AnalyticDB for MySQLは、非構造化データに対する類似性検索の実装に役立つベクトル検索機能を提供します。 このトピックでは、ベクトル検索機能と、ベクトルインデックスを作成および使用する方法について説明します。
前提条件
V3.1.4.0以降のAnalyticDB for MySQLクラスターが作成されます。
ベクトル検索機能を使用するには、3.1.5.16、3.1.6.8、3.1.8.6以降のマイナーバージョンを使用することを推奨します。
クラスターが前のバージョンではない場合、ベクトル検索機能を使用する前に、CSTORE_PROJECT_PUSH_DOWNおよびCSTORE_PPD_TOP_N_ENABLEパラメーターをfalseに設定することを推奨します。
AnalyticDB For MySQLクラスターのマイナーバージョンを照会する方法については、AnalyticDB for MySQLクラスターのバージョンを照会するにはどうすればよいですか? クラスターのマイナーバージョンを更新するには、テクニカルサポートにお問い合わせください。
背景情報
概要
AIアルゴリズムを使用して、非構造化データから特徴を抽出し、特徴を特徴ベクトルにエンコードし、特徴ベクトルをAnalyticDB for MySQLに保存できます。 特徴ベクトルを使用して非構造化データを識別する場合、ベクトル間の距離を使用して、異なる非構造化データ間の類似性を測定できます。 AnalyticDB for MySQLは、画像ベースの検索、声紋マッチング、顔認識、テキスト検索などのシナリオに効率的なベクトル検索機能を提供します。
アーキテクチャ
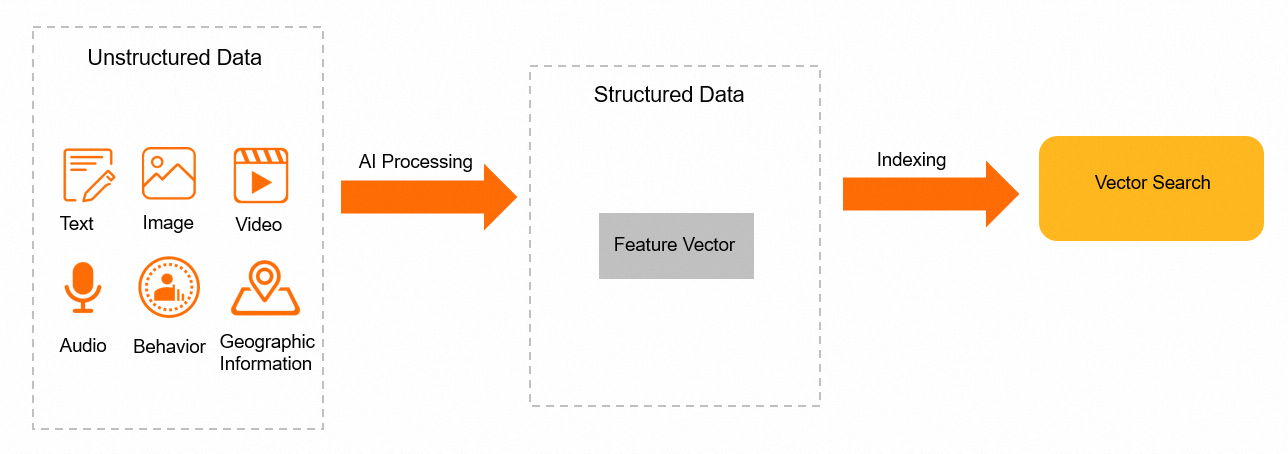
メリット
ベクトルデータの高次元、高性能、高リコール
この例では、人間の顔を表す512次元ベクトルが使用される。 AnalyticDB for MySQLは、100クエリ /秒 (QPS) と50ミリ秒の応答時間を必要とするシナリオでは100億エントリのベクトルデータ、または1,000 QPSと1秒の応答時間を必要とするシナリオでは0.2億エントリのベクトルデータの99% リコールを提供できます。
構造化データと非構造化データの統合クエリ
AnalyticDB for MySQLは、k最近傍 (KNN) および半径最近傍 (RNN) アルゴリズムを使用した統合クエリをサポートしています。 たとえば、2つのベクトルセット間の類似性を比較できます。
リアルタイム更新
AnalyticDB for MySQLは、同時並行性の高いリアルタイムの書き込みと更新をサポートしています。 データが書き込まれた直後にデータを照会できます。
リアルタイム検索
AnalyticDB for MySQLは、大規模並列処理 (MPP) アーキテクチャを使用して、ミリ秒レベルのデータ検索を提供し、検索効率を向上させます。
使いやすさ
AnalyticDB for MySQLは標準のSQLステートメントをサポートしており、複雑な設定を追加することなく開発プロセスを簡素化します。
用語
ベクトルインデックスの作成
構文
次の構文を使用して、テーブルを作成するときにベクトルインデックスを作成できます。
ANN INDEX [index_name] (column_name)] [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]Parameters
ANN INDEX: ベクトルインデックスのキーワード。
index_name: インデックスの名前。 インデックスの命名規則の詳細については、「制限」トピックの「命名制限」セクションを参照してください。
column_name: ベクトル列の名前。 列の命名規則の詳細については、「制限」トピックの「命名制限」セクションを参照してください。
ARRAY< FLOAT>、ARRAY<BYTE>、ARRAY<SMALLINT>。algorithm: ベクトル距離の計算に使用されるアルゴリズム。 値を
HNSW_PQに設定します。distancemeasure: ベクトル距離の計算に使用される式。 値を
SquaredL2に設定します。 の計算式SquaredL2:(x1 - y1)2+ (x2 - y2)2+. ..(xn - yn)2.
