このトピックでは、追跡されたデータを使用するために Kafka クライアントのデモを使用する方法について説明します。新しいバージョンの変更追跡機能を使用すると、V0.11 から V2.7 の Kafka クライアントを使用して追跡されたデータを使用できます。
使用上の注意
変更追跡機能を使用するときに自動コミットを有効にすると、一部のデータが使用される前にコミットされる場合があります。これにより、データが失われる可能性があります。手動でデータをコミットすることをお勧めします。
説明データのコミットに失敗した場合、クライアントを再起動して、最後に記録された消費チェックポイントからデータの消費を続行できます。ただし、この期間中に重複データが生成される可能性があります。重複データは手動で除外する必要があります。
データはシリアル化され、Avro 形式で保存されます。詳細については、「Record.avsc」をご参照ください。
警告このトピックで説明されている Kafka クライアントを使用していない場合は、Avro スキーマ に基づいて追跡されたデータを解析し、解析されたデータを確認する必要があります。
Data Transmission Service (DTS) が
offsetForTimes操作を呼び出す場合、検索単位は秒です。ネイティブ Kafka クライアントがこの操作を呼び出す場合、検索単位はミリ秒です。ディザスタリカバリなど、いくつかの理由により、Kafka クライアントと変更追跡サーバー間で一時的な接続が発生する場合があります。このトピックで説明されている Kafka クライアントを使用していない場合は、Kafka クライアントにネットワーク再接続機能が必要です。
ネイティブ Kafka クライアントを使用して追跡されたデータを使用する場合、DTS で増分データ収集モジュールが変更される可能性があります。サブスクライブモードでは、Kafka クライアントが DTS サーバーに保存する消費チェックポイントは削除されます。ビジネス要件に基づいて追跡されたデータを使用するには、消費チェックポイントを指定する必要があります。サブスクライブモードでデータを使用する場合は、DTS が提供する SDK デモを使用してデータを追跡および使用するか、消費チェックポイントを手動で管理することをお勧めします。詳細については、「SDK デモを使用して追跡されたデータを使用する」およびこのトピックの「消費チェックポイントを管理する」セクションをご参照ください。
Kafka クライアントを実行する
Kafka クライアントデモ をダウンロードします。デモの使用方法の詳細については、「Readme」をご参照ください。
 をクリックし、[ZIP をダウンロード] を選択してパッケージをダウンロードします。
をクリックし、[ZIP をダウンロード] を選択してパッケージをダウンロードします。バージョン 2.0 の Kafka クライアントを使用する場合は、subscribe_example-master/javaimpl/pom.xml ファイルのバージョン番号を 2.0.0 に変更する必要があります。
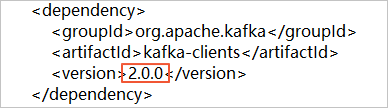
表 1 処理の説明
ステップ | 関連ディレクトリまたはファイル |
1. ネイティブ Kafka コンシューマーを使用して、変更追跡インスタンスから増分データを取得します。 | subscribe_example-master/javaimpl/src/main/java/recordgenerator/ |
2. 増分データのイメージを逆シリアル化し、pre-image、post-image、およびその他の属性を取得します。 警告
| subscribe_example-master/javaimpl/src/main/java/boot/RecordPrinter.java |
3. 逆シリアル化されたデータの dataTypeNumber 値を、対応するデータベースのデータ型に変換します。 説明 詳細については、このトピックの「データ型と dataTypeNumber 値のマッピング」セクションをご参照ください。 | subscribe_example-master/javaimpl/src/main/java/recordprocessor/mysql/ |
手順
次の手順は、Kafka クライアントを実行して追跡されたデータを使用する方法を示しています。この例では、Windows 用 IntelliJ IDEA Community Edition 2018.1.4 を使用しています。
変更追跡インスタンスを作成します。詳細については、「変更追跡シナリオの概要」をご参照ください。
1 つ以上のコンシューマーグループを作成します。詳細については、「コンシューマーグループを作成する」をご参照ください。
Kafka クライアントデモ のパッケージをダウンロードし、パッケージを解凍します。
説明 をクリックし、[ZIP をダウンロード] を選択してパッケージをダウンロードします。IntelliJ IDEA を開きます。表示されるウィンドウで、[開く] をクリックします。

表示されるダイアログボックスで、ダウンロードしたデモが存在するディレクトリに移動します。pom.xml ファイルを見つけます。
