このトピックでは、AnalyticDB for MySQLインポートツールを使用して、オンプレミスデータをAnalyticDB for MySQL data Warehouse Edition (V3.0) クラスターにインポートする方法について説明します。
概要
インポートツールの仕組み
AnalyticDB for MySQLインポートツールは、Java Database Connectivity (JDBC) プロトコルを使用してServer Load Balancer (SLB) インスタンスに接続します。 SLBインスタンスは、MySQLプロトコルとSQL文を解析し、データを書き込み、クエリをスケジュールする複数のフロントノードに接続されています。 データは、インポートのためにフロントノードからストレージノードに転送されます。
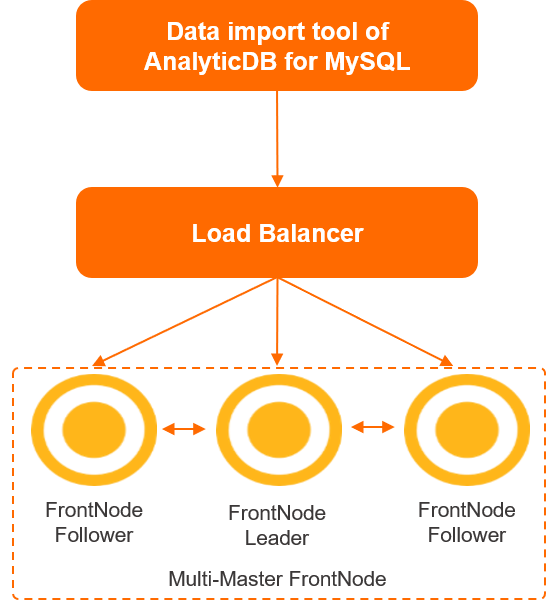
メリット
LOAD DATAステートメントと比較して、AnalyticDB for MySQLインポートツールには次の利点があります。
batchSizeや同時実行などのパラメーターを設定して、インポート速度を制御し、インポートのスループットを最大化できます。 パラメーターの詳細については、「手順3」を参照してください。 このトピックの「スクリプト」セクションを準備します。一度に1つのファイルをインポートしたり、複数のファイルやフォルダをインポートできます。 LOAD DATAステートメントを使用する場合は、複数のプロセスを開始して複数のファイルを並行してインポートする必要があります。
同時実行、バッチ処理、プーリング、非シリアル読み取りと書き込み、GCレスプログラミング、大きなブロックのシーケンシャル読み取りなどのテクノロジを使用して、パフォーマンスを向上させます。 インポートツールが適切に設定されている場合、AnalyticDB for MySQLクラスターの書き込みスループットを最大化できます。
手順
ステップ | 説明 |
AnalyticDB for MySQLインポートツールをダウンロードして解凍します。 | |
ステップ2。 インポートするデータの準備 | インポートするデータを準備します。 |
インポートテンプレートのパラメーターの値を変更して、データインポートスクリプトを準備します。 | |
インポートスクリプトを実行して、オンプレミスデータをAnalyticDB for MySQLクラスターにインポートします。 |
ステップ1: インポートツールをダウンロードして解凍する
次のコマンドを実行してディレクトリを作成します。 この例では、/u01/loadataという名前のディレクトリが作成されます。
mkdir -p /u01/loadata次のコマンドを実行してディレクトリに移動します。
# cd /u01/loadata次のコマンドを実行して、インポートツールをダウンロードします。
wget https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20220811/gpvn/adb-import-tool.tar.gz次のコマンドを実行して、インポートツールを解凍します。
tar zxvf adb-import-tool.tar.gz圧縮パッケージから次のファイルが抽出されます。
adb-import.sh.template adb-import.sh.template.md5 adb-import-tool.jar adb-import-tool.jar.md5説明java -versionコマンドを実行して、Java 1.8以降がインストールされているかどうかを確認できます。
ステップ2. インポートするデータの準備
Linuxでsplitコマンドを実行すると、大きなファイルをセグメントに分割できます。 1〜2 GBのセグメントサイズを推奨します。 ファイルを分割した後、AnalyticDB for MySQLインポートツールでセグメントを同時に読み取ることができ、インポート速度が向上します。
次のサンプル文では、filename.txtという名前の128 GBのファイルが64個のセグメントに分割されており、各セグメントのサイズは2 GBです。 AnalyticDB for MySQLインポートツールは、64個のファイルを同時に読み取ります。
# split -l$(('wc -l < filename.txt '/64 + 1)) filename.txt filename.txt.split -da 2;インポートするファイルまたはフォルダの絶対パスを確認します。
インポートするファイルの行区切り文字と列区切り文字を确认します。 区切り文字の詳細については、「ステップ3」を参照してください。 このトピックの「スクリプト」セクションを準備します。
ファイルの列が、CREATE TABLEステートメントで定義されている列と同じ順序であることを確認します。 データベースでSHOW CREATE TABLEステートメントを実行して、列の順序を確認できます。 ファイルには少なくとも2つの列が必要です。
次のコードブロックには、テーブルスキーマを定義するために使用できるサンプルステートメントが含まれています。
CREATE TABLE 'product_info' () 'id' bigint NOT NULL、「名前」varchar、「価格」10進数 (15, 2) NOT NULL ) ハッシュによる分配 ('id') INDEX_ALL='Y';有効なファイルには、次の情報が含まれます。
1 | tv | 1000.0 2 | コンピューター | 2000.0 3 | カップ | 15.8ファイルの最後の列に含まれる不要な列区切り文字には関係ありません。
たとえば、
1 | abc | 3.0と1 | abc | 3.0 |の両方が有効です。説明インポートツールは、空の文字列をデフォルトでnullとして扱います。 たとえば、ファイルに
4 | | 5.0行が含まれている場合、''文字列の代わりにnullがname列に追加されます。インポートツールは、ファイルを事前処理する必要なく、自動インクリメント列を処理できます。
