AnalyticDB for PostgreSQLでは、外部データラッパー (FDW) を使用して、Alibaba Cloudアカウント内のインスタンス間でデータを簡単かつ迅速にクエリできます。 これにより、データの適時性が確保され、データの冗長性が減ります。
概要
企業または組織は、異なるビジネス分野またはアプリケーションをサポートするために複数のインスタンスを実行できます。 特定のケースでは、インスタンス間でデータをクエリして、ビジネスユニット間で関連分析を行う必要があります。 次のいずれかの方法を使用して、過去のインスタンス間クエリを実行できます。
同じデータコピーを異なるインスタンスに保存します。 この方法は、データの無秩序化およびデータ冗長性を引き起こす。
Object storage Service (OSS) バケットなどの共有ストレージにデータを保存します。 この方法では、データの適時性を保証できません。
上記の問題を解決するために、Alibaba Cloudチームは、AnalyticDB for PostgreSQLのMPPアーキテクチャとコンピュートノード間の相互通信に基づくFDWを開発しました。 FDWは、計算ノードのパフォーマンス機能を使用して、インスタンス間の並列データアクセスを実装し、データアクセスの効率を向上させます。 FDWのパフォーマンスは、ネイティブpostgres_fdw拡張のパフォーマンスの数倍です。
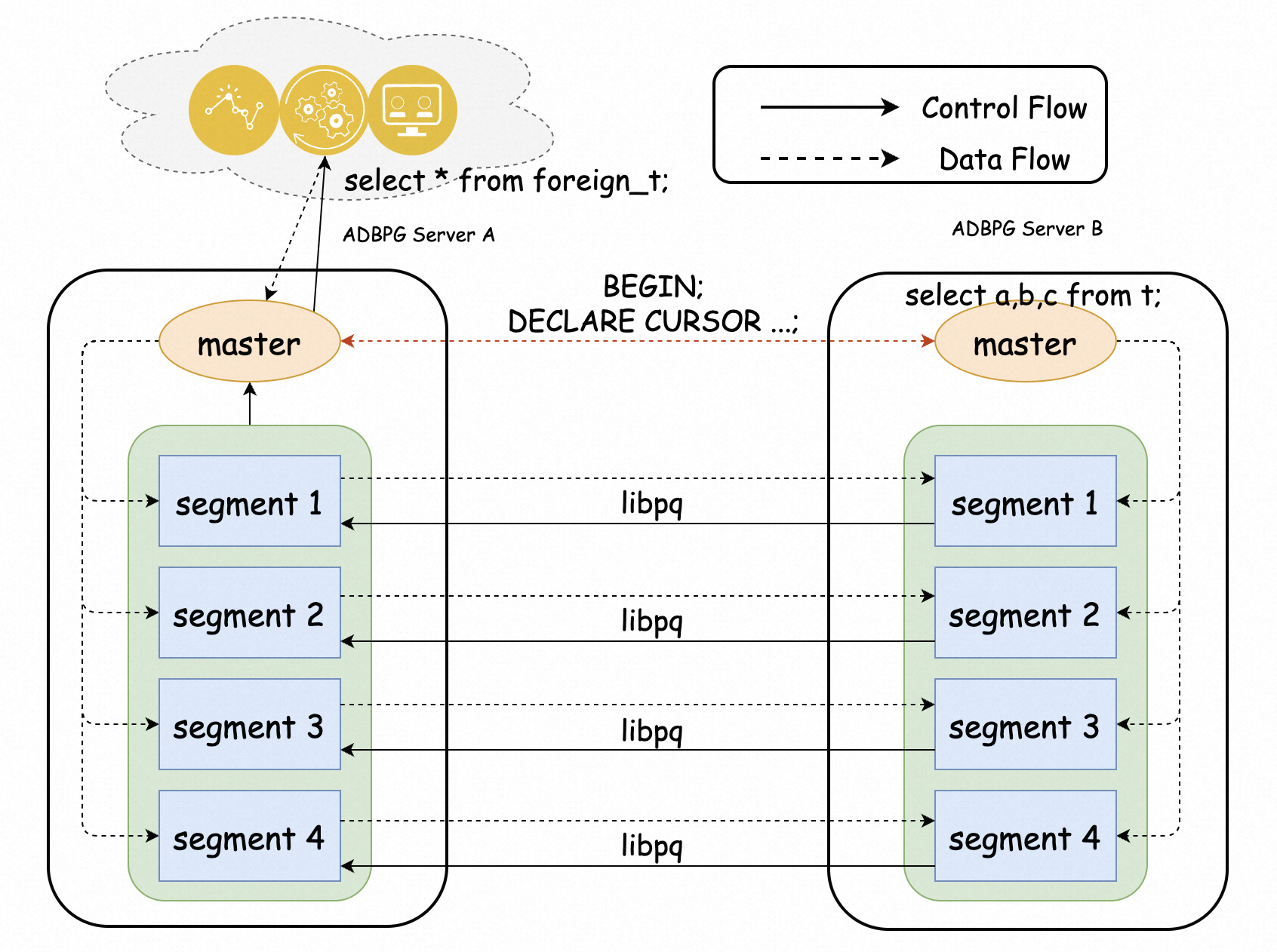
使用上の注意
ソースインスタンスとターゲットインスタンスは、同じAlibaba Cloudアカウントに属し、同じリージョンと仮想プライベートクラウド (VPC) に存在する必要があります。
サーバーレスモードのソースインスタンスがスケーリング状態の場合、インスタンスのデータにアクセスできません。
クロスインスタンスクエリ機能は、次のマイナーバージョンでのみサポートされています。
エラスティックストレージモードのAnalyticDB for PostgreSQL V7.0: V7.0.1.x以降。
エラスティックストレージモードのAnalyticDB for PostgreSQL V6.0: V6.3.11.2以降。
サーバーレスモードのAnalyticDB for PostgreSQL: V1.0.6.x以降。
AnalyticDB for PostgreSQL V7.0のパスワード検証方法が変更されました。 サーバーレスモードのAnalyticDB for PostgreSQL V7.0インスタンスまたはAnalyticDB for PostgreSQLインスタンスからAnalyticDB for PostgreSQL V7.0インスタンスにアクセスする場合は、 チケットを起票して、サービスセンターにお問い合わせください。
