データベース全体のリアルタイム同期は、完全移行と増分キャプチャを組み合わせ、ソースデータベース (MySQL や Oracle など) からターゲットシステムへ低レイテンシーでデータを同期します。このタスクは、履歴データ全体の同期をサポートし、ターゲットのスキーマとデータを自動的に初期化します。その後、シームレスにリアルタイム増分モードに切り替わり、CDC などの技術を使用してデータの変更をキャプチャし、同期します。この機能は、リアルタイムデータウェアハウジングやデータレイク構築などのシナリオに適しています。このトピックでは、MySQL データベースから MaxCompute へリアルタイムで同期する例を用いて、タスクの設定方法を説明します。
前提条件
データソースの準備
ソースとターゲットのデータソースを作成します。設定の詳細については、「データソース管理」をご参照ください。
データソースがデータベース全体のリアルタイム同期をサポートしていることを確認します。「サポートされるデータソースタイプと同期操作」をご参照ください。
Hologres や Oracle などの特定のデータソースのログを有効にします。方法はデータソースによって異なります。詳細については、データソースの設定:「データソースリスト」をご参照ください。
リソースグループ:Serverless リソースグループを購入し、設定します。
ネットワーク接続性:リソースグループとデータソース間のネットワーク接続設定が確立されていることを確認します。
エントリポイント
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ統合へ移動] をクリックします。
制限事項
DataWorks は、データベース全体のリアルタイム同期とデータベース全体の完全+増分 (ニアリアルタイム) 同期の 2 つのモードをサポートしています。どちらのモードも既存データを同期し、自動的にリアルタイム増分モードに切り替わります。ただし、レイテンシーとターゲットテーブルの要件が異なります:
レイテンシー:データベース全体のリアルタイム同期は、秒から分単位のレイテンシーを提供します。データベース全体の完全+増分 (ニアリアルタイム) 同期は、T+1 のレイテンシーを提供します。
ターゲットテーブル (MaxCompute):データベース全体のリアルタイム同期は、Delta Table テーブルタイプのみをサポートします。データベース全体の完全+増分 (ニアリアルタイム) 同期は、すべてのタイプをサポートします。
タスクの設定
ステップ 1:同期タスクの作成
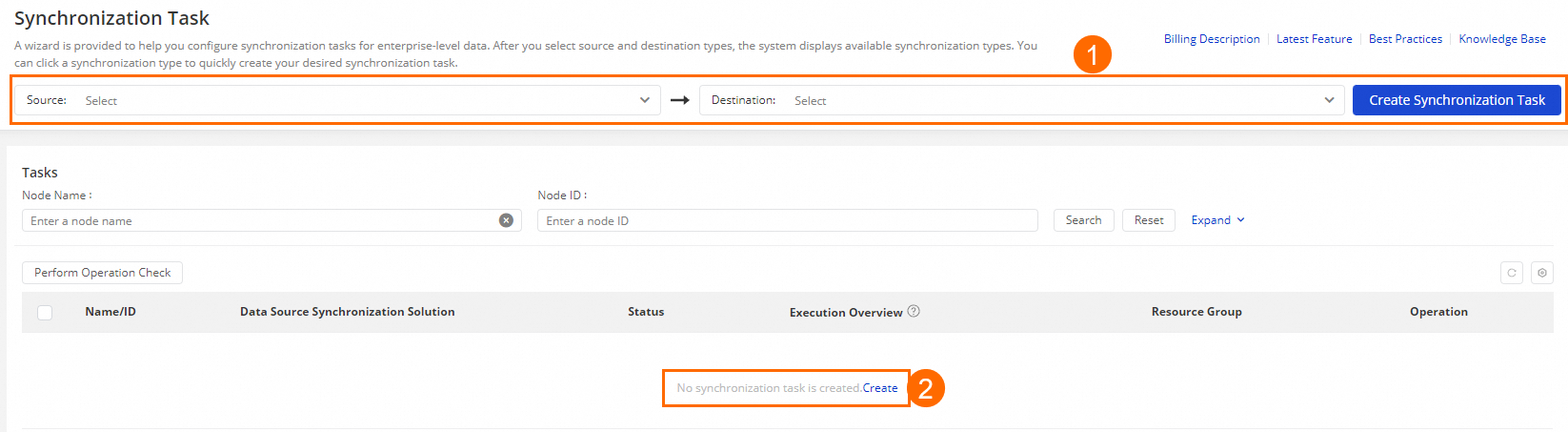
以下のいずれかの方法で同期タスクを作成します:
方法 1:[同期タスク] ページで、[ソース] と [ターゲット] を選択し、Create Synchronization Task をクリックします。この例では、ソースとして MySQL を、ターゲットとして MaxCompute を選択します。
方法 2:[同期タスク] ページで、タスクリストが空の場合は Create をクリックします。
ステップ 2:基本情報の設定
タスク名、タスクの説明、オーナーなどの基本情報を設定します。
同期タイプを選択します:DataWorks は、ソースとターゲットのデータベースタイプに基づいて、サポートされている Task Type を表示します。この例では、[データベース全体のリアルタイム移行] を選択します。
同期ステップ:
[構造移行]:ソースに一致するターゲットデータベースオブジェクト (テーブル、フィールド、データ型) を自動的に作成します。データは転送されません。
