Container Service for Kubernetes (ACK) では、マネージドPrometheusプラグインをインストールできます。 プラグインを使用してGPUリソースを監視できます。 cGPUソリューションを使用して、複数のアプリケーションを1つのGPUにスケジュールし、各アプリケーションに割り当てられているGPUメモリと計算能力を分離できます。 このトピックでは、マネージドPrometheusプラグインを使用してクラスターのGPUメモリ使用量を監視する方法と、cGPUを使用してGPUメモリを分離する方法について説明します。
シナリオ
このトピックは、cGPUが有効になっている専用Kubernetesクラスターと、cGPUが有効になっているプロフェッショナルKubernetesクラスターに適用されます。
前提条件
GPU高速化ノードを含む専用Kubernetesクラスターが作成されます。 Kubernetesのバージョンが1.16以降です。 詳細については、「GPUアクセラレーションノードを使用したACK専用クラスターの作成」をご参照ください。
アプリケーションリアルタイム監視サービス (ARMS) が起動されます。 詳細については、「ARMSのアクティベート」をご参照ください。
Prometheusのマネージドサービスがクラスターに対して有効になっています。 詳細については、「手順1: Prometheusのマネージドサービスの有効化」をご参照ください。
GPUモデルは、Tesla P4、Tesla P100、Tesla T4、またはTesla V100 (16 GB) です。
背景情報
AIの開発は、高い計算能力、大量のデータ、および最適化されたアルゴリズムによって促進されます。 NVIDIA GPUは、一般的な異種コンピューティング技術を提供します。 これらのテクニックは、高性能なディープラーニングの基礎です。 GPUのコストは高いです。 各アプリケーションがモデル予測シナリオにおいて1つの専用GPUを使用する場合、コンピューティングリソースが浪費され得る。 GPU共有はリソース使用量を改善します。 最低コストで最高のクエリ率を達成する方法と、アプリケーションサービスレベル契約 (SLA) を満たす方法を検討する必要があります。
マネージドPrometheusプラグインを使用して専用GPUを監視する
ARMSコンソールにログインします。
左側のナビゲーションウィンドウで、[Prometheusモニタリング] をクリックします。
[Prometheusモニタリング] ページで、クラスターがデプロイされているリージョンを選択し、[操作] 列の [インストール] をクリックします。
[確認] メッセージで、[OK] をクリックします。
