MySQL データソースは、MySQL へのデータの読み書きを行うための双方向チャネルを提供します。このトピックでは、DataWorks の MySQL データ同期機能について説明します。
サポートされている MySQL のバージョン
オフライン読み取り/書き込み:
MySQL 5.5.x、MySQL 5.6.x、MySQL 5.7.x、および MySQL 8.0.x をサポートしており、Amazon RDS for MySQL、Azure MySQL、および Amazon Aurora MySQL と互換性があります。
オフライン同期は、ビューからのデータ読み取りをサポートします。
リアルタイム読み取り:
Data Integration は、MySQL バイナリログをサブスクライブすることで、MySQL データをリアルタイムで読み取ります。リアルタイム同期は、MySQL 5.5.x、5.6.x、5.7.x、および 8.0.x に対応しています。バージョン 8.0.x では、関数インデックスなどの新機能を除き、すべての機能がサポートされています。また、Amazon RDS for MySQL、Azure MySQL、および Amazon Aurora MySQL と互換性があります。
重要DRDS for MySQL データベースからデータを同期するには、MySQL データソースとして設定しないでください。詳細については、「DRDS データソースの設定」をご参照ください。
制限事項
リアルタイム読み取り
バージョン 5.6.x より前の MySQL 読み取り専用インスタンスからのデータ同期はサポートされていません。
関数インデックスを含むテーブルの同期はサポートされていません。
XA ROLLBACK はサポートされていません。
XA PREPARE 状態のトランザクション内のデータについては、リアルタイム同期はデータを宛先に書き込みます。XA ROLLBACK が発生した場合、リアルタイム同期はこのデータをロールバックしません。このシナリオに対処するには、リアルタイム同期タスクからテーブルを手動で削除し、再度追加して同期を再開する必要があります。
MySQL サーバーのバイナリロギングは、ROW フォーマットのみがサポートされています。
リアルタイム同期では、カスケード削除によって関連テーブルから削除されたレコードは同期されません。
Amazon Aurora MySQL データベースの場合、プライマリまたはライターデータベースインスタンスに接続する必要があります。これは、AWS が Aurora MySQL の読み取り専用レプリカでバイナリロギング機能を有効にすることを許可していないためです。リアルタイム同期タスクでは、増分更新を実行するためにバイナリログが必要です。
オンライン DDL 操作のリアルタイム同期は、Data Management DMS を使用した MySQL テーブルへの列の追加 (Add Column) のみをサポートします。
MySQL からのストアドプロシージャの読み取りはサポートされていません。
オフライン読み取り
MySQL Reader プラグインがシャーディングされたデータベース内の複数のテーブルからデータを同期する場合、デフォルトではシャーディングされたタスクの数はテーブルの数と等しくなります。単一のテーブルでシャーディングを有効にするには、同時実行タスクの数をテーブルの数より大きい値に設定する必要があります。
MySQL からのストアドプロシージャの読み取りはサポートされていません。
サポートされているデータ型
各 MySQL バージョンのデータ型の完全なリストについては、MySQL 公式ドキュメントをご参照ください。次の表は、例として MySQL 8.0.x でサポートされている主要なデータ型をリストしています。
データ型 | オフライン読み取り (MySQL Reader) | オフライン書き込み (MySQL Writer) | リアルタイム読み取り | リアルタイム書き込み |
TINYINT | ||||
SMALLINT | ||||
INTEGER | ||||
BIGINT | ||||
FLOAT | ||||
DOUBLE | ||||
DECIMAL/NUMERIC | ||||
REAL | ||||
VARCHAR | ||||
JSON | ||||
TEXT | ||||
