Apache Sparkは、ビッグデータのワークロードを処理するために使用されるオープンソースの分散処理システムです。 Apache SparkはSQLをサポートしており、複数のプログラミング言語でDataFramesを記述できます。 これにより、Apache Sparkは柔軟で使いやすくなります。 Sparkエンジンは、SQL、バッチ処理、ストリーム処理、機械学習、グラフ計算などの機能を提供できます。
AnalyticDB for MySQL Serverless Sparkは、Apache Sparkの上にあるAnalyticDB for MySQLチームによって開発されたビッグデータ分析およびコンピューティングサービスです。 AnalyticDB for MySQLクラスターを作成した後、Sparkクラスターデプロイを必要とせずにSparkジョブを送信するように簡単な設定を構成できます。 次の図は、AnalyticDB for MySQL Serverless Sparkのアーキテクチャを示しています。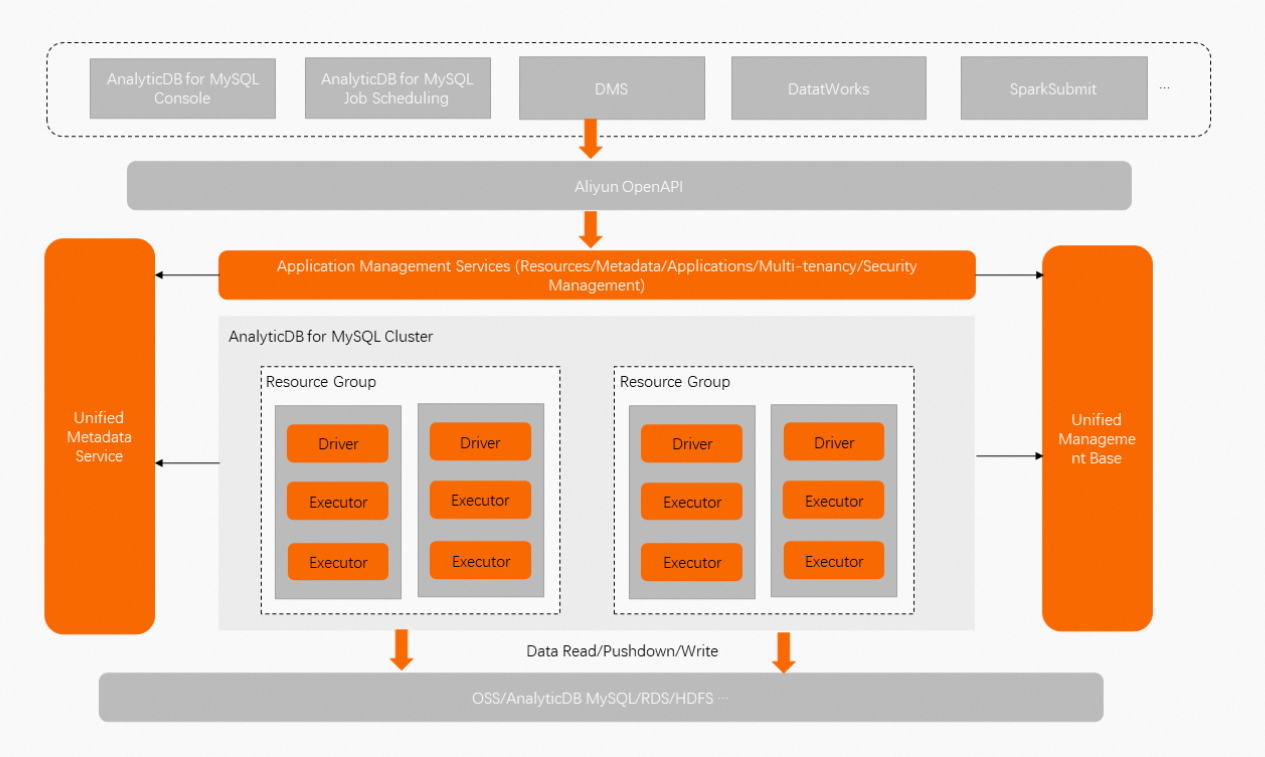
Serverless Sparkは、Spark、Serverless、およびクラウドネイティブテクノロジーの詳細な統合です。 Apache Sparkと比較して、Serverless Sparkには次の利点があります。
使いやすさ
Serverless SparkはシンプルなAPI、スクリプト、およびコンソール操作を提供し、基盤となるコンポーネントを構成する必要なしにApache Sparkを使用するのと同じ方法でビッグデータ開発を実行するのに役立ちます。
O&Mフリー
AnalyticDB for MySQL Serverless Sparkは、サーバー設定、Hadoop設定、またはリソーススケーリングを必要とせずにSparkジョブを管理するのに役立ちます。
ジョブレベルのスケーラビリティ
Serverless Sparkを使用すると、各ジョブのドライバーとエグゼキュータープロセスのリソースを購入できます。 数秒以内にリソースをプルアップして、リソース要件にすばやく対応できます。
コスト削減
リソースをオンデマンドでスケールアップして、予約済みリソースを保持する必要なしにSparkジョブを実行できます。 スケーリングされたリソースに対して課金されます。 リソースを使用しない場合、料金は発生しません。
強化されたパフォーマンス
AnalyticDB for MySQLチームは、Sparkエンジンで詳細なカスタマイズと最適化を実行し、Apache SparkをAnalyticDB for MySQLデータウェアハウスと統合します。 一般的なシナリオでは、Object Storage Service (OSS) データへのアクセスパフォーマンスはApache Sparkの最大5倍、接続パフォーマンスはJava Database Connectivity (JDBC) 接続の最大6倍です。 さらに、AnalyticDB for MySQLおよびApache Sparkの上にゼロETLソリューションが提供されています。