Prometheusプラグインのインストールには約2分かかります。 Prometheusプラグインがインストールされると、[インストール済みダッシュボード] 列に表示されます。
CLIを使用して、次のサンプルアプリケーションをデプロイできます。 詳細については、「kubectlを使用したアプリケーションの管理」をご参照ください。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 1 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-3g-v1 updateStrategy: type: RollingUpdate template: # define the pods specifications metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: nvidia.com/gpu: 1アプリケーションがデプロイされたら、次のコマンドを実行してアプリケーションのステータスを照会します。 出力は、アプリケーション名がapp-3g-v1-0であることを示します。
kubectl get pod期待される出力:
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 1 2m56sアプリケーションがデプロイされているクラスターを見つけてクリックします。 [ダッシュボード] ページで、[名前] 列の [GPU APP] をクリックします。
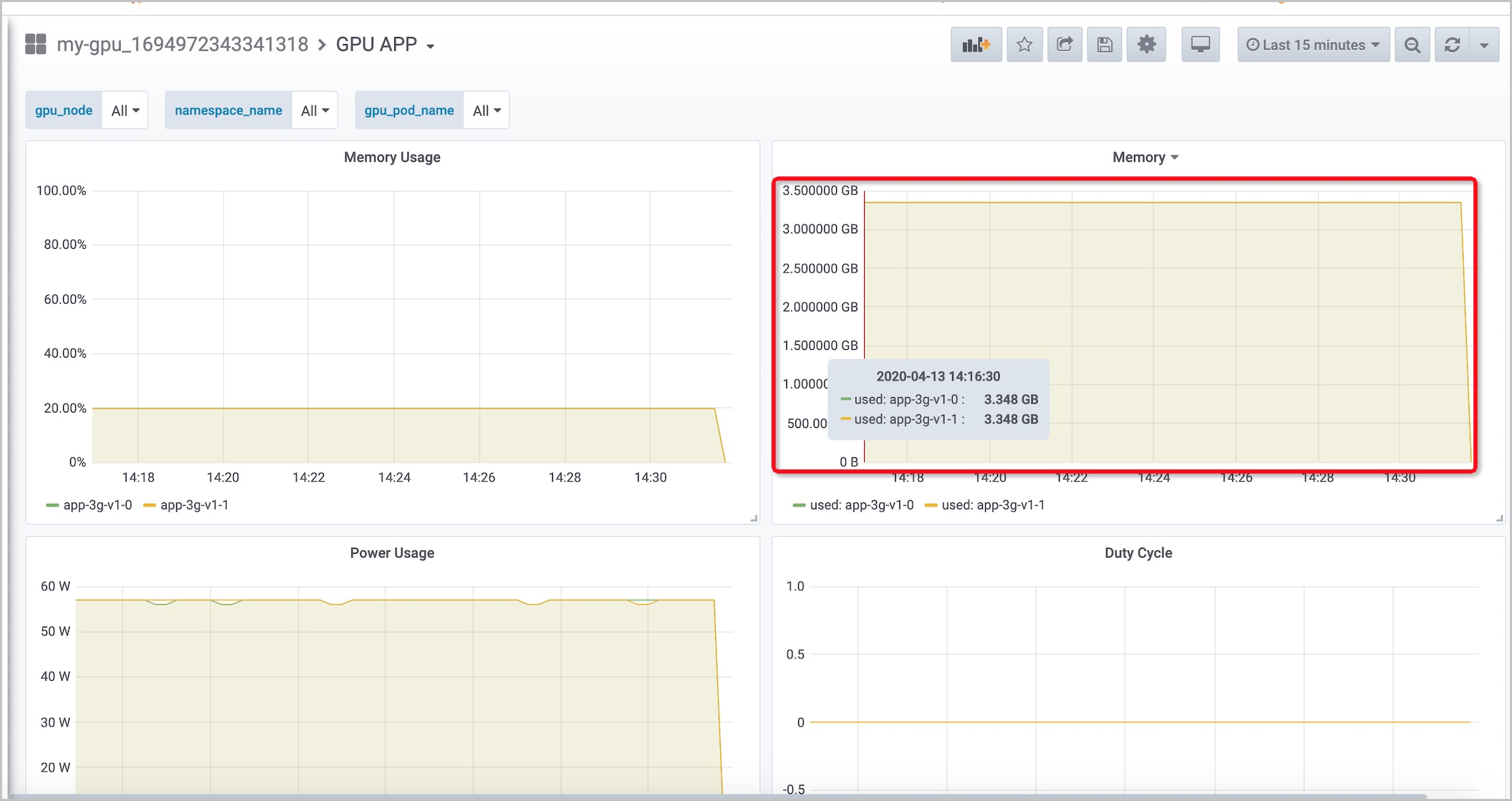
次の図は、アプリケーションがGPUメモリの20% のみを使用することを示しています。これは、GPUメモリの80% が無駄になっていることを示しています。 GPU メモリは合計で約 16 GB ですが、 メモリの使用量は約 3.4 GB で安定しています。 各アプリケーションに1つのGPUを割り当てると、大量のGPUリソースが無駄になります。 GPUリソース使用量を改善するために、cGPUを使用して複数のアプリケーション間でGPUを共有できます。

複数のコンテナー間で1つのGPUを共有する
GPU高速化ノードにラベルを追加します。
ACKコンソールにログインします。
ACKコンソールの左側のナビゲーションウィンドウで、[クラスター] をクリックします。
[クラスター] ページで、管理するクラスターを見つけてクラスターの名前をクリックするか、[操作] 列の [アプリケーション] をクリックします。
詳細ページの左側のナビゲーションウィンドウで、 を選択します。
[ノード] ページで、ページの右上隅にある [ラベルとテイントの管理] をクリックします。
[ラベルとテイントの管理] ページで、管理するノードを選択し、[ラベルの追加] をクリックします。