ステップ3. スクリプトの準備
adb-import.sh.templateファイルは、名前を変更できるテンプレートスクリプトです。 たとえば、インポートするテーブルの名前がproduct_infoの場合、スクリプトにadb-import-product_info.shという名前を付けることができます。 テンプレートスクリプトのコピーを作成し、データインポートシナリオに基づいてパラメーター値を変更できます。
# スクリプト内のパラメータの説明#
# --------------------------------#
# 次のパラメータが必要です。# --------------------------------#
####################################
# Javaコマンドのパス。
# 注: コンソールでJavaコマンドを実行できる場合は、このパラメーターを指定する必要はありません。
####################################
java_cmd=java
####################################
# インポートツールのJARパッケージの絶対パス。
# ツールがスクリプトと同じディレクトリで実行されている場合は、このパラメーターを指定する必要はありません。
####################################
jar_path=adb-import-tool.jar
####################################
# データベース接続パラメーターを設定します。
# 注意: データベースがAnalyticDB for MySQLクラスターに作成されていることを確認します。
# encryptPasswordをtrueに設定した場合、Base64-encryptedパスワードを指定する必要があります。
####################################
host=ホスト
port=3306
user=adbuser
パスワード=pwd
データベース=dbname
encryptPassword=false
####################################
# インポートするテーブルの名前。
####################################
tableName=please_set_table_name
####################################
# インポートするファイルまたはフォルダの絶対パス。 次のいずれかの操作を実行できます。#1. 単一のファイルまたはフォルダをインポートします。
# または
#2. パスがコンマ (,) で区切られた複数のファイルをインポートします。
####################################
dataPath=please_set_data_file_path_or_dir_path
####################################
# 同时にインポートされるファイルの数。
# 注: AnalyticDB for MySQLのパフォーマンスを完全に活用するには、このパラメーターを16 ~ 96の範囲内の数値に設定することを推奨します。
####################################
並行性=64
####################################
# インポート操作が実行されたときに書き込まれる値の数。
# 注意: このパラメーターは、個々の行の長さに基づいて指定する必要があります。 AnalyticDB for MySQLのパフォーマンスを十分に活用するには、このパラメーターを1024〜4096の範囲内の数値に設定することを推奨します。
####################################
batchSize=4096
####################################
# インポートしたファイルのエンコード標準。 有効な値: UTF-8とGBK。
####################################
encoding=UTF-8
####################################
# 行の区切り文字。
# \\n文字などの印刷可能な文字と印刷不可能な文字の両方がサポートされます。
# 印刷できない文字を使用する場合は、16進表記で指定する必要があります。
* たとえば、\x0d\x06\x08\x0aはhex0d06080aとして指定する必要があります。
####################################
lineSeparator="\\n"
####################################
# 列の区切り文字。
# \\| などの印刷可能な文字と印刷不可能な文字の両方がサポートされています。
# 印刷できない文字を使用する場合は、16進表記で指定する必要があります。
* たとえば、\x07\x07はhex0707として指定する必要があります。
####################################
delimiter="\\|"
# --------------------------------#
# 次のパラメータはオプションです。# --------------------------------#
####################################
# jvmパラメーター。
####################################
jvmopts="-Xmx12G -Xms12G"
####################################
# フォルダにdataFileを設定したときに同時に読み取られるファイルの数。
####################################
