ノードに同一サイクルスケジューリング依存関係が設定されている場合、現在のサイクルでノードに対して生成されたインスタンスは、同じスケジューリングサイクルで別のノードに対して生成されたインスタンスのデータに依存します。現在のノードは、別のノードに対して生成されたインスタンスが正常に実行された後にのみ、期待どおりに実行できます。現在のノードが、同じスケジューリングサイクルで別のノードによって生成されたテーブル内のデータに依存する必要がある場合、現在のノードに同一サイクルスケジューリング依存関係を設定できます。DataWorks では、さまざまなメソッドを使用して同一サイクルスケジューリング依存関係を設定でき、依存関係プレビュー機能を提供しています。ノードが期待どおりにスケジューリングされるように、不正なスケジューリング依存関係をできるだけ早い機会に表示して調整できます。このトピックでは、同一サイクルスケジューリング依存関係を設定するための注意事項、ロジック、およびメソッドについて説明します。
注意事項
スケジューリング依存関係の構成をスムーズに行うには、「スケジューリング依存関係設定ガイド」で説明されている情報を理解する必要があります。
ノードの有向非巡回グラフ (DAG) では、ノードの同一サイクルスケジューリング依存関係は実線で表されます。
特定の複雑なシナリオでノード間の同一サイクルスケジューリング依存関係が要件を満たせない場合は、ノード間にサイクルをまたいだスケジューリング依存関係を設定できます。例えば、日次でスケジューリングされるノードが時間単位でスケジューリングされるノードに依存する場合、日次でスケジューリングされるノードに対して生成されたインスタンスは、デフォルトで、当日に時間単位でスケジューリングされるノードに対して生成されたすべてのインスタンスに依存します。時間単位でスケジューリングされるノードに自己依存を設定すると、日次でスケジューリングされるノードが、特定のスケジューリングサイクルで時間単位でスケジューリングされるノードに対して生成されたインスタンスに依存するように指定できます。詳細については、「複雑な依存関係シナリオにおけるスケジューリング設定の原則とサンプル」をご参照ください。
予期しないスケジューリング依存関係による本番環境でのノードのスケジューリングの遅延を防ぐために、ノードをデプロイする前に、プレビュー機能を使用して、ノードに対して生成されたインスタンスのスケジューリング依存関係が期待どおりであるかどうかを確認することをお勧めします。詳細については、「ノードのスケジューリング依存関係をプレビューする」をご参照ください。
設定の原則
ノード開発の効率を向上させるために、自動解析機能を使用して、ノードのスケジューリング依存関係を迅速に設定することをお勧めします。開発プロセス中は、以下の原則に従う必要があります。
ノードの作成: ノードの出力テーブルの名前と同じノード名を指定することをお勧めします。
コード開発: 複数のノードを使用して同じテーブルにデータを書き込まないでください。
依存関係の設定: ノードによって生成されたテーブルをノードの出力として使用することをお勧めします。
設定のエントリポイントと説明
DataStudio で作成したノードの設定タブに移動し、右側のナビゲーションウィンドウで [プロパティ] タブをクリックして、[プロパティ] タブの [依存関係] セクションでノードのスケジューリング依存関係を設定できます。
ノードの同一サイクルスケジューリング依存関係を設定する場合、[親ノード] セクションで現在のノードが依存する必要があるノードを指定し、[現在のノードの出力名] セクションで現在のノードの出力に基づいて現在のノードに依存する必要がある他のノードを指定する必要があります。
