このセクションでは、Python SDKを使用してジョブを送信する方法について説明します。ジョブの目的は、ログファイルにINFO、WARN、ERROR、およびDEBUGが出現する回数をカウントすることです。
注: 事前にBatch Computeサービスにサインアップしていることを確認してください。
目次:
ジョブの準備
データファイルをOSSにアップロードする
タスクプログラムをOSSにアップロードする
SDKを使用してジョブを送信する
結果を確認する
ジョブの目的は、ログファイルにINFO、WARN、ERROR、およびDEBUGが出現する回数をカウントすることです。
このジョブには、次のタスクが含まれています。
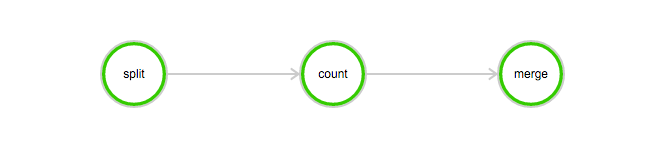
分割タスクは、ログファイルを3つの部分に分割するために使用されます。
カウントタスクは、ログファイルの各部分にINFO、WARN、ERROR、およびDEBUGが出現する回数をカウントするために使用されます。カウントタスクでは、InstanceCountを3に設定する必要があります。これは、3つのカウントタスクが同時に開始されることを示します。
マージタスクは、すべてのカウント結果をマージするために使用されます。
DAG
1.1. データファイルをOSSにアップロードする
この例で使用されるデータファイルをダウンロードします: log-count-data.txt
log-count-data.txtファイルをoss://your-bucket/log-count/log-count-data.txtにアップロードします。
your-bucketは、自分で作成したバケットを示します。この例では、リージョンはcn-shenzhenであると想定されています。ファイルをOSSにアップロードするには、ファイルをOSSにアップロードするを参照してください。
1.2. タスクプログラムをOSSにアップロードする
この例で使用されるジョブプログラムは、Pythonを使用してコンパイルされています。プログラムをダウンロードします: log-count.tar.gz.
この例では、サンプルコードを変更する必要はありません。 log-count.tar.gzをOSSに直接アップロードできます。たとえば、oss://your-bucket/log-count/log-count.tar.gzです。
アップロード方法は前述しました。
Batch Computeは、拡張子がtar.gzの圧縮パッケージのみをサポートしています。パッケージ化には、前述の方法(gzip)を使用してください。そうしないと、パッケージを解析できません。
コードを変更する必要がある場合は、ファイルを解凍し、コードを変更してから、次の手順に従って変更されたコードをパックします。
コマンドは次のとおりです。
> cd log-count # ディレクトリに切り替えます。 > tar -czf log-count.tar.gz * # このディレクトリの下にあるすべてのファイルをlog-count.tar.gzにパックします。次のコマンドを実行して、圧縮パッケージの内容を確認できます。
$ tar -tvf log-count.tar.gz次のリストが表示されます。
conf.py count.py merge.py split.py
2. SDKを使用してジョブを送信する
Python SDKのアップロードとインストール方法の詳細については、ここをクリックしてください。
SDKバージョンがv20151111の場合、ジョブを送信するときにクラスタIDを指定するか、AutoClusterパラメータを使用する必要があります。この例では、AutoClusterを使用します。AutoClusterには、次のパラメータを設定する必要があります。
使用可能なイメージID。システムが提供するイメージを使用するか、イメージをカスタマイズできます。イメージのカスタマイズ方法の詳細については、イメージを使用するを参照してください。
InstanceType。インスタンスタイプの詳細については、現在サポートされているインスタンスタイプを参照してください。
StdoutRedirectPath(プログラム出力)とStderrRedirectPath(エラーログ)を格納するためのパスをOSSに作成します。この例では、作成されたパスはoss://your-bucket/log-count/logs/です。
この例でプログラムを実行するには、前述の変数とOSSパス変数に基づいて、プログラム内のコメント付き変数を変更します。
Python SDKを使用する場合のプログラム送信テンプレートを以下に示します。プログラムのパラメータの具体的な意味については、ここをクリックしてください。
#encoding=utf-8
import sys
from batchcompute import Client, ClientError
from batchcompute import CN_SHENZHEN as REGION
from batchcompute.resources import (
JobDescription, TaskDescription, DAG, AutoCluster
)
ACCESS_KEY_ID='' # AccessKeyIDを入力してください
ACCESS_KEY_SECRET='' # AccessKeySecretを入力してください
IMAGE_ID = 'img-ubuntu' # イメージIDを入力してください
INSTANCE_TYPE = 'ecs.sn1.medium' # リージョンに基づいてインスタンスタイプを入力してください
