このトピックでは、Kafkaクライアントのデモを使用して追跡データを使用する方法について説明します。 新しいバージョンの変更追跡機能を使用すると、V0.11からV2.7のKafkaクライアントを使用して追跡データを消費できます。
使用上の注意
変更追跡機能を使用するときに自動コミットを有効にすると、一部のデータが消費される前にコミットされることがあります。 これにより、データが失われます。 手動でデータをコミットすることを推奨します。
説明データのコミットに失敗した場合は、クライアントを再起動して、最後に記録された消費チェックポイントからデータを消費し続けることができます。 しかしながら、この期間中に重複データが生成されることがある。 重複データを手動で除外する必要があります。
データはシリアル化され、Avro形式で保存されます。 詳細については、「Record.avsc」をご参照ください。
警告このトピックで説明しているKafkaクライアントを使用していない場合は、Avroスキーマに基づいて追跡データを解析する必要があります。
検索単位は、データ送信サービス (DTS) が
offsetForTimes操作を呼び出すときに2番目になります。 ネイティブKafkaクライアントがこの操作を呼び出す場合、検索単位はミリ秒です。障害復旧などのいくつかの理由により、Kafkaクライアントと変更追跡サーバーの間で一時的な接続が発生する場合があります。 このトピックで説明しているKafkaクライアントを使用していない場合は、Kafkaクライアントにネットワーク再接続機能が必要です。
Kafkaクライアントを実行する
Kafka clientデモをダウンロードします。 デモの使用方法の詳細については、「Readme」をご参照ください。
 アイコンをクリックし、[ZIPのダウンロード] を選択してパッケージをダウンロードします。
アイコンをクリックし、[ZIPのダウンロード] を選択してパッケージをダウンロードします。 バージョン2.0のKafkaクライアントを使用する場合は、subscribe_example-master/javaimpl/pom.xmlファイルのバージョン番号を2.0.0に変更する必要があります。
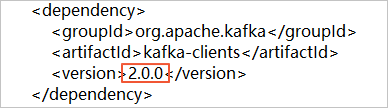
表 1. 次の表に、Kafkaクライアントを実行する手順を示します。
ステップ | ファイルまたはディレクトリ |
1. ネイティブKafkaコンシューマーを使用して、変更追跡インスタンスから増分データを取得します。 | subscribe_example-master/javaimpl/src/main/java/recordgenerator / |
2. 増分データのイメージを逆シリアル化し、 事前イメージ、 ポストイメージ 、およびその他の属性。 警告
| subscribe_example-master/javaimpl/src/main/java/boot/RecordPrinter.java |
3. 逆シリアル化されたデータのdataTypeNumber値を、対応するデータベースのデータ型に変換します。 説明 詳細については、このトピックの次のセクションを参照してください。 | subscribe_example-master/javaimpl/src/main/java/recordprocessor/mysql / |