デフォルトでは、ノードコード内でデータを読み取るテーブルとデータを書き込むテーブル間のリネージに基づいて、ノードのスケジューリング依存関係を設定できます。ノードをコミットすると、DataWorks はスケジューリング依存関係が期待どおりに設定されているかどうかを確認します。詳細については、「テーブルのリネージを確認する」をご参照ください。ビジネス要件に基づいて、目的のノードをコミットする前にコードの自動解析を実行するかどうかを指定できます。詳細については、「スケジューリング設定を行う」をご参照ください。
DataWorks は、ノードのコード内のリネージに基づく設定、ワークフローの設定タブでの線の描画による設定、手動設定など、複数の設定方法をサポートしています。ビジネス要件に基づいて設定方法を選択できます。詳細については、このトピックの「設定方法」セクションをご参照ください。
現在のサイクルでノードに対して生成されたインスタンスが、前日の別のノードに対して生成されたインスタンスのデータに依存する必要がある場合、または現在のサイクルで時間単位または分単位でスケジューリングされるノードに対して生成されたインスタンスが、前のサイクルで同じノードに対して生成されたインスタンスに依存する必要がある場合は、サイクルをまたいだスケジューリング依存関係を設定できます。詳細については、「サイクルをまたいだスケジューリング依存関係を設定する」をご参照ください。
スケジューリング依存関係の設定プロセスにおけるよくある質問、および異なるワークスペースまたはワークフローに属するノード間のスケジューリング依存関係の設定に関するベストプラクティスについては、「付録 1: よくある質問」および「付録 2: ベストプラクティス」をご参照ください。

先祖ノード
現在のノードが依存するノードを指定できます。ノードが指定されると、現在のノードは先祖ノードが正常に実行された後にのみ実行を開始できます。先祖ノードの出力を現在のノードの入力として入力する必要があります。現在のノードが依存するノードを指定する際には、次の項目に注意してください。
すべてのノードに先祖ノードを設定する必要があります。テーブルリネージに基づいてノードの先祖ノードを設定することをお勧めします。テーブルリネージが存在しない場合は、ビジネス要件に基づいて、ワークスペースのルートノードまたはゼロロードノードを現在のノードの先祖ノードとして選択できます。詳細については、「スケジューリング依存関係設定ガイド」をご参照ください。
先祖ノードがコミットされていることを確認してください。現在のノードをコミットするときに、先祖ノードの出力が存在しないことを示すエラーが報告された場合は、先祖ノードがコミットされているかどうかを確認してください。
次の図は、現在のノードの先祖ノードを指定するために使用できるすべてのメソッドを示しています。 自動推奨メソッドを使用して現在のノードが依存するノードを指定する場合、推奨されるノードがコミットされて本番環境にデプロイされ、目的のテーブルが生成されることを確認してください。推奨されるノードは、前日にスケジューリングシステムにコミットする必要があります。これにより、当日にデータが生成された後、自動推奨機能によってノードを識別できます。したがって、自動的に推奨されるノードは 1 日遅れで更新されます。
自動推奨メソッドを使用して現在のノードが依存するノードを指定する場合、推奨されるノードがコミットされて本番環境にデプロイされ、目的のテーブルが生成されることを確認してください。推奨されるノードは、前日にスケジューリングシステムにコミットする必要があります。これにより、当日にデータが生成された後、自動推奨機能によってノードを識別できます。したがって、自動的に推奨されるノードは 1 日遅れで更新されます。
