データセキュリティガードでは、機密フィールドタイプに基づいて機密データ検出ルールを設定できます。ルールを設定した後、それを使用してテナント内の対応するタイプの機密データを検出できます。DataWorks は、さまざまな組み込みの機密フィールドタイプと検出ルールを提供します。組み込みのルールがビジネス要件を満たさない場合は、カスタムの機密フィールドタイプと検出ルールを作成できます。このトピックでは、機密フィールドタイプの作成方法とデータ検出ルールの設定方法について説明します。
背景情報
DataWorks では、データの感度レベルとカテゴリに基づいてデータ検出ルールを定義できます。これにより、組織内の機密データを検出できます。検出結果が不正確な場合は、機密データ検出結果の表示と手動修正が可能です。[機密データの概要] モジュールには、最近検出ルールに一致したすべての機密フィールドの分布が、プロジェクトごとに分類されて表示されます。以下の図は、データ検出ルールの使用方法を示しています。
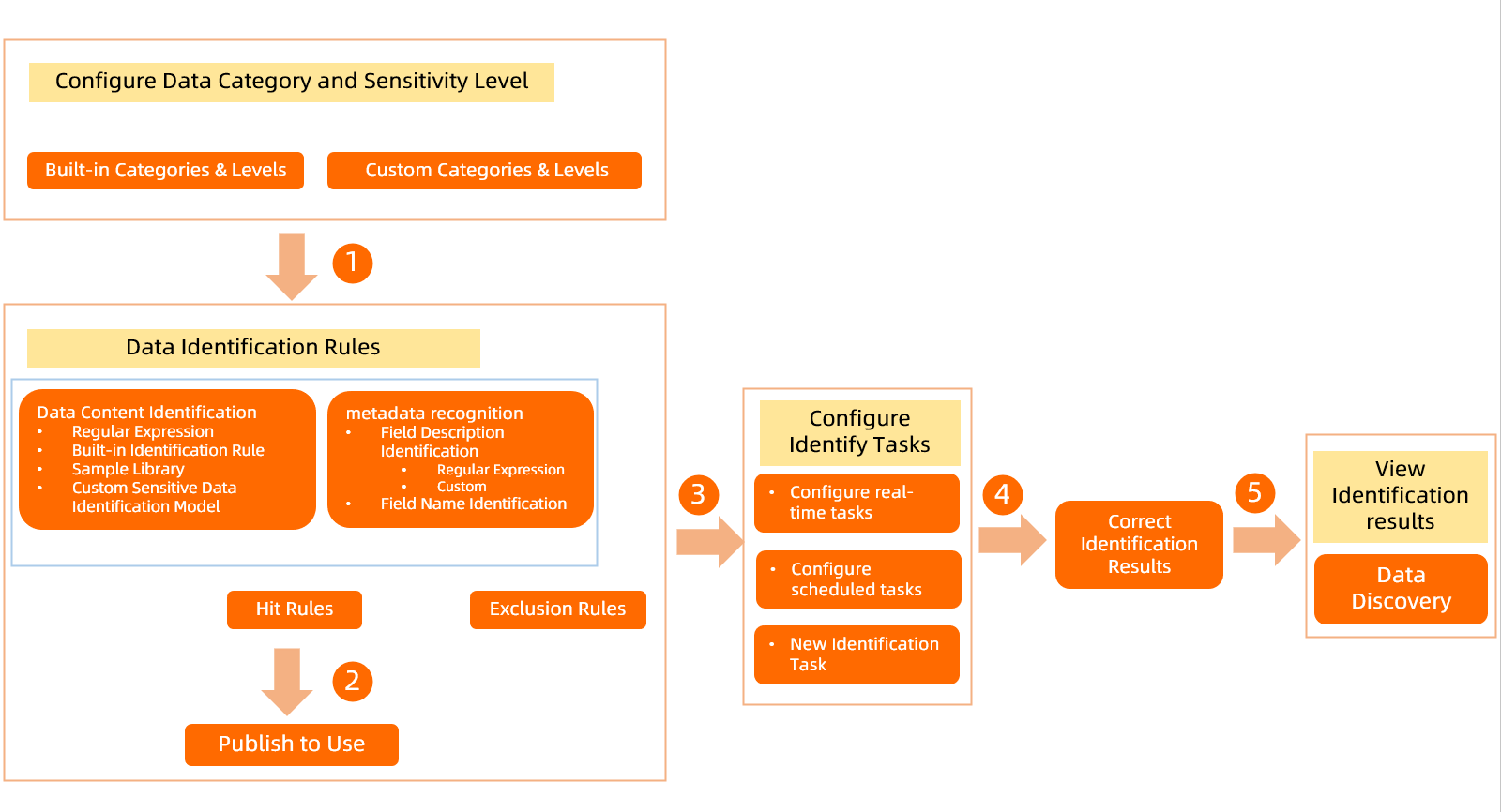
[データ検出ルール] ページへ移動
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、[セキュリティセンターへ] をクリックします。
左側のナビゲーションウィンドウで、 をクリックして、[データセキュリティガード] ページに移動します。
説明ご利用の Alibaba Cloud アカウントに必要な権限が付与されている場合、直接 [データセキュリティガード] ページにアクセスできます。
ご利用の Alibaba Cloud アカウントに必要な権限が付与されていない場合、データセキュリティガードの権限付与ページにリダイレクトされます。Alibaba Cloud アカウントに必要な権限が付与された後にのみ、データセキュリティガードの機能を使用できます。
左側のナビゲーションウィンドウで、 をクリックして、[データ検出ルール] ページに移動します。
ステップ 1:機密フィールドの分類とグレーディングの設定
機密フィールドタイプは、データカテゴリに属し、定義された感度レベルを持つ必要があります。したがって、機密フィールドタイプを作成して検出ルールを設定する前に、データの分類とグレーディングを設定する必要があります。
データセキュリティガードは、組み込みの分類とグレーディングテンプレートを提供します。このテンプレートには、直接使用できる 4 つの感度レベルと 4 つの主要カテゴリが含まれています。DataWorks では、組み込みテンプレートの分類とグレードを編集したり、カスタムのものを作成したりできます。最大 10 の感度レベルを定義できます。カテゴリについては、複数レイヤーのカテゴリ、サブカテゴリ、およびそれらが含む機密フィールドタイプを定義できます。
ページで、フィールドの感度グレーディングを設定できます。
[データ分類とグレーディング] ページには、デフォルトの組み込みテンプレートが表示されます。テンプレートの横にある
 アイコンをクリックして、テンプレート名、説明、およびグレード数を編集します。
アイコンをクリックして、テンプレート名、説明、およびグレード数を編集します。
ページで、機密フィールドの分類を設定できます。