MEDIUMTEXT | ||||
LONGTEXT | ||||
VARBINARY | ||||
BINARY | ||||
TINYBLOB | ||||
MEDIUMBLOB | ||||
LONGBLOB | ||||
ENUM | ||||
SET | ||||
BOOLEAN | ||||
BIT | ||||
DATE | ||||
DATETIME | ||||
TIMESTAMP | ||||
TIME | ||||
YEAR | ||||
LINESTRING | ||||
POLYGON | ||||
MULTIPOINT | ||||
MULTILINESTRING | ||||
MULTIPOLYGON | ||||
GEOMETRYCOLLECTION |
事前準備
DataWorks で MySQL データソースを設定する前に、後続のタスクが期待どおりに実行されるように、このセクションで説明する事前準備を完了してください。
以下のセクションでは、MySQL データを同期するために必要な準備について説明します。
MySQL バージョンの確認
Data Integration には、MySQL に対する特定のバージョン要件があります。詳細については、「サポートされている MySQL のバージョン」セクションをご参照ください。MySQL データベースで次のステートメントを実行して、現在のバージョンを確認できます。
SELECT version();アカウント権限の設定
DataWorks がデータソースにアクセスするための専用の MySQL アカウントを作成します。手順は次のとおりです。
オプション: アカウントを作成します。
詳細については、「MySQL アカウントの作成」をご参照ください。
権限を設定します。
オフライン
オフライン同期
MySQL からデータを読み取るには、アカウントにターゲットテーブルに対する
SELECT権限が必要です。MySQL にデータを書き込むには、アカウントにターゲットテーブルに対する
INSERT、DELETE、およびUPDATE権限が必要です。
リアルタイム同期
リアルタイム同期の場合、アカウントにはデータベースに対する
SELECT、REPLICATION SLAVE、およびREPLICATION CLIENT権限が必要です。
次のコマンドを実行してアカウントに権限を付与するか、
SUPER権限を直接付与できます。次のステートメントで、'sync_account'を作成したアカウントに置き換えてください。-- CREATE USER 'sync_account'@'%' IDENTIFIED BY 'password'; //同期アカウントを作成し、パスワードを設定し、任意のホストからデータベースにログインできるようにします。パーセント記号 (%) は任意のホストを示します。 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sync_account'@'%'; // データベースに対する SELECT、REPLICATION SLAVE、および REPLICATION CLIENT 権限を同期アカウントに付与します。*.*は、すべてのデータベース内のすべてのテーブルに対する指定の権限をアカウントに付与します。 ターゲットデータベース内の特定のテーブルに対して権限を付与することもできます。 たとえば、test データベース内の user テーブルに SELECT および REPLICATION CLIENT 権限を付与するには、次の文を実行します:GRANT SELECT, REPLICATION CLIENT ON test.user TO 'sync_account'@'%';。説明REPLICATION SLAVEはグローバル権限です。この権限をターゲットデータベースの特定のテーブルに付与することはできません。
MySQL バイナリロギングの有効化 (リアルタイム同期のみ)
Data Integration は、MySQL バイナリログをサブスクライブすることで、増分データのリアルタイム同期を実行します。DataWorks で同期タスクを設定する前に、MySQL バイナリロギングサービスを有効にする必要があります。手順は次のとおりです:
バイナリログが消費されている場合、データベースはそれを削除できません。リアルタイム同期タスクで高いレイテンシーが発生すると、ソースデータベースのバイナリログが長期間保持される可能性があります。タスクにレイテンシーアラートを設定し、データベースのディスク領域を監視してください。
バイナリログは少なくとも 72 時間保持する必要があります。これにより、タスクが失敗し、バイナリログが削除されたために以前のオフセットにリセットできない場合のデータ損失を防ぎます。この場合、データをバックフィルするために完全なオフライン同期を実行する必要があります。
バイナリロギングが有効になっているか確認します。
次のステートメントを実行して、バイナリロギングが有効になっているか確認します。
SHOW variables LIKE "log_bin";コマンドが ON を返した場合、バイナリロギングは有効です。
セカンダリデータベースからデータを同期する場合、次のステートメントを実行してバイナリロギングが有効になっているか確認することもできます。
SHOW variables LIKE "log_slave_updates";コマンドが ON を返した場合、セカンダリデータベースでバイナリロギングが有効になっています。
結果が一致しない場合:
オープンソースの MySQL の場合、MySQL 公式ドキュメント を参照してバイナリロギングを有効にしてください。
ApsaraDB RDS for MySQL の場合、「RDS for MySQL のログバックアップ」を参照してバイナリロギングを有効にしてください。
PolarDB for MySQL の場合、「バイナリロギングの有効化」を参照してバイナリロギングを有効にしてください。
バイナリログのフォーマットを確認します。
次のステートメントを実行して、バイナリログのフォーマットを確認します。
SHOW variables LIKE "binlog_format";考えられる戻り値は次のとおりです:
ROW:バイナリログのフォーマットは ROW です。
STATEMENT:バイナリログのフォーマットは STATEMENT です。
MIXED:バイナリログのフォーマットは MIXED です。
重要DataWorks のリアルタイム同期は、MySQL サーバーのバイナリロギングの ROW フォーマットのみをサポートします。コマンドが ROW 以外の値を返す場合は、バイナリログのフォーマットを変更する必要があります。
完全な行イメージロギングが有効になっているか確認します。
次のステートメントを実行して、完全な行イメージロギングが有効になっているか確認します。
SHOW variables LIKE "binlog_row_image";考えられる戻り値は次のとおりです:
FULL:バイナリログに対して完全な行イメージロギングが有効になっています。
MINIMAL:バイナリログに対して最小限の行イメージロギングが有効になっています。完全な行イメージロギングは有効になっていません。
重要DataWorks のリアルタイム同期は、完全な行イメージロギングが有効になっている MySQL サーバーのみをサポートします。コマンドが FULL 以外の値を返す場合は、binlog_row_image の設定を変更する必要があります。
OSS からのバイナリログ読み取りの権限設定
MySQL データソースを追加する際に、設定モード を Alibaba Cloud インスタンスモード に設定し、RDS for MySQL インスタンスが DataWorks ワークスペースと同じリージョンにある場合、OSS からのバイナリログ読み取りを有効化 を有効にできます。この機能を有効にすると、DataWorks が RDS バイナリログにアクセスできない場合に、OSS からバイナリログを取得しようとします。これにより、リアルタイム同期タスクが中断されるのを防ぎます。
OSS からバイナリログにアクセスするための ID を Alibaba Cloud RAM ユーザー または Alibaba Cloud RAM ロール に設定した場合は、以下で説明するようにアカウント権限も設定する必要があります。
Alibaba Cloud RAM ユーザー
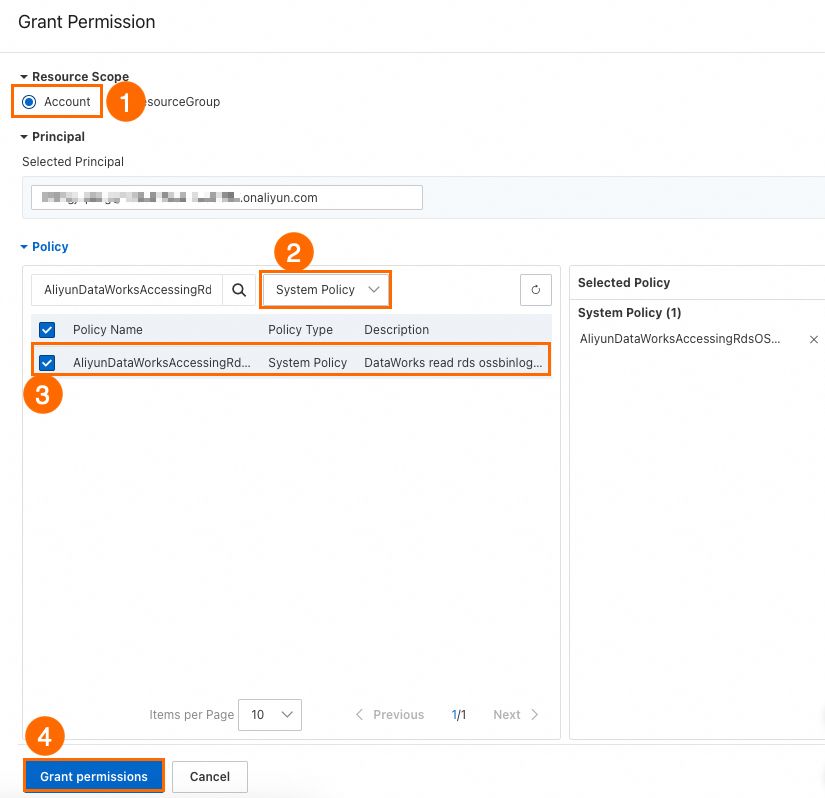
RAM コンソールにログインし、権限を付与したい RAM ユーザーを見つけます。
操作 列で、権限の追加 をクリックします。
