XUANWU分析ストレージエンジンは、信頼性が高く、可用性の高いエンタープライズクラスのデータストレージ機能を高性能で低コストで提供します。 これにより、AnalyticDB for MySQLは、高スループットのリアルタイムデータ書き込みと高性能のリアルタイムクエリを実装できます。
XUANWU分析ストレージエンジン (XUANWU)
高スループットリアルタイムデータ書き込み
AnalyticDB for MySQLは、3層アーキテクチャを使用して高スループット機能を提供します。 アクセスノード層、ストレージノード層、および永続的分散ストレージ層は、並列にスケールアウトすることができる。 AnalyticDB for MySQLは、ハイスループット、高並行性、リアルタイムデータ書き込みを実装するために、ハイブリッド行と列ストレージ形式と増分データの非同期移行をサポートしています。
AnalyticDB for MySQLは、Raftコンセンサスプロトコルとapplyメソッドを使用してデータを同期的に書き込みます。 これにより、データの書き込み直後にデータをクエリでき、書き込みの一貫性が確保されます。 XUANWUエンジンは、mark-for-deleteテクノロジを使用して、データをリアルタイムで高スループットで更新および削除できます。また、マルチバージョン同時実行制御 (MVCC) テクノロジを使用して、データの原子性と整合性を確保します。

ハイブリッド行列ストレージ
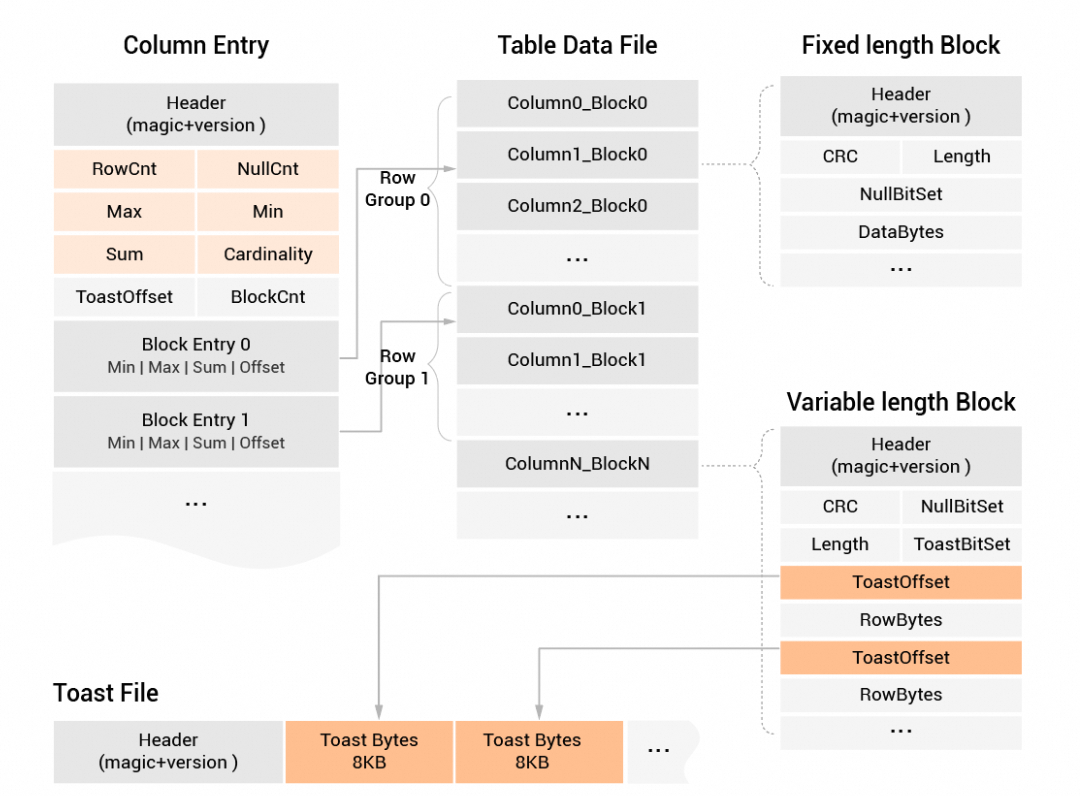
XUANWUエンジンは、Apache HadoopのOptimized row Columnar (ORC) またはParquet形式と同様のハイブリッド行列ストレージ形式をサポートしています。 ハイブリッド行と列ストレージ形式は、分析的な列のプルーニング、高スループットのデータスキャン、および行のアライメントをサポートして、特に多次元インデックスフィルタリングを伴うシナリオで、高性能でランダムなクエリを実装します。
次の図は、行と列のハイブリッドストレージ形式を示しています。
アダプティブインデックス作成
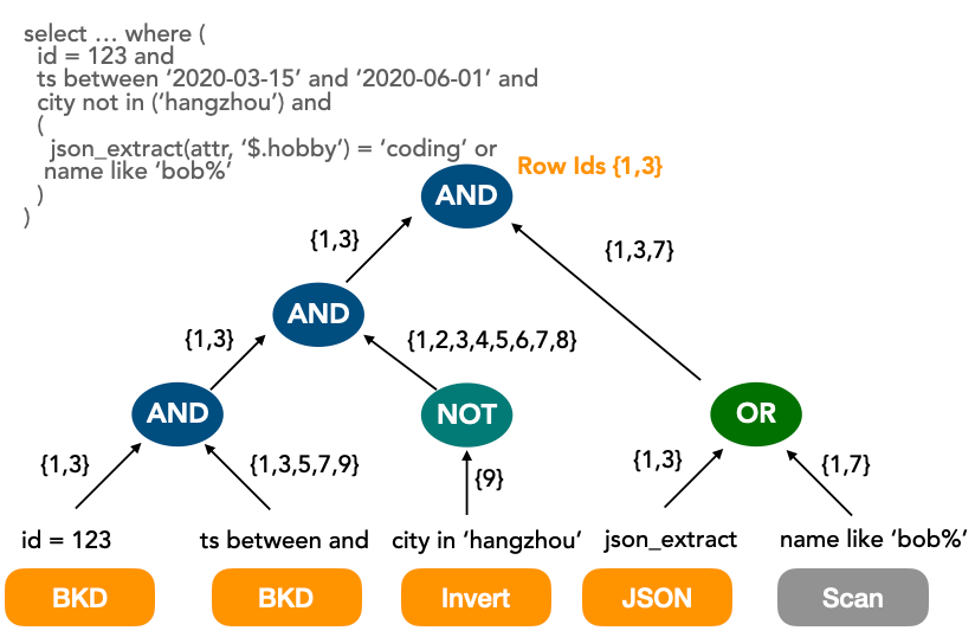
オンライン分析処理 (OLAP) シナリオでは、多次元クエリが必要ですが、従来のオンライントランザクション処理 (OLTP) シナリオの単一列または結合インデックスは要件を満たすことができません。 XUANWUエンジンは、列のアダプティブインデックスを使用して、STRING、NUMBER、TEXT、JSON、VECTORなどの列タイプのインデックスデータ構造を自動的に設定します。 さらに、XUANWUエンジンは、列レベルのインデックスを使用して、プログレッシブストリーミング方式で多次元結合検索とマルチウェイマージを実装します。 これにより、データフィルタリングのパフォーマンスが大幅に向上します。
次のタイプのインデックスがサポートされています: 転置インデックス、BKDツリーインデックス、およびビットマップインデックス。 インデックスのパフォーマンスは、範囲クエリのカーディナリティやテーブルレコード数などのデータ分散特性によって異なります。 特定のシナリオでは、インデックスオーバーヘッドはスキャンオーバーヘッドよりも高くなります。 例: age > 0およびage <100の条件を含むクエリ。 XUANWUエンジンは、コストベース最適化 (CBO) に基づいてデータをインデックス化するかスキャンするかを決定します。
次の図は、さまざまな種類のインデックスに対してマルチウェイマージを使用する方法を示しています。
構造化インデックスと非構造化インデックスの融合
XUANWUエンジンのインデックスマネージャは、構造化インデックスと非構造化インデックスをストレージ層で集中管理します。 インデックスには、数値のBKDインデックス、文字列の転置インデックス、非構造化JSONおよびベクトルインデックス、テキストデータのフルテキストインデックスが含まれます。 インデックスマネージャは、計算層のための統一された式を提供し、これは、計算層のSQLロジックが異なるデータ型と互換性があることを可能にし、クエリを加速する。 AnalyticDB for MySQLは、複雑なSQLロジックをサポートするために、フルテキストデータと構造化テーブル間の相関分析を実行します。 例:

上記のクエリは、サブクエリのフルテキスト検索から取得した結果セットに対して関連性分析を実行し、分析した結果をスコアに基づいて降順に並べ替え、最初の10,000行を返します。
XUANWU分析ストレージエンジンV2 (XUANWU_V2)
XUANWU_V2エンジンは、AnalyticDB for MySQL用のXUANWUエンジンに基づいて開発された次世代ストレージエンジンです。
効率的なデータ編成
XUANWU_V2エンジンは、データ編成方法を最適化します。 データは、追加モードでリアルタイムエンジンに書き込まれ、その後、読み取りフレンドリーなフルデータエンジンにフラッシュされます。 次に、コンパクションタスクは、フルデータエンジンのレベル内またはレベル間でデータをコンパクト化し、L0レベル未満のデータが部分的に順序付けられ、固定サイズに基づいて物理的に編成されることを保証する。
次の図は、データの整理方法を示しています。

このデータ編成方法により、リアルタイムエンジンが読み取りフレンドリーなフルデータエンジンのデータをタイムリーに構築し、クエリのパフォーマンスを向上させることができます。 さらに、この方法は、コンパクション中の読み出し増幅の問題を大幅に軽減し、CPUおよびI/Oの消費をさらに低減する。 XUANWU_V2エンジンは、このメソッドを使用して、過度に大きいまたは小さいパーティションファイルを適応的に分割および圧縮できます。 パーティションキーの選択に悩まされる必要はありません。
効率的なストレージフォーマット
XUANWU_V2エンジンは、列レベルのI/Oブロックを固定数の行で編成する元のファイル形式の上に、固定サイズでI/Oブロックを編成するファイル形式を使用します。 新しいI/Oブロック編成方法は、I/Oおよびメモリ管理を最適化し、行アライメントおよびI/Oサイズの不一致によって引き起こされる問題を解決するだけでなく、メモリの再利用効率を向上させ、メモリアプリケーションおよび再利用のオーバーヘッドを削減します。 新しいI/Oブロック編成方法は、メモリおよびI/O動作を整列させ、これにより、読み出し増幅およびI/Oコストがさらに削減される。

より良い水平スケーリング弾力性
XUANWU_V2エンジンはすべてのデータをObject Storage Service (OSS) に保存します。これにより、ユーザーのストレージコストが大幅に削減され、水平スケーリングとノード移行の効率が大幅に向上します。 XUANWU_V2エンジンはエンタープライズSSD (ESSD) をクエリキャッシュとして使用し、DDLステートメントを実行して特定のパーティションのデータをプリフェッチし、自動的にキャッシュされたデータをクエリできます。 これにより、クエリのパフォーマンスが効果的に向上します。