このトピックでは、Pod の診断手順と Pod エラーのトラブルシューティング方法について説明します。また、Pod に関するよくある質問への回答も提供します。
目次
セクション | 説明 |
手順 | |
一般的なトラブルシューティング方法 | |
FAQ と解決策 |
手順
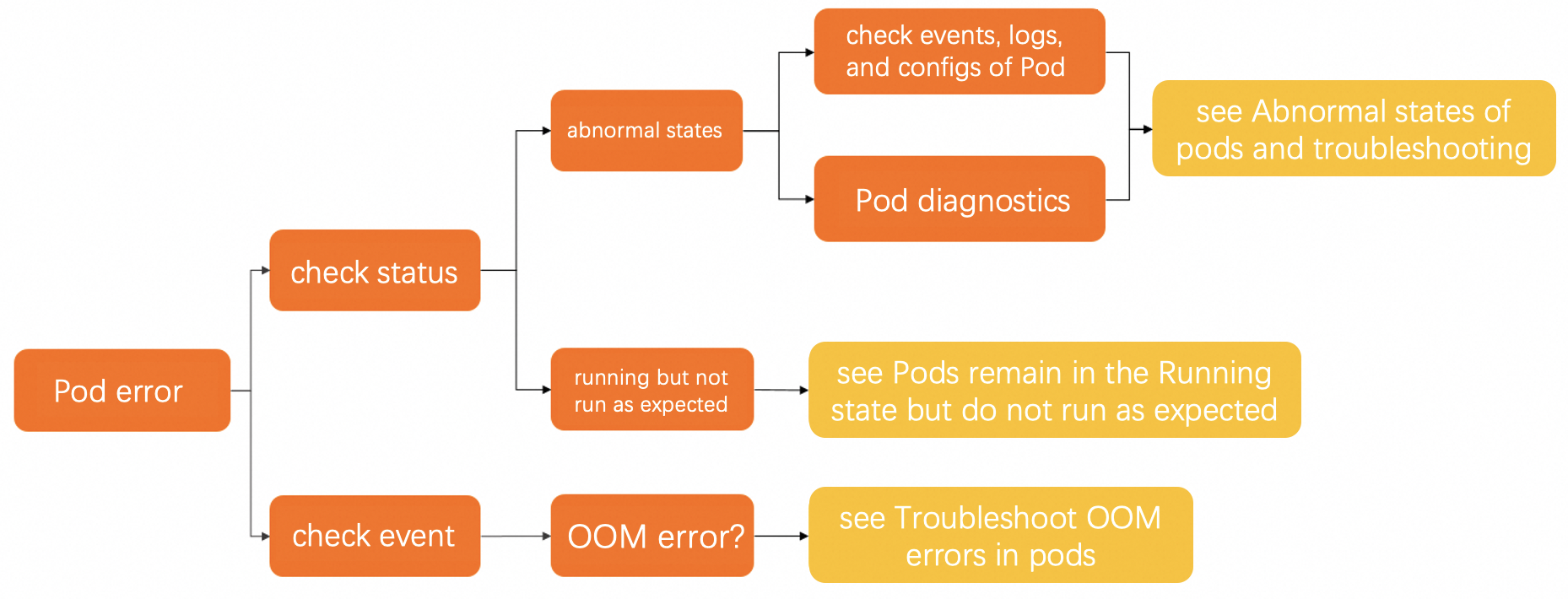
Pod が想定どおりに実行されているかどうかを確認します。詳細については、Pod の状態を確認するを参照してください。
Pod が想定どおりに実行されていない場合は、Pod のイベント、ログ、および構成を確認することで原因を特定できます。詳細については、一般的なトラブルシューティング方法を参照してください。Pod の異常な状態と Pod エラーのトラブルシューティング方法の詳細については、Pod の異常な状態とトラブルシューティングを参照してください。
Pod が Running 状態であるが想定どおりに実行されていない場合は、Pod が Running 状態のまま想定どおりに実行されないを参照してください。
Pod でメモリ不足 (OOM) エラーが発生した場合は、Pod の OOM エラーのトラブルシューティングを参照してください。
Pod の異常な状態とトラブルシューティング
Pod の状態 | 説明 | 解決策 |
Pending | Pod はスケジュールされていません。 | |
Init:N/M | Pod には M 個の init コンテナが含まれており、N 個の init コンテナが起動されています。 | Pod が Init:N/M、Init:Error、または Init:CrashLoopBackOff 状態のままになる |
Init:Error | init コンテナが起動に失敗しました。 | Pod が Init:N/M、Init:Error、または Init:CrashLoopBackOff 状態のままになる |
Init:CrashLoopBackOff | init コンテナが起動ループで停止しています。 | Pod が Init:N/M、Init:Error、または Init:CrashLoopBackOff 状態のままになる |
Completed | Pod は起動コマンドを完了しました。 | |
CrashLoopBackOff | Pod が起動ループで停止しています。 | |
ImagePullBackOff | Pod はコンテナイメージのプルに失敗しました。 | |
Running |
|
|
Terminating | Pod は終了処理中です。 |
一般的なトラブルシューティング方法
Pod の状態を確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。次に、Pod を見つけて、その状態を確認します。
Pod が Running 状態の場合、Pod は想定どおりに実行されています。
Pod が Running 状態ではない場合、Pod は異常です。問題のトラブルシューティングを行うには、Pod の異常な状態とトラブルシューティングを参照してください。
Pod の詳細を確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。Pod のリストで、Pod を見つけて、Pod の名前をクリックするか、[アクション] 列の [詳細の表示] をクリックして、Pod に関する情報を表示します。Pod の名前、イメージ、および IP アドレスを表示できます。
Pod の構成を確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。Pod のリストで、Pod を見つけて、Pod の名前をクリックするか、[アクション] 列の [詳細の表示] をクリックします。
Pod 詳細ページの右上隅にある 編集をクリックして、Pod の YAML ファイルと構成を表示します。
Pod のイベントを確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。Pod のリストで、Pod を見つけて、Pod の名前をクリックするか、[アクション] 列の [詳細の表示] をクリックします。
