Amazon S3 出力コンポーネントを設定して、外部データベースのデータを Amazon S3 に書き込んだり、接続されたストレージシステムのデータをビッグデータプラットフォームにコピーしてプッシュし、Data Integration や再処理を行ったりします。この Topic では、Amazon S3 出力コンポーネントの設定プロセスについて説明します。
前提条件
Amazon S3 データソースが作成されていること。詳細については、「Amazon S3 データソースの作成」をご参照ください。
Amazon S3 出力コンポーネントのプロパティを設定するには、アカウントにデータソースに対するリードスルー権限が必要です。この権限がない場合は、リクエストする必要があります。詳細については、「データソース権限のリクエスト」をご参照ください。
操作手順
Dataphin ホームページで、トップメニューバーから[開発] > [データ統合] を選択します。
統合ページの上部メニューバーで、[プロジェクト] を選択します (Dev-Prod モードでは環境の選択が必要です)。
左側のナビゲーションウィンドウで、[Batch Pipeline] をクリックします。[Batch Pipeline] リストで、開発する オフラインパイプライン をクリックして、その構成ページを開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、 [コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] を選択します。 次に、右側にある出力コンポーネントのリストから [Amazon S3] コンポーネントを見つけて、キャンバスにドラッグします。
ターゲットの上流コンポーネントから
 アイコンをクリックしてドラッグし、Amazon S3 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、Amazon S3 出力コンポーネントに接続します。Amazon S3 出力コンポーネントのカードにある
 アイコンをクリックすると、[Amazon S3 出力設定] ダイアログボックスが開きます。
アイコンをクリックすると、[Amazon S3 出力設定] ダイアログボックスが開きます。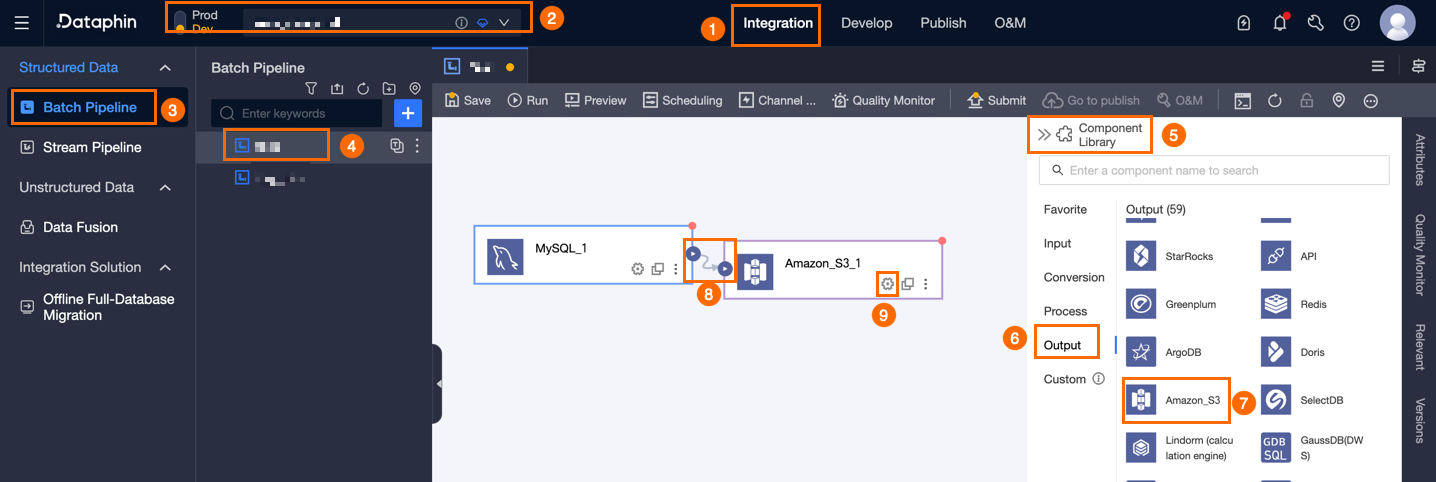
[Amazon S3 出力設定] ダイアログボックスで、次の表に従ってパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
Amazon S3 出力コンポーネントの名前です。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更できます。命名規則は次のとおりです:
中国語の文字、英字、アンダースコア (_)、および数字のみを含めることができます。
64 文字を超えることはできません。
データソース
データソースのドロップダウンリストには、ライトスルー権限があるものとないものを含め、すべての Amazon S3 タイプのデータソースが表示されます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。ライトスルー権限がないデータソースの場合、データソースの後に [リクエスト] をクリックして、ライトスルー権限をリクエストできます。詳細については、「データソース権限のリクエスト、更新、および返却」をご参照ください。
Amazon S3 型のデータソースがない場合は、[データソースの作成] をクリックしてデータソースを作成します。詳細については、「Amazon S3 データソースの作成」をご参照ください。
ファイルタイプ
データを変換して保存するファイルタイプを選択します。[ファイルタイプ] には [テキスト] と [CSV] が含まれます。
ファイル エンコーディング
ターゲットのデータソースにおけるファイルストレージ用のコーデックを選択します。[ファイルエンコーディング]には、[UTF-8] および [GBK] が含まれます。
オブジェクトプレフィックス
Amazon S3 オブジェクトの [オブジェクトプレフィックス] 情報を入力します。オブジェクトは、Amazon S3 におけるデータストレージの基本単位であり、Amazon S3 ファイルとも呼ばれます。オブジェクトは、メタデータ、ユーザー データ、およびキーで構成されます。キーは、バケット内でのオブジェクトを一意に識別します。データソースでディレクトリが設定されている場合、ここに自動的に表示されます。変更できますが、他のディレクトリに対する権限があることを確認してください。そうしないと、タスクは失敗します。
プレフィックス競合
オブジェクトのプレフィックスが競合した場合の実行ポリシーです。競合が発生した場合に、元のファイルを置換するか、元のファイルに追加するか、エラーを報告するかをサポートします。
元のファイルを置換:書き込み前に、指定されたオブジェクトプレフィックスに一致するすべてのオブジェクトをクリアします。たとえば、オブジェクトプレフィックスが Dataphin の場合、Dataphin で始まるすべてのオブジェクトがクリアされます。
