリプト generate_people_csv.py をダウンロードします。
wget https://github.com/intel-analytics/BigDL/raw/main/ppml/scripts/generate_people_csv.py次のコマンドを実行して、トレーニングデータセットファイル people.csv を生成します。
python generate_people_csv.py </save/path/of/people.csv> <num_lines>説明</save/path/of/people.csv> を、people.csv ファイルを生成するパスに設定します。この例では、/home/user パスを使用します。
<num_lines> を、people.csv の行数に設定します。この例では、行数は 500 です。
次のコマンドを実行して、people.csv を特定のディレクトリに移動します。
sudo scp /home/user/people.csv /mnt/data/simplekms/重要/home/userを実際のディレクトリに置き換えます。この例では、
/mnt/data/simplekms/ディレクトリを使用します。/mnt/data/simplekms/ディレクトリには、暗号化および復号されたデータが保存されます。このトピックの以降のセクションでは、これについて個別に詳しく説明していません。
Kubernetes クラスタのマスターノードで次のコマンドを実行して、bigdl-ppml-client コンテナを実行します。
このコンテナは、トレーニングデータの暗号化と復号に使用されます。
説明bigdl-ppml-client コンテナを実行するユーザーに基づいて、
/home/user/kuberconfig:/root/.kube/configを置き換えます。ルートユーザーがコンテナを実行する場合は、/home/user/kuberconfig:/root/.kube/config を
/root/kuberconfig:/root/.kube/configに置き換えます。test ユーザーなどの共通ユーザーがコンテナを実行する場合は、/home/user/kuberconfig:/root/.kube/config を
/home/test/kuberconfig:/root/.kube/configに置き換えます。
export K8S_MASTER=k8s://$(kubectl cluster-info | grep 'https.*6443' -o -m 1) echo The k8s master is $K8S_MASTER . export SPARK_IMAGE=intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT sudo docker run -itd --net=host \ -v /etc/kubernetes:/etc/kubernetes \ -v /home/user/kuberconfig:/root/.kube/config \ -v /mnt/data:/mnt/data \ -e RUNTIME_SPARK_MASTER=$K8S_MASTER \ -e RUNTIME_K8S_SPARK_IMAGE=$SPARK_IMAGE \ -e RUNTIME_PERSISTENT_VOLUME_CLAIM=task-pv-claim \ --name bigdl-ppml-client \ $SPARK_IMAGE bash docker exec -it bigdl-ppml-client bashKubernetes クラスタのマスターノードで people.csv を暗号化します。
次のコマンドを実行して、アプリケーション ID(APPID)と API キー(APIKEY)に基づいてプライマリキー(primarykey)を生成します。
simple KMS を使用して、1 ~ 12 文字のアプリケーション ID と API キーを生成できます。この例では、APPID の値は 98463816****、APIKEY の値は 15780936**** です。 --primaryKeyPath は、プライマリキーを保存するディレクトリを指定します。