データセキュリティガードを初めて使用する場合、[データ検出ルール] ページの左側に [組み込みの分類とグレーディングテンプレート] のデフォルトカテゴリが表示されます。カテゴリを名前で検索できます。また、カテゴリ名の横にある
 アイコンをクリックして、[同レベルのカテゴリを追加]、[サブカテゴリを追加]、[名前の変更]、または [削除] を行うことができます。
アイコンをクリックして、[同レベルのカテゴリを追加]、[サブカテゴリを追加]、[名前の変更]、または [削除] を行うことができます。既存のデータセキュリティガードユーザーの場合、[データ検出ルール] ページの左側で最大 4 つのデータカテゴリを作成できます。
カテゴリ名は一意である必要があります。長さは 1~30 文字で、英数字のみ使用できます。
カテゴリを削除する前に、公開済みの機密データ検出ルールが含まれているかどうかを確認してください。含まれている場合は、カテゴリを削除する前に、そのカテゴリ内のすべてのルールを非アクティブ化する必要があります。詳細については、「データ検出ルールの管理」をご参照ください。
機密データのグレーディング設定方法の詳細については、「機密データの分類とグレーディングの設定」をご参照ください。
ステップ 2:機密データ検出ルールの設定
機密データ検出ルールは、機密フィールドタイプに基づいて設定する必要があります。このトピックでは、機密フィールドタイプの作成とデータ検出ルールの設定を例に、設定の詳細を説明します。組み込みの機密フィールドタイプに基づいてデータ検出ルールを設定することもできます。
[データ検出ルール] ページで、右上の [+ 機密フィールドタイプ] をクリックして、機密フィールドタイプを追加します。
機密フィールドタイプの基本情報を設定します。
[基本情報] タブで、機密フィールドのタイプ、分類、グレーディングなどのパラメーターを設定します。
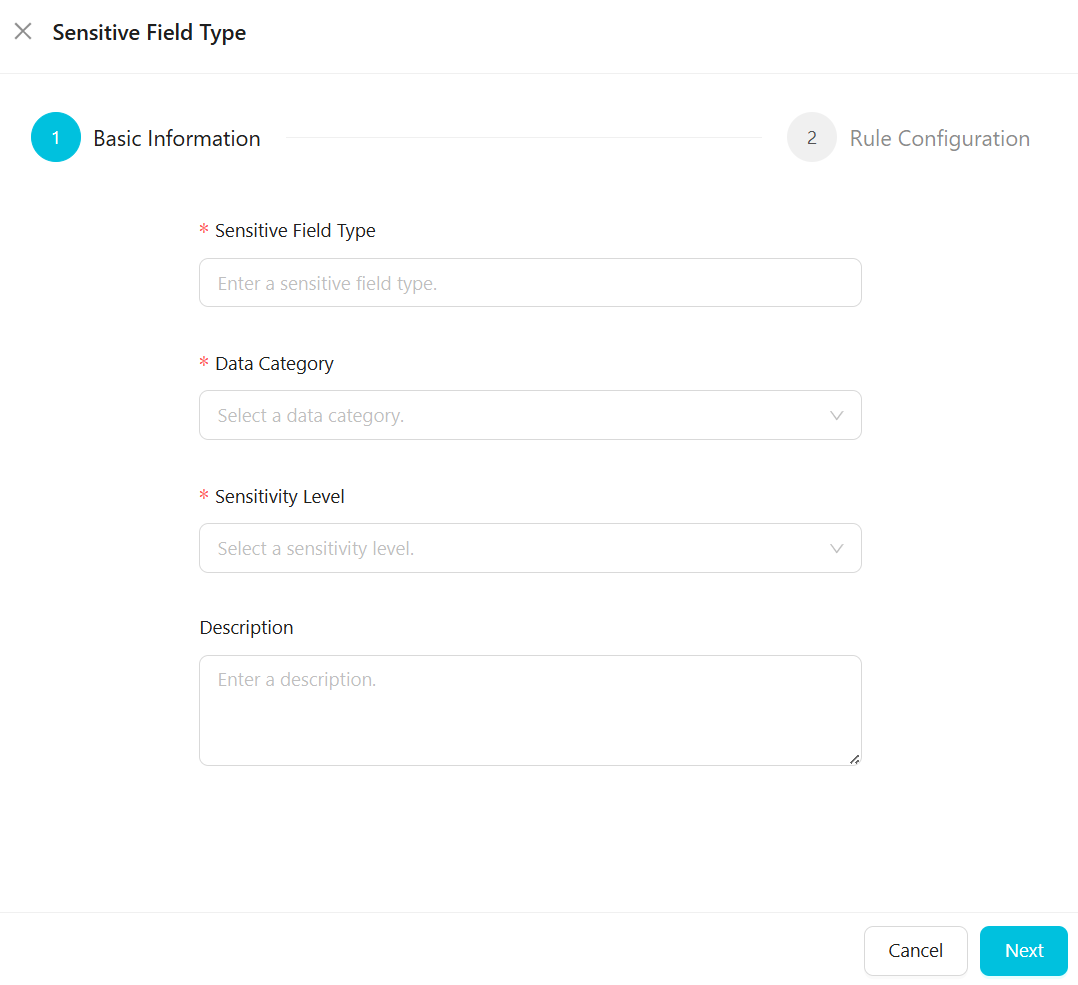
次の表に、主なパラメーターを説明します。
パラメーター
説明
機密フィールドタイプ
機密フィールドタイプのカスタム名 (例:名前、ID カード番号、電話番号)。名前は一意である必要があります。
カテゴリ
機密フィールドタイプが属するカテゴリ。既存のカテゴリがニーズを満たさない場合は、[データ分類とグレーディング] ページに移動してカテゴリを設定します。詳細については、「機密データの分類とグレーディングの設定」をご参照ください。
[感度レベル]
機密フィールドタイプが属する感度レベル。数値が大きいほど感度レベルが高くなります。既存のグレードがニーズを満たさない場合は、[データ分類とグレーディング] ページに移動してグレードを設定します。詳細については、「機密データの分類とグレーディングの設定」をご参照ください。
[次へ] をクリックします。
機密フィールドタイプの検出ルールを設定します。
[ルール設定] タブで、機密データ検出ルールとその一致条件を設定し、ルールの精度をテストします。
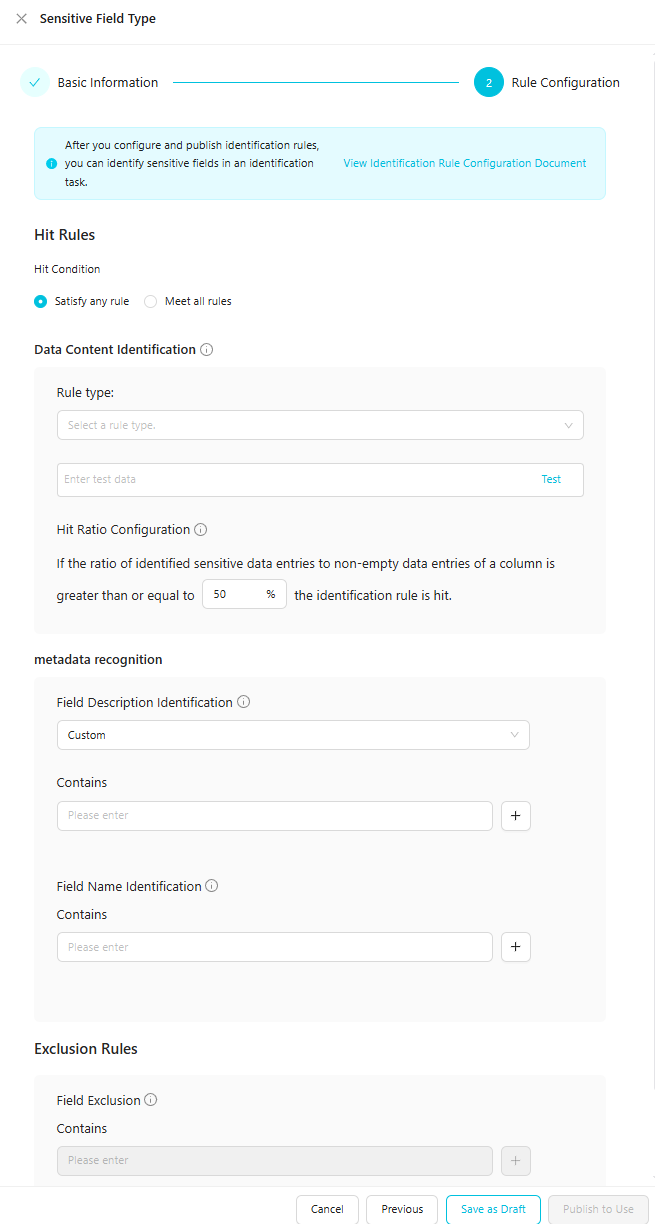
パラメーター
説明
ルールヒット数
右側のドロップダウンリストから検出ルールのヒット条件を選択します:
いずれかのルールを満たす: 検出ルールは、
データ内容の検出またはフィールド名の検出のいずれかの条件が満たされた場合にヒットします。すべてのルールに一致:
Data content detectionとField name detectionの両方の条件が満たされた場合にのみ、検出ルールがヒットします。
説明[ルールヒット数] パラメーターは、
データ内容の検出およびフィールド名の検出ルールにのみ有効になります。データコンテンツ検出
フィールドのデータ内容、つまりフィールドの値に基づいて機密データを検出します。たとえば、
nameフィールドの値が Zhang San の場合、ルールは Zhang San を検出します。説明コンテンツスキャン機能は、DataWorks Professional Edition 以上で利用できます。下位エディションの DataWorks を使用している場合は、Professional Edition 以上にスペックアップしてください。スペックアップの詳細については、「ソフトウェアバージョンの選択と支払い」をご参照ください。
ルールタイプに基づいて機密データ検出ルールの内容を定義し、機密テキストに一致させます。4 つのルールタイプが利用可能です:
[正規表現]:検出ルールの正規表現を入力し、テストデータを入力してルールの精度をテストします。
[組み込み検出ルール]:組み込みの検出ルールを選択し、テストデータを入力してルールの精度をテストします。
説明[組み込み検出ルール] は DataWorks Enterprise Edition でのみ選択できます。
[サンプルライブラリ]:設定済みのルールサンプルを選択し、テストデータを入力してルールの精度をテストします。サンプルの設定方法の詳細については、「サンプルライブラリを使用した検出」をご参照ください。
[カスタムモデル]:カスタムルールモデルを選択し、テストデータを入力してルールの精度をテストします。カスタムモデルの設定方法の詳細については、「カスタムモデルを使用した検出」をご参照ください。
説明[カスタムモデル] ルールは MaxCompute DPI エンジンでのみ選択できます。[カスタムモデル] は DataWorks Enterprise Edition でのみ使用できます。
フィールド名検出
フィールドの名前に基づいて機密データを検出します。たとえば、
nameフィールドの値が Zhang San の場合、ルールはnameを検出します。機密データとして検出するフィールドを入力します。複数のフィールドを指定できます。フィールド間の論理関係は
ORです。データソースごとの入力フォーマットは次のとおりです。EMR、CDH、および MaxCompute:
project.table.columnHologres:
instance_id.project.table.column
入力フォーマットの任意のセグメントでアスタリスク (*) をワイルドカード文字として使用できます。例:
a.b.*:プロジェクト a のテーブル b 内のすべてのフィールドが機密データとして検出されます。
ab*.c*.salary:名前が ab で始まるプロジェクト内の、名前が c で始まるテーブルのすべての salary フィールドが機密データとして検出されます。
*cd.ef*.sa*ry:名前が cd で終わるプロジェクト内の、名前が ef で始まるテーブルの、名前が sa で始まり ry で終わるすべてのフィールドが機密データとして検出されます。
