このトピックでは、Alibaba Cloud AI Containers (AC2) が提供する人工知能 (AI) コンテナイメージを使用して、Intelプロセッサを使用してチャットボットを作成するElastic Compute Service (ECS) インスタンスにQwen-7B-Chatモデルをデプロイする方法について説明します。
手順 1: ECS インスタンスの作成
ECSコンソールのインスタンス購入ページに移動します。
ECSインスタンスの作成のプロンプトに従ってパラメーターを設定します。
次のパラメータに注意してください。 ECSインスタンス購入ページで他のパラメーターを設定する方法については、「カスタム起動タブでインスタンスを作成する」をご参照ください。
インスタンス: Qwen-7B-Chatモデルには約30 GiBのメモリが必要です。 モデルを安定して実行するには、ecs.g8i.4xlargeまたは64 GiB以上のメモリを持つ別のインスタンスタイプを選択します。
イメージ: Alibaba Cloud Linux 3.2104 LTS 64ビットイメージを選択します。
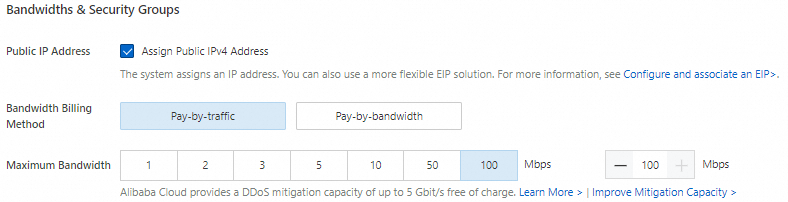
パブリックIPアドレス: モデルのダウンロードプロセスを高速化するには、[パブリックIPv4アドレスの割り当て] を選択し、帯域幅課金方法を [トラフィック課金] に設定し、最大帯域幅を100 Mbit/sに設定します。
データディスク: Qwen-7B-Chat用の複数のモデルファイルをダウンロードする必要があり、大量のストレージスペースを占有します。 モデルが期待どおりに実行されるようにするには、100 GiBデータディスクを追加することを推奨します。
手順2: Dockerランタイム環境の作成
Dockerをインストールします。
Alibaba Cloud Linux 3を実行するECSインスタンスにDockerをインストールする方法については、「」をご参照ください。
次のコマンドを実行して、Dockerデーモンが起動していることを確認します。
sudo systemctl status docker次のコマンドを実行して、PyTorch AIコンテナを作成して実行します。
AC2は、Intelのハードウェアおよびソフトウェア用に最適化されたPyTorchイメージを含む、AIシナリオ用のさまざまなコンテナイメージを提供し、PyTorchのランタイム環境をすばやく作成するために使用できます。
sudo docker pul l ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/pytorch:2.0.1-3.2304 sudo docker run -itd -- name pytorch -- net host -v $HOME/workspace:/workspace \ ac2-registry.cn-hangzhou.cr.aliyuncs.com/ac2/pytorch:2.0.1-3.2304
ステップ3: Qwen-7B-Chatのデプロイ
次のコマンドを実行して、コンテナー環境に入ります。
sudo docker exec -it -w /workspace pytorch /bin/bash後続のコマンドを実行するには、コンテナー環境を使用する必要があります。 予期せず終了した場合は、上記のコマンドを使用してコンテナ環境を再入力してください。
cat /proc/1/cgroup | grep dockerコマンドを実行して、現在の環境がコンテナーであるかどうかを確認できます。 コマンド出力が返された場合、環境はコンテナです。次のコマンドを実行して、必要なソフトウェアをインストールおよび設定します。
yum install -y tmux git git-lfs wget次のコマンドを実行して、Git Large File Storage (LFS) を有効にします。
事前トレーニング済みモデルをダウンロードするには、Git LFSを有効にする必要があります。
git lfs installソースコードとモデルをダウンロードします。
次のコマンドを実行して、tmuxセッションを作成します。
tmux説明事前にトレーニングされたモデルをダウンロードするには長い時間が必要であり、ダウンロードの成功率はネットワーク条件によって異なります。 ECSインスタンスへの接続とモデルダウンロードプロセスの継続性を維持するために、tmuxセッションでモデルをダウンロードすることを推奨します。
次のコマンドを実行して、Qwen-7Bプロジェクトのソースコードと事前トレーニング済みモデルをダウンロードします。
git clone https://github.com/QwenLM/Qwen.git git clone https:// www.modelscope.cn/qwen/Qwen-7B-Chat.git qwen-7b-chat -- 深さ=1次のコマンドを実行して、現在の作業ディレクトリを表示します。
ls -l
次のコマンドを実行して、ランタイム環境をデプロイします。
多数のPython AI依存関係がAC2に統合されています。
Yellowdog Updater Modified (YUM)またはDandified YUM (DNF)を使用して、Pythonランタイム依存関係をインストールできます。yum install -y python3-{transformers {、-stream-generator} 、tiktoken、accelerate} python-einopsチャットボットとチャットします。
次のコマンドを実行して、モデルのロードパラメーターを変更します。
サンプルのターミナルスクリプトがプロジェクトのソースコードで提供されています。これにより、Qwen-7B-Chatモデルを実行してオンプレミスのチャットボットとチャットできます。 スクリプトを実行する前に、モデルの読み込みパラメーターを変更して、BFloat16の精度でモデルを読み込み、CPU用のAVX-512命令セットを使用して読み込みプロセスを高速化します。
cd /workspace/Qwen grep "torch.bfloat16" cli_demo.py 2>&1 >/dev/null || sed -i "57i\torch_dtype=torch.bfloat16," cli_demo.py次のコマンドを実行してチャットボットを起動します。
cd /workspace/Qwen python3 cli_demo.py -c ../qwen-7b-chat --cpu-onlyデプロイプロセスが完了したら、
[ユーザー]>プロンプトにテキストを入力して、Qwen-7B-Chatモデルとリアルタイムでチャットできます。 説明
説明:exitコマンドを実行してチャットボットを終了できます。