AnalyticDB for MySQLクラスターのフロントエンドアクセスノードがクエリリクエストを受信した後、クラスターはクエリを複数のステージに分割し、ワーカーノードとエグゼキューターノードで分散してデータを読み取り、計算します。 一部のステージは並列に実行できますが、依存関係を持つ他のステージは直列にのみ実行できます。 その結果、複雑なSQL文は遅いクエリ問題を引き起こす可能性があります。 ステージとタスクの詳細を使用して、API操作を呼び出すか、AnalyticDB for MySQLコンソールで問題を分析できます。 このトピックでは、ステージとタスクの詳細を使用してクエリを分析する方法について説明します。
手順
AnalyticDB for MySQL コンソールにログインします。 ホームページの左上でリージョンを選択します。 左側のナビゲーションウィンドウで、クラスターリスト をクリックします。 クラスターリスト ページで、エディションタブをクリックします。 管理するクラスターを確認し、クラスター ID をクリックします。
左側のナビゲーションウィンドウで、[診断と最適化] をクリックします。
[SQLクエリ] タブで、診断するクエリを見つけ、[操作] 列の [診断] をクリックします。
[ステージとタスク] タブをクリックして、ステージの詳細を表示します。 ステージクエリの結果については、このトピックの「ステージパラメーター」を参照してください。
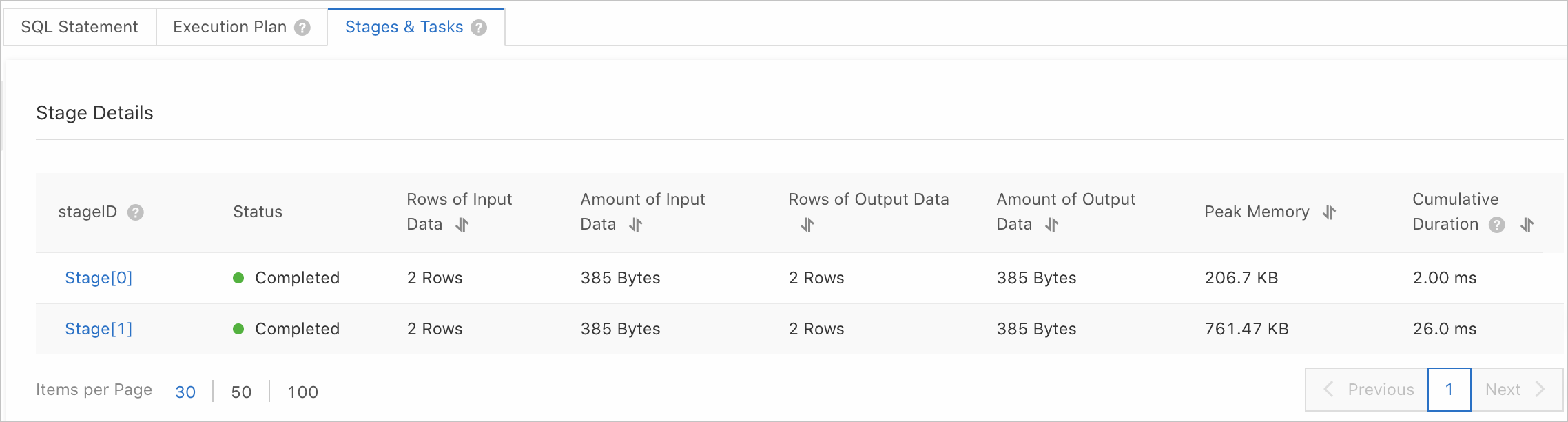
ステージIDをクリックして、ステージ内のすべてのタスクの詳細を表示します。 タスククエリ結果の詳細については、このトピックの「タスクパラメーター」を参照してください。
重要タスクの詳細は、1秒を超えるクエリに対してのみ表示できます。
パラメーター
ステージパラメータ
パラメーター | 説明 |
ステージID | ステージの一意の識別子。実行プランツリーのステージIDに対応します。 |
Status | ステージの実行ステータス。 有効な値:
|
入力データの行 | ステージに入力されるデータ行の数。 |
入力データの量 | ステージに入力されるデータの量。 |
出力データの行 | ステージから出力されるデータ行の数。 |
出力データの量 | ステージから出力されるデータの量。 |
ピークメモリ | ステージのピークメモリ使用量。 |
累積期間 | ステージ内のすべての演算子を実行するために消費される合計時間。 このパラメーターを使用して、実行に時間がかかり、大量のCPUリソースを消費するステージを特定できます。 累積期間とクエリ期間を比較するときは、ステージの同時実行性を考慮する必要があります。 |
タスクパラメーター
パラメーター | 説明 |
タスク ID | タスクの一意の識別子。 例: |
Status | タスクの実行ステータス。 有効な値:
|
入力データの量 | タスクに入力されるデータ行数と入力データ量。 すべてのタスクの入力データ量を並べ替えて、ステージの入力データにデータスキューが発生していないかを確認できます。 データスキューは、GROUP句またはJOIN句の不適切なフィールド設定によって引き起こされる可能性があります。 この問題を解決するには、現在のタスクが属するステージの上流ステージまでトレースします。 説明 指定された配布フィールドが不適切な場合、ワーカーノード間でデータが不均等に配布される可能性があります。 これをデータスキューと呼ぶ。 |
出力データの量 | タスクから出力されるデータ行数と出力データ量。 現在のステージの演算子プランツリーの [集約] ノードまたは [結合] ノードの属性に基づいて、SQL文の [GROUP] 句または [JOIN] 句に結合フィールドが存在するかどうかを確認できます。 たとえば、 |
ピークメモリ | タスクのピークメモリ使用量。 ピークメモリは、入力データの量に比例する。 このパラメーターを使用して、クエリの失敗が入力データの不均衡な分散によるものかどうかを確認できます。 |
テーブルデータの読み取り期間 | ステージのすべてのTableScan演算子がテーブルデータを読み取るために消費した累積時間。 このパラメーターは、複数のノードとスレッドを含む累積値であり、クエリ期間と比較することはできません。 このパラメーターを累積期間と比較すると、データスキャンに費やされるステージのコンピューティングリソースの数を判断できます。 |
テーブルデータの読み取り量 | ステージのすべてのTableScan演算子によって読み取られるデータ行数とデータ量。 すべてのタスクの読み取りテーブルデータの量をソートして、ソーステーブルデータでデータスキューが発生していないかどうかを確認できます。 データスキューが発生した場合は、AnalyticDB for MySQLコンソールの配布フィールドが原因であるかどうかを確認できます。 詳細については、「データモデリング診断」をご参照ください。 |
作成日時 | タスクが作成された時刻。 |
キュー期間 | タスクの実行前のキュー時間。 |
終了時間 | タスクが終了した時刻。 |
開始時間と終了時間の間隔 | タスクの作成時刻と終了時刻の間隔。 たとえば、タスクが2022-12-12 12:00:00に作成され、2022-12-12 12:00:04に終了する場合、開始および終了の時間間隔は4秒です。 このパラメーターをクエリ期間と比較すると、実行が遅い主な原因を特定できます。 たとえば、クエリの期間が6秒で、開始時間と終了時間の間隔が4秒の場合、現在のステージがクエリの実行に時間がかかった主な理由です。 詳細については、このトピックの「タスク期間と同時実行性の計算の例」をご参照ください。 |