maxConcurrentNumOfFilesToImport=64
####################################
# 空の文字列を2つの引用符 (") に置き換えるかどうかを指定します。
# このパラメーターをfalseに設定すると、空の文字列はnullに置き換えられます。 このパラメーターをtrueに設定すると、空の文字列は ''文字列に置き換えられます。
# デフォルト値はfalseです。 この値を使用することを推奨します。
####################################
nullAsQuotes=false
####################################
# ファイルをインポートするたびに、ターゲットテーブルの実際の行数を表示するかどうかを指定します。
# デフォルト値: false。
####################################
printRowCount=false
####################################
# 実行に失敗したときに表示されるSQL文の最大長。
# デフォルト値: 1000
####################################
failureSqlPrintLengthLimit=1000
####################################
# INSERT文を実行するかどうかを指定します。 このパラメーターをtrueに設定した場合、INSERTステートメントは表示されるだけで、実行されません。 このパラメーターをfalseに設定すると、INSERTステートメントが実行されます。
# デフォルト値: false。
####################################
disableInsertOnlyPrintSql=false
####################################
# テーブルヘッダーをスキップするかどうかを指定します。 デフォルト値:false
####################################
skipHeader=false
####################################
# INSERT文を実行したときのバッファプールのサイズ。
# これにより、クライアントのパフォーマンスを向上させるために、AnalyticDB for MySQLにデータが送信されるときにI/Oとコンピューティングが分離されます。
####################################
windowSize=128
####################################
# 列のバックスラッシュ (\) とアポストロフィ (') をエスケープするかどうかを指定します。 デフォルト値:true
# このパラメーターをtrueに設定すると、文字列の解析時にクライアントのパフォーマンスが低下する可能性があります。
# テーブルにバックスラッシュ (\) とアポストロフィ (') が存在しないことが確実な場合は、このパラメーターをfalseに設定します。
####################################
escapeSlashAndSingleQuote=true
####################################
# インポートに失敗したデータのバッチを無視するかどうかを指定します。
####################################
ignoreErrors=false
####################################
# 実行に失敗したSQL文を表示するかどうかを指定します。
####################################
printErrorSql=true
####################################
# エラーが発生し、printErrorSqlがtrueに設定されている場合にスタック情報を表示するかどうかを指定します。
####################################
printErrorStackTrace=true ステップ 4. インポートスクリプトの実行
次のコマンドを実行して、スクリプトをインポートします。
sh adb-import-product_info.sh;次のログエントリが返されると、スクリプトが実行されます。
[2021-03-13 17:50:24.730] add consumer consumer-01データインポートプロセス中、インポートツールは進行状況を通知しません。 インポートの進行状況を照会するには、次のコマンドを実行して、宛先テーブルの合計行数を照会します。
mysql > select count(*) from dbname.product_info;説明データインポートプロセス中にエラーが発生すると、インポートツールはインポート操作を直ちに終了し、失敗したSQL文の詳細を提供します。 宛先テーブルのデータが不完全です。
TRUNCATE TABLE table_nameステートメントを実行して宛先テーブルをクリアし、インポート操作を再度実行できます。DROP TABLE table_nameステートメントを実行して、ターゲットテーブルを削除し、インポート用の別のテーブルを作成することもできます。インポートが完了すると、各ファイルで読み取られた行数、各ファイルの読み取りにかかった時間、インポートの完了にかかった合計時間、およびすべてのファイルがインポートされているかどうかの情報が表示されます。 すべてのファイルをインポートすると、
すべてのインポート完了が表示されます。 そうでない場合、すべてのインポートはエラーで終了しました!というメッセージが表示されます。 インポートされた行の数を確認するには、データベースを照会します。
よくある質問
Q: ボトルネックがクライアントまたはそのサーバーに存在するかどうかを知るにはどうすればよいですか?