以下の主要なパラメーターを設定し、権限の付与 をクリックします。
リソース範囲 をアカウントレベルに設定します。
ポリシー をシステムポリシーに設定します。
ポリシー名 を
AliyunDataWorksAccessingRdsOSSBinlogPolicyに設定します。
Alibaba Cloud RAM ロール
RAM コンソールにログインし、RAM ロールを作成します。詳細については、「信頼できる Alibaba Cloud アカウントの RAM ロールを作成する」をご参照ください。
主要なパラメーター:
プリンシパルタイプ を Alibaba Cloud アカウントに設定します。
プリンシパル名 を他の Alibaba Cloud アカウントに設定し、DataWorks ワークスペースを所有する Alibaba Cloud アカウントの ID を入力します。
ロール名 をカスタム名に設定します。
作成した RAM ロールに権限を付与します。詳細については、「RAM ロールに権限を付与する」をご参照ください。
主要なパラメーター:
ポリシー をシステムポリシーに設定します。
ポリシー名 を
AliyunDataWorksAccessingRdsOSSBinlogPolicyに設定します。
作成した RAM ロールの信頼ポリシーを修正します。詳細については、「RAM ロールの信頼ポリシーを修正する」をご参照ください。
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "<DataWorks ユーザーの Alibaba_Cloud_アカウント_ID>@di.dataworks.aliyuncs.com", "<DataWorks ユーザーの Alibaba_Cloud_アカウント_ID>@dataworks.aliyuncs.com" ] } } ], "Version": "1" }
データソースの追加
Alibaba Cloud インスタンスモード
MySQL データベースが Alibaba Cloud RDS インスタンスである場合、Alibaba Cloud インスタンスモードでデータソースを作成できます。次の表にパラメーターを説明します:
パラメーター | 説明 |
データソース名 | データソースの名前。名前はワークスペース内で一意である必要があります。ビジネスと環境を識別する名前 (例: |
設定モード | Alibaba Cloud インスタンスモードを選択します。詳細については、「シナリオ 1:インスタンスモード (現在の Alibaba Cloud アカウント)」および「シナリオ 2:インスタンスモード (他の Alibaba Cloud アカウント)」をご参照ください。 |
Alibaba Cloud アカウント | インスタンスが属するアカウントを選択します。他の Alibaba Cloud アカウント を選択した場合は、クロスアカウント権限を設定する必要があります。詳細については、「クロスアカウント権限付与 (RDS、Hive、または Kafka)」をご参照ください。 他の Alibaba Cloud アカウントを選択した場合は、次の情報を指定する必要があります:
|
リージョン | インスタンスが配置されているリージョン。 |
インスタンス | 接続したいインスタンスの名前。 |
セカンダリインスタンスの設定 | データソースに読み取り専用インスタンス (読み取り専用レプリカ) がある場合、タスクを設定する際に読み取り操作に読み取り専用レプリカを選択できます。これにより、プライマリデータベースへの干渉を防ぎ、そのパフォーマンスに影響を与えません。 |
インスタンスアドレス | 正しいインスタンスを選択した後、[最新のエンドポイントを取得] をクリックして、インスタンスのパブリックまたはプライベートエンドポイント、VPC、および vSwitch を表示します。 |
データベース | データソースがアクセスする必要のあるデータベースの名前。指定されたユーザーがデータベースにアクセスする権限を持っていることを確認してください。 |
ユーザー名/パスワード | MySQL データベースアカウントのユーザー名とパスワード。RDS インスタンスを使用する場合、インスタンスの アカウント管理 セクションでアカウントを作成および管理できます。 |