java -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ com.intel.analytics.bigdl.ppml.examples.GeneratePrimaryKey \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****暗号化スクリプト encrypt.py を作成します。
次のコマンドを実行して、
/mnt/data/simplekmsディレクトリに切り替えます。cd /mnt/data/simplekms次のコマンドを実行して、encrypt.py ファイルを作成して開きます。
sudo vim encrypt.pyI キーを押して、
[挿入モード]に入ります。encrypt.py ファイルに次のコンテンツを追加します。
# encrypt.py from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) csv_plain_path = "/mnt/data/simplekms/people.csv" csv_plain_df = sc.read(CryptoMode.PLAIN_TEXT) \ .option("header", "true") \ .csv(csv_plain_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/encrypted-input" sc.write(csv_plain_df, CryptoMode.AES_CBC_PKCS5PADDING) \ .mode('overwrite') \ .option("header", True) \ .csv(output_path)Esc キーを押し、
:wqと入力して変更を保存し、[挿入モード]を終了します。
bigdl-ppml-client コンテナで次のコマンドを実行して、APPID、APIKEY、および primarykey を使用して people.csv を暗号化します。
暗号化されたデータは、
/mnt/data/simplekms/encrypted-outputディレクトリに保存されます。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/encrypt.py
Kubernetes クラスタの各ワーカーノードで次のコマンドを実行して、マスターノードから各ワーカーノードに
/mnt/data/simplekmsをコピーします。cd /mnt/data sudo scp -r user@192.168.XXX.XXX:/mnt/data/simplekms .説明user をマスターノードの実際のユーザー名に置き換え、192.168.XXX.XXX をマスターノードの実際の IP アドレスに置き換えます。
ステップ 3:BigDL PPML ベースのビッグデータ分析の例を実行する
bigdl-ppml-client コンテナで、Apache Spark ジョブを Kubernetes クラスタに送信して、Simple Query の例を実行します。
説明spark.driver.host=192.168.XXX.XXX では、192.168.XXX.XXX をマスターノードの実際の IP アドレスに置き換えます。
${SPARK_HOME}/bin/spark-submit \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --name spark-simplequery-tdx \ --conf spark.driver.memory=4g \ --conf spark.executor.cores=4 \ --conf spark.executor.memory=4g \ --conf spark.executor.instances=2 \ --conf spark.driver.host=192.168.XXX.XXX \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.cores.max=8 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.kubernetes.executor.deleteOnTermination=false \ --conf spark.driver.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.executor.