ACK Serverless Knative 上で KServe を使用して、AI モデルをサーバーレス推論サービスとしてデプロイできます。これにより、オートスケーリング、マルチバージョン管理、カナリアリリースなどの主要な機能を利用できます。
ステップ 1: KServe のインストールと設定
KServe と Knative の ALB Ingress または Kourier ゲートウェイ との円滑な統合を確実にするために、まず KServe コンポーネントをインストールし、次にそのデフォルト設定を変更して、組み込みの Istio VirtualService の作成を無効にします。
KServe コンポーネントをインストールします。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、対象のクラスターを見つけてその名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。
[コンポーネント] タブで、[アドオン] セクションにある [KServe] コンポーネントを見つけてデプロイします。
Istio VirtualService の作成を無効にします。
inferenceservice-configConfigMap を編集して、disableIstioVirtualHostをtrueに設定します。kubectl get configmap inferenceservice-config -n kserve -o yaml \ | sed 's/"disableIstioVirtualHost": false/"disableIstioVirtualHost": true/g' \ | kubectl apply -f -期待される出力:
configmap/inferenceservice-config configured設定の変更を確認します。
kubectl get configmap inferenceservice-config -n kserve -o yaml \ | grep '"disableIstioVirtualHost":' \ | tail -n1 \ | awk -F':' '{gsub(/[ ,]/,"",$2); print $2}'出力は
trueである必要があります。KServe コントローラーを再起動して変更を適用します。
kubectl rollout restart deployment kserve-controller-manager -n kserve
ステップ 2: InferenceService のデプロイ
この例では、Iris データセットでトレーニングされた scikit-learn 分類モデルをデプロイします。このサービスは、花に関する 4 つの測定値の配列を受け入れ、3 種類のうちどの種に属するかを予測します。
入力 (4 つの数値特徴の配列):
| 出力 (予測されたクラスインデックス):
|
inferenceservice.yamlという名前のファイルを作成します。apiVersion: "serving.kserve.io/v1beta1" kind: "InferenceService" metadata: name: "sklearn-iris" spec: predictor: model: # モデルのフォーマット、この場合は scikit-learn modelFormat: name: sklearn image: "kube-ai-registry.cn-shanghai.cr.aliyuncs.com/ai-sample/kserve-sklearn-server:v0.12.0" command: - sh - -c - "python -m sklearnserver --model_name=sklearn-iris --model_dir=/models --http_port=8080"InferenceService をデプロイします。
kubectl apply -f inferenceservice.yamlサービスステータスを確認します。
kubectl get inferenceservices sklearn-iris出力で、
READY列にTrueと表示されたら、サービスは稼働しています。NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE sklearn-iris http://sklearn-iris-predictor-default.default.example.com True 100 sklearn-iris-predictor-default-00001 51s
ステップ 3: サービスへのアクセス
クラスターのイングレスゲートウェイ経由で、サービスに推論リクエストを送信します。
[Knative] ページの [サービス] タブで、サービスにアクセスするためのゲートウェイアドレスとデフォルトのドメイン名を取得します。
次の図は、ALB Ingress を使用した例を示しています。Kourier ゲートウェイのインターフェイスも同様です。
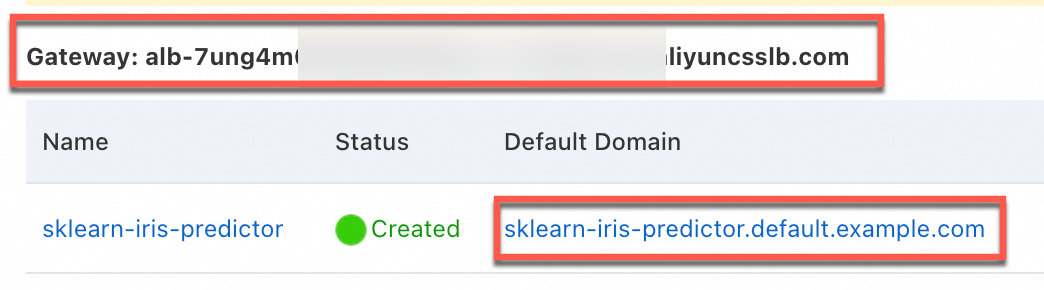
リクエストデータを準備します。
ローカルターミナルで、リクエストペイロードを含む
./iris-input.jsonという名前のファイルを作成します。この例には、予測対象の 2 つのサンプルが含まれています。cat <<EOF > "./iris-input.json" { "instances": [ [6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6] ] } EOFローカルターミナルから推論リクエストを送信します。
${INGRESS_DOMAIN}をステップ 1 で取得したゲートウェイアドレスに置き換えます。curl -H "Content-Type: application/json" -H "Host: sklearn-iris-predictor.default.example.com" "http://${INGRESS_DOMAIN}/v1/models/sklearn-iris:predict" -d @./iris-input.json出力は、モデルが両方の入力サンプルをクラス
1(ブルーフラッグ) に属すると予測したことを示しています。{"predictions":[1,1]}
課金
KServe および Knative コンポーネント自体に追加料金は発生しません。ただし、Elastic Compute Service (ECS) インスタンスや Elastic Container Instance などの計算リソース、および Application Load Balancer (ALB) や Classic Load Balancer (CLB) インスタンスなどのネットワークリソースを含む、使用する基盤リソースに対して課金されます。詳細については、「クラウド リソース料金」をご参照ください。
よくある質問
InferenceService が Not Ready 状態のままになるのはなぜですか?
InferenceService が Ready にならない場合は、イベント、Pod のステータス、コンテナーのログの順に確認してデバッグします。
次のステップに従ってください:
kubectl describe inferenceservice <your-service-name>を実行し、イベントにエラーメッセージがないか確認します。<your-service-name>を実際のサービス名に置き換えてください。kubectl get podsを実行して、サービスに関連付けられている Pod がErrorまたはCrashLoopBackOff状態になっていないか確認します。InferenceServiceの Pod には、通常、サービス名がプレフィックスとして付けられます。Pod がエラー状態にある場合は、
kubectl logs <pod-name> -c kserve-containerでそのログを確認して障害を診断します。これにより、ネットワークの問題によるモデルのダウンロード失敗や、不正なモデルファイル形式などの問題が明らかになる可能性があります。
独自にトレーニングしたカスタムモデルをデプロイするにはどうすればよいですか?
モデルファイルをアクセス可能な Object Storage Service (OSS) バケットにアップロードします。
InferenceServiceマニフェストを設定してモデルを指定します:spec.predictor.model.storageUriフィールドを OSS バケット内のモデルファイルの URI に設定します。モデルのフレームワークに基づいて
modelFormatフィールドをtensorflow、pytorch、onnxなどに設定します。
モデルに GPU リソースを設定するにはどうすればよいですか?
モデルの推論に GPU が必要な場合は、InferenceService YAML マニフェストの predictor セクションに resources フィールドを追加することで GPU リソースを要求できます。
詳細については、「GPU リソースの使用」をご参照ください。
spec:
predictor:
resources:
requests:
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"関連ドキュメント
ACK Knative は Stable Diffusion のアプリケーションテンプレートを提供しています。詳細については、「Knative を利用した本番環境レベルの Stable Diffusion サービスのデプロイ」をご参照ください。