Pod 詳細ページの右上隅にある 編集をクリックして、Pod の YAML ファイルと構成を表示します。
Pod 詳細ページの下部にある イベントタブをクリックして、Pod のイベントを表示します。
説明デフォルトでは、Kubernetes は過去 1 時間以内に発生したイベントを保持します。より長い期間に発生したイベントを保持する場合は、イベントセンターの作成と使用を参照してください。
Pod のログを確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタ ページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーション ウィンドウで、ワークロード > ポッド を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。Pod のリストで、Pod を見つけて、Pod の名前をクリックするか、[アクション] 列の [詳細の表示] をクリックします。
Pod 詳細ページの下部にある ログタブをクリックして、Pod のログを表示します。
説明Alibaba Cloud Container Service for Kubernetes (ACK) はログサービスと統合されています。クラスタを作成するときに、ログサービスを有効にして、クラスタのコンテナからログデータを収集できます。ログデータは標準出力とテキストファイルに書き込まれます。詳細については、Pod の環境変数を使用してアプリケーションログを収集するを参照してください。
Pod に関する監視情報を確認する
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Prometheus 監視 を選択します。
Prometheus 監視ページで、クラスタ概要タブをクリックして、Pod に関する次の監視情報を表示します。CPU 使用率、メモリ使用率、およびネットワーク I/O。
ターミナルを使用してコンテナーにログオンする
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページで、管理する Pod を見つけて、ターミナルアクション列の をクリックします。
説明ターミナルを使用して Pod のコンテナーにログオンし、コンテナー内のローカルファイルを表示できます。
Pod 診断
コンテナサービスコンソールにログインします。左側のナビゲーションペインで、クラスタをクリックします。
クラスタページで、管理するクラスタを見つけて、その ID をクリックします。クラスタ詳細ページの左側のナビゲーションペインで、ワークロード > Pod を選択します。
Pod ページの左上隅で、Pod が属する 名前空間を選択します。Pod のリストで、Pod を見つけて、Pod の名前をクリックするか、[アクション] 列の [詳細の表示] をクリックして、Pod に関する情報を表示します。Pod の名前、イメージ、および IP アドレスを表示できます。
Pod ページで、管理する Pod を見つけて、診断アクション列の をクリックします。
説明Pod 診断が完了したら、診断結果を表示して問題のトラブルシューティングを行うことができます。詳細については、クラスタ診断の操作を参照してください。
Pod が Pending 状態のままになる
原因
Pod が Pending 状態のままになっている場合、Pod を特定のノードにスケジュールできません。この問題は、Pod に必要なリソースが不足しているか、クォータ構成が無効な場合に発生します。
症状
Pod が Pending 状態のままになっています。
解決策
Pod のイベントを確認し、イベントに基づいて Pod をノードにスケジュールできない理由を特定します。考えられる原因:
リソース依存関係
ConfigMap や永続ボリュームクレーム (PVC) など、特定のクラスタリソースがないと作成できない Pod もあります。たとえば、Pod の PVC を指定する前に、PVC を永続ボリューム (PV) に関連付ける必要があります。
無効なクォータ構成
Pod のイベントと監査ログを確認します。
Pod が Init:N/M 状態、Init:Error 状態、または Init:CrashLoopBackOff 状態のままになる