自動推奨は ODPS SQL ノードでのみ利用可能です。
現在のノードの出力
現在のノードと他のノードとの間にスケジューリング依存関係を確立するために、ノードの出力を設定できます。他のノードは、現在のノードの出力名を検索して現在のノードを見つけ、スケジューリング依存関係の設定に基づいて現在のノードがノードの先祖ノードとして指定されます。現在のノードが子孫ノードの先祖ノードとして設定されている場合、子孫ノードがコミットされた後、現在のノードの出力名には子孫ノードの名前が含まれます。DataWorks では、現在のノードの [現在のノードの出力名] セクションで子孫ノードを手動で変更することはできません。次の図は、現在のノードの出力を指定するすべてのメソッドを示しています。
DataWorks では、ノードに対して生成される出力の名前はノードの名前と同じです。ワークスペースに同じ名前のノードが含まれている場合、出力名が重複しているためにノードがコミットに失敗することがあります。子孫ノードを持つノードの出力を削除すると、深刻な影響が及ぶ可能性があります。詳細については、「付録 3: ノードの出力の削除または変更による影響」をご参照ください。

設定ロジック
ノード間のスケジューリング依存関係を設定するには、あるノードの出力を別のノードの入力として使用します。これにより、ノード間にスケジューリング依存関係が形成されます。データを読み取るテーブルとデータを書き込むテーブル間のリネージに基づいて、ノード間のスケジューリング依存関係を設定することをお勧めします。スケジューリング依存関係が設定されると、子孫ノードは先祖ノードが正常に実行された後にのみ実行を開始できます。スケジューリング依存関係は、ノードがその実行に必要なデータを先祖ノードから取得できるようにするのに役立ちます。テーブルリネージの確認方法の詳細については、「テーブルのリネージを確認する」をご参照ください。
次の表で説明するメソッドを使用して、ノード間のスケジューリング依存関係を設定できます。3 つのメソッドの設定ロジックは同じです。
設定方法 | 説明 |
DataWorks は、名前が _out で終わる先祖ノードの出力を子孫ノードの入力として自動的に追加します。 | |
自動解析機能に基づいてノード間のスケジューリング依存関係を設定できます。この機能は、ノードコードに基づいてテーブルリネージを自動的に解析し、ノード間のスケジューリング依存関係を迅速に設定できます。 | |
ほとんどの場合、自動解析機能を使用して取得したスケジューリング依存関係がビジネス要件を満たさない場合に、このメソッドを使用してノードのスケジューリング依存関係を変更できます。 |
設定方法
ワークフローの設定タブで線を描画してノードを接続し、ノード間のスケジューリング依存関係を確立する
ワークフローの設定タブで線を描画してノードを接続することでノード間のスケジューリング依存関係を設定する場合、DataWorks は、名前が _out で終わる先祖ノードの出力を子孫ノードの入力として自動的に追加します。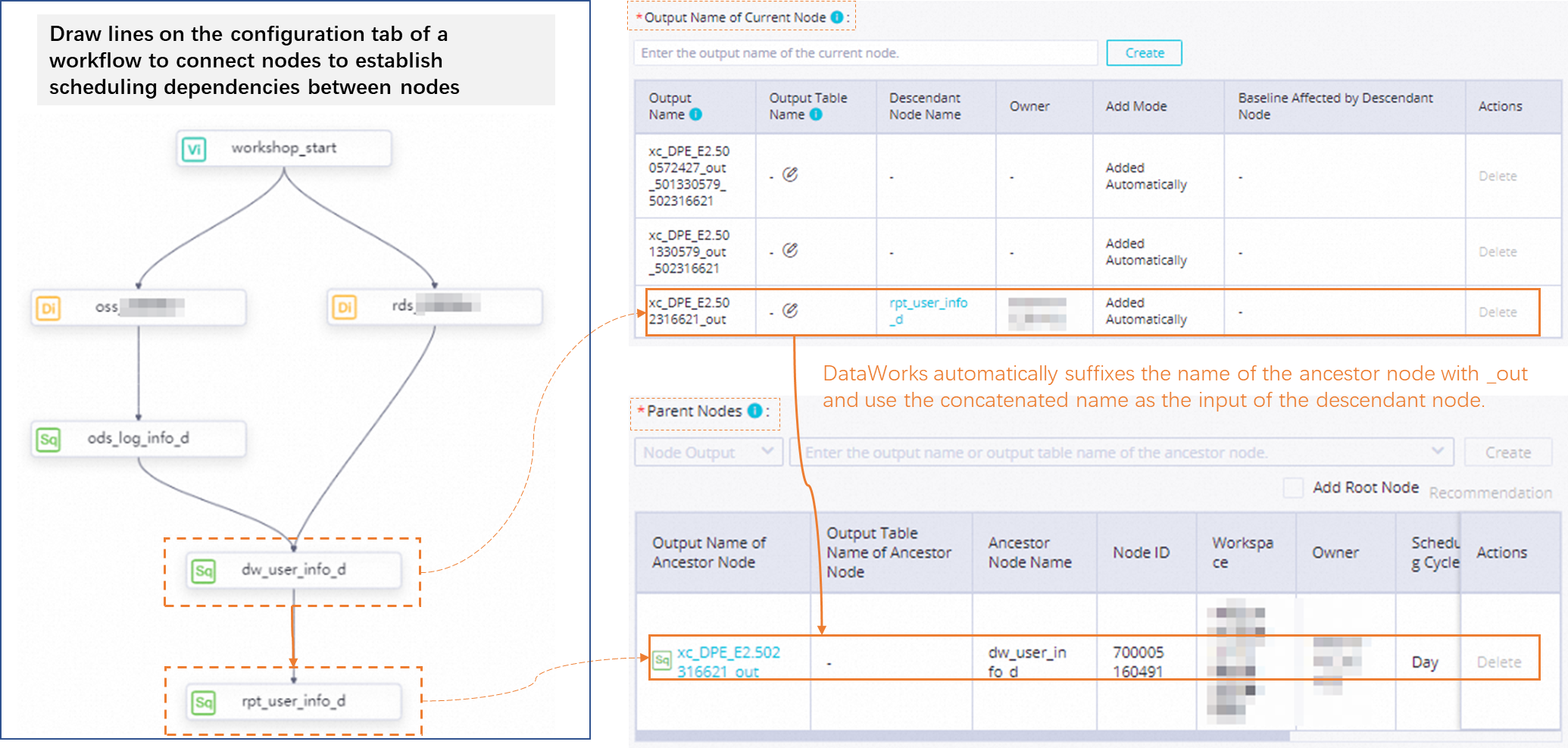
スケジューリング依存関係の接続線がワークフローの設定タブから削除されると、スケジューリング依存関係もノードのスケジューリング設定から削除されます。
[依存関係] セクションでノードの先祖ノードを手動で追加する
[親ノード] セクションで、ノードの出力を入力して、そのノードを現在のノードの先祖ノードとして追加できます。出力名は projectname.tablename 形式です。
自動解析機能を使用して、テーブルリネージに基づいてノード間のスケジューリング依存関係を設定する
