Data Transmission Service (DTS) は、Redisデータベース間の一方向同期をサポートします。 この機能は、アクティブな地理的冗長性や地理的災害復旧などのシナリオに適用できます。 このトピックでは、Express Connect、VPN Gateway、またはSmart Access Gatewayを介して接続された自己管理Redisデータベースから、Elastic Compute Service (ECS) インスタンスでホストされている自己管理Redisデータベースにデータを同期する方法について説明します。
データ同期タスクを設定した後、ソースインスタンスまたはターゲットインスタンスのアーキテクチャタイプを変更しないでください。 たとえば、マスターレプリカアーキテクチャをクラスターアーキテクチャに変更すると、データの同期が失敗します。 ApsaraDB For Redisでサポートされているアーキテクチャタイプの詳細については、 概要をご参照ください。
前提条件
ソースRedisデータベースのバージョンは、2.8、3.0、3.2、4.0、または5.0です。
説明ターゲットRedisデータベースのバージョンは、2.8、3.0、3.2、4.0、または5.0です。 移行先データベースのバージョンは、移行元データベースのバージョンと同じかそれ以降である必要があります。 異なるバージョンのRedisデータベース間でデータを同期する場合は、ソースデータベースとターゲットデータベースのバージョンが互換性があることを確認してください。
ターゲットRedisデータベースの使用可能なストレージ容量は、ソースRedisデータベースのデータの合計サイズよりも大きくなっています。
ソースRedisデータベースがクラスターアーキテクチャにデプロイされているシナリオでは、Redisクラスターのすべてのノードが
PSYNCコマンドをサポートし、同じパスワードを共有します。ソースインスタンスのマスターノードとレプリカノード間のデータレプリケーションのタイムアウト期間は、repl-timeoutパラメーターで指定します。 デフォルトでは、このパラメータは60秒に設定されています。
config set repl-timeout 600コマンドを実行して、このパラメーターを600秒に設定することを推奨します。 ソースインスタンスに大量のデータが保存されている場合は、ビジネス要件に基づいてrepl-timeoutパラメーターの値を増やすことができます。データ同期に使用されるアカウントは、ターゲットデータベースに作成され、パスワードで構成されます。
使用上の注意
DTSは、最初の完全データ同期中にソースインスタンスとターゲットインスタンスのリソースを使用します。 これにより、データベースサーバーの負荷が増加する可能性があります。 大量のデータを同期したり、サーバーの仕様が要件を満たしていない場合、データベースサービスが利用できなくなることがあります。 データを同期する前に、ソースインスタンスとターゲットインスタンスのパフォーマンスに対するデータ同期の影響を評価します。 オフピーク時にデータを同期することを推奨します。
ソースデータベースの特定のキーに対して有効期限ポリシーが有効化されている場合、これらのキーは、有効期限が切れた後の最も早い機会に削除されない場合があります。 したがって、宛先データベース内のキーの数は、ソースデータベース内のキーの数よりも少なくてもよい。 INFOコマンドを実行して、ターゲットデータベース内のキーの数を表示できます。