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.kubernetes.file.upload.path=/mnt/data \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --jars local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --inputPath /mnt/data/simplekms/encrypted-input \ --outputPath /mnt/data/simplekms/encrypted-output \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****マスターノードで Apache Spark ジョブのステータスを表示します。
次のコマンドを実行して、ドライバーとエグゼキュータの名前とステータスを表示します。
kubectl get podApache Spark ジョブが完了すると、STATUS の値が
RunningからCompletedに変わります。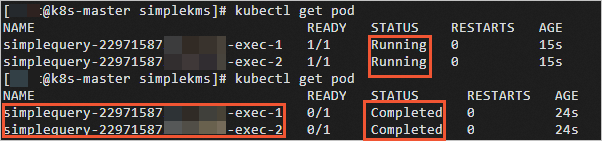
次のコマンドを実行して、ポッドのログを表示します。
kubectl logs simplequery-xxx-exec-1説明simplequery-xxx-exec-1 を、前のステップで取得した対応する Name の値に置き換えます。
Apache Spark ジョブが完了すると、ポッドのログに
Finishedと表示されます。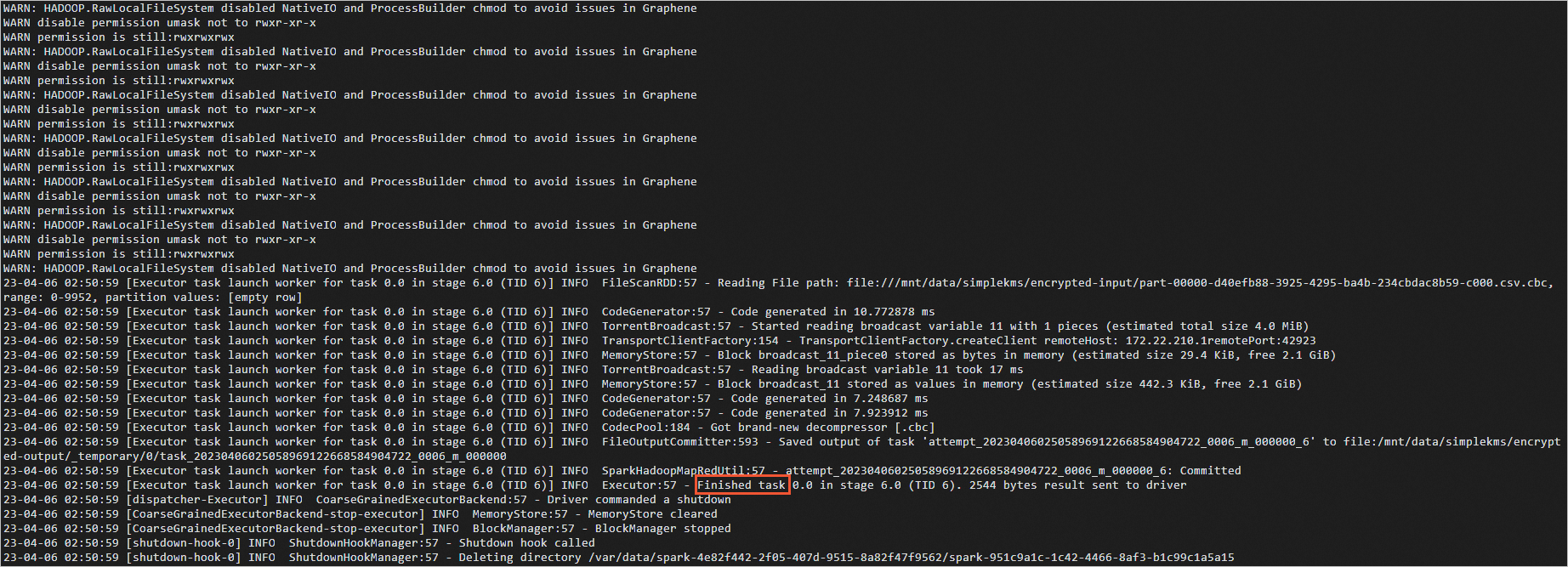
ステップ 4:結果を復号する
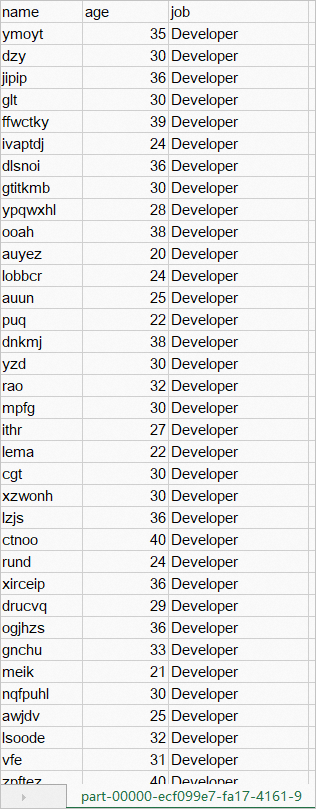
各ワーカーノードの encrypted-output ディレクトリに保存されている
.metaファイルとpart-XXXX.csv.cbcファイルを、マスターノードの encrypted-output ディレクトリにアップロードします。ファイルがアップロードされると、マスターノードの encrypted-output ディレクトリには、次の図に示すようにデータが含まれます。

マスターノードの
/mnt/data/simplekmsディレクトリに、decrypt.py ファイルを作成します。次のコマンドを実行して、
/mnt/data/simplekmsディレクトリに切り替えます。cd /mnt/data/simplekms次のコマンドを実行して、decrypt.py ファイルを作成して開きます。
sudo vim decrypt.pyI キーを押して、
[挿入モード]に入ります。decrypt.py ファイルに次のコンテンツを追加します。
from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) encrypted_csv_path = "/mnt/data/simplekms/encrypted-output" csv_plain_df = sc.read(CryptoMode.AES_CBC_PKCS5PADDING) \ .option("header", "true") \ .csv(encrypted_csv_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/decrypted-output" sc.write(csv_plain_df, CryptoMode.PLAIN_TEXT) \ .mode('overwrite') \ .option("header", True)\ .csv(output_path)Esc キーを押し、
:wqと入力して変更を保存し、[挿入モード]を終了します。
Kubernetes クラスタのマスターノードで次のコマンドを実行して、
encrypted_csv_pathディレクトリに保存されているデータを復号します。APPID、APIKEY、および primarykey を使用してデータを復号します。復号されたデータファイル
part-XXXX.csvは、/mnt/data/simplekms/decrypted-outputディレクトリに保存されます。java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/decrypt.py復号されたデータは、次の図に示すように Windows に表示されます。