MaxCompute 上の Spark ジョブは、ローカルモード または クラスターモード のいずれかで実行できます。DataWorks 内では、オフラインジョブ を クラスターモード で実行することも可能であり、他の ノード タイプと統合できます。本トピックでは、これらの ジョブ の構成およびスケジュール設定方法について説明します。
概要
MaxCompute 上の Spark は、オープンソースの Spark と互換性のある MaxCompute が提供するコンピューティングサービスです。統一されたコンピューティングリソースおよびデータ権限システムの上に Spark コンピューティングフレームワークを提供し、データ処理および分析に際して馴染みのある開発手法を利用できます。DataWorks では、ODPS Spark ノード を使用することで、これらの ジョブ をスケジュール設定し、他のノードと統合できます。
MaxCompute 上の Spark ジョブ は、Java、Scala、Python のいずれかで開発できます。DataWorks で オフラインジョブ として実行する場合、クラスターモード で実行されます。MaxCompute 上の Spark の実行モードの詳細については、「実行モード」をご参照ください。
制限事項
Spark 3.x を使用する ODPS Spark ノード の送信が失敗した場合、サーバーレスリソースグループ を購入して使用する必要があります。詳細については、「サーバーレスリソースグループの使用」をご参照ください。
前提条件
ODPS Spark ノードは、Java/Scala または Python を使用して MaxCompute オフラインジョブで Spark を実行することをサポートしています。開発プロセスおよび構成オプションは、言語によって異なります。
Java/Scala
ODPS Spark ノード で Java または Scala コードを実行するには、まず ジョブ を開発し、パッケージ化したコードを DataWorks に MaxCompute リソース としてアップロードする必要があります。
開発環境を準備します。
お使いのオペレーティングシステムに応じて、開発環境を準備してください。詳細については、「Linux 開発環境のセットアップ」および「Windows 開発環境のセットアップ」をご参照ください。
Java/Scala コードを開発します。
ローカル環境で MaxCompute 上の Spark コードを開発します。MaxCompute 上の Spark が提供するサンプルプロジェクトテンプレートの使用を推奨します。
コードをパッケージ化し、DataWorks にアップロードします。
コードの開発が完了したら、それをパッケージ化し、DataWorks に MaxCompute
リソースとしてアップロードします。詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
Python(デフォルト環境を使用)
DataWorks では、PySpark コードを Python リソース 内に直接記述し、ODPS Spark ノード を使用して送信および実行できます。DataWorks における Python リソース の作成方法については、「MaxCompute リソースの作成と使用」をご参照ください。PySpark 開発の例については、「PySpark を使用した MaxCompute 上の Spark アプリケーションの開発」をご参照ください。
この方法では、DataWorks が提供するデフォルトの Python 環境を使用します。この環境は、サードパーティパッケージのサポートが限定されています。お使いの ジョブ で他の依存関係が必要な場合は、「Python(カスタム環境を使用)」セクションに記載されているとおり、カスタム Python 環境を準備できます。あるいは、PyODPS 2 ノード または PyODPS 3 ノード を使用することもできます。これらのノードは、Python リソース に対するより優れたサポートを提供します。
Python(カスタム環境を使用)
デフォルトの Python 環境が要件を満たさない場合、MaxCompute 上の Spark ジョブ を実行するためのカスタム環境を準備します。
ローカルの Python 環境を準備します。
適切な Python 環境の設定手順については、「
PySpark Python のバージョンと依存関係のサポート」をご参照ください。環境をパッケージ化し、DataWorks にアップロードします。
Python 環境を ZIP パッケージに圧縮し、DataWorks に MaxCompute
リソースとしてアップロードします。このパッケージは、MaxCompute 上の Sparkジョブの実行環境を提供します。詳細については、「MaxCompute リソースの作成と使用」をご参照ください。
パラメーター
DataWorks は、Cluster Mode で MaxCompute 上の Spark Offline Jobs を実行します。このモードでは、カスタムプログラムのエントリポイントとして、main を指定する必要があります。main メソッドが完了すると Spark ジョブは終了し、Success または Fail ステータスを返します。さらに、spark-defaults.conf の構成を、ODPS Spark ノードの 構成アイテムセクションに 1 つずつ追加する必要があります。例として、エグゼキュータ インスタンスの数、メモリ、spark.hadoop.odps.runtime.end.point 構成などが挙げられます。
