このトピックでは、ApsaraMQ for RocketMQ クライアントがメッセージを消費する方法と、メッセージが蓄積される理由について説明します。 また、SDK for Java を使用して TCP 経由でメッセージを送受信する際に、メッセージの蓄積と遅延を処理する方法についても説明します。 これにより、ビジネスデプロイメントの前にリソースを適切に計画し、設定を構成することができます。 また、O&M 中にビジネスロジックを調整して、メッセージの蓄積と遅延によって発生する問題を防ぐのにも役立ちます。
背景情報
メッセージ処理中に、クライアントのメッセージ消費率がブローカーのメッセージ生成率に追いつかない場合、蓄積されたメッセージが生成されます。 これにより、メッセージ消費の遅延がさらに発生します。 次のシナリオでは、メッセージの蓄積と遅延に特に注意することをお勧めします。
ダウンストリームシステムの消費能力がアップストリームシステムの生産能力と一致しないため、メッセージが継続的に蓄積されます。 また、メッセージ消費は自動的に回復できません。
ビジネスシステムは、リアルタイムのメッセージ消費に非常に高い要件を課しているため、一時的なメッセージの蓄積による遅延も許容できません。
クライアントはどのようにメッセージを消費しますか?
次の図は、ApsaraMQ for RocketMQ クライアントが TCP 経由でメッセージを消費する方法を示しています。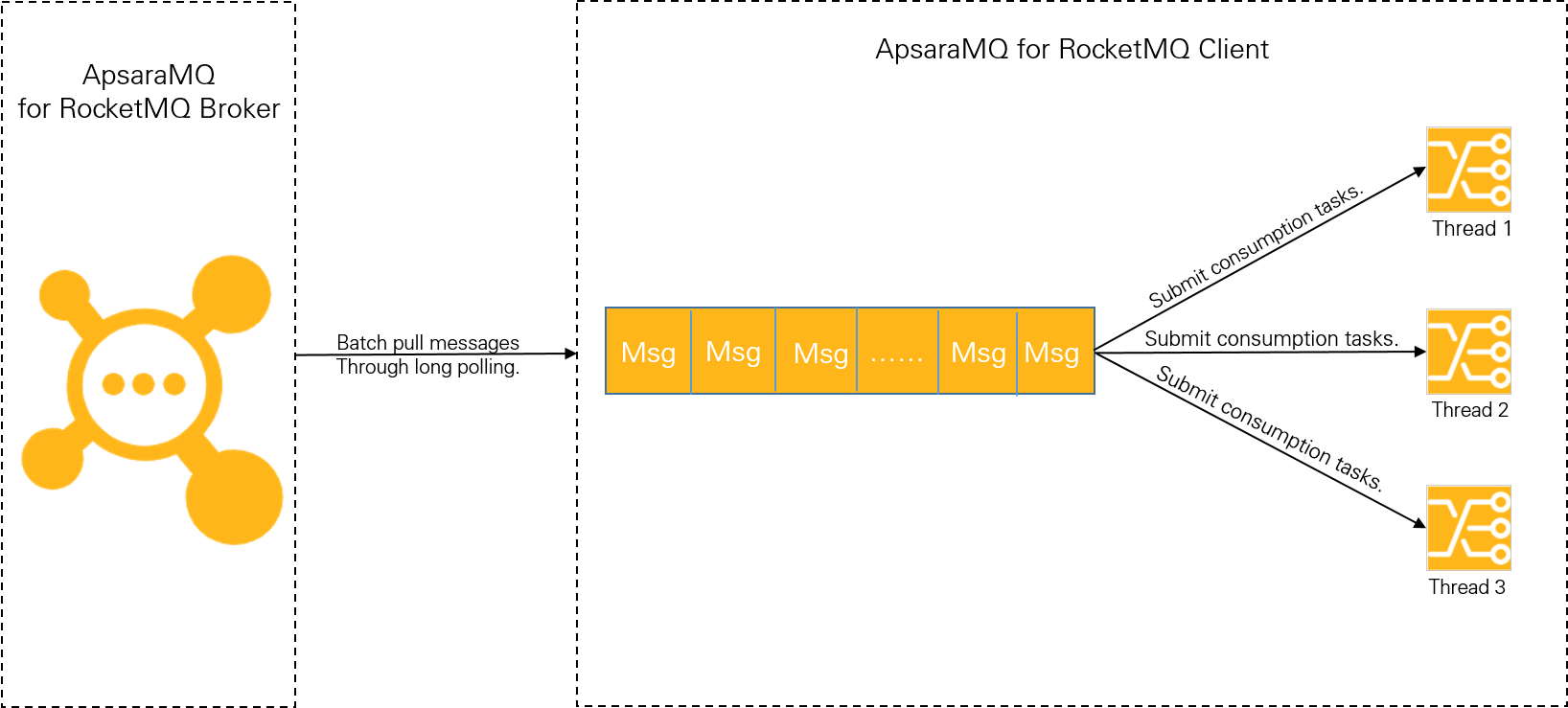
クライアントを使用してプッシュモードでメッセージを消費するには、次の 2 つのフェーズがあります。
フェーズ 1: メッセージをプルする。 クライアントは、ロングポーリングを使用して、ApsaraMQ for RocketMQ ブローカーからメッセージをバッチでプルします。 プルされたメッセージは、ローカルバッファーキューにキャッシュされます。
メッセージをバッチでプルすると、一般的な内部ネットワークで高いスループットを実現できます。 たとえば、シングルスレッドとシングルパーティションの低スペックサーバー (4 vCPU と 8 GB メモリ) の 1 秒あたりのトランザクション数 (TPS) は数万の範囲になります。 複数パーティションのサーバーの場合、TPS は数十万に達する可能性があります。 したがって、このフェーズでは、メッセージ蓄積のボトルネックは発生しません。
フェーズ 2: 消費スレッドにメッセージを送信する。 クライアントは、ローカルにキャッシュされたメッセージを消費スレッドに送信し、スレッドはメッセージ消費ロジックを使用してメッセージを処理します。
クライアントの消費能力は、ビジネスロジックの複雑さ (消費期間) と消費の同時実行性に依存します。 ビジネスロジックが複雑で、単一のメッセージを処理するのに多くの時間がかかる場合、全体的なスループットは高くできません。 ローカルバッファーキューに格納されているメッセージの数が上限に達すると、クライアントはブローカーからのメッセージのプルを停止します。