[完全初期化] (オプション):指定されたソースオブジェクト (テーブルなど) の既存データをターゲットに複製します。これは通常、初期データ移行または初期化に使用されます。
[増分同期] (オプション):完全同期の完了後、ソースからの変更データ (挿入、更新、削除) を継続的にキャプチャし、ターゲットに同期します。
ステップ 3:ネットワークとリソースの設定
[ネットワークおよびリソース設定] セクションで、同期タスクで使用する Resource Group を選択します。タスクに [タスクリソース使用量] (CU) を割り当てることができます。
追加した
MySQLデータソースを[ソース]に、追加したMaxComputeデータソースを[宛先]に選択し、[接続テスト]をクリックします。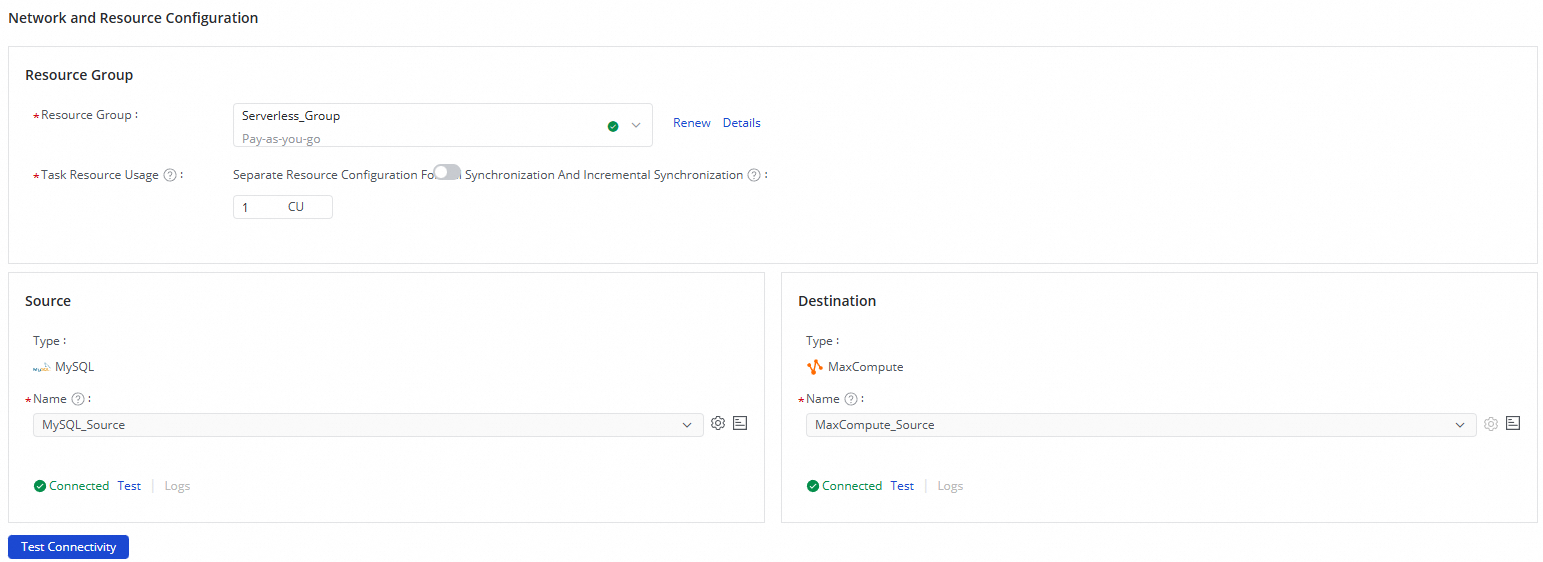
両方のデータソースの接続テストが成功したことを確認し、[次へ] をクリックします。
ステップ 4:同期するテーブルの選択
[ソーステーブル] エリアで、ソースデータソースから同期するテーブルを選択します。![]() アイコンをクリックして、テーブルを [選択されたテーブル] リストに移動します。
アイコンをクリックして、テーブルを [選択されたテーブル] リストに移動します。

テーブル数が多い場合は、[データベースフィルタリング] または [テーブルの検索] を使用して、正規表現でテーブルを選択します。
ステップ 5:ターゲットテーブルのマッピング
ソーステーブルとターゲットテーブル間のマッピングルールを定義し、プライマリキー、動的パーティション、DDL/DML 処理などのオプションを設定して、データの書き込み方法を決定します。
パラメーター | 説明 | ||||||||||||
マッピング結果の更新 | システムは選択されたソーステーブルをリスト表示します。ただし、ターゲットの属性は、マッピングを更新して確認した後にのみ有効になります。
| ||||||||||||
宛先テーブル名のマッピングルールのカスタマイズ (任意) | システムは、デフォルトのルールを使用してテーブル名を生成します:
サポートされているシナリオ:
| ||||||||||||
[フィールドデータ型のマッピングを編集] (オプション) | システムは、ソースとターゲットのフィールドタイプ間のデフォルトマッピングを提供します。テーブルの右上隅にある [フィールドデータ型のマッピングを編集] をクリックしてマッピング関係をカスタマイズし、[適用してマッピングを更新] をクリックします。 注意:フィールドタイプの変換ルールが正しくないと、変換の失敗、データ破損、またはタスクの中断を引き起こす可能性があります。 | ||||||||||||
[ターゲットテーブル構造の編集] (オプション) | システムは、カスタムのテーブル名マッピングルールに基づいて、存在しないターゲットテーブルを自動的に作成するか、同じ名前の既存のテーブルを再利用します。 DataWorks はソーススキーマに基づいてターゲットスキーマを生成します。通常、手動での介入は不要です。以下の方法でテーブルスキーマを変更することもできます:
既存のテーブルの場合、フィールドの追加のみが可能です。新しいテーブルの場合、フィールド、パーティションフィールドの追加、およびテーブルタイプやプロパティの設定ができます。詳細については、インターフェイスの編集可能なエリアをご参照ください。 | ||||||||||||
値の割り当て | ネイティブフィールドは、ソーステーブルとターゲットテーブルの同じ名前のフィールドに基づいて自動的にマッピングされます。追加フィールドとパーティションフィールドには手動で値を割り当てる必要があります。手順は次のとおりです:
定数または変数を割り当て、[割り当て方法] でタイプを切り替えます。サポートされている方法は次のとおりです。
説明 注意:パーティションが多すぎると、同期効率が低下します。1 日に 1,000 を超えるパーティションを作成すると、障害が発生してタスクが終了します。割り当てを定義する際には、生成されるパーティションを推定してください。秒レベルまたはミリ秒レベルのパーティション作成方法は、注意して使用してください。 | ||||||||||||
ソース分割列 | ドロップダウンリストからソーステーブルのフィールドを選択するか、[分割しない] を選択できます。同期タスクが実行されると、このフィールドに基づいて複数のタスクに分割され、データの同時並行およびバッチ読み取りが可能になります。 テーブルのプライマリキーをソース分割キーとして使用することを推奨します。文字列、浮動小数点、日付などのタイプはサポートされていません。 現在、ソース分割キーはソースが MySQL の場合にのみサポートされています。 | ||||||||||||
完全同期の実行 | ステップ 3 で完全同期が設定されている場合、特定のテーブルの完全データ同期を個別にキャンセルできます。これは、完全データがすでに他の手段でターゲットに同期されているシナリオに適用されます。 | ||||||||||||
すべての条件 | 完全フェーズ中にソースデータをフィルタリングします。ここでは WHERE キーワードなしで where 句を記述するだけです。 | ||||||||||||
DML ルールの設定 | DML メッセージ処理により、キャプチャされたデータ変更 ( | ||||||||||||
その他 |
Delta Table の詳細については、「Delta Table」をご参照ください。 |
 ボタンをクリックし、[手動入力] または [組み込み変数] を選択して連結することで、ターゲットテーブル名を生成します。サポートされている変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。
ボタンをクリックし、[手動入力] または [組み込み変数] を選択して連結することで、ターゲットテーブル名を生成します。サポートされている変数には、ソースデータソース名、ソースデータベース名、ソーステーブル名が含まれます。





 ボタンをクリックして、フィールドを追加します。
ボタンをクリックして、フィールドを追加します。 ツールチップで確認できます。
ツールチップで確認できます。ステップ 6:DDL 機能の設定
特定のリアルタイム同期タスクは、ソーステーブル構造のメタデータ変更を検出し、更新を同期するか、アラート、無視、または実行終了などの他のアクションを実行します。
インターフェイスの右上隅にある [DDL 機能の設定] をクリックして、各変更タイプの処理ポリシーを設定します。サポートされているポリシーはチャネルによって異なります。
通常処理:ターゲットはソースからの DDL 変更情報を処理します。
無視:変更メッセージは無視され、ターゲットでは変更は行われません。
エラー:データベース全体のリアルタイム同期タスクは終了し、ステータスは [エラー] に設定されます。
アラート:ソースでこのような変更が発生した場合、ユーザーにアラートが送信されます。Configure Alert Rule で DDL 通知ルールを設定する必要があります。
DDL 同期によってソース列がターゲットに追加された場合、既存のレコードには新しい列のデータはバックフィルされません。
ステップ 7:その他の設定
アラーム設定
1. アラームの追加

(1) Create Rule をクリックしてアラームルールを設定します。