FDW外部テーブルは、SELECTおよびINSERT操作のみをサポートします。 UPDATEおよびDELETE操作はサポートされていません。
エラスティックストレージモードのAnalyticDB for PostgreSQL V7.0のみが、結合プッシュダウンと集約プッシュダウンをサポートしています。
FDW外部テーブルの実行計画を生成できるのは、エラスティックストレージモードのAnalyticDB for PostgreSQL V7.0のOrcaオプティマイザだけです。 エラスティックストレージモードのAnalyticDB for PostgreSQL V6.0およびサーバーレスモードのAnalyticDB for PostgreSQLは、ネイティブオプティマイザを使用してFDW外部テーブルの実行計画を生成します。
手順
同じAlibaba Cloudアカウントに属するインスタンスAとBでデータクエリ機能を有効にするには、次の手順を実行します。 2つのインスタンスは同じリージョンとVPCに存在します。 この機能を有効にすると、インスタンスAのdb01データベースからインスタンスBのdb02データベースのテーブルにアクセスできます。その後、計算ノード間の相互通信を使用して、db01データベースのテーブルとの関連クエリを容易にすることができます。
psqlツールを使用してインスタンスAとBに接続します。詳細については、「クライアント接続」をご参照ください。
インスタンスAとBでデータベースを作成します。
インスタンスaにdb01という名前のデータベースを作成し、db01データベースに切り替えます。
CREATE DATABASE db01; \c db01インスタンスBにdb02という名前のデータベースを作成し、db02データベースに切り替えます。
CREATE DATABASE db02; \c db02greenplum_fdwおよびgp_parallel_retrieve_cursor拡張機能をインスタンスAのdb01データベースおよびインスタンスBのdb02データベースにインストールします。詳細については、「拡張機能のインストール、更新、およびアンインストール」をご参照ください。
インスタンスAの内部IPアドレスを取得し、そのIPアドレスをインスタンスBのホワイトリストに追加します。ホワイトリストの設定方法については、「IPアドレスホワイトリストの設定」をご参照ください。
インスタンスAで次のステートメントを実行して、内部IPアドレスを取得します。
SELECT dbid, address FROM gp_segment_configuration;インスタンスBのdb02データベースでテストデータを準備します。