手順
次の手順は、Kafkaクライアントを実行して追跡データを消費する方法を示しています。 この例では、IntelliJ IDEA Community Edition 2018.1.4 for Windowsが使用されています。
変更追跡タスクを作成します。 詳細については、「ApsaraDB RDS For MySQLインスタンスからのデータ変更の追跡」、「PolarDB for MySQLクラスターからのデータ変更の追跡」、または「自己管理型Oracleデータベースからのデータ変更の追跡」をご参照ください。
1つ以上のコンシューマグループを作成します。 詳細については、「コンシューマーグループの作成」をご参照ください。
Kafkaクライアントデモをダウンロードし、パッケージを解凍します。
説明アイコンをクリックし、[ZIPのダウンロード] を選択してパッケージをダウンロードします。 IntelliJ IDEAを開きます。 表示されるウィンドウで、[開く] をクリックします。

表示されるダイアログボックスで、ダウンロードしたデモが存在するディレクトリに移動します。 pom.xmlファイルを見つけます。
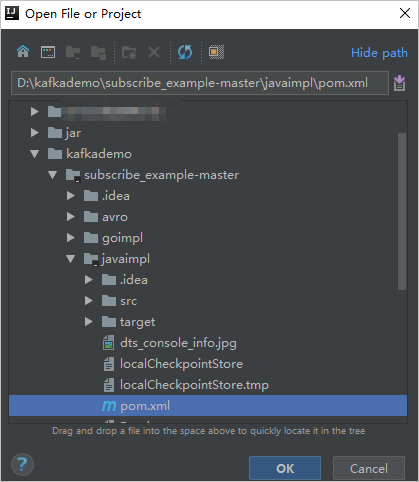
表示されるダイアログボックスで、[プロジェクトとして開く] を選択します。
IntelliJ IDEAのプロジェクトツールウィンドウで、フォルダーをクリックしてKafkaクライアントのデモファイルを検索し、ファイルをダブルクリックします。 ファイル名はNotifyDemoDB.javaです。
NotifyDemoDB.javaファイルのパラメーターを設定します。
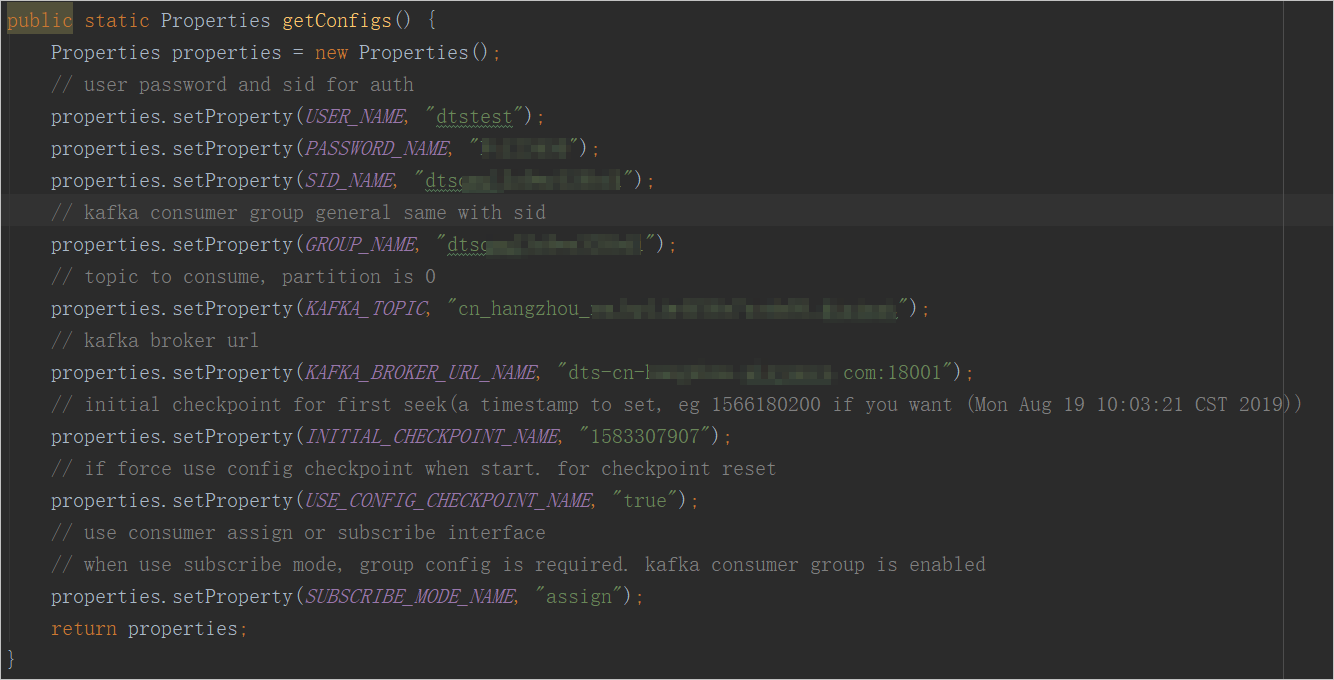
パラメーター
説明
パラメータ値を取得するメソッド
USER_NAME
消費者グループのアカウント。
警告このトピックで説明するKafkaクライアントを使用していない場合は、
<Username>-<Consumer group ID>の形式でアカウントを指定する必要があります。 例:dtstest-dtsae ****** bpvそうしないと、接続は失敗します。DTSコンソールで、管理する変更追跡インスタンスを見つけ、インスタンスIDをクリックします。 左側のナビゲーションウィンドウで、[データの使用] をクリックします。 表示されるページで、コンシューマーグループIDと対応するユーザー名を取得できます。
説明コンシューマーグループアカウントのパスワードは、コンシューマーグループの作成時に自動的に指定されます。

パスワード名
アカウントのパスワードを入力します。
SID_NAME
コンシューマーグループの ID です。
グループ名
消費者グループの名前です。 このパラメーターをコンシューマーグループIDに設定します。
KAFKA_TOPIC
変更追跡インスタンスのトピック。
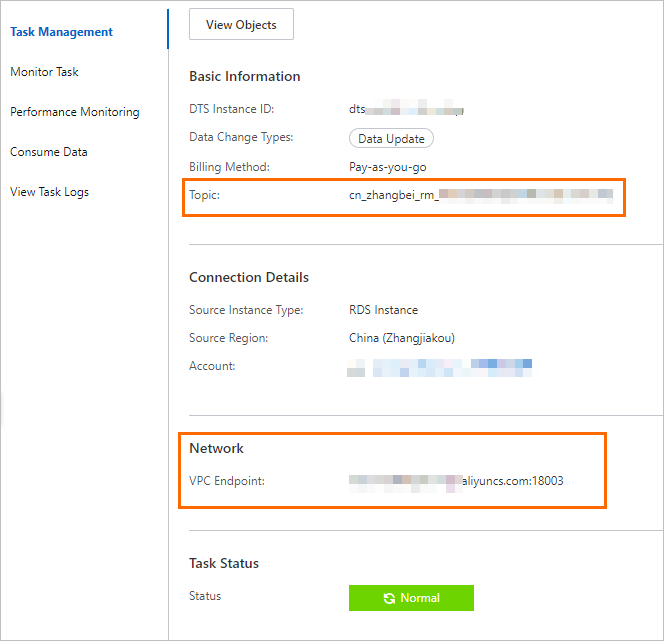
DTSコンソールで、管理する変更追跡インスタンスを見つけ、インスタンスIDをクリックします。 [タスク管理] ページで、トピックとネットワーク情報を取得できます。