説明有効期限ポリシーが有効になっていない、または有効期限が切れていないキーの数は、ソースデータベースとターゲットデータベースで同じです。
ソースredisデータベースのRedis. confファイルで
bindパラメーターが設定されている場合、このパラメーターの値をECSインスタンスの内部IPアドレスに設定する必要があります。 この設定により、DTSがソースデータベースに接続できるようになります。データ同期の安定性を確保するために、ソースredisデータベースの
Redis. confファイルのrepl-backlog-sizeパラメーターの値を大きくすることを推奨します。同期品質を確保するために、DTSはソースRedisデータベースに
DTS_REDIS_TIMESTAMP_HEARTBEATキーを追加します。 このキーは、データがApsaraDB for Redisに同期される時刻を記録するために使用されます。Redisクラスター間のデータ同期中は、ソースデータベースで
FLUSHDBまたはFLUSHALLコマンドを実行しないことを推奨します。 Redisクラスター間のデータ同期中にソースデータベースでいずれかのコマンドを実行すると、ソースRedisデータベースとターゲットApsaraDB for Redisインスタンスの間でデータの不整合が発生する可能性があります。デフォルトでは、データの削除方法を指定するmaxmemory-policyパラメーターは、ApsaraDB for Redisインスタンスのvolatile-lruに設定されています。 デスティネーションインスタンスのメモリが不十分な場合、データの削除により、ソースインスタンスとデスティネーションインスタンスの間でデータの不整合が発生する可能性があります。 この場合、データ同期タスクは実行を停止しません。
データの不整合を防ぐため、ターゲットインスタンスのmaxmemory-policyをnoevictionに設定することを推奨します。 このように、宛先インスタンスのメモリが不十分な場合、データ同期タスクは失敗しますが、宛先インスタンスのデータ損失を防ぐことができます。
説明データ削除ポリシーの詳細については、「ApsaraDB for Redisのデフォルトの削除ポリシーは何ですか?」をご参照ください。
データ同期中に、自己管理Redisデータベースのシャードの数が増減した場合、またはメモリ容量のスケールアップなどのデータベース仕様を変更した場合、データ同期タスクを再構成する必要があります。 データの一貫性を確保するために、データ同期タスクを再構成する前に、ターゲットインスタンスに同期されたデータをクリアすることを推奨します。
データ同期中に、自己管理Redisデータベースのエンドポイントが変更された場合、データ同期タスクを再構成する必要があります。
スタンドアロンApsaraDB for RedisインスタンスからApsaraDB for Redisクラスターインスタンスへのデータ同期の制限: 各コマンドは、ApsaraDB for Redisクラスターインスタンスの単一のスロットでのみ実行できます。 ソースデータベース内の複数のキーに対して操作を実行し、キーが異なるスロットに属している場合、次のエラーが発生します。