DataWorks では、ノードコード内のテーブルリネージを使用して、ノード間のスケジューリング依存関係を迅速に設定できます。自動解析機能を有効にすると、システムはノードによって生成されたテーブルを projectname.tablename 形式で命名し、そのテーブルをノードの出力として使用します。システムはまた、ノードがクエリするテーブルをノードの入力として追加します。たとえば、ノードのコードの SELECT 文でテーブルが指定されている場合、システムは自動解析機能に基づいてそのテーブルをノードの親ノードに追加します。ノードのコードの INSERT 文でテーブルが指定されている場合、システムは自動解析機能に基づいてそのテーブルをノードの出力に追加します。自動解析機能がさまざまなタイプのノードでサポートするキーワードの詳細については、「自動解析機能のサポート」をご参照ください。
自動解析機能に基づくノード間のスケジューリング依存関係の設定の詳細:
自動解析機能に基づくノード間のスケジューリング依存関係の設定
次の図は、自動解析機能に基づいてノード間のスケジューリング依存関係がどのように設定されるかを示しています。

自動解析機能に基づいて取得されたスケジューリング依存関係の変更
自動解析機能に基づいてノード間に設定されたスケジューリング依存関係が期待どおりでない場合、またはスケジューリング依存関係の設定がサポートされていない (データが定期的なスケジューリングに基づいて生成されないテーブル) 場合は、次の表を参照して、自動解析機能に基づいて取得されたスケジューリング依存関係を変更できます。
シナリオとメソッド
説明
操作と結果の例
自動解析機能が有効な場合に、コードを使用してノードの入力と出力を削除します。
ノードのコードでコマンドを実行してノードの入力と出力を削除または追加し、ノードの入力と出力を再度解析します。
ノードの入力と出力が削除または追加されると、自動解析結果にコメントが自動的に追加されます。
--@exclude_input=ノードの入力を削除
--@exclude_output=ノードの出力を削除
--@extra_output=ノードの出力を追加
--@extra_input=ノードの入力を追加

自動解析機能が無効な場合に、自動解析機能に基づいて取得されたノードの入力と出力を変更します。
DataWorks では、子孫ノードを持つノードの出力を削除することはできません。ノードの出力を削除すると、子孫ノードの実行時にエラーが発生したり、子孫ノードがデータを取得できなくなったりします。
この場合、下流のビジネスロジックを調整することをお勧めします。ノードの出力を削除する前に、子孫ノードの現在の先祖ノードへの依存関係を削除できます。

自動解析機能をサポートしていないノード
DataWorks の一時テーブルは、[テーブル管理] タブで定義され、
t_などのプレフィックスが付いたテーブルのように固定形式であり、自動解析機能に基づいて現在のノードの出力または入力として使用されません。自動解析機能を使用する際の注意事項
自動解析機能を使用してスケジューリング依存関係を設定する場合、ノードの出力名が現在のリージョンで一意であることを確認する必要があります。DataWorks でのノード開発で自動解析機能を使用する場合は、次の項目に注意してください。
ノードの作成: DataWorks では、ノードに対して生成される出力の名前はノードの名前と同じです。ワークスペースに同じ名前のノードが含まれている場合は、いずれかのノードの出力名を手動で変更する必要があります。
コード開発: 自動解析機能は、ノードによって生成されたテーブルをノードの出力として使用します。ワークスペースで、2 つのノードが同じテーブルにデータを書き込むために使用される場合、自動解析シナリオでいずれかのノードでエラーが報告されることがあります。詳細については、「複数のノードが同じ出力名を持つことはできますか?」をご参照ください。