KAFKA_BROKER_URL_NAME
変更追跡インスタンスのエンドポイント。
説明内部ネットワーク上のデータ変更を追跡する場合、ネットワーク遅延は最小限に抑えられます。 これは、KafkaクライアントをデプロイするElastic Compute Service (ECS) インスタンスがクラシックネットワーク上にある場合、または変更追跡インスタンスと同じ仮想プライベートクラウド (VPC) にある場合に適用されます。
INITIAL_CHECKPOINT_NAME
消費されたデータの消費チェックポイント。 この値は UNIX タイムスタンプです。 例: 1592269238。
説明次の理由で、消費チェックポイントを保存する必要があります。
消費プロセスが中断された場合、Kafkaクライアントで消費チェックポイントを指定してデータ消費を再開できます。 これにより、データの損失を防ぎます。
Kafkaクライアントを起動すると、オンデマンドでデータを消費するための消費チェックポイントを指定できます。
SUBSCRIBE_MODE_NAMEパラメーターがsubscribeに設定されている場合、指定したINITIAL_CHECKPOINT_NAMEパラメーターは、Kafkaクライアントを初めて起動したときにのみ有効になります。
次の図に示すように、消費されるデータの消費チェックポイントは、変更追跡インスタンスのデータ範囲内にある必要があります。 消費チェックポイントは、UNIXタイムスタンプに変換する必要があります。
 説明
説明検索エンジンを使用して、UNIXタイムスタンプコンバーターを取得できます。
USE_CONFIG_CHECKPOINT_NAME
指定された消費チェックポイントからのデータをクライアントに消費させるかどうかを指定します。 デフォルト値: true。 このパラメーターをtrueに設定すると、受信したが処理されていないデータが失われないようにすることができます。
非該当
SUBSCRIBE_MODE_NAME
コンシューマグループに対して2つ以上のKafkaクライアントを実行するかどうかを指定します。 この機能を使用する場合は、このパラメーターをこれらのKafkaクライアントのサブスクライブに設定します。
デフォルト値はassignで、この機能が使用されていないことを示します。 コンシューマグループに1つのKafkaクライアントのみをデプロイすることを推奨します。
非該当
IntelliJ IDEAの上部メニューバーで、 を選択してクライアントを実行します。
説明IntelliJ IDEAを初めて実行する場合、関連する依存関係をロードしてインストールするには、特定の期間が必要です。
Kafkaクライアントの結果
次の図は、Kafkaクライアントがソースデータベースからのデータ変更を追跡できることを示しています。

NotifyDemoDB.javaファイルの25行目の // log.info(ret); 文字列から2重スラッシュ (//) を削除できます。 次に、クライアントを再度実行して、データ変更情報を表示します。
よくある質問
Q: Kafkaクライアントの消費チェックポイントを記録する必要があるのはなぜですか?