A: 次のコマンドを実行して、クライアントまたはそのサーバーにボトルネックが存在するかどうかを確認できます。 ボトルネックが存在する場合、ストレステスト中のデータベースのワークロードを最大化できません。
コマンド
説明
トップ
CPU使用率を表示します。
無料
メモリ使用量を表示します。
vmstat 1 1000
システム全体の負荷を表示します。
dstat -all -- disk-utilまたはiostat 1 1000
ディスクの使用率または読み取り帯域幅を表示します。
jstat -gc <pid> 1000
インポートツールのJavaガベージコレクション (GC) プロセスの詳細を表示します。 GCが頻繁に実行される場合は、
jvmoptsパラメーターを-Xmx16G -Xms16Gなどの大きな値に設定できます。Q: 単一のスクリプトを使用して複数のテーブルをインポートするにはどうすればよいですか?
A: インポートしたファイルの行区切り文字と列の区切り文字が同じ場合、
tableNameパラメーターとdataPathパラメーターの値を変更して、1つのスクリプトを使用して複数のテーブルをインポートできます。たとえば、tableNameパラメーターとdataPathパラメーターは、次の値に設定できます。
tableName=$1 dataPath=$2次のコマンドを実行してファイルをインポートします。
# sh adb-import.sh table_name001 /path/table_001 # sh adb-import.sh table_name002 /path/table_002 # sh adb-import.sh table_name003 /path/table_003Q: インポートツールをバックグラウンドで実行するにはどうすればよいですか?
A: 次のコマンドを実行して、インポートツールをバックグラウンドで実行できます。
# nohup sh adb-import.sh &インポートツールの起動後、次のコマンドを実行してログを確認できます。 エラー情報が返された場合は、返された情報に基づいてトラブルシューティングを行います。
# tail -f nohup.out次のコマンドを実行して、インポートプロセスが正常に実行されているかどうかを確認することもできます。
# ps -ef | grepインポートQ: インポートの進行中にエラーを無視するにはどうすればよいですか?
A: 次の理由によりエラーが発生する場合があります。
SQL文の実行に失敗しました。
ignoreErrorsパラメーターをtrueに設定すると、エラーを無視できます。 実行結果には、エラーが発生したファイル、開始行番号、およびfailed文が含まれます。batchSizeパラメーターが指定されている場合、障害のある行番号は開始行番号にbatchSize値を加えた値以下になります。ファイル内の列数が期待される数と一致しません。
ファイルの列数が予想される数と一致しない場合、インポートツールは現在のファイルのインポートを直ちに停止し、エラー情報を返します。 ただし、このエラーは無効なファイルが原因であるため無視されません。ファイルの有効性を手動で確認する必要があります。 この場合、次のようなエラーメッセージが返されます。
[エラー] 2021-03-22 00:46:40,444 [producer- /test2/data/lineitem.csv.split00.100-41] analyticdb.tool.ImportTool (ImportTool.java:591) -悪い行が見つかり、インポートを停止します! 16, file = /test2/data/tpch100g/lineitem.csv.split00.100, rowCount = 7, current row = 3 | 123 | 179698 | 145 | 73200.15 | 0.06 | 0.00 | R | F | 1994-02-02 | 1994-01-04 | 1994-02- 23 | なし | 空気 | 猛烈に勇敢なaccoの横 |
Q: インポートエラーの原因を絞り込むにはどうすればよいですか?