フィールドコメント検出
フィールドのコメントに基づいて機密データを検出します。たとえば、電話番号の機密フィールドタイプのコメントを「電話番号」と「連絡先」として設定できます。システムがデータコメントに「連絡先」が含まれていることを検出すると、そのデータは電話番号として検出されます。
入力ボックスにフィールドコメントを入力します。コメントの長さは 0~100 文字です。すべての文字タイプがサポートされています。最大 10 個の入力ボックスを追加できます。
フィールド除外
除外するフィールドを入力してください。除外ルールに一致するフィールドは、この検出ルールにヒットしません。複数のフィールドを指定できます。フィールド間の論理関係は
ORです。データソースごとの入力フォーマットは次のとおりです。EMR、CDH、および MaxCompute:
project.table.columnHologres:
instance_id.project.table.column
入力フォーマットの任意のセグメントでアスタリスク (*) をワイルドカード文字として使用できます。例:
a.b.*:プロジェクト a のテーブル b 内のすべてのフィールドが機密データとして検出されます。
ab*.c*.salary:名前が ab で始まるプロジェクト内の、名前が c で始まるテーブルのすべての salary フィールドが機密データとして検出されます。
*cd.ef*.sa*ry:名前が cd で終わるプロジェクト内の、名前が ef で始まるテーブルの、名前が sa で始まり ry で終わるすべてのフィールドが機密データとして検出されます。
ヒット率設定
ルールのカスタムヒット率を定義します。これは、検出ルールがヒットするために、カラム内の空ではないデータが
[Data content detection]条件に一致する必要がある割合を指定します。たとえば、50% です。デフォルト値は 50% です。ヒット率は、数式:
100% × 検出ルールにヒットした列内のデータレコード数 / 列内の総データレコード数を使用して計算されます。説明ヒット率は、
データ内容検出ルールにのみ適用されます。データ検出ルールを公開します。
[公開] をクリックして、現在のデータ検出ルールを公開します。ルールが公開されると、検出タスクでそれを使用して対応する機密データを検出できます。
ルールをすぐに使用する必要がない場合は、[下書きとして保存] をクリックしてデータ検出ルールを保存します。
列内のデータが複数の機密フィールドタイプの検出ルールに一致する場合、ルールは次の順序で有効になります:
これらの機密フィールドタイプの一致条件の数が同じ場合、検出順序は です。
一致条件の数とタイプが同じ場合、感度レベルが高い機密フィールドタイプの検出ルールが優先されます。
ステップ 3:機密データ検出タスクの権限付与と開始
機密データ検出ルールを設定した後、機密データ検出タスクの権限を付与して開始する必要があります。タスクが開始されると、プラットフォームは検出ルールに基づいてテナント内の機密データを検出します。
機密データ検出タスクの権限を付与します。
初めて機密データ検出タスクを開始するときは、[機密データ検出] ページの左上隅にある [有効化して権限付与] をクリックし、プロンプトに従って権限を付与します。