例
この例では、vectorという名前のテーブルが作成されます。 テーブルには、float_featureとshort_featureの2つのベクトル列があります。 float_feature列はARRAY <float> タイプで、4次元データが含まれています。 short_feature列は、ARRAY<SMALLINT> タイプであり、4次元データを含む。 テーブルが作成されると、2つの列にベクトルインデックスが作成されます。
テーブルの作成ベクトル (
xid bigint not null,
cid bigint not null,
uid varchar not null,
vid varchar not null,
wid varchar not null,
float_feature配列 <float >(4),
short_feature配列 <smallint >(4) 、
ANN INDEX idx_short_feature(short_feature) 、
ANN INDEX idx_float_feature(float_feature) 、
主要なキー (xid、cid、vid)
) ハッシュによる分配 (xid); ベクトルインデックスの追加
構文
次の構文を使用して、テーブルを作成した後にベクトルインデックスを追加できます。
ALTER TABLE table_name ADD ANN INDEX [index_name] (column_name) [algorithm=HNSW_PQ ] [distancemeasure=SquaredL2]例
vectorテーブルは、次のステートメントを実行して作成されます。
テーブルの作成ベクトル (
xid bigint not null,
cid bigint not null,
uid varchar not null,
vid varchar not null,
wid varchar not null,
float_feature配列 <float >(4),
short_feature配列 <smallint >(4) 、
主要なキー (xid、cid、vid)
) ハッシュによる分配 (xid); 次のサンプルコードを実行して、float_featureおよびshort_featureのベクトルインデックスを作成します。
ALTER TABLEベクトルADD ANNインデックスidx_float_feature(float_feature);
ALTER TABLEベクトルADD ANNインデックスidx_short_feature(short_feature); クエリベクターデータ
SELECTステートメントに距離計算関数を追加して、エンティティ間の関係をベクトル空間内のベクトル間の距離に抽象化できます。 例: L2_DISTANCE。
例
データの挿入
vectorテーブルにデータを挿入します。
する値 (1,2,'A','B','C','[1,1,1,1]','[1.2,1.5,2,3.0]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (2,1,'e','v','f','[2,2,2,2]','[1.5,1.15,2.2,2.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (0,6,'d','f','g','[3,3,3,3]','[0.2,1.6,5,3.7]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','b','h','[4,4,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid、cid、uid、vid、wid、short_feature、float_feature) VALUES (8,5、'Sj' 、'Hb' 、'Dh' 、'[5,5、5,5]' 、'[1.3、4.5、6.9、5.2]');
INSERT into vector (xid、cid、uid、vid、wid、short_feature、float_feature) VALUES (5,4、'x' 、'g' 、'h' 、'[3,4、4,4]' 、'[1.0、4.15、6,2 9]);
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'j','r','k','[6,6,4,4]','[1.0,4.15,6,2.9]');
INSERT into vector (xid,cid,uid,vid,wid,short_feature,float_feature) VALUES (5,4,'s','i','q','[2,2,4,4]','[1.0,4.15,6,2.9]'); クエリデータ
ベクトル
'[1,1,1,1]'までの距離が最も短いshort_feature列の上位3つのエントリを照会します。SELECT xid, l2_distance(short_feature, '[1,1,1,1]') as dis FROMベクトルORDER BY 2 LIMIT 3;サンプル結果:
+ ------- ---------------- | xid | dis | + ------ ---------------- + | 1 | 0.0 | + ------ ---------------- + | 2 | 4.0 | + ------ ---------------- + | 0 | 16.0 | + ------ ---------------- +xidが5、cidが4の場合、ベクトル
'[1,1,1,1]'までの距離が最も短いshort_feature列の上位4つのエントリを照会します。SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROMベクトルWHERE xid = 5 AND cid = 4 ORDER BY 2 LIMIT 4;サンプル結果:
+ ------- ---------------- | uid | dis | + ------ ---------------- + | s | 20.0 | + ------ ---------------- + | x | 31.0 | + ------ ---------------- + | j | 36.0 | + ------ ---------------- + | j | 68.0 | + ------ ---------------- +距離が50以下で、xidが5の場合、ベクトル
'[1,1,1,1]'までの最短距離を持つshort_feature列の上位3つのエントリを照会します。SELECT uid, l2_distance(short_feature, '[1,1,1,1]') as dis FROMベクトルWHERE l2_distance(short_feature, '[1,1,1,1]') < 50.0 AND xid = 5 ORDER BY 2 LIMIT 3;サンプル結果:
+ ------- ------------------ | uid | dis | + ------ ----------------- + | s | 20.0 | + ------ ----------------- + | x | 31.0 | + ------ ----------------- + | j | 36.0 | + ------ ----------------- +