OSS からのバイナリログ読み取りを有効化 | この機能を有効にすると、DataWorks が RDS バイナリログにアクセスできない場合に、OSS からバイナリログを取得しようとします。これにより、リアルタイム同期タスクが中断されるのを防ぎます。設定の詳細については、「OSS からのバイナリログ読み取りの権限設定」をご参照ください。その後、権限設定に基づいて OSS バイナリログアクセス ID を設定します。 |
認証方法 | 認証なしまたは SSL 認証を選択できます。SSL 認証を選択する場合、インスタンス自体で SSL 認証が有効になっている必要があります。証明書ファイルを準備し、証明書ファイル管理 にアップロードします。 |
バージョン | MySQL サーバーにログインし、`SELECT VERSION()` コマンドを実行してバージョン番号を表示できます。 |
接続文字列モード
より柔軟性を高めるために、接続文字列モードでデータソースを作成することもできます。次の表にパラメーターを説明します:
パラメーター | 説明 |
データソース名 | データソースの名前。名前はワークスペース内で一意である必要があります。ビジネスと環境を識別する名前 (例: |
設定モード | 接続文字列モード を選択します。このモードは、JDBC URL を使用してデータベースに接続します。 |
JDBC 接続文字列プレビュー | エンドポイントとデータベース名を入力すると、DataWorks はそれらを自動的に連結して JDBC URL をプレビュー用に生成します。 |
接続アドレス | ホスト IP:データベースホストの IP アドレスまたはドメイン名。データベースが Alibaba Cloud RDS インスタンスの場合、インスタンスの製品ページでエンドポイントを表示できます。 ポート:データベースポート。デフォルト値は 3306 です。 |
データベース名 | データソースがアクセスする必要のあるデータベースの名前。指定されたユーザーがデータベースにアクセスする権限を持っていることを確認してください。 |
ユーザー名/パスワード | MySQL データベースアカウントのユーザー名とパスワード。RDS インスタンスを使用する場合、インスタンスの アカウント管理 セクションでアカウントを作成および管理できます。 |
バージョン | MySQL サーバーにログインし、`SELECT VERSION()` コマンドを実行してバージョン番号を表示できます。 |
認証方法 | 認証なしまたは SSL 認証を選択できます。SSL 認証を選択する場合、インスタンス自体で SSL 認証が有効になっている必要があります。証明書ファイルを準備し、認証ファイル管理 にアップロードします。 |
詳細パラメーター | パラメーター:パラメーターのドロップダウンリストをクリックし、サポートされているパラメーター名 (例: 値:選択したパラメーターの値 (例: 3000) を入力します。 URL は自動的に更新されます: |
リソースグループがデータソースに接続できることを確認する必要があります。そうしないと、後続のタスクを実行できません。必要なネットワーク設定は、データソースのネットワーク環境と接続モードによって異なります。詳細については、「接続性テスト」をご参照ください。
データ同期タスクの開発:MySQL 同期プロセスのガイド
同期タスクの設定のエントリポイントと手順については、以下の設定ガイドをご参照ください。
単一テーブルのオフライン同期タスクの設定ガイド
手順については、「コードレス UI でオフライン同期タスクを設定する」および「コードエディタでオフライン同期タスクを設定する」をご参照ください。
コードエディタのパラメーターの完全なリストとスクリプトの例については、「付録:MySQL スクリプトの例とパラメーターの説明」をご参照ください。
単一テーブルのリアルタイム同期タスクの設定ガイド
手順については、「DataStudio でリアルタイム同期タスクを設定する」をご参照ください。
データベースレベルの同期タスクの設定ガイド:オフライン、完全および増分 (リアルタイム)、シャーディング (リアルタイム)
手順については、「Data Integration で同期タスクを設定する」をご参照ください。
よくある質問
MySQL データソースのリアルタイム同期タスクが、最初はデータを読み取るが、しばらくするとデータの読み取りを停止するのはなぜですか?