累積期間 | ステージ内のすべてのタスクのすべてのスレッドが消費した合計時間。 詳細については、このトピックの「タスク期間と同時実行性の計算の例」をご参照ください。 |
計算時間比 | サブタスクのライフサイクルに対するデータ計算時間の比率。 このパラメータは、次の式を使用して計算できます。計算時間比=(累積期間 /サブタスク同時実行) /開始時間と終了時間の間の間隔。 この式で、(累積期間 /サブタスク同時実行) は、各スレッドがデータを計算するために消費する平均時間を示します。 開始および終了時間間隔は、実際のデータ計算時間、サブタスク待ち行列期間、およびネットワーク待ち時間を含む。 詳細については、このトピックの「タスク期間と同時実行性の計算の例」をご参照ください。 説明 開始および終了時間間隔が長いほど、計算時間の比率は小さくなる。 この場合、長時間を消費する演算子を特定する必要があります。 開始および終了時間間隔が短いほど、計算時間の比率が大きくなる。 この場合、キューイングやネットワーク遅延などの問題に集中する必要があります。 |
サブタスクの同時実行 | ノードでタスクを同時に実行するスレッドの数。 詳細については、このトピックの「タスク期間と同時実行性の計算の例」をご参照ください。 |
実行ノード | タスクが実行されるノードのIPアドレス。 同じノードで複数のクエリに対してロングテールの問題が発生した場合は、このノードを確認する必要があります。 説明 AnalyticDB for MySQLのロングテールの問題とは、一部のタスクが他のタスクよりも実行に時間がかかる状況を指します。 |
タスク期間と同時実行の計算例
この例では、タスク2.1の開始および終了時間間隔、累積期間、計算時間比、およびサブタスク同時実行性が計算されます。
タスク2.1はステージ2に属します。 ステージ2は、StageOutput、Join、TableScan、RemoteSourceの4つの演算子で構成されているとします。 次の図は、ステージ2の演算子ツリー図を示しています。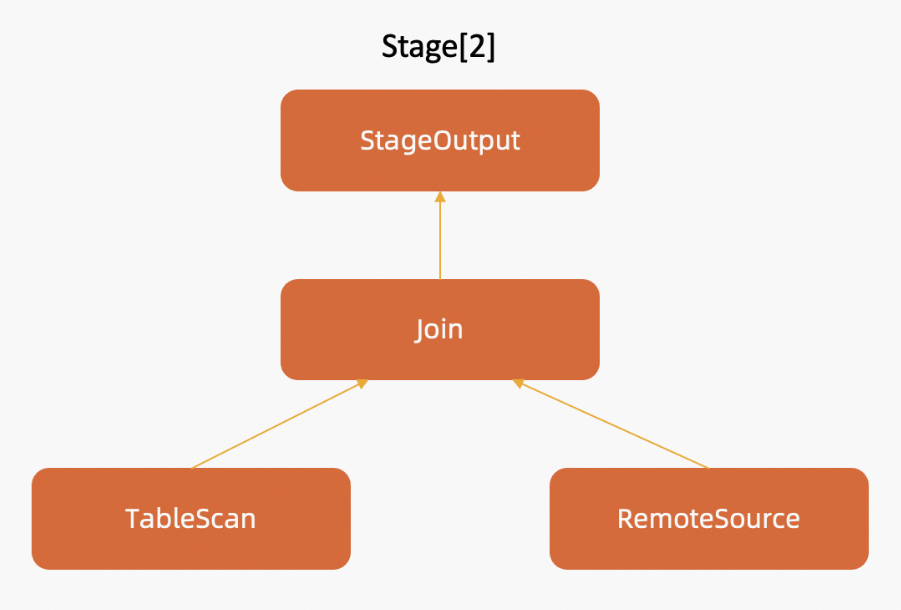
これらの演算子は、矢印の方向に複数のノードで同時に実行されます。 IPアドレスが192.168.12.23のノードで、タスク2.1は4つの同時スレッドで実行されます。 次の図に示すように、4つのスレッドはそれぞれ5、5、6、6秒を消費してデータを計算します。
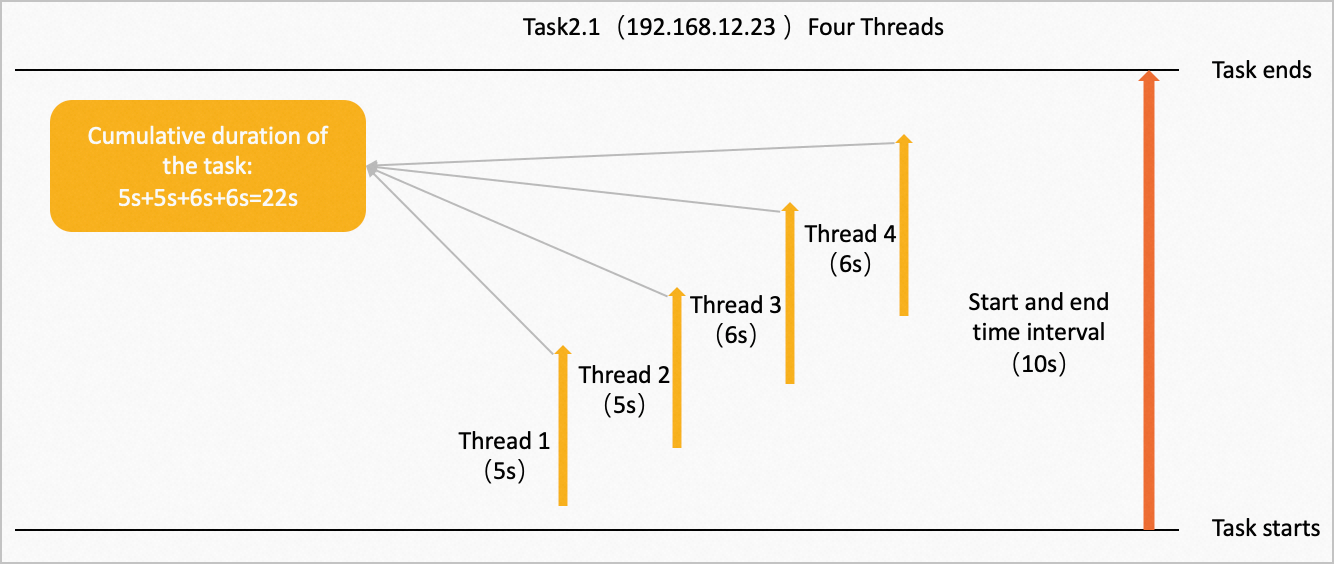
タスクの累積期間: 5s + 5s + 6s + 6s = 22s。
開始および終了時間間隔: 10秒。
計算時間比 :( 22s/4)/10s = 0.55。
関連する API 操作
API 操作 | 説明 |
SQL文の実行情報を照会します。 | |
クエリのステージで分散タスクに関する実行情報を照会します。 |