上記のクライアント側の消費メカニズムは、メッセージ蓄積のボトルネックがローカルクライアントの消費能力、つまり 消費期間 と 消費の同時実行性 によって発生することを示しています。 メッセージの蓄積によって発生する問題を防ぎ、解決するには、消費期間と同時実行性を適切に構成する必要があります。 消費期間は消費の同時実行性よりも優先されることに注意してください。
消費期間
消費期間に影響を与える要因には、CPU、メモリ内コンピューティング、外部 I/O 操作などがあります。 ほとんどの場合、再帰とループはコードで定義されていません。 したがって、内部計算時間は、外部 I/O 操作と比較してほとんど無視できます。 外部 I/O 操作には、通常、次のビジネスロジックが含まれます。
MySQL データベースなどの外部データベースでのデータの読み取りと書き込み。
Redis などの外部キャッシュシステムでのデータの読み取りと書き込み。
Dubbo 呼び出しやダウンストリーム HTTP インターフェース呼び出しなどのダウンストリームシステム呼び出し。
このような外部呼び出しのロジックとシステム容量を整理して、各呼び出しで消費される予想時間を理解する必要があります。 これにより、消費ロジックの I/O 操作で消費される時間が妥当かどうかを判断できます。 ほとんどの場合、サービスの例外またはダウンストリームシステムの容量制限により消費期間が長くなるため、メッセージが蓄積されます。
たとえば、データベースにデータを書き込むメッセージ消費ロジックを指定し、各メッセージの消費期間を 1 ミリ秒に指定するとします。 メッセージ量が小さい場合、例外は発生しません。 ただし、販売プロモーション中は、データベースに書き込まれる 1 秒あたりのメッセージ数が大幅に増加し、データベースの容量制限にすぐに達します。 その結果、各メッセージの消費期間が 100 ミリ秒に増加し、消費率が急激に低下します。 ApsaraMQ for RocketMQ クライアントの消費の同時実行性を変更するだけでは、この問題は解決できません。 代わりに、データベース容量をスペックアップする必要があります。
消費の同時実行性
次の表に、ApsaraMQ for RocketMQ での消費の同時実行性を計算する方法を示します。
メッセージタイプ | 消費の同時実行性 |
通常のメッセージ | ノードあたりのスレッド数 × ノード数 |
スケジュール済みメッセージと遅延メッセージ | |
トランザクションメッセージ | |
順序付けられたメッセージ | 最小 (ノードあたりのスレッド数 × ノード数、パーティション数) |
クライアントの消費の同時実行性は、ノードあたりのスレッド数とノード数によって決まります。 ほとんどの場合、最初に単一ノードのスレッド数を調整する必要があります。 ノードのハードウェアリソースが上限に達している場合は、ノードを追加して消費の同時実行性を高める必要があります。
順序付けられたメッセージの消費の同時実行性は、トピックのパーティション数によっても制限されます。 パーティション数の評価については、Alibaba Cloud カスタマーサービスにお問い合わせください。
単一ノードでの消費の同時実行性を設定する場合、スレッド数が多すぎると、スレッド切り替えのオーバーヘッドが大きくなる可能性があります。 理想的な環境で単一ノードの最適なスレッド数を計算するには、次のモデルを使用します。
