AnalyticDB for MySQLでは、外部テーブルを使用してデータをインポートおよびエクスポートできます。 このトピックでは、外部テーブルを使用してAnalyticDB for MySQL data Warehouse Edition (V3.0) からApsara File Storage for HDFSにデータをエクスポートする方法について説明します。
前提条件
AnalyticDB for MySQLクラスターはV3.1.4.4以降を実行します。
説明クラスターのマイナーバージョンをクエリする方法については、AnalyticDB for MySQLクラスターのバージョンを照会するにはどうすればよいですか? クラスターのマイナーバージョンを更新するには、テクニカルサポートにお問い合わせください。
Apsara File Storage for HDFSクラスターが作成され、インポートされたAnalyticDB for MySQLデータを保存するフォルダーがクラスターに作成されます。 この例では、フォルダ名はhdfs_output_test_csv_dataです。
説明INSERT OVERWRITE文を使用してデータをインポートすると、保存先フォルダ内の既存のファイルが上書きされます。 既存のファイルが上書きされないように、データのエクスポート時に別の保存先フォルダを作成することをお勧めします。Apsara File Storage for HDFSクラスターでは、AnalyticDB for MySQLクラスターの次のサービスアクセスポートが設定されています。
namenode: ファイルシステムのメタデータの読み取りと書き込みに使用されます。 fs.de faultFSパラメーターを使用して、ポート番号を設定できます。 デフォルトのポート番号は8020です。詳細な設定については、「core-default.xml」をご参照ください。
datanode: データの読み取りと書き込みに使用されます。 dfs.datanode.addressパラメーターを使用して、ポート番号を設定できます。 デフォルトのポート番号は50010です。詳細な設定については、「hdfs-default.xml」をご参照ください。
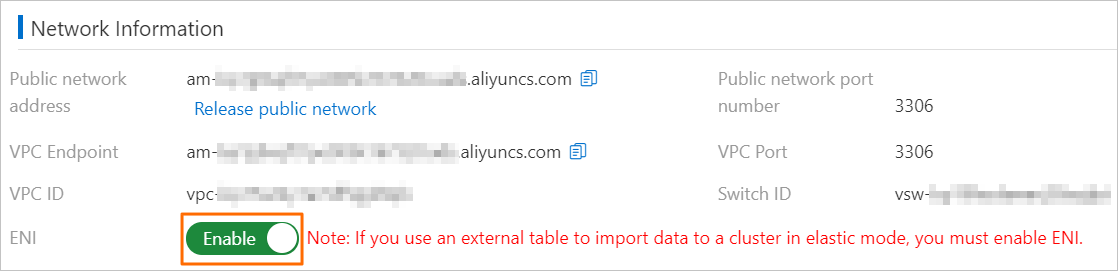
AnalyticDB for MySQLクラスターがエラスティックモードの場合、クラスター情報 ページの ネットワーク情報 セクションでEniネットワークをオンにする必要があります。
使用上の注意
AnalyticDB for MySQLクラスターからApsara File Storage for HDFSクラスターにエクスポートできるのは、CSVファイルとParquetファイルのみです。 ORCファイルはエクスポートできません。
AnalyticDB for MySQLは、
INSERT INTO VALUESやREPLACE INTO VALUESなど、行ごとに外部テーブルにデータを挿入するために使用されるinsert構文をサポートしていません。パーティション化された外部テーブルを使用して、個々のファイルをAnalyticDB for MySQLからApsara File Storage for HDFSにエクスポートすることはできません。
パーティション化された外部テーブルからデータをエクスポートする場合、データファイルにはパーティション列のデータは含まれません。 パーティション列のデータは、Apsara File Storage for HDFSディレクトリの形式で表示されます。
たとえば、3つの通常列と2つのパーティション列がパーティション外部テーブルに定義されています。 第1レベルのパーティション列の名前は
p1、列の値は1です。 第2レベルのパーティション列の名前はp2で、列の値はaです。 パーティション化された外部テーブルを使用して、Apsara File Storage for HDFSクラスターのadb_data/ ディレクトリにデータをエクスポートする必要があります。p1が1に設定され、p2がaに設定されている場合、データがエクスポートされる相対パスはadb_data/p1=1/p2=a/ です。 エクスポートされたCSVファイルまたはParquetファイルには、通常の3つの列の値のみが含まれ、p1列とp2列の値は含まれません。
手順
AnalyticDB for MySQLクラスターに接続します。 詳細については、「AnalyticDB For MySQLクラスターへの接続」をご参照ください。
- ソースデータベースを作成します。 詳細については、「データベースの作成」をご参照ください。
この例では、
adb_demoという名前のデータベースがAnalyticDB for MySQLクラスターのソースデータベースとして使用されています。 ソーステーブルを作成し、ソーステーブルにデータを挿入します。
次のステートメントを実行して、
adb_demoソースデータベースにadb_hdfs_import_sourceという名前のソーステーブルを作成します。が存在しない場合はテーブルを作成しますadb_hdfs_import_source ( uid文字列、 その他の文字列 ) ハッシュによって分布 (uid);次のステートメントを実行して、テストデータの行を