CROSSSLOT Keys in request don't hash to the same slotデータ同期中は、1つのキーに対してのみ操作を実行することを推奨します。 それ以外の場合、データ同期タスクは中断されます。
ターゲットインスタンスがクラスターアーキテクチャにデプロイされ、ターゲットインスタンスのシャードが使用するメモリ量が上限に達した場合、またはターゲットインスタンスの使用可能なストレージスペースが不十分な場合、メモリ不足 (OOM) によりデータ同期タスクが失敗します。
同期品質を確保するために、Data Transmission Service (DTS) は、ソースデータベースにDTS_REDIS_TIMESTAMP_HEARTBEATというプレフィックスが付いたキーを追加します。 このキーは、データが宛先データベースに同期される時刻を記録するために使用されます。 ソースデータベースがクラスターアーキテクチャにデプロイされている場合、DTSはこのキーを各シャードに追加します。 キーはデータ同期中に除外されます。 データ同期タスクが完了すると、キーは期限切れになります。
ソースデータベースが読み取り専用データベースである場合、またはデータ同期タスクの実行に使用されるソースデータベースアカウントにSETEXコマンドを実行する権限がない場合、報告されるレイテンシが不正確になる可能性があります。
ターゲットインスタンスに対して透過データ暗号化 (TDE) 機能が有効になっている場合、DTSを使用してデータを同期することはできません。
課金
同期タイプ | タスク設定料金 |
スキーマ同期と完全データ同期 | 無料です。 |
増分データ同期 | 有料。 詳細については、「課金の概要」をご参照ください。 |
サポートしている同期トポロジ
一方向の 1 対 1 の同期
一方向の 1 対多の同期
一方向のカスケード同期
詳細については、「同期トポロジ」をご参照ください。
同期できるコマンド
APPEND
BITOP、BLPOP、BRPOP、およびBRPOPLPUSH
DECR、DECRFY、およびDEL
EVAL、EVALSHA、EXEC、EXPIRE、EXPIREAT
GEOADDとGETSET
HDEL、HINCRBY、HINCRBYFLOAT、HMSET、HSET、およびHSETNX
INCR、INCRBY、およびINCRBYFLOAT
LINSERT、LPOP、LPUSH、LUSHX、LREM、LSET、およびLTRIM
移動、MSET、MSETNX、およびマルチ
PERSIST、PEXPIRE、PEXPIREAT、PFADD、PFMERGE、およびPSETEX
RENAME、RENAMENX、RESTORE、RPOP、RPOPLPUSH、RPUSH、およびRPUSHX
SADD、SDIFFSTORE、SELECT、SET、SETBIT、SETEX、SETNX、SETRANGE、SINTERSTORE、SMOVE、SPOP、SREM、およびSUUNIONSTORE
ZADD、ZINCRBY、ZINTERSTORE、ZREM、ZREMRANGEBYLEX、ZUNION STORE、ZREMRANGEBYRANK、およびZREMRANGEBYSCORE
SWAPDBとUNLINK。 これらの2つのコマンドは、ソースデータベースのエンジンバージョンがRedis 4.0の場合にのみ同期できます。
PUBLISHコマンドは同期できません。