A: 次の方法を使用して、インポートエラーの原因を絞り込むことができます。
インポートが失敗すると、AnalyticDB for MySQLインポートツールはエラーログと詳細なエラー原因を返します。 最大1,000文字のSQL文を返すことができます。 制限を拡張する必要がある場合は、次のコマンドを実行し、
failureSqlPrintLengthLimitパラメーターを1500などの大きな値に設定します。printErrorSql=true failureSqlPrintLengthLimit=1500;batchSize値に基づいて何千ものSQL文が同時に実行される可能性があり、障害のある行を識別することが困難になります。 トラブルシューティングを容易にするために、次の例に示すように、batchSizeパラメーターを10などの小さな値に設定できます。batchSize=10;ファイルが分割され、障害のある行を含むセグメントが特定されている場合は、次の例に示すように、
dataPathパラメーターを指定して、障害のある行を含むセグメントをインポートできます。dataPath=/u01/this/is/the/directory/where/product_info/stores/file007;
Q: Windowsオペレーティングシステムでインポートツールを実行するにはどうすればよいですか?
A: バッチスクリプトはWindowsでは提供されていません。 JARファイルを呼び出して、次の方法でインポートスクリプトを実行できます。
使用法: java -jar adb-import-tool.jar [-a <arg>] [-b <arg>] [-B <arg>] [-c <arg>] [-D <arg>] [-d <arg>] [-E <arg>] [-f <arg>] [-h <arg>] [-I <arg>] [-k <arg>] [-l <arg>] [-m <arg>] [-n <arg>] [-N <arg>] [-O <arg>] [-o <arg>] [-p <arg>] [-P <arg>] [-Q <arg>] [-s <arg>] [-S <arg>] [-t <arg>] [-T <arg>] [-u <arg>] [-w <arg>] [-x <arg>] [-y <arg>] [-z <arg>]パラメーター
必須
説明
-h,-- ip <arg>可
AnalyticDB for MySQLクラスターのエンドポイント。
-u,-- username <arg>AnalyticDB for MySQLクラスターのデータベースアカウント。
-p,-- password <arg>AnalyticDB for MySQLクラスターのデータベースアカウントに対応するパスワード。
-P,-- port <arg>AnalyticDB for MySQLクラスターへの接続に使用されるポート番号。
-D,-- databaseName <arg>AnalyticDB for MySQLクラスターのデータベース名。
-f,-- dataFile <arg>インポートするファイルまたはフォルダーの絶対パス。 次のいずれかの操作を実行できます。
単一のファイルまたはフォルダをインポートします。
パスがコンマ (,) で区切られた複数のファイルをインポートします。
-t,-- tableName <arg>インポートするテーブルの名前。
-a,-- createEmptyFinishFilePath <arg>任意
インポートが完了したことを示すファイルを生成するかどうかを指定します。 このパラメーターのデフォルト値は空の文字列です。これは、そのようなファイルが生成されないことを示します。 そのようなファイルを生成する場合は、このパラメーターをファイル名に設定します。 たとえば、このパラメーターを
-a file_aに設定すると、-a file_aという名前のファイルが生成されます。-b,-- batchSize <arg>INSERT INTO tablename values (..),(..)ステートメントに同時に書き込まれる値の数。 デフォルト値は 1 です。説明インポート速度とシステムパフォーマンスのバランスをとるために、このパラメーターを1024〜4096の範囲内の数値に設定することを推奨します。
-B,-- encryptPassword <arg>データベースアカウントのパスワードを暗号化するかどうかを指定します。 デフォルト値:false
-c,-- printRowCount <arg>ファイルをインポートするたびに、ターゲットテーブルの実際の行数を表示するかどうかを指定します。 デフォルト値:false
-d,-- skipHeader <arg>テーブルヘッダーをスキップするかどうかを指定します。 デフォルト値:false
-E,-- escapeSlashAndSingleQuote <arg>列のバックスラッシュ (
\) とアポストロフィ (') をエスケープするかどうかを指定します。 デフォルト値:true説明このパラメーターをtrueに設定すると、文字列の解析時にクライアントのパフォーマンスが低下する可能性があります。 テーブルにバックスラッシュ (\) またはアポストロフィ (') が存在しないことが確実な場合は、このパラメーターをfalseに設定します。