MySQL データベースからの読み取り時のエラー:サーバーから最後に正常に受信したパケットは 902,138 ミリ秒前です
Data Integration のその他の一般的な問題については、「Data Integration に関するよくある質問」をご参照ください。
付録:MySQL スクリプトの例とパラメーターの説明
コードエディタを使用したバッチ同期タスクの設定
コードエディタを使用してバッチ同期タスクを設定する場合、統一されたスクリプトフォーマット要件に基づいて、スクリプト内の関連パラメーターを設定する必要があります。詳細については、「コードエディタでタスクを設定する」をご参照ください。以下の情報は、コードエディタを使用してバッチ同期タスクを設定する際に、データソースに対して設定する必要があるパラメーターについて説明しています。
Reader スクリプトの例
このセクションでは、単一データベース内の単一テーブルとシャーディングされたテーブルの設定例を示します:
以下の JSON の例のコメントは、デモンストレーションのみを目的としています。スクリプトを設定する際には、コメントを削除する必要があります。
単一データベース内の単一テーブル
{ "type": "job", "version": "2.0",// バージョン番号。 "steps": [ { "stepType": "mysql",// プラグイン名。 "parameter": { "column": [// 列名。 "id" ], "connection": [ { "querySql": [ "select a,b from join1 c join join2 d on c.id = d.id;" ], "datasource": ""// データソース名。 } ], "where": "",// フィルター条件。 "splitPk": "",// シャードキー。 "encoding": "UTF-8"// エンコーディング形式。 }, "name": "Reader", "category": "reader" }, { "stepType": "stream", "parameter": {}, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "0"// 許可されるエラーレコード数。 }, "speed": { "throttle": true,// throttle が false に設定されている場合、mbps パラメーターは効果がなく、データ転送レートは制限されません。throttle が true に設定されている場合、データ転送レートは制限されます。 "concurrent": 1,// 同時実行ジョブ数。 "mbps": "12"// 最大データ転送レート。1 mbps = 1 MB/s。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }シャーディングされたテーブル
説明シャーディングにより、MySQL Reader は同じスキーマを持つ複数の MySQL テーブルを選択できます。この文脈では、シャーディングとは、複数のソース MySQL テーブルから単一の宛先テーブルにデータを書き込むことを意味します。データベースレベルのシャーディングを設定するには、Data Integration でタスクを作成し、データベースレベルのシャーディング機能を選択できます。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "mysql", "parameter": { "indexes": [ { "type": "unique", "column": [ "id" ] } ], "envType": 0, "useSpecialSecret": false, "column": [ "id", "buyer_name", "seller_name", "item_id", "city", "zone" ], "tableComment": "テスト注文テーブル", "connection": [ { "datasource": "rds_dataservice", "table": [ "rds_table" ] }, { "datasource": "rds_workshop_log", "table": [ "rds_table" ] } ], "where": "", "splitPk": "id", "encoding": "UTF-8" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": {}, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }
Reader スクリプトのパラメーター
パラメーター | 説明 | 必須 | デフォルト値 |
datasource | データソースの名前。コードエディタはデータソースの追加をサポートしています。このパラメーターの値は、追加されたデータソースの名前と同じである必要があります。 | はい | なし |
table | データを同期するテーブルの名前。データ統合タスクは、1 つのテーブルからのみデータを読み取ることができます。 table パラメーターの高度な使用法として、範囲を設定する例を以下に示します:
説明 タスクは、一致するすべてのテーブルを読み取ります。具体的には、これらのテーブルの column パラメーターで指定された列を読み取ります。テーブルまたは列が存在しない場合、タスクは失敗します。 | はい | なし |
column | 設定されたテーブルから同期する列名のコレクション。JSON 配列を使用してフィールド情報を記述します。デフォルトでは、すべての列が設定されます (例: [*])。
| はい | なし |
splitPk | MySQL Reader がデータを抽出する際に、splitPk パラメーターを指定すると、splitPk が表すフィールドに基づいてデータがシャーディングされます。これにより、データ同期が同時実行タスクとして実行され、同期効率が向上します。
| いいえ | なし |
splitFactor | シャーディング係数。データ同期のシャード数を設定できます。複数の同時実行スレッドを設定した場合、データは `同時実行スレッド数 × splitFactor` の部分にシャーディングされます。たとえば、同時実行スレッド数が 5 で、splitFactor が 5 の場合、データは 5 × 5 = 25 の部分にシャーディングされ、5 つの同時実行スレッドによって処理されます。 説明 推奨値の範囲は 1 から 100 です。値が大きすぎると、メモリ不足 (OOM) エラーが発生する可能性があります。 | いいえ | 5 |