原因
Pod が Init:N/M 状態のままになっている場合、Pod には M 個の init コンテナが含まれており、N 個の init コンテナが起動されていますが、M-N 個の init コンテナが起動に失敗しています。
Pod が Init:Error 状態のままになっている場合、Pod 内の init コンテナが起動に失敗しています。
Pod が Init:CrashLoopBackOff 状態のままになっている場合、Pod 内の init コンテナが起動ループで停止しています。
症状
Pod が Init:N/M 状態のままになっています。
Pod が Init:Error 状態のままになっています。
Pod が Init:CrashLoopBackOff 状態のままになっています。
解決策
Pod のイベントを表示し、Pod 内で起動に失敗した init コンテナでエラーが発生しているかどうかを確認します。詳細については、Pod のイベントを確認するを参照してください。
Pod 内で起動に失敗した init コンテナのログを確認し、ログデータに基づいて問題のトラブルシューティングを行います。詳細については、Pod のログを確認するを参照してください。
Pod の構成を確認し、起動に失敗した init コンテナの構成が有効であることを確認します。詳細については、Pod の構成を確認するを参照してください。init コンテナの詳細については、init コンテナのデバッグを参照してください。
Pod が ImagePullBackOff 状態のままになる
原因
Pod が ImagePullBackOff 状態のままになっている場合、Pod はバックグラウンドでスケジュールされていますが、コンテナイメージのプルに失敗しています。
症状
Pod が ImagePullBackOff 状態のままになっています。
解決策
対応する Pod イベントの説明を確認し、プルに失敗したコンテナイメージの名前を確認します。
コンテナイメージの名前が有効かどうかを確認します。
プライベートイメージリポジトリを使用している場合は、イメージリポジトリに保存されているイメージを使用して ACK ワークロードを作成するを参照してください。
Pod が CrashLoopBackOff 状態のままになる
原因
Pod が CrashLoopBackOff 状態のままになっている場合、Pod 内のアプリケーションでエラーが発生しています。
症状
Pod が CrashLoopBackOff 状態のままになっています。
解決策
Pod のイベントを表示し、Pod でエラーが発生しているかどうかを確認します。詳細については、Pod のイベントを確認するを参照してください。
Pod のログを確認し、ログデータに基づいて問題のトラブルシューティングを行います。詳細については、Pod のログを確認するを参照してください。
Pod の構成を表示し、ヘルスチェック構成が有効かどうかを確認します。詳細については、Pod の構成を確認するを参照してください。Pod のヘルスチェックの詳細については、Liveness、Readiness、および Startup プローブの構成を参照してください。
Pod が Completed 状態のままになる
原因
Pod が Completed 状態の場合、Pod 内のコンテナは起動コマンドを完了し、コンテナ内のすべてのプロセスが終了しています。
症状
Pod が Completed 状態のままになっています。
解決策
Pod の構成を表示し、Pod 内のコンテナによって実行される起動コマンドを確認します。詳細については、Pod の構成を確認するを参照してください。
Pod のログを確認し、ログデータに基づいて問題のトラブルシューティングを行います。詳細については、Pod のログを確認するを参照してください。
Pod が Running 状態のまま想定どおりに実行されない
原因
Pod のデプロイに使用される YAML ファイルにエラーが含まれています。
症状
Pod が Running 状態のままになっていますが、想定どおりに実行されていません。
解決策