[追加] ダイアログボックスで、名前をcgpuに設定し、値をtrueに設定し、[OK] をクリックします。
重要ワーカーノードがcgpu=trueラベルで追加された場合、GPUリソースnvidia.com/gpuはワーカーノードのポッド専用ではなくなります。 ワーカーノードのcGPUを無効にするには、cgpuの値をfalseに設定します。 これにより、GPUリソースnvidia.com/gpuはワーカーノード上のポッド専用になります。
cGPUコンポーネントをインストールします。
ACKコンソールにログインします。
ACKコンソールの左側のナビゲーションウィンドウで、 を選択します。
アプリカタログページで、ack-cgpuを検索し、表示されたらack-cgpuをクリックします。
ページの右側にある [デプロイ] セクションで、作成したクラスターを選択し、ack-cgpuをデプロイする名前空間を選択して、[作成] をクリックします。
マスターノードにログインし、次のコマンドを実行してGPUリソースを照会します。
詳細については、「クラスターのkubeconfigファイルを取得し、kubectlを使用してクラスターに接続する」をご参照ください。
kubectl inspect cgpu期待される出力:
NAME IPADDRESS GPU0(Allocated/Total) GPU Memory(GiB) cn-hangzhou.192.168.2.167 192.168.2.167 0/15 0/15 ---------------------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 0/15 (0%)説明出力は、GPUリソースがGPUからGPUメモリに切り替えられたことを示します。
GPUリソースを共有するワークロードをデプロイします。
サンプルアプリケーションのデプロイに使用されたYAMLファイルを変更します。
レプリケートされたポッドの数を1から2に変更します。 これにより、2つのポッドをデプロイしてアプリケーションを実行できます。 cGPUを有効にする前は、GPUは唯一のポッド専用です。 cGPUを有効にすると、GPUは2つのポッドで共有されます。
リソースタイプを
nvidia.com/gpuからaliyun.com/gpu-memに変更します。 GPUリソースの単位がGBに変更されます。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-3g-v1 labels: app: app-3g-v1 spec: replicas: 2 serviceName: "app-3g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-3g-v1 