adb_hdfs_import_sourceテーブルに挿入します。INSERT INTO adb_hdfs_import_source VALUES ("1", "a"), ("2", "b"), ("3", "c");外部テーブルを作成します。
次の構文を使用して、
adb_demoソースデータベースに外部テーブルを作成できます。 このテーブルは、AnalyticDB for MySQLデータをApsara File Storage for HDFSにエクスポートするために使用されます。次のステートメントを実行して、標準の外部テーブルを作成します。 この例では、ターゲットテーブルの名前は
hdfs_import_externalです。が存在しない場合はテーブルを作成しますhdfs_import_external ( uid文字列、 その他の文字列 ) エンジン='HDFS' TABLE_PROPERTIES='{ "format":"csv" 、 "delimiter":",", "hdfs_url":"hdfs:// 172.17。***:9000/adb/hdfs_output_test_csv_data" } ';次のステートメントを実行して、パーティション化外部テーブルを作成します。 ステートメントには、通常の列 (
uidやotherなど) とパーティション列 (p1、p2、p3など) を定義する必要があります。 この例では、ターゲットテーブルの名前はhdfs_import_external_parです。が存在しない場合はテーブルを作成しますhdfs_import_external_par ( uid文字列、 その他の文字列、 p1日付、 p2 int, p3 varchar ) エンジン='HDFS' TABLE_PROPERTIES='{ "format":"csv" 、 "delimiter":",", "hdfs_url":"hdfs:// 172.17。***:9000/adb/hdfs_output_test_csv_data" "partition_column":"p1, p2, p3" } ';
説明AnalyticDB for MySQLクラスターからApsara File Storage for HDFSクラスターにエクスポートできるのは、CSVファイルとParquetファイルのみです。 ORCファイルはエクスポートできません。
外部テーブルを作成するための詳細な構文については、「data Warehouse Editionにデータをインポートする外部テーブルを使用する」トピックの「HDFS外部テーブル用のApsaraファイルストレージの作成」および「HDFS外部テーブル用のパーティション分割Apsaraファイルストレージの作成」をご参照ください。
ソースデータをAnalyticDB for MySQLクラスターからApsara File Storage for HDFSにエクスポートします。
標準外部テーブルを使用してデータをエクスポートする構文の詳細については、このトピックの「付録1: 標準外部テーブルを使用してデータをエクスポートする構文」を参照してください。
パーティション化外部テーブルを使用してデータをエクスポートする構文の詳細については、このトピックの「付録2: パーティション化外部テーブルを使用してデータをエクスポートする構文」を参照してください。
次のステップ
データがエクスポートされた後、Hadoopクライアントを使用して、エクスポートされたデータをhdfs_output_test_csv_dataの保存先フォルダーに表示できます。 AnalyticDB for MySQLクラスターに接続し、次のステートメントを実行して、外部テーブルを使用してエクスポートされたデータを照会することもできます。 クエリ構文は、パーティション化された外部テーブルと標準の外部テーブルで同じです。 この例では、hdfs_import_external標準外部テーブルが使用されます。
SELECT * からhdfs_import_external LIMIT 100;付録1: 標準の外部テーブルを使用してデータをエクスポートする構文
外部テーブルの作成時にパーティション列が指定されていない場合は、次のいずれかの方法でデータをエクスポートできます。
方法1: 宛先テーブルに既にデータが含まれている場合、
INSERT INTOステートメントを使用してデータを外部テーブルにインポートします。 このステートメントを使用してソーステーブルからApsara File Storage for HDFSフォルダにデータを書き込むたびに、新しいApsara File Storage for HDFSファイルが生成されます。説明エクスポートする列はすべて外部テーブルに書き込む必要があります。
INSERT INTOは、既存のファイルを上書きせずに新しいファイルを生成します。構文:
<target_table> に挿入 SELECT <col_name> <source_table>;例:
hdfs_import_externalに挿入 SELECT col1, col2, col3からadb_hdfs_import_source;説明col1、col2、col3は、外部テーブルのすべての列を示します。方法2: Apsara File Storage for HDFSの外部テーブルでプライマリキーを定義することはできません。