EVALまたはEVALSHAコマンドを実行してLuaスクリプトを呼び出した場合、DTSはこれらのLuaスクリプトがターゲットデータベースで実行されているかどうかを識別できません。 これは、増分データ同期中に、ターゲットデータベースがLuaスクリプトの実行結果を明示的に返さないためです。
DTSがSYNCまたはPSYNCコマンドを実行してLISTタイプのデータを転送すると、DTSはターゲットデータベースの既存のデータをクリアしません。 結果として、宛先データベースは、重複するデータレコードを含み得る。
手順
データ同期インスタンスを購入します。 詳細については、「データ同期インスタンスの購入」をご参照ください。
説明購入ページで、ソースインスタンスとターゲットインスタンスの両方のパラメーターをRedisに設定します。
最初に DTSコンソールにログインします。
説明DTSコンソールからDMSコンソールに移動している場合は、右下隅にある
 アイコンの上にポインターを移動し、
アイコンの上にポインターを移動し、 アイコンをクリックしてDTSコンソールに戻ることができます。
アイコンをクリックしてDTSコンソールに戻ることができます。 ログイン後に新しいバージョンのDTSコンソールが表示される場合は、右下隅にある
 アイコンをクリックして、以前のバージョンに戻ることができます。
アイコンをクリックして、以前のバージョンに戻ることができます。
左側のナビゲーションウィンドウで、[データ同期] を選択します。
[データ同期タスク] ページの上部で、ターゲットインスタンスが存在するリージョンを選択します。
データ同期インスタンスを見つけ、[操作] 列の [タスクの設定] をクリックします。
ソースとターゲットのRedisデータベースを設定します。
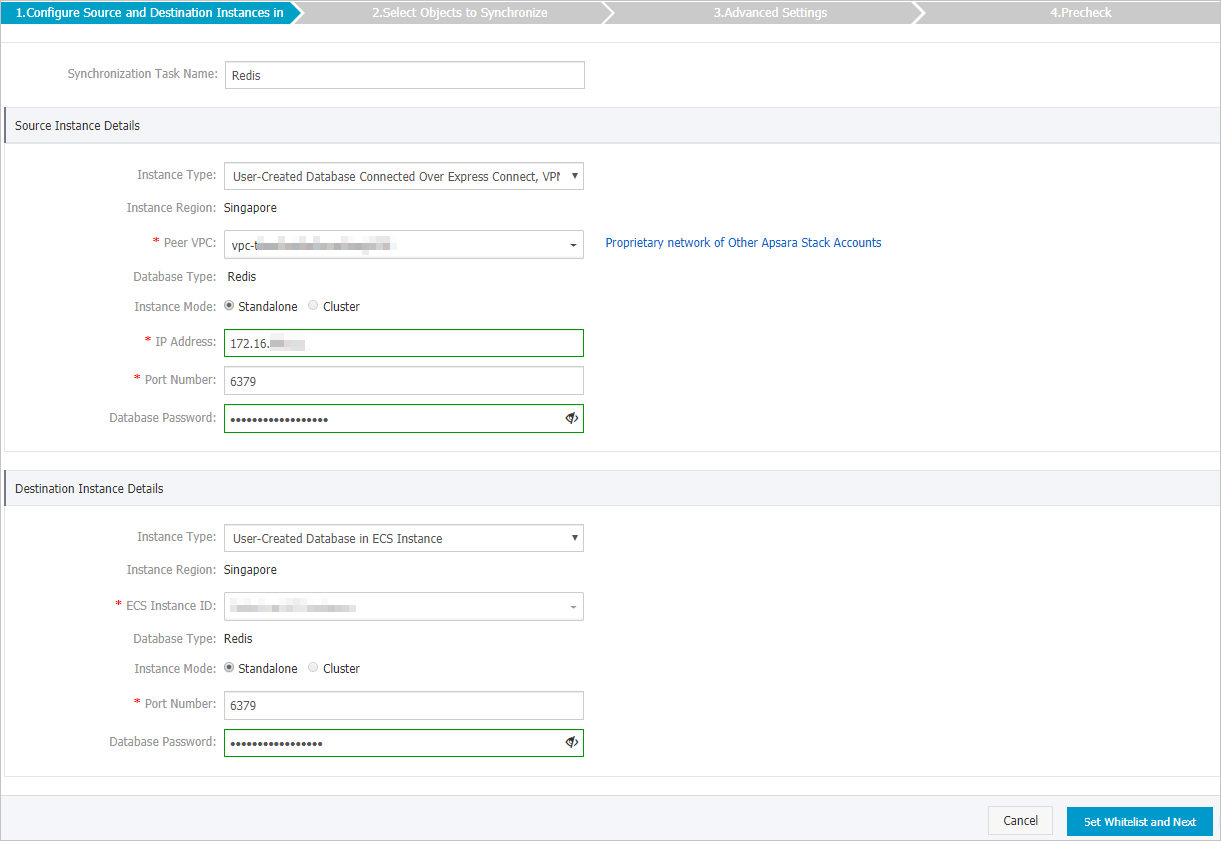
セクション
パラメーター
説明
非該当
同期タスク名
DTSが自動的に生成するタスク名。 タスクを簡単に識別できるように、わかりやすい名前を指定することをお勧めします。 一意のタスク名を使用する必要はありません。
ソースインスタンスの詳細
インスタンスタイプ
ソースデータベースのアクセス方法。 Express Connect、または VPN Gateway、または Smart Access Gateway 経由で接続されたユーザー作成のデータベース を選択します。
インスタンスリージョン
購入ページで選択したソースリージョン。 このパラメーターの値は変更できません。
ピア VPC
自己管理Redisデータベースに接続されている仮想プライベートクラウド (VPC) のID。
データベースエンジン
このパラメーターの値はRedisに設定されています。
インスタンスモード
ソースRedisデータベースのアーキテクチャ。 [スタンドアロン] または [クラスター] を選択します。
IP アドレス
ソースRedisデータベースのサーバーIPアドレス。
説明ソースRedisデータベースがクラスターアーキテクチャにデプロイされている場合は、マスターノードが属するサーバーのIPアドレスを入力します。
ポート番号
ソースRedisデータベースのサービスポート番号。 デフォルト値: 6379
説明ソースRedisデータベースがクラスターアーキテクチャにデプロイされている場合は、マスターノードのサービスポート番号を入力します。
データベースパスワード
ソースRedisデータベースのパスワード。