template: # define the pods specifications metadata: labels: app: app-3g-v1 spec: containers: - name: app-3g-v1 image: registry.cn-hangzhou.aliyuncs.com/ai-samples/gpushare-sample:tensorflow-1.5 command: - cuda_malloc - -size=4096 resources: limits: aliyun.com/gpu-mem: 4 # Each pod requests 4 GB of GPU memory. Two replicated pods are configured. Therefore, a total of 8 GB of GPU memory is requested by the application.変更された設定に基づいてワークロードを再作成します。
出力は、2つのポッドが同じGPUアクセラレーションノードにスケジュールされていることを示します。
kubectl inspect cgpu -d期待される出力:
NAME: cn-hangzhou.192.168.2.167 IPADDRESS: 192.168.2.167 NAME NAMESPACE GPU0(Allocated) app-3g-v1-0 default 4 app-3g-v1-1 default 4 Allocated : 8 (53%) Total : 15 -------------------------------------------------------- Allocated/Total GPU Memory In Cluster: 8/15 (53%)次のコマンドを実行して、2つのコンテナーに1つずつログインします。
出力は、GPUメモリの制限がMiB 4,301であることを示します。つまり、各コンテナは最大で4,301のMiBのGPUメモリを使用できます。
次のコマンドを実行して、コンテナーapp-3g-v1-0にログインします。
kubectl exec -it app-3g-v1-0 nvidia-smi期待される出力:
Mon Apr 13 01:33:10 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 37C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+次のコマンドを実行して、コンテナーapp-3g-v1-1にログインします。
kubectl exec -it app-3g-v1-1 nvidia-smi期待される出力:
Mon Apr 13 01:36:07 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... On | 00000000:00:07.0 Off | 0 | | N/A 38C P0 57W / 300W | 3193MiB / 4301MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+
GPU高速化ノードにログインして、GPUの使用状況を確認します。
出力は、使用中のGPUメモリの合計がMiB 6,396であることを示します。これは、2つのコンテナによって使用されるメモリの合計です。 これは、cGPUがコンテナー間でGPUメモリを分離したことを示しています。 コンテナーにログインし、さらに多くのGPUリソースを申請すると、メモリ割り当てエラーが報告されます。
次のコマンドを実行して、GPUアクセラレーションノードにログインします。
kubectl exec -it app-3g-v1-1 bash次のコマンドを実行して、GPUの使用状況を照会します。
cuda_malloc -size=1024期待される出力:
gpu_cuda_malloc starting... Detected 1 CUDA Capable device(s) Device 0: "Tesla V100-SXM2-16GB" CUDA Driver Version / Runtime Version 10.1 / 10.1 Total amount of global memory: 4301 MBytes (4509925376 bytes) Try to malloc 1024 MBytes memory on GPU 0 CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)"
パッチを入手するために ARMSコンソールの各アプリケーションまたはノードのGPU使用状況を監視します。
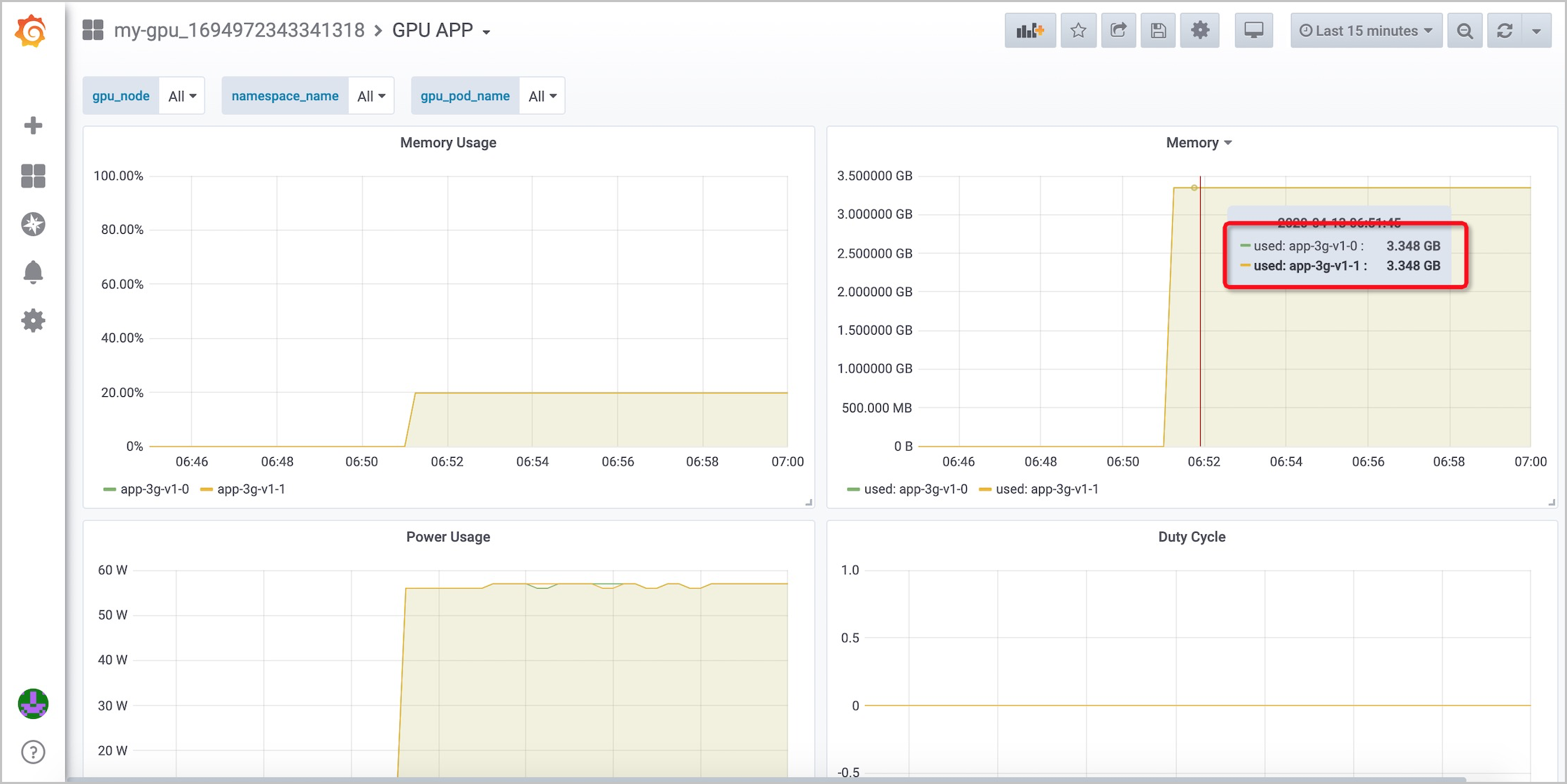
GPU APP: 各アプリケーションで使用されているGPUメモリの量と割合を表示できます。
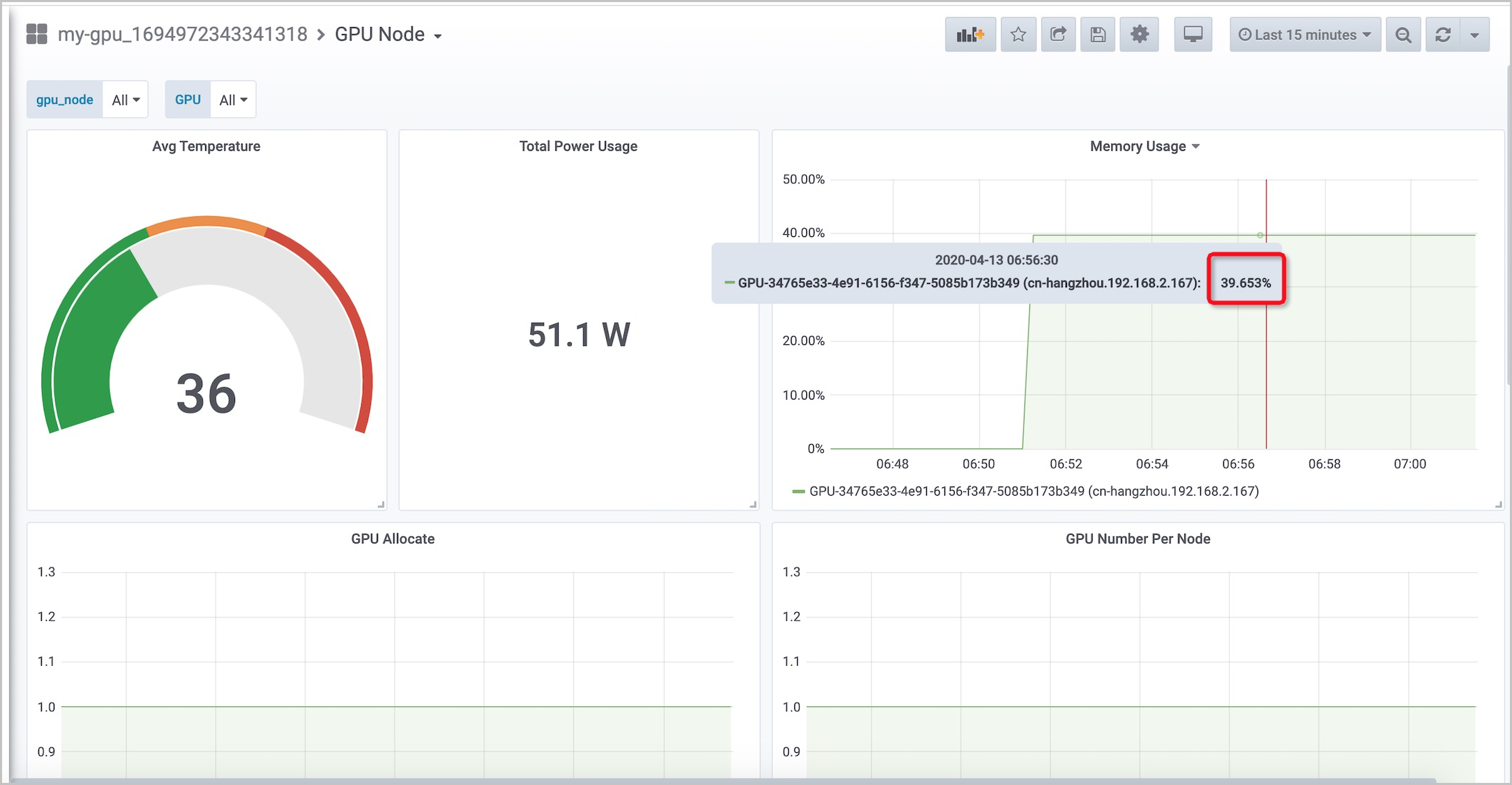
GPUノード: 各GPUのメモリ使用量を表示できます。
マネージドPrometheusプラグインを使用してGPU共有を監視する
アプリケーションによって要求されるGPUメモリの量が上限を超える場合、cGPUのGPUメモリ分離モジュールは、他のアプリケーションが影響を受けるのを防ぐことができます。
共有GPUを使用する新しいアプリケーションをデプロイします。
アプリケーションは4 GBのGPUメモリを要求します。 ただし、アプリケーションの実際のメモリ使用量は6 GBです。