spark-defaults.conf ファイルをアップロードしないでください。代わりに、各設定を ODPS Spark ノード の個別の 設定項目 として追加してください。
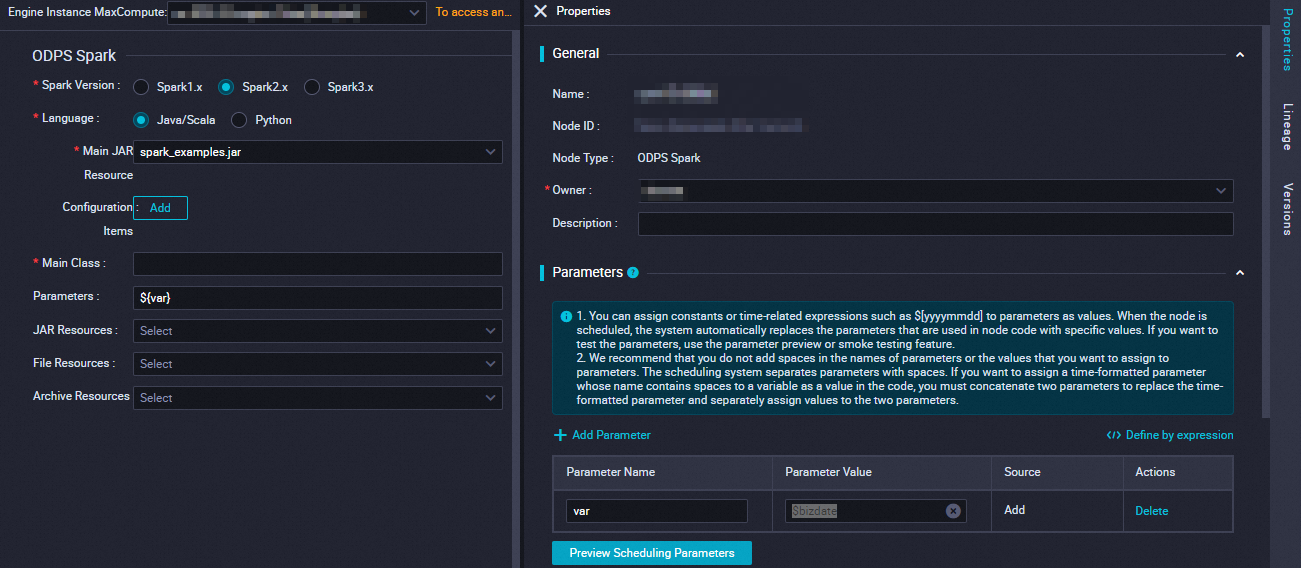
パラメーター | 説明 | spark-submit コマンド |
Spark バージョン | 利用可能なバージョンには、Spark 1.x、Spark 2.x、および Spark 3.x があります。 説明 Spark 3.x を使用する ODPS Spark | — |
言語 | MaxCompute 上の Spark | — |
メインリソースの選択 |
まず、 |
|
設定項目 |
|
|
メインクラス |
|
|
引数 | 必要に応じて、スペースで区切って引数を追加できます。DataWorks ではスケジュール設定パラメーターをサポートしています。引数 の形式は ${変数名} です。構成後に、右側ペインの セクションで、変数に値を割り当てます。 説明 スケジュール設定パラメーターへの値の割り当てにサポートされる形式については、「スケジュール設定パラメーターのサポート形式」をご参照ください。 |
|
その他のリソースの選択 | 必要に応じて、以下の
まず、 | 異なる
|
簡単な例
本セクションでは、ODPS Spark ノード を使用した簡単な例(文字列が数値かどうかを確認する)を紹介します。
リソースを作成します。
データ開発 ページで、新しい Python
リソースを作成し、名前を spark_is_number.py とします。詳細については、「MaxCompute リソースの作成と使用」をご参照ください。# -*- coding: utf-8 -*- import sys from pyspark.sql import SparkSession try: # for python 2 reload(sys) sys.setdefaultencoding('utf8') except: # python 3 not needed pass if __name__ == '__main__': spark = SparkSession.builder\ .appName("spark sql")\ .config("spark.sql.broadcastTimeout", 20 * 60)\ .config("spark.sql.crossJoin.enabled", True)\ .config("odps.exec.dynamic.partition.mode", "nonstrict")\ .config("spark.sql.catalogImplementation", "odps")\ .getOrCreate() def is_number(s): try: float(s) return True except ValueError: pass try: import unicodedata unicodedata.numeric(s) return True except (TypeError, ValueError): pass return False print(is_number('foo')) print(is_number('1')) print(is_number('1.3')) print(is_number('-1.37')) print(is_number('1e3'))リソースを保存およびコミットします。
作成した ODPS Spark
ノードで、パラメーター に記載されている通り、ノードのパラメーターおよびスケジュール設定パラメーターを構成し、ノードを保存およびコミットします。パラメーター
説明
Spark バージョン
Spark 2.x
言語
Python
メイン Python リソースの選択
ドロップダウンリストから、作成した Python
リソース(spark_is_number.py)を選択します。開発環境の
オペレーションセンターに移動し、データバックフィルジョブを実行します。詳細な手順については、「データバックフィルインスタンスの運用管理」をご参照ください。説明ODPS Spark
ノードはデータ開発で直接実行できないため、開発環境のオペレーションセンターからジョブを実行する必要があります。結果を確認します。
データバックフィルインスタンスの実行が成功した後、実行ログ内の トラッキング URL にアクセスして結果を確認します:False True True True True
高度な例
さまざまなユースケース向けに MaxCompute 上の Spark ジョブ を開発するためのその他の例については、以下のトピックをご参照ください:
次のステップ
ジョブ の開発が完了したら、以下の操作を実行できます。
スケジュール設定:ノードのスケジュール設定プロパティを構成します。タスクを定期的に実行する必要がある場合は、再実行設定やスケジュール依存関係などのプロパティを構成する必要があります。詳細については、「タスクのスケジュール設定プロパティの概要」をご参照ください。
タスクのデバッグ:現在のノードのコードをテストおよび実行し、コードのロジックが正しいことを検証します。詳細については、「タスクのデバッグプロセス」をご参照ください。
タスクのデプロイメント:すべての開発関連の操作が完了したら、すべてのノードをデプロイする必要があります。デプロイ後、ノードはスケジュール設定に従って定期的に実行されます。詳細については、「タスクのデプロイメント」をご参照ください。
Spark ジョブの診断:MaxCompute では、Logview ツールおよび Spark Web UI を使用して Spark
ジョブを診断できます。実行ログを確認することで、正しく送信および実行されていることを検証できます。