REPLACE INTOとINSERT INTOは完全に同等です。 どちらもデータを外部テーブルにレプリケートします。 宛先テーブルにすでにデータが含まれている場合、REPLACE INTOステートメントを実行してデータをインポートすると、既存のデータは変更されず、新しいデータが宛先ファイルに追加されます。説明エクスポートする列はすべて外部テーブルに書き込む必要があります。 書き込む特定の列を指定することはできません。
REPLACE INTOは、既存のファイルを上書きせずに新しいファイルを生成します。
構文:
<target_table> への置き換え SELECT <col_name> <source_table>;例:
hdfs_import_externalへの交換 SELECT col1, col2, col3からadb_hdfs_import_source;方法3:
insert OVERWRITEステートメントを使用して、外部テーブルにデータを一括挿入します。 移行先の外部テーブルにすでにデータが含まれている場合、新しいApsara File Storage for HDFSファイルが生成される前に、外部テーブルパス内のすべてのファイルが削除されます。重要エクスポートする列はすべて外部テーブルに書き込む必要があります。 書き込む特定の列を指定することはできません。
INSERT OVERWRITEは、ディレクトリ内の既存のデータを上書きします。 作業は慎重に行ってください。
構文:
INSERT OVERWRITE <target_table> SELECT <col_name> <source_table>;例:
挿入上書きhdfs_import_external SELECT col1, col2, col3からadb_hdfs_import_source;方法4:
INSERT OVERWRITEステートメントを非同期実行してデータをエクスポートします。 構文:SUBMITジョブINSERT OVERWRITE <target_table> SELECT <col_name> <source_table>;例:
ジョブの挿入を上書き送信hdfs_import_external SELECT col1, col2, col3からadb_hdfs_import_source;次の応答が返されます。
+ --------------------------------------- + | job_id | + --------------------------------------- + | 2020112122202917203100908203303 ****** | + --------------------------------------- +job_idの値に基づいて、非同期タスクの状態を確認することもできます。 詳細については、「インポートタスクの非同期送信」をご参照ください。
付録2: パーティション化された外部テーブルを使用してデータをエクスポートする構文
パーティション化された外部テーブルを使用してデータをエクスポートする場合は、PARTITIONフィールドを構文に追加する必要があります。 partitionフィールドでパーティション列とパーティション値を指定して、静的パーティションと動的パーティションのどちらを使用するかを決定することもできます。
方法1:
INSERT INTO PARTITION文を使用して、パーティション化された外部テーブルにデータをバッチ挿入します。説明データを書き込むと、対応する列にデータが追加されます。 データを書き込むたびに、新しいApsara File Storage for HDFSファイルが生成され、既存のデータは上書きされません。 エクスポートする列はすべて外部テーブルに書き込む必要があります。 書き込む特定の列を指定することはできません。
完全に静的なパーティション
構文:
INSERT INTO <target_table> PARTITION(par1=val1,par2=val2,...) SELECT <col_name> <source_table>;例:
INSERT INTO hdfs_import_external_par PARTITION(p1='2021-05-06 '、p2=1、p3='test') SELECT col1, col2, col3, FROM adb_hdfs_import_source;静的動的パーティション
説明静的パーティションは、動的パーティションの前に配置する必要があります。 シーケンスを変更することはできません。
構文:
INSERT INTO <target_table> PARTITION(par1=val1,par2,...) SELECT <col_name> <source_table>;例:
INSERT INTO hdfs_import_external_par PARTITION(p1='2021-05-27 ',p2,p3) SELECT col1, col2, col3, FROM adb_hdfs_import_source;完全に動的なパーティション (