単一ノードの vCPU の数は C です。
スレッド切り替えに消費される時間は無視され、I/O 操作は CPU リソースを消費しません。
スレッドには処理を待機しているメッセージが十分にあり、メモリも十分にあります。
ロジックでは、CPU 時間は T1、外部 I/O 操作時間は T2 です。
単一スレッドは、1/(T1 + T2) の TPS を実現できます。 CPU 使用率が目的の値 100% に達した場合は、単一ノードが最大の消費能力に達するように、C × (T1 + T2)/T1 スレッドを設定する必要があります。
この例の最大スレッド数は、理想的な環境下で得られた理論上のデータにすぎません。 実際のアプリケーション環境では、スレッド数を徐々に増やし、効果を観察してから調整することをお勧めします。
メッセージの蓄積と遅延を防ぐにはどうすればよいですか?
予期しないメッセージの蓄積と遅延を防ぐには、設計の初期段階でビジネスロジックを確認して整理します。 通常のビジネス運用のパフォーマンスベースラインを整理しておくと、障害発生時に問題を迅速に特定できます。 主なタスクは、消費期間と同時実行性を整理することです。
消費期間を整理する
ストレステストを実行し、時間のかかる操作のコードロジックを分析することにより、消費期間を取得します。 消費期間のクエリ方法の詳細については、「消費期間をクエリする」をご参照ください。 消費期間を整理する際には、次の点に注意してください。
メッセージ消費ロジックの計算の複雑さが過度に高いかどうか、およびコードに無限ループや再帰などの欠陥がないかどうかを確認します。
メッセージ消費ロジックの I/O 操作 (外部呼び出し、ストレージの読み取り/書き込みなど) が必要かどうかを確認します。 また、ローカルキャッシュなどのソリューションを使用して、これらの操作を回避できるかどうかを確認します。
メッセージ消費ロジックの複雑で時間のかかる操作を非同期で処理できるかどうかを確認します。 可能な場合は、ロジックが混乱するかどうかを確認します。 たとえば、消費は完了しましたが、非同期操作は完了していません。
消費の同時実行性を設定する
単一ノードのスレッド数を徐々に増やします。 次に、ノードのメトリックを観察して、ノードの最適な消費スレッド数と最大スループットを取得します。
単一ノードの最適なスレッド数とスループットを取得したら、必要なノード数を計算します。 これは、アップストリームシステムとダウンストリームシステムのピークトラフィックに基づいて、次の式を使用して行うことができます。ノード数 = ピークトラフィック/単一スレッドのスループット。
メッセージの蓄積と遅延を処理するにはどうすればよいですか?
メッセージ蓄積アラートを構成します。
ApsaraMQ for RocketMQ が提供する監視およびアラート機能を使用してアラートルールを設定し、メッセージの蓄積を監視および処理します。 アラートルールを設定する方法の詳細については、「メッセージ蓄積アラートを構成する」をご参照ください。
蓄積されたメッセージを処理します。
蓄積されたメッセージの処理方法については、「蓄積されたメッセージを処理するにはどうすればよいですか?」をご参照ください。