apiVersion: apps/v1 kind: StatefulSet metadata: name: app-6g-v1 labels: app: app-6g-v1 spec: replicas: 1 serviceName: "app-6g-v1" podManagementPolicy: "Parallel" selector: # define how the deployment finds the pods it manages matchLabels: app: app-6g-v1 template: # define the pods specifications metadata: labels: app: app-6g-v1 spec: containers: - name: app-6g-v1 image: registry.cn-shanghai.aliyuncs.com/tensorflow-samples/cuda-malloc:6G resources: limits: aliyun.com/gpu-mem: 4 # Each pod requests 4 GB of GPU memory. One replicated pod is configured for the application. Therefore, a total of 4 GB of GPU memory is requested by the application.次のコマンドを実行して、ポッドのステータスを照会します。
新しいアプリケーションを実行するポッドは、CrashLoopBackOff状態のままです。 既存の2つのポッドは通常どおり実行されます。
kubectl get pod期待される出力:
NAME READY STATUS RESTARTS AGE app-3g-v1-0 1/1 Running 0 7h35m app-3g-v1-1 1/1 Running 0 7h35m app-6g-v1-0 0/1 CrashLoopBackOff 5 3m15s次のコマンドを実行して、コンテナログのエラーを確認します。
出力は、cudaErrorMemoryAllocationエラーが発生したことを示します。
kubectl logs app-6g-v1-0期待される出力:
CUDA error at cgpu_cuda_malloc.cu:119 code=2(cudaErrorMemoryAllocation) "cudaMalloc( (void**)&dev_c, malloc_size)"マネージドPrometheusプラグインが提供するGPU APPダッシュボードを使用して、コンテナーのステータスを表示します。
次の図は、新しいアプリケーションのデプロイ後に既存のコンテナーが影響を受けないことを示しています。