CREATE SCHEMA s01; CREATE TABLE s01.t1(a int, b int, c text); CREATE TABLE s01.t2(a int, b int, c text); CREATE TABLE s01.t3(a int, b int, c text); INSERT INTO s01.t1 VALUES(generate_series(1,10),generate_series(11,20),'t1'); INSERT INTO s01.t2 VALUES(generate_series(11,20),generate_series(11,20),'t2'); INSERT INTO s01.t3 VALUES(generate_series(21,30),generate_series(11,20),'t3')インスタンスaのdb01データベースにサーバーとユーザーマッピングを作成します。
サーバーを作成します。
CREATE SERVER remote_adbpg FOREIGN DATA WRAPPER greenplum_fdw OPTIONS (host 'gp-xxxxxxxx-master.gpdb.zhangbei.rds.aliyuncs.com', port '5432', dbname 'db02');下表に、各パラメーターを説明します。
パラメーター
説明
host
インスタンスBの内部エンドポイント。
AnalyticDB for PostgreSQLコンソールにログインし、インスタンスBの基本情報ページに移動して、[データベース接続情報] セクションの内部エンドポイントを表示します。
port
インスタンスBの内部ポート番号。デフォルト値:
5432。dbname
ソースデータベースの名前。 この例では、このパラメーターは
db02に設定されています。ユーザーマッピングを作成します。 ユーザーマッピングの詳細については、「ユーザーマッピングの作成」をご参照ください。
CREATE USER MAPPING FOR PUBLIC SERVER remote_adbpg OPTIONS (user 'report', password '******');下表に、各パラメーターを説明します。
パラメーター
説明
user
インスタンスBへの接続に使用されるデータベースアカウントの名前。
データベースアカウントには、db02データベースに対する読み取り権限が必要です。 INSERT操作を実行する場合は、書き込み権限も必要です。 データベースアカウントの作成方法については、「データベースアカウントの作成」をご参照ください。
password
データベースアカウントのパスワードを設定します。
インスタンスAのdb01データベースのクロスインスタンスクエリ機能を有効にします。
次のいずれかの方法を使用して、クロスインスタンスクエリ機能を有効にできます。
ソーステーブルの外部テーブルを作成します。