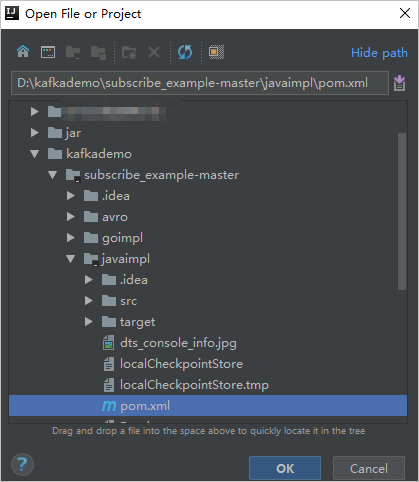
表示されるダイアログボックスで、[プロジェクトとして開く] を選択します。
IntelliJ IDEA の [プロジェクト] ツールウィンドウで、フォルダをクリックして Kafka クライアントのデモファイルを見つけ、ファイルをダブルクリックします。ファイル名は NotifyDemoDB.java です。
NotifyDemoDB.java ファイルのパラメーターを指定します。
パラメーター
説明
パラメーター値を取得する方法
USER_NAME
コンシューマーグループアカウントのユーザー名。
警告このトピックで説明されている Kafka クライアントを使用していない場合は、
<ユーザー名>-<コンシューマーグループ ID>の形式でこのパラメーターを指定する必要があります。例:dtstest-dtsae******bpv。そうしないと、接続に失敗します。DTS コンソールで、管理する変更追跡インスタンスを見つけ、インスタンス ID をクリックします。左側のナビゲーションウィンドウで、データ消費 をクリックします。表示されるページで、コンシューマーグループの ID や名前、アカウントなどの情報を表示できます。
説明コンシューマーグループアカウントのパスワードは、コンシューマーグループの作成時に指定されます。
PASSWORD_NAME
アカウントのパスワード。
SID_NAME
コンシューマーグループの ID。
GROUP_NAME
コンシューマーグループの名前。このパラメーターをコンシューマーグループ ID に設定します。
KAFKA_TOPIC
変更追跡インスタンスの追跡されたトピックの名前。
DTS コンソールで、管理する変更追跡インスタンスを見つけ、インスタンス ID をクリックします。基本情報 ページで、トピックとネットワークに関する情報を表示できます。
KAFKA_BROKER_URL_NAME
変更追跡インスタンスのエンドポイント。
説明内部ネットワークを介してデータの変更を追跡する場合、ネットワーク遅延は最小限です。これは、Kafka クライアントをデプロイする Elastic Compute Service (ECS) インスタンスが、変更追跡インスタンスと同じクラシックネットワークまたは同じ virtual private cloud (VPC) に存在する場合に適用されます。
ネットワークの安定性を確保するために、パブリックエンドポイントを使用しないことをお勧めします。
INITIAL_CHECKPOINT_NAME
使用済みデータの消費チェックポイント。値は UNIX タイムスタンプです。例: 1592269238。
説明次の理由により、消費チェックポイントを保存する必要があります。
消費プロセスが中断された場合、Kafka クライアントで消費チェックポイントを指定して、データ消費を再開できます。これにより、データの損失を防ぎます。
Kafka クライアントを起動するときに、消費チェックポイントを指定して、ビジネス要件に基づいてデータを使用できます。
SUBSCRIBE_MODE_NAME パラメーターが subscribe に設定されている場合、指定した INITIAL_CHECKPOINT_NAME パラメーターは、Kafka クライアントを初めて起動したときにのみ有効になります。
使用済みデータの消費チェックポイントは、変更追跡インスタンスのデータ範囲内である必要があります。消費チェックポイントは UNIX タイムスタンプに変換する必要があります。
説明変更追跡インスタンスのデータ範囲は、[変更追跡タスク] ページの データ範囲 列に表示されます。
検索エンジンを使用して、UNIX タイムスタンプコンバーターを取得できます。
USE_CONFIG_CHECKPOINT_NAME
クライアントが指定された消費チェックポイントからデータを強制的に使用するかどうかを指定します。デフォルト値: true。このパラメーターを true に設定して、受信したが処理されていないデータが失われないようにすることができます。
なし
SUBSCRIBE_MODE_NAME
コンシューマーグループに 2 つ以上の Kafka クライアントを実行するかどうかを指定します。この機能を使用する場合は、これらの Kafka クライアントに対してこのパラメーターを subscribe に設定します。
デフォルト値は assign で、この機能が使用されていないことを示します。コンシューマーグループには 1 つの Kafka クライアントのみをデプロイすることをお勧めします。
なし
IntelliJ IDEA のトップメニューバーで、 を選択してクライアントを実行します。
説明IntelliJ IDEA を初めて実行する場合は、関連する依存関係のロードとインストールに特定の期間が必要です。
Kafka クライアントの結果
次の図は、Kafka クライアントがソースデータベースからのデータ変更を追跡できることを示しています。

//// ログ情報 (ret)NotifyDemoDB.java ファイルの 25 行目の 文字列から二重スラッシュ () を削除できます。次に、クライアントを再実行して、データ変更情報を表示します。
FAQ
Q: Kafka クライアントの消費チェックポイントを記録する必要があるのはなぜですか?