A: DTSによって記録された消費チェックポイントは、DTSがKafkaクライアントからコミット操作を受信した時点です。 記録された消費チェックポイントは、実際の消費時間とは異なり得る。 ビジネスアプリケーションまたはKafkaクライアントが予期せず中断された場合は、正確な消費チェックポイントを指定してデータの消費を継続できます。 これにより、データの損失や重複データの消費を防ぎます。
MySQLデータ型とdataTypeNumber値のマッピング
MySQLデータ型 | dataTypeNumberの値 |
MYSQL_TYPE_DECIMAL | 0 |
MYSQL_TYPE_INT8 | 1 |
MYSQL_TYPE_INT16 | 2 |
MYSQL_TYPE_INT32 | 3 |
MYSQL_TYPE_FLOAT | 4 |
MYSQL_TYPE_DOUBLE | 5 |
MYSQL_TYPE_NULL | 6 |
MYSQL_TYPE_TIMESTAMP | 7 |
MYSQL_TYPE_INT64 | 8 |
MYSQL_TYPE_INT24 | 9 |
MYSQL_TYPE_DATE | 10 |
MYSQL_TYPE_TIME | 11 |
MYSQL_TYPE_DATETIME | 12 |
MYSQL_TYPE_YEAR | 13 |
MYSQL_TYPE_DATE_NEW | 14 |
MYSQL_TYPE_VARCHAR | 15 |
MYSQL_TYPE_BIT | 16 |
MYSQL_TYPE_TIMESTAMP_NEW | 17 |
MYSQL_TYPE_DATETIME_NEW | 18 |
MYSQL_TYPE_TIME_NEW | 19 |
MYSQL_TYPE_JSON | 245 |
MYSQL_TYPE_DECIMAL_NEW | 246 |
MYSQL_TYPE_ENUM | 247 |
MYSQL_TYPE_SET | 248 |
MYSQL_TYPE_TINY_BLOB | 249 |
MYSQL_TYPE_MEDIUM_BLOB | 250 |
MYSQL_TYPE_LONG_BLOB | 251 |
MYSQL_TYPE_BLOB | 252 |
MYSQL_TYPE_VAR_STRING | 253 |
MYSQL_TYPE_STRING | 254 |
MYSQL_TYPE_GEOMETRY | 255 |
Oracleデータ型とdataTypeNumber値のマッピング
Oracleデータ型 | dataTypeNumberの値 |
VARCHAR2およびNVARCHAR2 | 1 |
番号とフロート | 2 |
LONG | 8 |
日付 | 12 |
RAW | 23 |
LONG_RAW | 24 |
未定 | 29 |
XMLTYPE | 58 |
ROWID | 69 |
CHARとNCHAR | 96 |
BINARY_FLOAT | 100 |
BINARY_DOUBLE | 101 |
CLOBおよびNCLOB | 112 |
BLOB | 113 |
BFILE | 114 |
TIMESTAMP | 180 |
TIMESTAMP_WITH_TIME_ZONE | 181 |
INTERVAL_YEAR_TO_MONTH | 182 |
INTERVAL_DAY_TO_SECOND | 183 |
ウービッド | 208 |
TIMESTAMP_WITH_LOCAL_TIME_ZONE | 231 |
PostgreSQLデータ型とdataTypeNumber値のマッピング
PostgreSQLデータ型 | dataTypeNumberの値 |
INT2とSMALLINT | 21 |
INT4、INTEGER、およびシリアル | 23 |
INT8およびBIGINT | 20 |
CHARACTER | 18 |
CHARACTER VARYING | 1043 |
REAL | 700 |
DOUBLE PRECISION | 701 |
NUMERIC | 1700 |
お金 | 790 |
日付 | 1082 |
タイムゾーンなしの時間と時間 | 1083 |
タイムゾーンでの時間 | 1266 |
タイムゾーンなしのタイムスタンプとタイムスタンプ | 1114 |
TIMESTAMP WITH TIME ZONE | 1184 |
BYTEA | 17 |
TEXT | 25 |
JSON | 114 |
JSONB | 3082 |
XML | 142 |
UUID | 2950 |
ポイント | 600 |
LSEG | 601 |
PATH | 602 |
ボックス | 603 |
ポリゴン | 604 |
ライン | 628 |
CIDR | 650 |
サークル | 718 |
MACADDR | 829 |
INET | 869 |
INTERVAL | 1186 |
TXID_SNAPSHOT | 2970 |
PG_LSN | 3220 |
TSVECTOR | 3614 |
TSQUERY | 3615 |