説明このパラメーターはオプションで、データベースパスワードが設定されていない場合は空のままにできます。
ターゲットインスタンスの詳細
インスタンスタイプ
ターゲットデータベースのアクセス方法。 [ECS インスタンスのユーザー作成データベース] を選択します。
インスタンスリージョン
購入ページで選択したターゲットリージョン。 このパラメーターの値は変更できません。
ECS インスタンス ID
ターゲットRedisデータベースをホストするECSインスタンスのID。
説明ターゲットRedisデータベースがクラスターアーキテクチャにデプロイされている場合は、マスターノードが存在するECSインスタンスのIDを選択します。
インスタンスモード
ターゲットRedisデータベースのアーキテクチャ。 [スタンドアロン] または [クラスター] を選択します。
ポート番号
宛先Redisデータベースのサービスポート番号。 デフォルト値: 6379
説明ターゲットRedisデータベースがクラスターアーキテクチャにデプロイされている場合は、マスターノードのサービスポート番号を入力します。
データベースパスワード
ターゲットRedisデータベースのパスワード。
説明This parameter is required. このパラメーターを空のままにすると、事前チェック中にエラーが報告されます。
ページの右下隅にある [ホワイトリストの設定] および [次へ] をクリックします。
説明ApsaraDB RDS for MySQLやApsaraDB for MongoDBなどのAlibaba Cloudデータベースインスタンス、またはECSインスタンスでホストされている自己管理型データベースのセキュリティ設定を変更する必要はありません。 DTSは、DTSサーバーのCIDRブロックをAlibaba CloudデータベースインスタンスのホワイトリストまたはECSインスタンスのセキュリティグループルールに自動的に追加します。 詳細については、「DTSサーバーのCIDRブロックをオンプレミスデータベースのセキュリティ設定に追加する」をご参照ください。
データ同期が完了したら、DTSサーバーのCIDRブロックをホワイトリストまたはセキュリティグループルールから削除することを推奨します。
競合するテーブルの処理モードと、同期するオブジェクトを選択します。
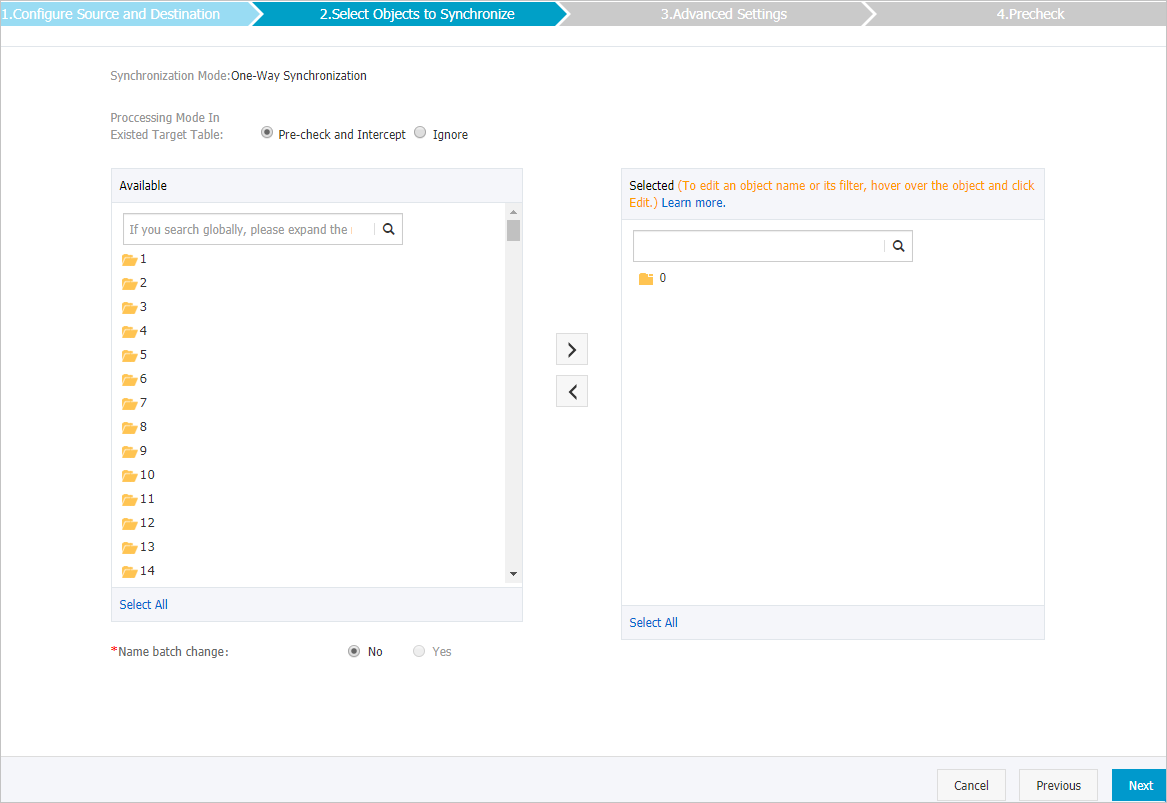
設定
説明
競合するテーブルの処理モードを選択する
事前チェックとインターセプト: ターゲットインスタンスが空かどうかを確認します。 ターゲットインスタンスが空の場合、事前チェックに合格します。 ターゲットインスタンスが空でない場合、事前チェック中にエラーが返され、データ同期タスクを開始できません。
無視: 空のターゲットインスタンスのチェックをスキップします。
警告[無視] を選択した場合、ソースインスタンスのデータレコードは、ターゲットインスタンスの同じキーを持つデータレコードを上書きします。 作業は慎重に行ってください。
同期するオブジェクトの選択
[使用可能] セクションから1つ以上のデータベースを選択し、
 アイコンをクリックして、データベースを [選択済み] セクションに追加します。
アイコンをクリックして、データベースを [選択済み] セクションに追加します。 同期するオブジェクトとしてデータベースのみを選択できます。 同期するオブジェクトとしてキーを選択することはできません。
