このトピックでは、AnalyticDB for MySQLのグループ化および集計クエリを最適化する方法について説明します。
グループ化と集約プロセス
AnalyticDB for MySQLは、分散データウェアハウスサービスです。 デフォルトでは、AnalyticDB for MySQLは次の手順を実行して、グループ化および集約クエリを実行します。
データの部分集計を実行します。
部分集約ノードは、少量のメモリしか使用しない。 集約プロセスはストリームベースであり、部分的な集約ノードにデータが積み重なるのを防ぎます。
部分集約が完了したら、GROUP BYフィールドに基づいてノード間でデータを再分配し、最終集約を実行します。
部分的な集約結果は、ネットワークを介して下流段のノードに送信される。 詳細については、「クエリパフォーマンスに影響を与える要因」をご参照ください。 部分集約は、ネットワークを介して送信される必要があるデータの量を低減する。 その結果、ネットワークの圧力が低減される。 データが再分配された後、最終的な集約が実行される。 最後の集約ノードでは、すべてのデータが処理されるまで、グループの値と集約状態データをメモリに保持する必要があります。 これにより、特定のグループ値に対して新しいデータを処理する必要がなくなります。 この場合、最終的なアグリゲーションノードは、大量のメモリを占有し得る。
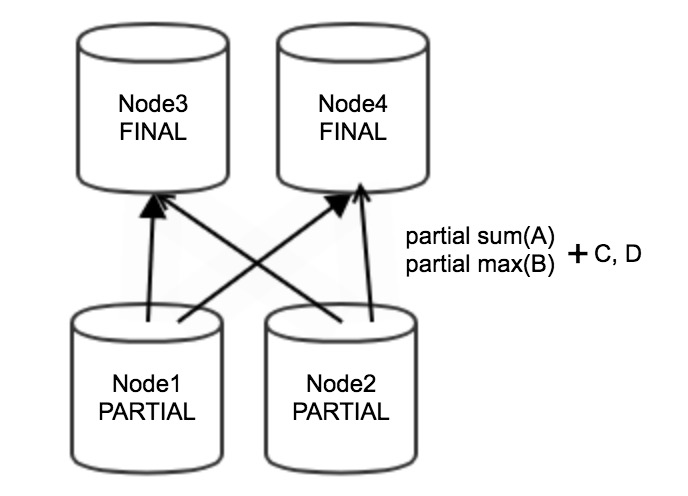
たとえば、次のSQL文を実行して、グループ化と集計を実行します。
SELECT sum(A), max(B) FROM tb1 GROUP BY C,D;上記の文を実行してグループ化と集約を行う場合、まず上流段のノード1とノード2で部分集約が行われます。 部分集約結果は、部分和 (A) 、部分max(B) 、C、およびDである。次の図に示すように、部分集約結果は、最終集約のために、ネットワークを介して下流段のノード3およびノード4に送信される。
ヒントを使用してグループ化と集約を最適化する
シナリオ
ほとんどのシナリオでは、2段階の集約でメモリとネットワークリソースのバランスが取れます。 ただし、GROUP BYフィールドに多数の一意の値が含まれる特殊なシナリオでは、2ステップの集計が最良の選択ではない場合があります。
たとえば、携帯電話番号またはユーザーIDでデータをグループ化します。 2段階の集計方法を使用すると、少量のデータしか集計できませんが、部分的な集計ステップは、グループのハッシュ値の計算、重複排除、集計関数の実行など、複数の操作で実行されます。 この例では、多数のグループが含まれる。 その結果、部分的な集約ステップは、ネットワークを介して送信されるデータの量を低減しないが、大量のコンピューティングリソースを消費する。
解決策
前述の低い集計率の問題を解決するには、
/* + aggregation_path_type=single_agg */ヒントを追加して、部分的な集計をスキップし、クエリの実行時に最終的な集計を直接実行します。 これにより、不要なコンピューティングオーバーヘッドが削減されます。説明/* + aggregation_path_type=single_agg */ヒントがSQL文で使用されている場合、SQL文のすべてのグループ化および集計クエリは指定された最適化プロセスを使用します。 元の実行計画で集計演算子の特性を分析し、ヒントの利点を評価してから、この最適化スキームを使用するかどうかを決定することをお勧めします。最適化の説明
集約レートが低い場合、上流ステージのノード1およびノード2上で実行される部分集約は、ネットワークを介して送信されるデータの量を低減させないが、大量のコンピューティングリソースを消費する。
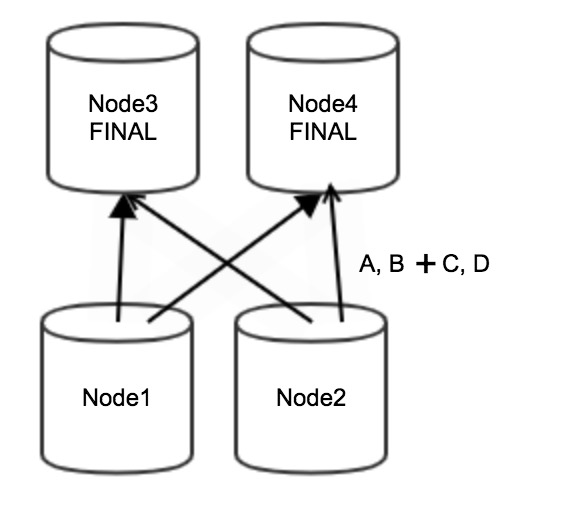
最適化後、部分集約はノード1とノード2で実行されません。 次の図に示すように、すべてのデータ (A、B、C、およびD) は、下流段のノード3およびノード4に直接集約されます。これにより、必要なコンピューティングリソースの量が削減されます。
 説明
説明この最適化は、メモリ使用を最適化しない。 集約率が低い場合、重複排除と集約のために大量のデータがメモリに蓄積され、特定のグループ値のすべてのデータが処理されるようになります。