依存関係の設定: SQL ノードを使用してバッチ同期ノードによって生成されたテーブルを処理するシナリオでは、自動解析機能を使用して、リネージに基づいてバッチ同期ノードのスケジューリング依存関係を設定できます。バッチ同期ノードの出力テーブルをノードの出力として手動で設定するか、バッチ同期ノードの出力テーブルの名前をバッチ同期ノードの名前として使用する必要があります。そうしないと、バッチ同期ノードに依存する SQL ノードをコミットするときに、次のエラーが報告されることがあります: 先祖ノードの ${projectname.tablename} 形式の名前の出力が存在しません。現在のノードはコミットできません。出力名が ${projectname.tablename} 形式の先祖ノードがコミットされていることを確認してください。DataWorks では、ノードに対して生成される出力の名前はノードの名前と同じです。
次のステップ: スケジューリング依存関係が期待どおりか確認する
スケジューリング依存関係が設定された後、次の操作を実行して、ノードが期待どおりにスケジューリングされることを確認できます。
スケジューリング依存関係のプレビュー: 予期しないスケジューリング依存関係による本番環境でのノードのスケジューリングの遅延を防ぎます。
ノードのコミット: ノードをコミットするときに、ノード間のスケジューリング依存関係の変更が期待どおりであるかどうかを確認します。
オペレーションセンターでのノード間のスケジューリング依存関係の確認: ノードをデプロイした後、本番環境の自動トリガーノード間のスケジューリング依存関係がオペレーションセンターで期待どおりであるかどうかを確認します。本番環境の自動トリガーノードは、最新の状態のノードです。ノードに対して生成されたインスタンス間のスケジューリング依存関係は、[インスタンス生成モード] パラメーターに関連しています。
詳細については、「スケジューリング依存関係の確認」をご参照ください。
付録 1: よくある質問
その他のよくある質問については、「スケジューリング依存関係」をご参照ください。
付録 2: ベストプラクティス
異なるワークスペースに属するノード間、または同じワークスペース内の異なるワークフローに属するノード間のスケジューリング依存関係を設定する方法については、「シナリオ 3: ワークフローまたはワークスペースをまたがるノードの依存関係を設定する」をご参照ください。
付録 3: ノードの出力の削除または変更による影響
ノードによって生成されたテーブルを変更すると、それに応じてノードの出力も変更されます。ノードの出力を直接変更することもできます。ノードの出力を削除または変更する際には、次の項目に注意してください。
ノードの出力を削除しても、ノードによって生成されたテーブルには影響しません。
子孫ノードを持つノードの出力を削除または変更すると、子孫ノードに深刻な影響が及ぶ可能性があります。
ノードによって生成されたテーブルの削除: ノードによって生成されたテーブルが削除されると、ノードの子孫ノードが孤立ノードになり、スケジューリングできなくなったり、子孫ノードのスケジューリング依存関係が失われるために下流のデータが影響を受けたりする可能性があります。
ノードによって生成されたテーブルの変更: ノードによって生成されたテーブルを他のノードに転送できます。詳細については、「ノードの出力の削除または変更による影響」をご参照ください。
子孫ノードを持つノードの出力を削除する場合は、事前に子孫ノードのオーナーに削除を通知し、子孫ノードが孤立ノードになるのを防ぐために、できるだけ早く子孫ノードのスケジューリング依存関係を調整するように依頼することをお勧めします。