データベースとテーブルの名前変更
同期するオブジェクト。 このシナリオでは、オブジェクトの名前を変更することはできません。
DMSがDDL操作を実行するときの一時テーブルのレプリケート
DMSを使用してソースデータベースでオンラインDDL操作を実行する場合、オンラインDDL操作によって生成された一時テーブルを同期するかどうかを指定できます。
Yes: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期します。
説明オンラインDDL操作が大量のデータを生成する場合、データ同期タスクが遅延する可能性があります。
No: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期しません。 ソースデータベースの元のDDLデータのみが同期されます。
説明[いいえ] を選択すると、ターゲットデータベースのテーブルがロックされる可能性があります。
失敗した接続の再試行時間
既定では、DTSがソースデータベースまたはターゲットデータベースへの接続に失敗した場合、DTSは次の720分 (12時間) 以内に再試行します。 必要に応じて再試行時間を指定できます。 DTSが指定された時間内にソースデータベースとターゲットデータベースに再接続すると、DTSはデータ同期タスクを再開します。 それ以外の場合、データ同期タスクは失敗します。
説明DTSが接続を再試行すると、DTSインスタンスに対して課金されます。 ビジネスニーズに基づいて再試行時間を指定することを推奨します。 ソースインスタンスとターゲットインスタンスがリリースされた後、できるだけ早くDTSインスタンスをリリースすることもできます。
ページの右下に表示される [次へ] をクリックします。
初期同期タイプを選択します。 値はInclude full data + incremental dataに設定されており、変更できません。
 説明
説明DTSは、履歴データをソースインスタンスからターゲットインスタンスに同期します。 次に、DTSは増分データを同期します。
バージョン関連のエラーメッセージが表示された場合は、ソースインスタンスを指定したバージョンにアップグレードできます。 バージョンをアップグレードする方法の詳細については、「メジャーバージョンのアップグレード」および「インスタンスのマイナーバージョンの更新」をご参照ください。
ページの右下に表示される [事前確認] をクリックします。
説明データ同期タスクを開始する前に、DTSは事前チェックを実行します。 データ同期タスクは、タスクが事前チェックに合格した後にのみ開始できます。
タスクが事前チェックに合格しなかった場合は、失敗した各項目の横にある
 アイコンをクリックして詳細を表示できます。
アイコンをクリックして詳細を表示できます。 原因に基づいて問題をトラブルシューティングし、事前チェックを再度実行できます。
問題をトラブルシューティングする必要がない場合は、失敗した項目を無視して、再度事前チェックを実行できます。
[事前チェックに合格] の後に、[事前チェック] ダイアログボックスを閉じます。 [事前チェック] ダイアログボックスにメッセージが表示されます。 その後、データ同期タスクが開始されます。
初期同期が完了し、データ同期タスクが同期状態になるまで待ちます。
 説明
説明データ同期タスクの状態は、[同期タスク] ページで確認できます。