説明機密データ検出タスクが開始された後、[機密データ検出] ページの右上隅にある [権限付与レコード] をクリックして、権限付与の詳細を表示できます。
機密データ検出タスクを開始します。
機密データ検出タスクを設定します。
機密データ検出タスクを設定する際には、そのタイプ、スキャン方法、およびスキャン範囲を設定する必要があります。リアルタイムタスク、定期タスク、またはワンタイムタスクを設定できます。
リアルタイムタスクを設定します。
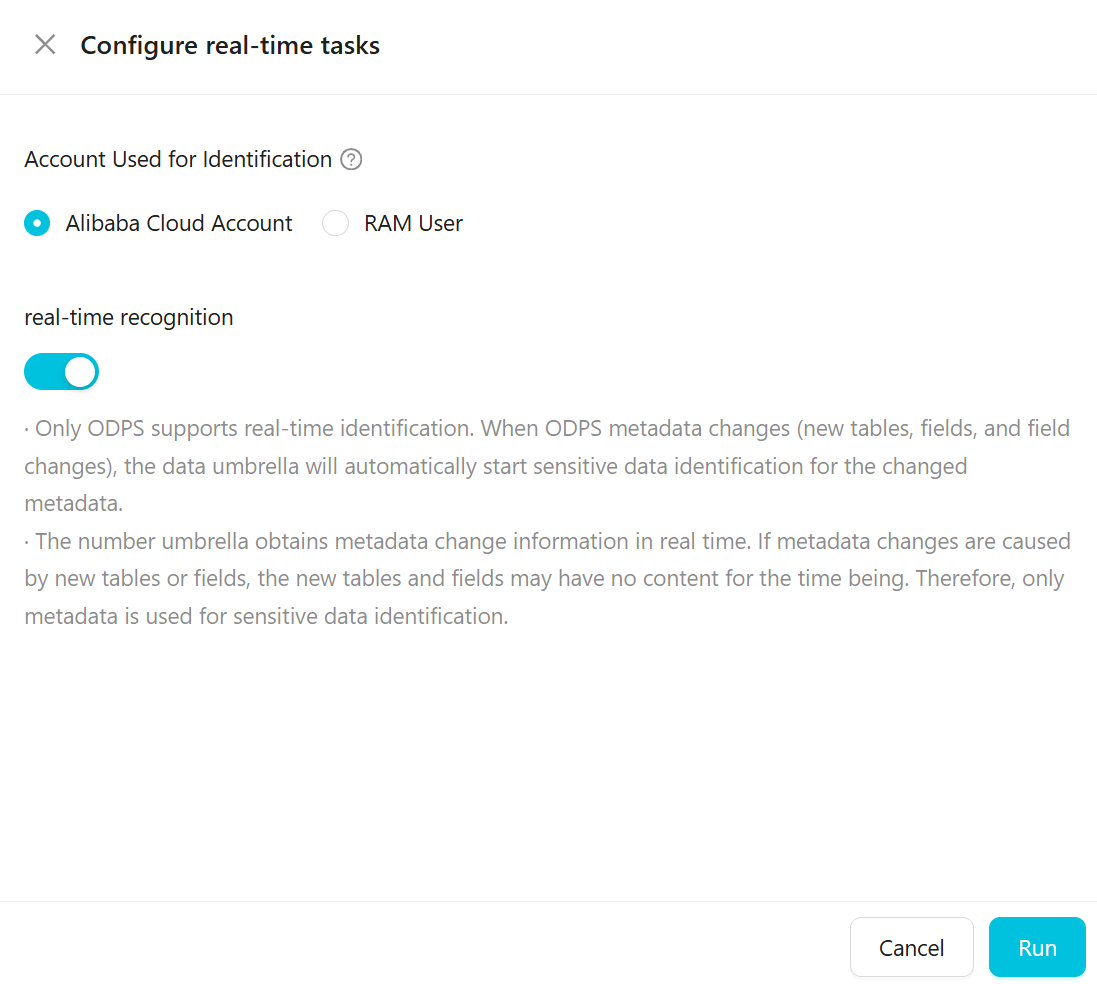
次の表に、パラメーターを説明します。
パラメーター
説明
[検出用アカウント]
データのサンプリングとスキャンを行うAlibaba Cloud アカウントまたは RAM ユーザーを指定します。データは選択されたアカウントを使用してサンプリングおよびスキャンされます。サンプリングできるデータの範囲は、アカウントの権限によって異なります。
説明検出に RAM ユーザーを使用する場合、その RAM ユーザーは MaxCompute プロジェクトに対する権限を持っている必要があります。
リアルタイム検出
ODPS のみがリアルタイム検出をサポートしています。ODPS メタデータが変更された場合 (テーブルやフィールドの追加、フィールドの変更など)、データセキュリティガードは変更されたメタデータに対して自動的に機密データ検出タスクを開始します。
データセキュリティガードはメタデータの変更をリアルタイムで取得します。変更が新しいテーブルやフィールドによるものである場合、新しいテーブルやフィールドにはまだ内容がない可能性があります。この場合、メタデータのみが機密データ検出に使用されます。
定期タスクを設定します。
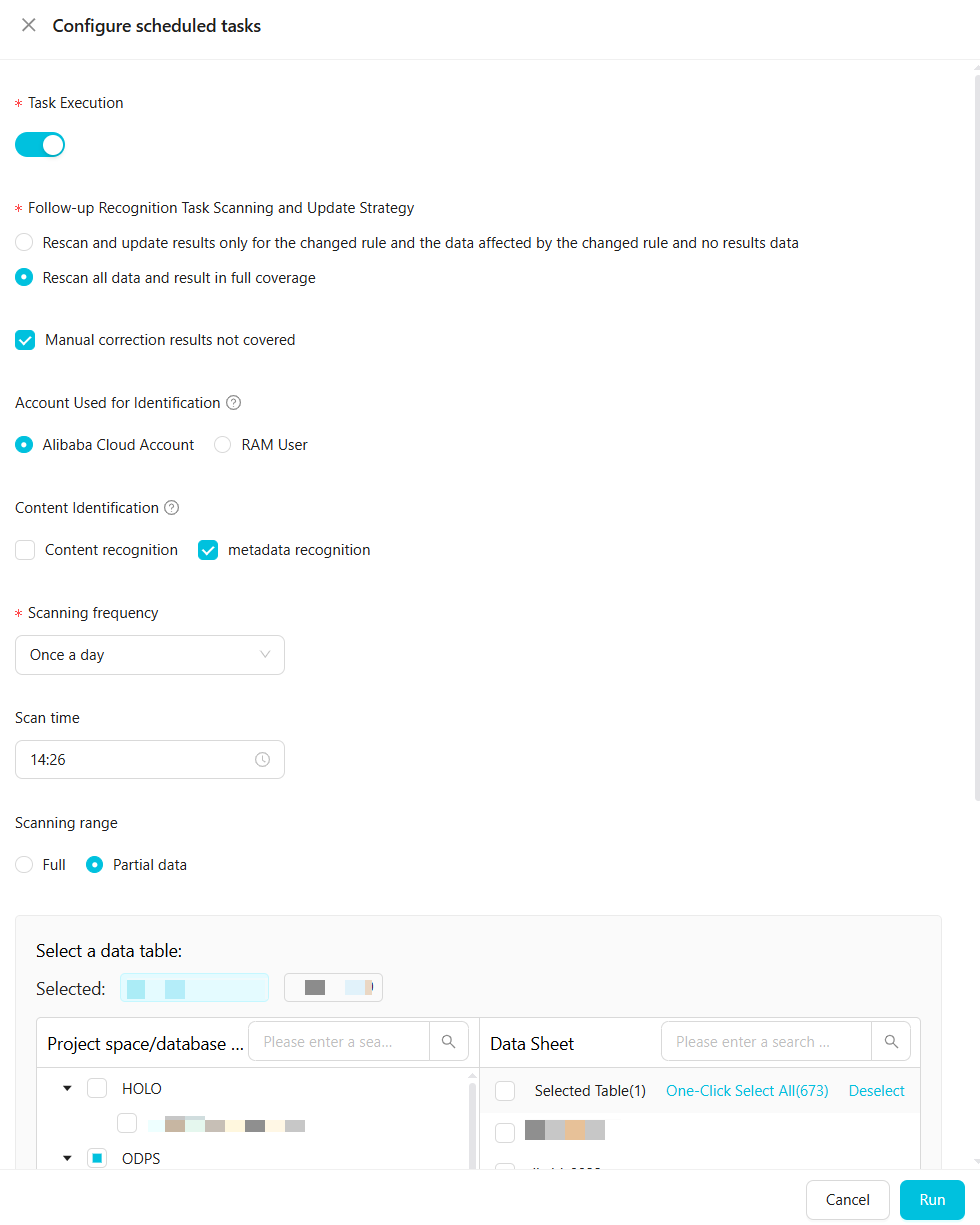 次の表に、パラメーターを説明します。
次の表に、パラメーターを説明します。パラメーター
説明
タスク実行
タスクを手動で開始する必要があります。
[後続の検出タスクのスキャンおよび更新ポリシー]
2 つのオプションが利用可能です:
変更されたルール、影響を受けるデータ、および結果のないデータのみを再スキャンして結果を更新します。
すべてのデータを再スキャンし、以前のすべての結果を上書きします。
[手動で修正された結果を上書きしない] を選択できます。
[検出用アカウント]
データのサンプリングとスキャンを行う Alibaba Cloud アカウントまたは RAM ユーザーを指定します。データは選択されたアカウントを使用してサンプリングおよびスキャンされます。サンプリングおよびスキャンできるデータの範囲は、アカウントの権限によって異なります。
説明データのサンプリングとスキャンに RAM ユーザーを使用する場合、その RAM ユーザーは MaxCompute プロジェクトに対する権限を持っている必要があります。
コンテンツ検出
[内容検出] と [メタデータ検出] ルールが有効になるかどうかを指定します。対応するルールは、それらを選択した後にのみ有効になります。
説明[内容検出] を選択しない場合、データセキュリティガードはデータをサンプリングまたはスキャンしません。内容検出ルールは有効になりません。ただし、フィールド名およびフィールドコメント検出ルールは引き続き有効です。
[サンプリング数]