partitionフィールドを必要としないパーティション)構文:
<target_table> に挿入 SELECT <col_name> <source_table>;例:
はhdfs_import_external_parに挿入します SELECT col1, col2, col3, FROM adb_hdfs_import_source;
方法2: Apsara File Storage for HDFSの外部テーブルでプライマリキーを定義することはできません。
REPLACE INTO PARTITIONとINSERT INTO PARTITIONは完全に同等です。説明エクスポートする列はすべて外部テーブルに書き込む必要があります。 書き込む特定の列を指定することはできません。
REPLACE INTO PARTITIONは、既存のファイルを上書きせずに新しいファイルを生成します。構文:
完全に静的なパーティション
構文:
REPLACE INTO <target_table> PARTITION(par1=val1,par2=val2,...) SELECT <col_name> <source_table>;例:
への置き換えhdfs_import_external_par PARTITION(p1='2021-05-06 '、p2=1、p3='test') SELECT col1, col2, col3, FROM adb_hdfs_import_source;静的動的パーティション
説明静的パーティションは、動的パーティションの前に配置する必要があります。 シーケンスを変更することはできません。
構文:
REPLACE INTO <target_table> PARTITION(par1=val1,par2,...) SELECT <col_name> <source_table>;例:
への置き換えhdfs_import_external_par PARTITION(p1='2021-05-06 ',p2,p3) SELECT col1, col2, col3, FROM adb_hdfs_import_source;完全に動的なパーティション (
partitionフィールドを必要としないパーティション)構文:
<target_table> への置き換え SELECT <col_name> <source_table>;例:
hdfs_import_external_parへの交換 SELECT col1, col2, col3, FROM adb_hdfs_import_source;
方法3:
INSERT OVERWRITE PARTITIONステートメントは、INSERT INTO PARTITIONステートメントと同じ方法で使用できます。 ただし、INSERT OVERWRITE PARTITIONステートメントを実行すると、移行先パーティションの既存のデータが上書きされます。 新しいデータがパーティションに書き込まれない場合、既存のデータはクリアされません。構文:
INSERT OVERWRITE <target_table> PARTITION(par1=val1,par2=val2,...)[IF NOT EXISTS] SELECT <col_name> <source_table>;重要エクスポートする列はすべて外部テーブルに書き込む必要があります。 書き込む特定の列を指定することはできません。
INSERT OVERWRITE PARTITIONは、ディレクトリ内の既存のデータを上書きします。 作業は慎重に行ってください。IF NOT EXISTS: 外部テーブルにパーティションがある場合、データがこのパーティションにインポートされないことを示します。
例:
INSERT OVERWRITE hdfs_import_external_par PARTITION(p1='2021-05-06 '、p2=1、p3='test') 存在しない場合 SELECT col1, col2, col3からadb_hdfs_import_source;方法4:
INSERT OVERWRITEステートメントを非同期実行してデータをエクスポートします。 構文:ジョブ挿入の上書きを送信 <target_table> SELECT <col_name> <source_table>;例:
ジョブ挿入の上書きを送信hdfs_import_external_par PARTITION(p1='2021-05-06 '、p2=1、p3='test') 存在しない場合 SELECT col1, col2, col3からadb_hdfs_import_source;次の応答が返されます。
+ --------------------------------------- + | job_id | + --------------------------------------- + | 2020112122202917203100908203303 ****** | + --------------------------------------- +job_idの値に基づいて、非同期タスクの状態を確認することもできます。 詳細については、「インポートタスクの非同期送信」をご参照ください。