WORKER_PATH = '' # 'oss://your-bucket/log-count/log-count.tar.gz' アップロードされたlog-count.tar.gzのOSSストレージパスを入力してください
LOG_PATH = '' # 'oss://your-bucket/log-count/logs/' エラーフィードバックとタスク出力のOSSストレージパスを入力してください
OSS_MOUNT= '' # 'oss://your-bucket/log-count/' "/home/inputs"と"/home/outputs"にマウントします
client = Client(REGION, ACCESS_KEY_ID, ACCESS_KEY_SECRET)
def main():
try:
job_desc = JobDescription()
# 自動クラスタを作成します。
cluster = AutoCluster()
cluster.InstanceType = INSTANCE_TYPE
cluster.ResourceType = "OnDemand"
cluster.ImageId = IMAGE_ID
# 分割タスクを作成します。
split_task = TaskDescription()
split_task.Parameters.Command.CommandLine = "python split.py"
split_task.Parameters.Command.PackagePath = WORKER_PATH
split_task.Parameters.StdoutRedirectPath = LOG_PATH
split_task.Parameters.StderrRedirectPath = LOG_PATH
split_task.InstanceCount = 1
split_task.AutoCluster = cluster
split_task.InputMapping[OSS_MOUNT]='/home/input'
split_task.OutputMapping['/home/output'] = OSS_MOUNT
# マップタスクを作成します。
count_task = TaskDescription(split_task)
count_task.Parameters.Command.CommandLine = "python count.py"
count_task.InstanceCount = 3
count_task.InputMapping[OSS_MOUNT] = '/home/input'
count_task.OutputMapping['/home/output'] = OSS_MOUNT
# マージタスクを作成します
merge_task = TaskDescription(split_task)
merge_task.Parameters.Command.CommandLine = "python merge.py"
merge_task.InstanceCount = 1
merge_task.InputMapping[OSS_MOUNT] = '/home/input'
merge_task.OutputMapping['/home/output'] = OSS_MOUNT
# タスクDAGを作成します。
task_dag = DAG()
task_dag.add_task(task_name="split", task=split_task)
task_dag.add_task(task_name="count", task=count_task)
task_dag.add_task(task_name="merge", task=merge_task)
task_dag.Dependencies = {
'split': ['count'],
'count': ['merge']
}
# ジョブ記述を作成します。
job_desc.DAG = task_dag
job_desc.Priority = 99 # 0-1000
job_desc.Name = "log-count"
job_desc.Description = "PythonSDKDemo"
job_desc.JobFailOnInstanceFail = True
job_id = client.create_job(job_desc).Id
print('job created: %s' % job_id)
except ClientError, e:
print (e.get_status_code(), e.get_code(), e.get_requestid(), e.get_msg())
if __name__ == '__main__':
sys.exit(main())3. ジョブステータスを確認する
get_jobを参照して、ジョブステータスを表示できます。
jobInfo = client.get_job(job_id)
print (jobInfo.State)ジョブは、待機中、実行中、完了、失敗、停止のいずれかの状態になります。
4. ジョブの実行結果を確認する
OSSコンソールにログインし、バケットの下にある次のファイルを確認します: /log-count/merge_result.json。
期待される結果は次のとおりです。
{"INFO": 2460, "WARN": 2448, "DEBUG": 2509, "ERROR": 2583}または、概要を使用して結果を取得することもできます。