内容検出のためにサンプリングするデータレコードの数。100 を超える値を推奨します。
[内容検出] を選択した場合は、このパラメーターを設定する必要があります。
[スキャン頻度] と [スキャン時間]
定期タスクのスキャンエポックを定義します。
[タスクタイプ] を [定期タスク] に設定した場合にのみ、このパラメーターを設定します。
スキャン頻度を週に 1 回または日に 1 回に設定します。週次スキャンの場合は、月曜日から金曜日までの曜日を選択します。時間範囲は 0:00 から 23:59 です。
スキャン範囲
機密データ検出タスクがスキャンするデータの範囲を設定します。
[すべて]:現在のテナントの権限付与されたアカウント配下のすべてのデータをスキャンします。
[一部のデータ]:指定されたプロジェクトのテーブルのデータをスキャンします。
説明デフォルトでは、プロジェクト範囲にはすべてのデータ処理エンジンのすべてのプロジェクトが含まれます。
ODPS、EMR、および Hologres プロジェクトで指定されたテーブルをスキャンできます。
テーブル名の全長は
0~100文字です。すべての文字タイプがサポートされています。これを空白のままにすると、すべてのテーブルがスキャンされます。ワイルドカード文字
.*がサポートされています。たとえば、.*nameは、サフィックスがnameである名前を示します。private.*は、プレフィックスがprivateである名前を示します。複数のテーブル名またはフィールド名をコンマ (,) で区切ります。
[一部のデータ] を選択して、複数のプロジェクトまたはデータベースのスキャン範囲を追加します。最終的なスキャン範囲は、追加されたすべての範囲の和集合です。
左側のペインでプロジェクトを手動で選択します。
プロジェクトを選択すると、そのプロジェクトまたはデータベース内のデータテーブルが右側に表示されます。テーブルを手動で選択するか、一度にすべてのテーブルを選択できます。デフォルトでは、データベース内のすべてのデータテーブルが選択されます。
キーワードでプロジェクトまたはデータベースの範囲とデータテーブルを検索できます。キーワードでデータテーブルを検索するには、まず検索対象のプロジェクトを選択します。
ワンタイムタスクを設定します。
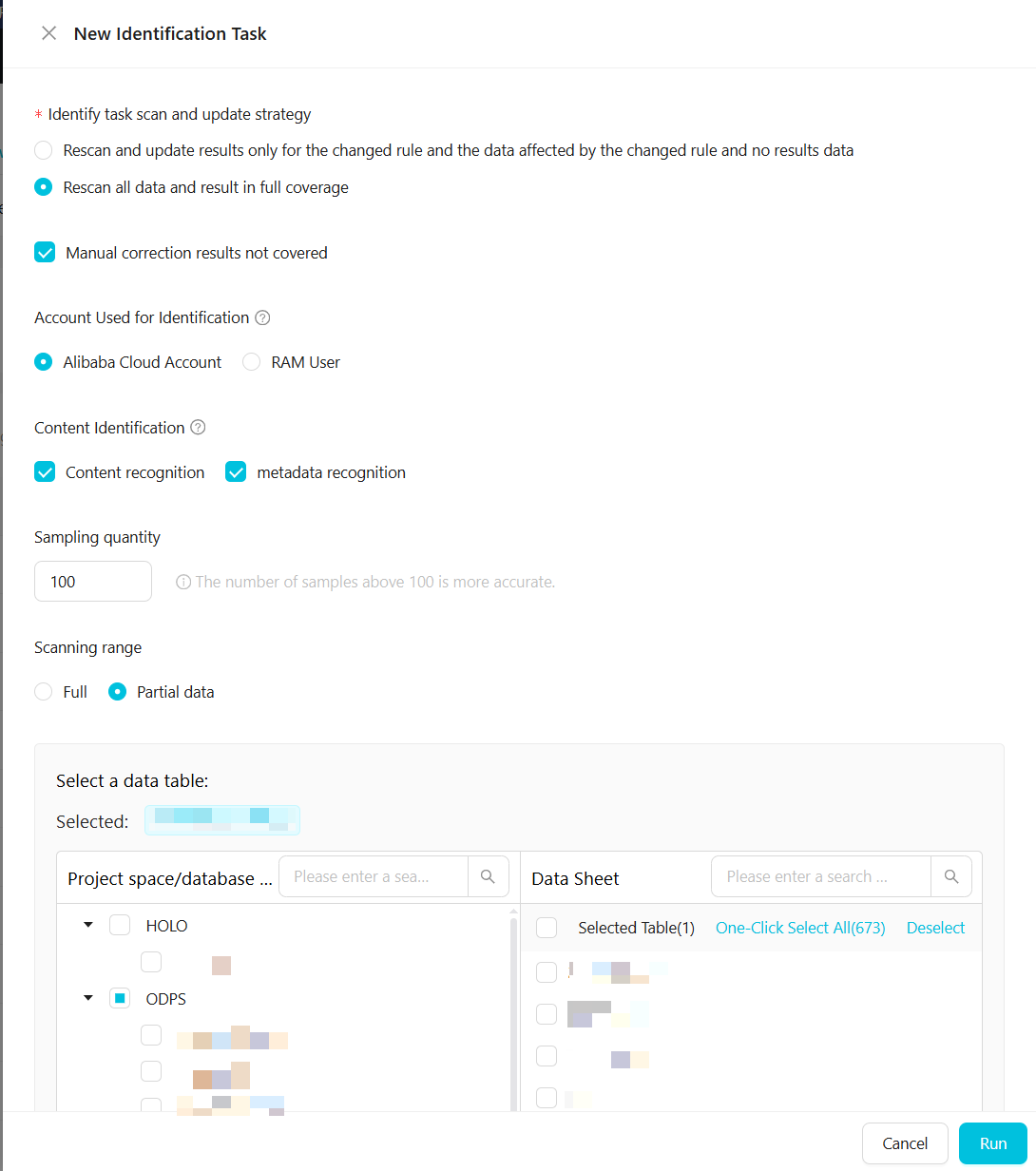 次の表に、パラメーターを説明します。
次の表に、パラメーターを説明します。パラメーター
説明
[検出タスクのスキャンおよび更新ポリシー]
2 つのオプションが利用可能です:
変更されたルール、影響を受けるデータ、および結果のないデータのみを再スキャンして結果を更新します。
すべてのデータを再スキャンし、以前のすべての結果を上書きします。
[手動で修正された結果を上書きしない] を選択できます。
[検出用アカウント]
データのサンプリングとスキャンを行う Alibaba Cloud アカウントまたは RAM ユーザーを指定します。データは選択されたアカウントを使用してサンプリングおよびスキャンされます。サンプリングおよびスキャンできるデータの範囲は、アカウントの権限によって異なります。
説明データのサンプリングとスキャンに RAM ユーザーを使用する場合、その RAM ユーザーは MaxCompute プロジェクトに対する権限を持っている必要があります。
コンテンツ検出