Alert Reason を設定して、Business delay、[フェイルオーバー]、Task status、DDL Notification、Task Resource Utilization などのタスクのメトリックを監視します。指定されたしきい値に基づいて、CRITICAL または WARNING のアラームレベルを設定できます。
Configure Advanced Parameters を設定することで、アラート疲れやメッセージのバックログを防ぐために、アラームメッセージの送信間隔を制御できます。
アラート理由として Business delay、Task status、または Task Resource Utilization を選択した場合、タスクが正常に戻ったときに受信者に通知する回復通知を有効にすることもできます。
(2) アラームルールの管理。
作成されたアラームルールについては、アラームスイッチを使用してアラームルールが有効かどうかを制御できます。アラームレベルに基づいて、特定の受信者にアラームを送信します。
2. アラームの表示
タスクリストの を展開してアラームイベントページに入り、発生したアラーム情報を表示します。
リソースグループの設定
インターフェイスの右上隅にある [リソースグループの設定] パネルで、タスクが使用するリソースグループとその設定を管理できます。
1. リソースグループの表示と切り替え
[リソースグループの設定] をクリックして、現在タスクにバインドされているリソースグループを表示します。
リソースグループを変更するには、ここで別の利用可能なリソースグループに切り替えます。
2. リソースの調整と「リソース不足」エラーのトラブルシューティング
タスクログに
Please confirm whether there are enough resources...のようなメッセージが表示された場合、現在のリソースグループの利用可能なコンピューティングユニット (CU) がタスクの開始または実行に不足しています。[リソースグループの設定] パネルでタスクが占有する CU 数を増やして、より多くのコンピューティングリソースを割り当てることができます。
推奨されるリソース設定については、「データ統合の推奨 CU」をご参照ください。実際状況に基づいて設定を調整してください。
詳細パラメーター設定
カスタムの同期要件がある場合は、[詳細設定] 列の [設定] をクリックして詳細パラメーターを変更します。
インターフェイスの右上隅にある [詳細設定] をクリックして、詳細パラメーター設定ページに入ります。
プロンプトに従ってパラメーター値を変更します。各パラメーターの意味はパラメーター名の後に説明されています。
タスクの遅延、他のタスクをブロックする過剰なリソース消費、またはデータ損失などの問題を避けるため、変更前にパラメーターを十分に理解してください。
ステップ 8:同期タスクの実行
設定が完了したら、[保存] または Complete をクリックしてタスクを保存します。
で、作成した同期タスクを見つけ、Operation 列の Deploy をクリックします。表示されるダイアログボックスで [デプロイ後すぐに開始] を選択し、[確認] をクリックすると、タスクはすぐに実行されます。そうでない場合は、手動でタスクを開始する必要があります。
説明Data Integration タスクは、実行する前に本番環境にデプロイする必要があります。したがって、変更を有効にするには、新しいタスクまたは変更されたタスクをデプロイする必要があります。
Tasks のタスクの Name/ID をクリックして、実行の詳細を表示します。
タスクの編集