元のファイルに追加:書き込み前に処理は行われません。設定されたオブジェクトプレフィックスが直接書き込みに使用され、ファイル名が競合しないようにランダムな UUID サフィックスが使用されます。
競合時にエラーを報告:指定されたパスに、指定されたプレフィックスに一致するオブジェクトが存在する場合、直接エラーが報告されます。たとえば、オブジェクトプレフィックスが Dataphin で、Dataphin という名前のオブジェクトが存在する場合、直接エラーが報告されます。
書き込むファイル数
ターゲットの Amazon S3 へのファイル書き込みポリシーです。単一ファイルまたは複数ファイルへの書き込みをサポートします。
単一ファイル:ターゲットの Amazon S3 に単一のファイルとして書き込みます。
複数ファイル:データは、宛先の Amazon S3 サービス内の複数のファイルに書き込まれます。サフィックスフォーマットも設定する必要があります。
_0、_1、または_2のようなシーケンスサフィックスを生成できます。ランダムな UUID サフィックスを生成することもできます。ファイル数はノードの並列度と同じになります。説明複数ファイルにデータを書き込む場合、ノードの並列度が 1 に設定されていてもサフィックスが生成されます。サフィックスは
_1またはランダムなuuidサフィックスになります。プレフィックスの競合ポリシーが「元のファイルに追加」の場合、UUID の乱数サフィックスのみが生成されます。
詳細設定
カラム区切り文字
列区切り文字を使用してターゲットテーブルに書き込みます。指定しない場合、デフォルトはカンマ (,) です。
行区切り文字
行区切り文字を使用してターゲットテーブルに書き込みます。指定しない場合、デフォルトは改行 (\n) です。
NULL 値
任意。NULL 値を表す文字列です。
ファイル名拡張子
.csvや.textなどのファイル名拡張子をオブジェクトの最終的なサフィックスとして指定できます。このパラメーターを空のままにすると、サフィックスは追加されません。フィールド名を出力するかどうか
[はい] を選択すると、上流コンポーネントのフィールド名が出力ファイルの最初の行として使用されます。[いいえ] を選択すると、フィールド名は出力されません。
フィールドマッピング
入力フィールド
上流の入力コンポーネントの出力フィールドを表示します。
出力フィールド
出力フィールドを表示します。Dataphin では、[一括追加] および [新しい出力フィールドの作成] で出力フィールドを設定できます:
バッチ追加: [バッチ追加] をクリックして、JSONまたはTEXT フォーマットでのバッチ構成をサポートします。
JSON フォーマットでのバッチ設定例:
// 例: [{"name": "user_id","type": "String"}, {"name": "user_name","type": "String"}]説明name はインポートされるフィールドの名前を指定し、type はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのデータの型を String に設定することを指定します。TEXT フォーマットでのバッチ設定例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行 (\n) です。改行 (\n)、セミコロン (;)、ピリオド (.) をサポートしています。
列区切り文字は、フィールド名とフィールドタイプを区切るために使用されます。デフォルトはカンマ (,) です。
新しい出力フィールドを作成。
「[+ 新しい出力フィールドを作成]」をクリックし、「[列]」を入力し、「[タイプ]」を画面の指示に従って選択します。
上流フィールドをコピー。
[上流フィールドのコピー] をクリックします。システムは、上流フィールド名に基づいて出力フィールドを自動的に生成します。
出力フィールドの管理。
追加されたフィールドに対して、次の操作も実行できます:
「[アクション]」列の
 アイコンをクリックして、既存のフィールドを編集します。
アイコンをクリックして、既存のフィールドを編集します。[操作] 列の
 アイコンをクリックして、既存のフィールドを削除します。
アイコンをクリックして、既存のフィールドを削除します。
マッピング
マッピング関係は、ソーステーブルの入力フィールドをターゲットテーブルの出力フィールドにマッピングし、後続のデータ同期を容易にするために使用されます。マッピング関係には、同名マッピングと同一行マッピングがあります。適用可能なシナリオは次のとおりです:
同名マッピング: フィールド名が同じフィールドをマッピングします。
同行マッピング: ソーステーブルとターゲットテーブルのフィールド名は一致しませんが、フィールドの対応する行のデータをマッピングする必要がある場合に使用します。同じ行のフィールドのみがマッピングされます。
[確認] をクリックして、Amazon S3 出力コンポーネントの設定を完了します.