CREATE SCHEMA s01; CREATE FOREIGN TABLE s01.t1(a int, b int) server remote_adbpg options(schema_name 's01', table_name 't1');この方法では、以下のようなメリットとデメリットがあります。
利点: 外部テーブルのカスタムDDL構造を指定できます。 たとえば、db02データベースのt1テーブルにはa、b、cフィールドが含まれていますが、db01データベースにはaとbフィールドしか含まれていません。 この方法を使用すると、外部テーブルを作成するときにフィールドを指定できます。
短所: 各テーブルのDDL構造を知っている必要があります。 一度に複数の外部テーブルをインポートするには、長時間が必要です。
ソースデータベースのスキーマからすべてのテーブルをインポートします。
CREATE SCHEMA s01; IMPORT FOREIGN SCHEMA s01 LIMIT TO (t1, t2, t3) FROM SERVER remote_adbpg INTO s01;この方法では、以下のようなメリットとデメリットがあります。
利点: 短期間で外国のテーブルをインポートできます。 各テーブルのDDL構造を知る必要はありません。
短所: 外部テーブルには、ソースデータベースのテーブルと同じ名前とフィールドが必要です。
詳細については、「IMPORT FOREIGN SCHEMA」をご参照ください。
インスタンスAのdb01データベースからインスタンスBのdb02データベースのデータを照会します。
SELECT * FROM s01.t1;サンプル結果:
a | b | c ----+----+---- 2 | 12 | t1 3 | 13 | t1 4 | 14 | t1 7 | 17 | t1 8 | 18 | t1 1 | 11 | t1 5 | 15 | t1 6 | 16 | t1 9 | 19 | t1 10 | 20 | t1 (10 rows)
パフォーマンステスト
次の図は、ローカルクエリとクロスインスタンスクエリのTPC-Hパフォーマンステストを示しています。 テストデータセットのサイズは1テラバイトです。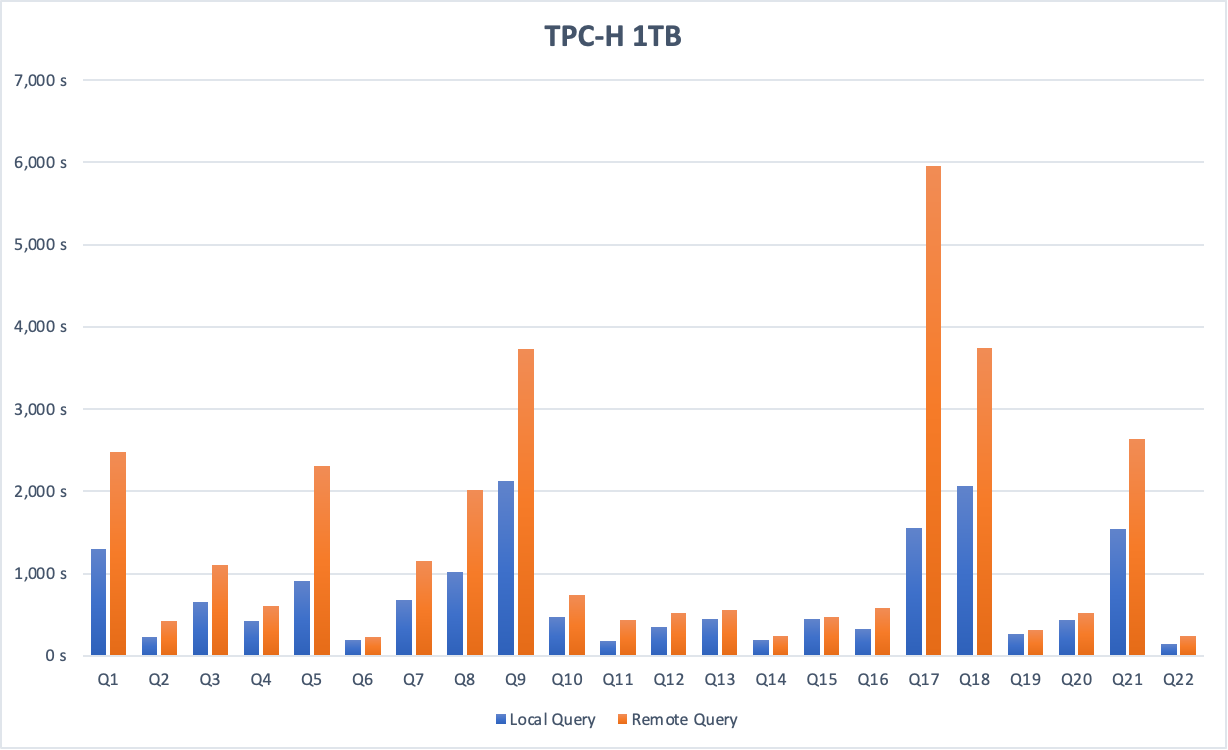
大量のデータ (この例では1テラバイト) が含まれる場合、クロスインスタンスクエリのパフォーマンスは、ローカルクエリのパフォーマンスの約半分になります。
インスタンス間でデータをクエリするには、ネットワーク間でデータを送信する必要があります。 ネットワークI/O操作を減らすために、外部テーブルのWHERE句に追加のフィルター条件を追加することをお勧めします。
関連ドキュメント
AnalyticDB for PostgreSQLは、クロスデータベースクエリ機能をサポートしています。 詳細については、「データベース間のデータの照会」をご参照ください。