ページで、作成した同期タスクを見つけ、Operation 列の More をクリックし、次に Edit をクリックします。タスク設定の手順に従ってタスク情報を変更します。
未実行のタスクについては、設定を変更、保存、公開します。
[実行中] 状態のタスクについて、タスクの編集とデプロイ時に [デプロイ後すぐに開始] を選択しなかった場合、元の操作ボタンは [更新を適用] になります。これをクリックして変更をオンラインで適用します。
[更新を適用] をクリックすると、変更に対して「停止、公開、再起動」のシーケンスがトリガーされます。
変更がテーブルの追加または既存テーブルの切り替えを含む場合:
更新を適用する際にチェックポイントを選択することはできません。[確認] をクリックすると、新しいテーブルに対してスキーマ移行と完全初期化が実行されます。完全初期化が完了した後、他の元のテーブルとともに増分操作が開始されます。
その他の情報が変更された場合:
更新を適用する際にチェックポイントの選択がサポートされます。[確認] をクリックすると、タスクは指定されたチェックポイントから実行を継続します。指定されていない場合は、最後の停止時間のチェックポイントから実行を開始します。
変更されていないテーブルは影響を受けず、更新再起動後に最後の停止時点から実行を継続します。
タスクの表示
同期タスクを作成した後、[同期タスク] ページで作成された同期タスクのリストとその基本情報を表示できます。

[操作] 列で同期タスクを Start または [停止] できます。[その他] では、編集や View などの操作を実行できます。
開始されたタスクについては、Execution Overview で基本的な実行ステータスを表示するか、対応する概要エリアをクリックして実行の詳細を表示できます。

ブレークポイントからの再開
適用シナリオ
以下のシナリオで、起動または再起動中にチェックポイントをリセットします:
タスクの回復:エラー後の正確なデータ回復を保証するために、中断時点を指定します。
トラブルシューティングとバックトラッキング:データ損失または異常を検出した場合、問題が発生する前の時間にチェックポイントをリセットして、データをリプレイおよび修復できます。
タスク設定の大きな変更:タスク設定に大きな調整 (ターゲットテーブル構造やフィールドマッピングなど) を加えた後、新しい設定下でのデータ精度を保証するために、明確な時点から同期を開始するようにチェックポイントをリセットすることを推奨します。
操作の説明
Start をクリックします。ダイアログボックスで、Whether to reset the site を選択します:

リセットしない:タスクは停止前に記録された最後のチェックポイントから再開します。
リセットして時間を選択:指定された時間のチェックポイントから実行を開始します。時間がソースの Binlog の範囲内であることを確認してください。
同期タスクの実行時にチェックポイントエラーまたは存在しないというメッセージが表示された場合は、次の解決策を試してください:
チェックポイントのリセット:リアルタイム同期タスクを開始するときに、チェックポイントをリセットし、ソースデータベースで利用可能な最も古いチェックポイントを選択します。
ログ保持期間の調整:データベースのチェックポイントが期限切れになっている場合は、データベースのログ保持期間を調整することを検討してください (例:7 日間に設定)。
データ同期:データがすでに失われている場合は、再度完全同期を実行するか、オフライン同期タスクを設定して失われたデータを手動で同期することを検討してください。
よくある質問
データベース全体のリアルタイム同期に関する一般的な質問については、「リアルタイム同期」および「完全+増分同期」をご参照ください。