[内容検出] と [メタデータ検出] ルールが有効になるかどうかを指定します。対応するルールは、それらを選択した後にのみ有効になります。
説明[内容検出] を選択しない場合、データセキュリティガードはデータをサンプリングまたはスキャンしません。内容検出ルールは有効になりません。ただし、フィールド名およびフィールドコメント検出ルールは引き続き有効です。
サンプリング数量
内容検出のためにサンプリングするデータレコードの数。100 を超える値を推奨します。
[内容検出] を選択した場合は、このパラメーターを設定する必要があります。
[スキャン範囲]
機密データ検出タスクがスキャンするデータの範囲を設定します。
[すべて]:現在のテナントの権限付与されたアカウント配下のすべてのデータをスキャンします。
[一部のデータ]:指定されたプロジェクトのテーブルのデータをスキャンします。
説明デフォルトでは、プロジェクト範囲にはすべてのデータ処理エンジンのすべてのプロジェクトが含まれます。
ODPS、EMR、および Hologres プロジェクトで指定されたテーブルをスキャンできます。
テーブル名の全長は
0~100文字です。すべての文字タイプがサポートされています。これを空白のままにすると、すべてのテーブルがスキャンされます。ワイルドカード文字
.*がサポートされています。たとえば、.*nameは、サフィックスがnameである名前を示します。private.*は、プレフィックスがprivateである名前を示します。複数のテーブル名またはフィールド名をコンマ (,) で区切ります。
[一部のデータ] を選択して、複数のプロジェクトまたはデータベースのスキャン範囲を追加します。最終的なスキャン範囲は、追加されたすべての範囲の和集合です。
左側のペインでプロジェクトを手動で選択します。
プロジェクトを選択すると、そのプロジェクトまたはデータベース内のデータテーブルが右側に表示されます。テーブルを手動で選択するか、一度にすべてのテーブルを選択できます。デフォルトでは、データベース内のすべてのデータテーブルが選択されます。
キーワードでプロジェクトまたはデータベースの範囲とデータテーブルを検索できます。キーワードでデータテーブルを検索するには、まず検索対象のプロジェクトを選択します。
[実行] をクリックしてスキャンタスクを開始します。
タスクが開始されると、[タスクステータス] は次のように変更されます:
リアルタイムタスク:ステータスが [実行中] に変わります。
定期タスク:ステータスが [実行中] に変わります。設定されたスキャン時間に達すると、プラットフォームは設定に基づいて機密データを検出します。
ワンタイムタスク:進捗横棒グラフが表示されます。進捗が 100% に達すると、スキャンは完了です。進捗は、数式:(現在のタスクでスキャンされたテーブル数 / 現在のタスクでスキャンする総テーブル数) × 100% を使用して計算されます。
説明検出ルールを変更した場合、新しいルールは次の定期タスクで有効になり、リアルタイムでは有効になりません。すぐに新しいタスクをトリガーするには、手動でワンタイム検出タスクを作成する必要があります。
スキャンタスクが完了すると、[タスクステータス] は [タスクなし] に更新されます。
データ検出ルールの管理
ルールのコピー:既存のルールをすばやくコピーするには、