Pod の構成を表示し、Pod 内のコンテナが想定どおりに構成されているかどうかを確認します。詳細については、Pod の構成を確認するを参照してください。
次の方法を使用して、環境変数のキーにスペルミスがないか確認します。
次の例では、command を commnd とスペルミスした場合に、スペルミスを特定する方法について説明します。
説明Pod を作成するときに、システムは環境変数のキーのスペルミスを無視します。たとえば、command を commnd とスペルミスした場合でも、YAML ファイルを使用して Pod を作成できます。ただし、Pod は YAML ファイルにスペルミスが含まれているコマンドを実行できません。代わりに、Pod はイメージ内のデフォルトコマンドを実行します。
--validateをkubectl apply -fコマンドの前に配置し、kubectl apply --validate -f XXX.yamlコマンドを実行します。command を commnd とスペルミスした場合、次のエラーが発生します。
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test。次のコマンドを実行し、生成された pod.yaml ファイルを、Pod の作成に使用された元のファイルと比較します。
kubectl get pods [$Pod] -o yaml > pod.yaml説明[$Pod]は異常な Pod の名前です。kubectl get podsコマンドを実行して名前を表示できます。pod.yaml ファイルに、Pod の作成に使用された元のファイルよりも多くの行が含まれている場合、Pod は想定どおりに作成されています。
pod.yaml ファイルに元のファイルのコマンド行が含まれていない場合、元のファイルにスペルミスが含まれている可能性があります。
Pod のログを確認し、ログデータに基づいて問題のトラブルシューティングを行います。詳細については、Pod のログを確認するを参照してください。
ターミナルを使用して Pod 内のコンテナにログオンし、コンテナ内のローカルファイルを確認できます。詳細については、ターミナルを使用してコンテナーにログオンするを参照してください。
Pod が Terminating 状態のままになる
原因
Pod が Terminating 状態の場合、Pod は終了処理中です。
症状
Pod が Terminating 状態のままになっています。
解決策
Terminating 状態のままになっている Pod は、一定期間後に削除されます。Pod が Terminating 状態のままになっている時間が長い場合は、次のコマンドを実行して Pod を強制的に削除できます。
kubectl delete pod [$Pod] -n [$namespace] --grace-period=0 --forcePod の OOM エラーのトラブルシューティング
原因
クラスタ内のコンテナのメモリ使用量が指定されたメモリ制限を超えると、コンテナが終了し、OOM イベントがトリガーされる可能性があり、コンテナが終了します。OOM イベントの詳細については、コンテナと Pod にメモリリソースを割り当てるを参照してください。
症状
終了したプロセスがスタックしたコンテナの原因である場合、コンテナが再起動する可能性があります。
OOM エラーが発生した場合は、コンソールにログインして Pod 詳細ページに移動します。イベントタブで、次の OOM イベントを表示できます。pod was OOM killed。
解決策
Pod のメモリ使用量グラフに基づいて、エラーが発生した時刻を確認します。詳細については、Pod に関する監視情報を確認するを参照してください。
次の監視情報に基づいて、Pod のプロセスでメモリリークが発生しているかどうかを確認します。メモリ使用量が急増した時点、ログデータ、およびプロセス名。
OOM エラーがメモリリークによって発生した場合は、ビジネスシナリオに基づいて問題のトラブルシューティングを行うことをお勧めします。
プロセスが想定どおりに実行されている場合は、Pod のメモリ制限を増やします。Pod の実際のメモリ使用量が Pod のメモリ制限の 80% を超えないようにしてください。詳細については、Pod の管理を参照してください。