-I,-- ignoreErrors <arg>インポートに失敗したデータのバッチを無視するかどうかを指定します。 デフォルト値:false
-k,-- skipLineNum <arg>スキップされた行の数。 このパラメーターの目的は、
IGNORE number {LINES | ROWS}パラメーターの目的と同様です。 このパラメーターのデフォルト値は0で、行がスキップされないことを示します。-l,-- delimiter <arg>列の区切り文字。 デフォルトでは、AnalyticDB for MySQLの列区切り文字として
\\|が使用されます。 列区切り文字として印刷できない文字を使用することもできます。 印刷できない文字を使用する場合は、16進表記で指定する必要があります。 たとえば、\x07\x07はhex0707として指定する必要があります。-m,-- maxConcurrentNumOfFilesToImport <arg>フォルダにdataFileが設定されているときに同時に読み取られるファイルの数。 このパラメーターのデフォルト値は
Integer.MAX_VALUEで、すべてのファイルが同時に読み取られることを示します。-n,-- nullAsQuotes <arg>| |を''に置き換えるかどうかを指定します。 デフォルト値:false このパラメーターをfalseに設定すると、| |は''ではなくnullに置き換えられます。-N,-- printErrorSql <arg>実行に失敗したSQL文を表示するかどうかを指定します。 デフォルト値:true
-O,-- connectionPoolSize <arg>AnalyticDB for MySQLデータベース接続プールのサイズ。 デフォルト値:2
-o,-- encoding <arg>インポートしたファイルのエンコード標準。 有効な値: GBKおよびUTF-8。 デフォルト値は UTF-8 です。
-Q,-- disableInsertOnlyPrintSql <arg>INSERTステートメントを実行するかどうかを指定します。 このパラメーターをtrueに設定した場合、INSERTステートメントは表示されるだけで、実行されません。 このパラメーターをfalseに設定すると、INSERTステートメントが実行されます。 デフォルト値:false
-s,-- lineSeparator <arg>行の区切り文字。 デフォルトでは、AnalyticDB for MySQLの行区切り文字として
\\nが使用されます。 列区切り文字として印刷できない文字を使用することもできます。 印刷できない文字を使用する場合は、16進表記で指定する必要があります。 たとえば、\x0d\x06\x08\x0aはhex0d06080aとして指定する必要があります。-S,-- printErrorStackTrace <arg>エラーが発生し、
printErrorSqlがtrueに設定されている場合にスタック情報を表示するかどうかを指定します。デフォルト値: false。-w,-- windowSize <arg>INSERT文が実行されたときのバッファプールのサイズ。 これにより、データがAnalyticDB for MySQLに送信されると、I/Oとコンピューティングが分離され、すべての手順が高速化され、クライアントのパフォーマンスが向上します。 デフォルト値: 128
-x,-- insertWithColumnNames <arg>INSERT INTOステートメントの実行時に列名を追加するかどうかを指定します。 たとえば、INSERT INTO tb(column1, column2)文を実行すると、データをインポートできます。 デフォルト値:true-y,-- failureSqlPrintLengthLimit <arg>INSERT文の実行に失敗したときに表示されるSQL文の最大長。 デフォルト値は 1000 です。
-z,-- connectionUrlParam <arg>データベース接続パラメーターの設定。 デフォルト値:
? characterEncoding=utf-8.例:
? characterEncoding=utf-8&autoReconnect=true.例1: 次のコマンドでは、デフォルトのパラメーター設定を使用して単一のファイルをインポートします。
java -Xmx8G -Xms8G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest -- dataFile /data/lineitem.sample -- tableName LINEITEM例2: 次のコマンドでは、関連するパラメーターの値を変更して、最大スループットでフォルダーのすべてのファイルをインポートします。
java -Xmx16G -Xms16G -jar adb-import-tool.jar -hyourhost.ads.aliyuncs.com -uadbuser -ppassword -P3306 -Dtest -- dataFile /data/tpch100g -- tableName LINEITEM-並行性64 -- batchSize 2048