 アイコンをクリックします。新しいルール名にはデフォルトでサフィックス
アイコンをクリックします。新しいルール名にはデフォルトでサフィックス -copyが付き、そのステータスは [下書き] です。必要に応じて設定できます。ルールの編集:ルール情報を変更するには、
 アイコンをクリックします。説明
アイコンをクリックします。説明組み込みの機密フィールドタイプに基づいて設定されたルールの基本情報は変更できません。
ルールを変更すると、以前のバージョンのルールに一致したフィールドの検出結果はクリアされます。
ルールの削除:ルールが不要になった場合は、
 アイコンをクリックして削除します。重要
アイコンをクリックして削除します。重要機密データタイプの検出ルールを削除すると、大きな影響があります。削除を確定する前に、以下の影響をよくお読みください。
この機密フィールドタイプのレコードが検出結果から削除されます。詳細については、「機密データ検出結果の表示と手動修正」をご参照ください。
この機密フィールドタイプの統計は、データディスカバリモジュールの機密データ分布情報に含まれなくなります。詳細については、「機密データの概要」をご参照ください。
不正検出ルールがこの機密フィールドタイプを参照している場合、その参照は削除されます。詳細については、「不正検出管理」をご参照ください。
ルールの一括公開:ルールが公開されると、プラットフォームはそれを使用して対応する機密データを検出します。多くのルールがある場合は、一括で公開できます。
[データ検出ルール] ページで、[一括公開] をクリックし、公開するルールを選択します。
説明[下書き] 状態のルールのみ選択できます。
[公開] をクリックします。ルールが公開されると、そのステータスは [公開済み] に変わります。
説明公開をキャンセルするには、[キャンセル] をクリックします。ルールは元の [下書き] 状態に戻ります。
ルールの一括非アクティブ化:ルールが非アクティブ化されると、プラットフォームはそれを使用して対応するタイプの機密データを検出しなくなります。この機密フィールドタイプのレコードは、データディスカバリや手動データ修正などのモジュールから削除されます。ルールを非アクティブ化する前に、それが データマスキングルールまたは 不正検出ルールによって参照されているかどうかを確認してください。参照されている場合は、まず データマスキングルールを非アクティブ化し、不正検出ルールから参照を削除する必要があります。詳細については、「データマスキングルールの作成」および「不正検出管理」をご参照ください。
[データ検出ルール] ページで、[一括非アクティブ化] をクリックし、非アクティブ化するルールを選択します。
説明[公開済み] 状態のルールのみ選択できます。
[一括非アクティブ化] をクリックします。ルールが非アクティブ化されると、そのステータスは [下書き] に変わります。
説明非アクティブ化をキャンセルするには、[キャンセル] をクリックします。ルールは元の [公開済み] 状態に戻ります。
次のステップ:タスク実行レコードの表示
ページには、過去 1 週間に完了したタスクのレコードが表示されます。このページには、現在実行中のタスクのレコードは含まれません。[開始時間]、[終了時間]、[期間]、[タスクタイプ]、[所有者]、[データ範囲] などの詳細を表示できます。