A: DTS によって記録された消費チェックポイントは、DTS が Kafka クライアントからコミット操作を受信した時点です。記録された消費チェックポイントは、実際の消費時間と異なる場合があります。ビジネスアプリケーションまたは Kafka クライアントが予期せず中断された場合、正確な消費チェックポイントを指定してデータ消費を続行できます。これにより、データの損失または重複データの消費を防ぎます。
消費チェックポイントを管理する
DTS でデータ収集モジュールのスイッチオーバーをリッスンするように Kafka クライアントを構成します。
Kafka クライアントのコンシューマーのプロパティを構成して、DTS でデータ収集モジュールのスイッチオーバーをリッスンできます。次のコードは、コンシューマーのプロパティを構成する方法の例を示しています。
properties.setProperty(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, ClusterSwitchListener.class.getName()); // DTSのデータ収集モジュールのスイッチオーバーをリッスンするようにコンシューマープロパティを設定します次のコードは、ClusterSwitchListener を実装する方法の例を示しています。
public class ClusterSwitchListener implements ClusterResourceListener, ConsumerInterceptor { private final static Logger LOG = LoggerFactory.getLogger(ClusterSwitchListener.class); // ロガーを初期化します private ClusterResource originClusterResource = null; // 元のクラスタリソース private ClusterResource currentClusterResource = null; // 現在のクラスタリソース public ConsumerRecords onConsume(ConsumerRecords records) { return records; // レコードを返します } public void close() { } // クローズ操作 public void onCommit(Map offsets) { } // コミット操作 public void onUpdate(ClusterResource clusterResource) { // クラスタリソースの更新 synchronized (this) { originClusterResource = currentClusterResource; // 元のクラスタリソースを更新 currentClusterResource = clusterResource; // 現在のクラスタリソースを更新 if (null == originClusterResource) { LOG.info("Cluster updated to " + currentClusterResource.clusterId()); // クラスタが更新されたことをログに記録します } else { if (originClusterResource.clusterId().equals(currentClusterResource.clusterId())) { LOG.info("Cluster not changed on update:" + clusterResource.clusterId()); // クラスタが変更されていないことをログに記録します } else { LOG.error("Cluster changed"); // クラスタが変更されたことをログに記録します throw new ClusterSwitchException("Cluster changed from " + originClusterResource.clusterId() + " to " + currentClusterResource.clusterId() + ", consumer require restart"); // クラスタが変更された例外をスローします } } } } public boolean isClusterResourceChanged() { // クラスタリソースが変更されたかどうかを確認します if (null == originClusterResource) { return false; // 元のクラスタリソースがnullの場合はfalseを返します } if (originClusterResource.clusterId().equals(currentClusterResource.clusterId())) { return false; // クラスタIDが同じ場合はfalseを返します } return true; // クラスタリソースが変更された場合はtrueを返します } public void configure(Map<String, ?> configs) { } // 構成 public static class ClusterSwitchException extends KafkaException { // クラスタスイッチ例外 public ClusterSwitchException(String message, Throwable cause) { super(message, cause); // メッセージと原因を持つ例外を構築します } public ClusterSwitchException(String message) { super(message); // メッセージを持つ例外を構築します } public ClusterSwitchException(Throwable cause) { super(cause); // 原因を持つ例外を構築します } public ClusterSwitchException() { super(); // 例外を構築します } } }DTS でキャプチャされたデータ収集モジュールのスイッチオーバーに基づいて、消費チェックポイントを指定します。