where | フィルター条件。多くのビジネスシナリオでは、当日のデータのみを同期したい場合があります。where 条件を
| いいえ | なし |
querySql (高度なモード。このパラメーターはコードレス UI ではサポートされていません。) | 一部のビジネスシナリオでは、`where` パラメーターだけではフィルター条件を記述するのに不十分な場合があります。このパラメーターを使用して、カスタムフィルター SQL ステートメントを定義できます。このパラメーターを設定すると、システムは `tables`、`columns`、および `splitPk` パラメーターを無視し、このパラメーターの内容を使用してデータをフィルター処理します。たとえば、複数テーブルの結合後にデータを同期するには、 説明 querySql パラメーターは大文字と小文字を区別します。たとえば、querysql と書くと、効果がありません。 | いいえ | なし |
useSpecialSecret | 複数のソースデータソースがある場合、各データソースのパスワードを使用するかどうかを指定します。有効な値:
複数のソースデータソースを設定し、各データソースが異なるユーザー名とパスワードを使用している場合、このパラメーターを true に設定して、各データソースのパスワードを使用できます。 | いいえ | false |
Writer スクリプトの例
{
"type": "job",
"version": "2.0",// バージョン番号。
"steps": [
{
"stepType": "stream",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "mysql",// プラグイン名。
"parameter": {
"postSql": [],// インポート後に実行される SQL ステートメント。
"datasource": "",// データソース。
"column": [// 列名。
"id",
"value"
],
"writeMode": "insert",// 書き込みモード。insert、replace、または update に設定できます。
"batchSize": 1024,// 1 回のバッチで送信されるレコード数。
"table": "",// テーブル名。
"nullMode": "skipNull",// null 値の処理ポリシー。
"skipNullColumn": [// null 値をスキップする列。
"id",
"value"
],
"preSql": [
"delete from XXX;"// インポート前に実行される SQL ステートメント。
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {// 許可されるエラーレコード数。
"record": "0"
},
"speed": {
"throttle": true,// throttle が false に設定されている場合、mbps パラメーターは効果がなく、データ転送レートは制限されません。throttle が true に設定されている場合、データ転送レートは制限されます。
"concurrent": 1,// 同時実行ジョブ数。
"mbps": "12"// 最大データ転送レート。これにより、上流/下流のデータベースへの過剰な読み取り/書き込み圧力を防ぎます。1 mbps = 1 MB/s。
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Writer スクリプトのパラメーター
パラメーター | 説明 | 必須 | デフォルト値 |
datasource | データソースの名前。コードエディタはデータソースの追加をサポートしています。このパラメーターの値は、追加されたデータソースの名前と同じである必要があります。 | はい | なし |
table | データを同期するテーブルの名前。 | はい | なし |
writeMode | インポートモード。INSERT INTO、ON DUPLICATE KEY UPDATE、または REPLACE INTO を選択できます。
| いいえ | insert |
nullMode | null 値の処理ポリシー。有効な値:
重要 このパラメーターを skipNull に設定すると、タスクは宛先のデフォルト値をサポートするためにデータを書き込む SQL ステートメントを動的に生成します。これにより、FLUSH 操作の数が増加し、同期速度が低下します。最悪の場合、データレコードごとに FLUSH 操作が実行されます。 | いいえ | writeNull |
skipNullColumn | nullMode が skipNull に設定されている場合、このパラメーターに設定された列は強制的に フォーマット: | いいえ | デフォルトでは、タスクに設定されたすべての列。 |
column | データを書き込む宛先テーブルのフィールド。フィールドをカンマ (,) で区切ります。例: | はい | なし |
preSql | データ同期タスクが開始される前に実行される SQL ステートメント。コードレス UI では、1 つの SQL ステートメントしか実行できません。コードエディタでは、複数の SQL ステートメントを実行できます。たとえば、実行前にテーブルから古いデータをクリアできます:`TRUNCATE TABLE tablename`。 説明 複数の SQL ステートメントに対するトランザクションはサポートされていません。 | いいえ | なし |
postSql | データ同期タスクが完了した後に実行される SQL ステートメント。コードレス UI では、1 つの SQL ステートメントしか実行できません。コードエディタでは、複数の SQL ステートメントを実行できます。たとえば、タイムスタンプを追加できます: 説明 複数の SQL ステートメントに対するトランザクションはサポートされていません。 | いいえ | なし |
batchSize | 1 回のバッチで送信されるレコード数。値を大きくすると、データ同期システムと MySQL 間のネットワーク対話が大幅に減少し、全体のスループットが向上します。この値が高すぎると、データ同期プロセスでメモリ不足 (OOM) エラーが発生する可能性があります。 | いいえ | 256 |
updateColumn | writeMode が update に設定されている場合、プライマリキーまたは一意なインデックスの競合が発生したときに更新されるフィールドです。フィールドをカンマ (,) で区切ります。例: | いいえ | なし |