次のデータ追跡の開始消費チェックポイントを、クライアントによって使用された最新の追跡データエントリのタイムスタンプに設定します。次のコードは、消費チェックポイントを指定する方法の例を示しています。
try{ //何らかのアクションを実行します } catch (ClusterSwitchListener.ClusterSwitchException e) { // クラスタスイッチ例外をキャッチします reset(); // 消費チェックポイントをリセットします } // 消費チェックポイントをリセットします。 public reset() { long offset = kafkaConsumer.offsetsForTimes(timestamp); // タイムスタンプに基づいてオフセットを取得します kafkaConsumer.seek(tp,offset); // オフセットを設定します }説明例の詳細については、「KafkaRecordFetcher」をご参照ください。
データ型と dataTypeNumber 値のマッピング
MySQL データ型と dataTypeNumber 値のマッピング
MySQL データ型 | dataTypeNumber の値 |
MYSQL_TYPE_DECIMAL | 0 |
MYSQL_TYPE_INT8 | 1 |
MYSQL_TYPE_INT16 | 2 |
MYSQL_TYPE_INT32 | 3 |
MYSQL_TYPE_FLOAT | 4 |
MYSQL_TYPE_DOUBLE | 5 |
MYSQL_TYPE_NULL | 6 |
MYSQL_TYPE_TIMESTAMP | 7 |
MYSQL_TYPE_INT64 | 8 |
MYSQL_TYPE_INT24 | 9 |
MYSQL_TYPE_DATE | 10 |
MYSQL_TYPE_TIME | 11 |
MYSQL_TYPE_DATETIME | 12 |
MYSQL_TYPE_YEAR | 13 |
MYSQL_TYPE_DATE_NEW | 14 |
MYSQL_TYPE_VARCHAR | 15 |
MYSQL_TYPE_BIT | 16 |
MYSQL_TYPE_TIMESTAMP_NEW | 17 |
MYSQL_TYPE_DATETIME_NEW | 18 |
MYSQL_TYPE_TIME_NEW | 19 |
MYSQL_TYPE_JSON | 245 |
MYSQL_TYPE_DECIMAL_NEW | 246 |
MYSQL_TYPE_ENUM | 247 |
MYSQL_TYPE_SET | 248 |
MYSQL_TYPE_TINY_BLOB | 249 |
MYSQL_TYPE_MEDIUM_BLOB | 250 |
MYSQL_TYPE_LONG_BLOB | 251 |
MYSQL_TYPE_BLOB | 252 |
MYSQL_TYPE_VAR_STRING | 253 |
MYSQL_TYPE_STRING | 254 |
MYSQL_TYPE_GEOMETRY | 255 |
Oracle データ型と dataTypeNumber 値のマッピング
Oracle データ型 | dataTypeNumber の値 |
VARCHAR2/NVARCHAR2 | 1 |
NUMBER/FLOAT | 2 |
LONG | 8 |
DATE | 12 |
RAW | 23 |
LONG RAW | 24 |
UNDEFINED | 29 |
XMLTYPE | 58 |
ROWID | 69 |
CHAR and NCHAR | 96 |
BINARY_FLOAT | 100 |
BINARY_DOUBLE | 101 |
CLOB/NCLOB | 112 |
BLOB | 113 |
BFILE | 114 |
TIMESTAMP | 180 |
TIMESTAMP WITH TIME ZONE | 181 |
INTERVAL YEAR TO MONTH | 182 |
INTERVAL DAY TO SECOND | 183 |
UROWID | 208 |
TIMESTAMP WITH LOCAL TIME ZONE | 231 |
PostgreSQL データ型と dataTypeNumber 値のマッピング
PostgreSQL データ型 | dataTypeNumber の値 |
INT2/SMALLINT | 21 |
INT4/INTEGER/SERIAL | 23 |
INT8/BIGINT | 20 |
CHARACTER | 18 |
CHARACTER VARYING | 1043 |
REAL | 700 |
DOUBLE PRECISION | 701 |
NUMERIC | 1700 |
MONEY | 790 |
DATE | 1082 |
TIME/TIME WITHOUT TIME ZONE | 1083 |
TIME WITH TIME ZONE | 1266 |
TIMESTAMP/TIMESTAMP WITHOUT TIME ZONE | 1114 |
TIMESTAMP WITH TIME ZONE | 1184 |
BYTEA | 17 |
TEXT | 25 |
JSON | 114 |
JSONB | 3082 |
XML | 142 |
UUID | 2950 |
POINT | 600 |
LSEG | 601 |
PATH | 602 |
BOX | 603 |
POLYGON | 604 |
LINE | 628 |
CIDR | 650 |
CIRCLE | 718 |
MACADDR | 829 |
INET | 869 |
INTERVAL | 1186 |
TXID_SNAPSHOT | 2970 |
PG_LSN | 3220 |
TSVECTOR | 3614 |
TSQUERY | 3615 |