Argoワークフローは、スケジュールされたタスク、機械学習タスク、抽出、変換、読み込み (ETL) タスクの構成に広く使用されている強力なワークフロー管理ツールです。 YAMLファイルを使用してワークフローを調整すると、課題が発生する可能性があります。 Heraは、Python用のArgoワークフローSDKです。 HeraはYAMLの代替手段であり、Pythonで複雑なワークフローを簡単に調整およびテストできます。 さらに、HeraはPythonエコシステムとシームレスに統合され、ワークフロー設計を大幅に簡素化します。 このトピックでは、Argo Workflows SDK for PythonのHeraを使用して大規模なワークフローを作成する方法について説明します。
背景情報
Argo Workflowsは、Kubernetes上の複雑なワークフローオーケストレーションを自動化するためのオープンソースのワークフローエンジンです。 Argoワークフローを使用して、タスクのコレクションを作成し、タスクの実行シーケンスと依存関係を設定できます。 これにより、カスタム自動ワークフローを効率的に作成および管理できます。
Argoワークフローは、スケジュールタスク、機械学習、シミュレーション、科学計算、抽出、変換、ロード (ETL) タスク、モデルトレーニング、継続的統合 /継続的配信 (CI/CD) パイプラインなどのシナリオで広く使用されています。 ArgoワークフローはYAMLファイルを使用して、わかりやすく簡単にワークフローを構成します。 これは、階層コード構造を構築するために厳密なインデントを必要とするYAML構文に慣れていない、または慣れていないユーザーに課題をもたらす可能性があります。 これは、これらのユーザにとって、長い学習曲線及び複雑な構成ステップにつながる可能性がある。

Heraは、Argoワークフローに基づくワークフローの作成と送信を目的としたArgo Workflows SDKです。 Heraは、ワークフローの作成と送信の手順を簡素化することを目的としており、YAMLではなくPythonに精通しているデータサイエンティストに適しています。 ヘラは次の利点を提供します。
シンプルさ: Heraは直感的で使いやすいコードを提供し、開発効率を大幅に向上させます。
複雑なワークフローのサポート: Heraは、複雑なワークフローオーケストレーションでのYAML構文エラーの解消に役立ちます。
Pythonエコシステムとの統合: 各関数はテンプレートで定義できます。 HeraはPythonフレームワークと統合されています。
Observability: Heraは、コードの品質と保守性の向上に役立つPythonテストフレームワークをサポートしています。
Distributed Cloud Container Platform for Kubernetes (ACK One) のワークフロークラスタは、サーバーレスモードで実行されます。 Argoワークフローは、ワークフロークラスターの管理コンポーネントです。 次の図は、ワークフロークラスターでのArgoワークフローのアーキテクチャを示しています。

手順1: ワークフロークラスターを作成し、アクセストークンを取得する
次のいずれかの方法を使用して、ワークフロークラスターのArgo Serverを有効にします。
Argo Serverのインターネットアクセスを有効にします。 この方法は、Express Connect回路を使用するユーザーにはオプションです。
次のコマンドを実行して、クラスターのアクセストークンを生成して取得します。
kubectl create token default -n default
ステップ2: ヘラを使い始める
次のコマンドを実行して、Heraをインストールします。
pip install hera-workflowワークフローを調整して送信します。
シナリオ1: シンプルなDAGダイヤモンド
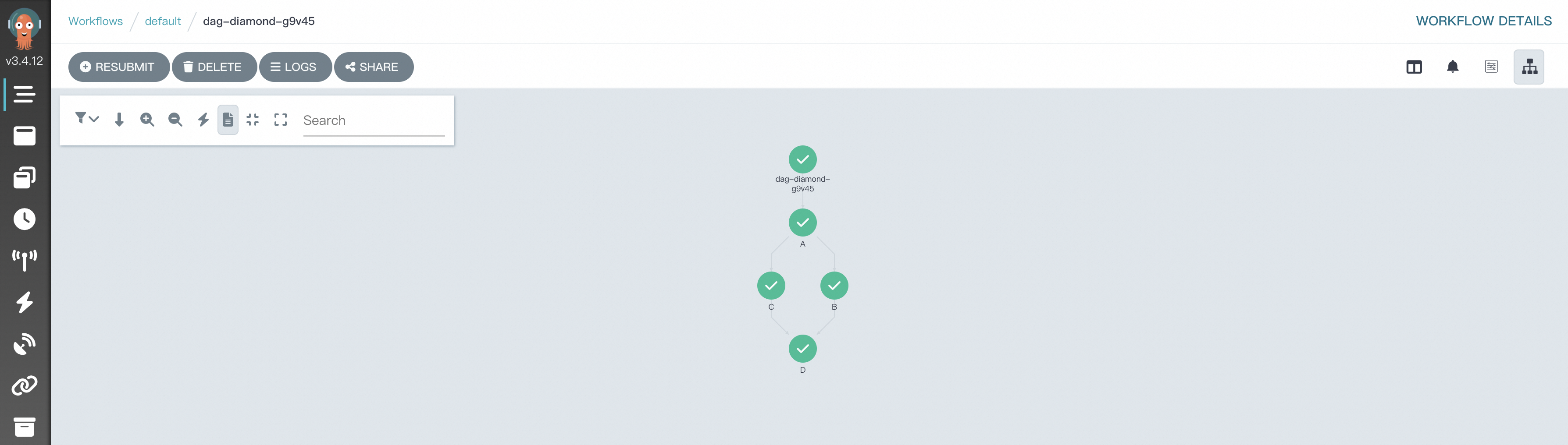
Argoワークフローは、有向非巡回グラフ (DAG) を使用して、ワークフロー内のタスクの複雑な依存関係を定義します。 ダイヤモンド構造は、ワークフローで一般的に採用されています。 ダイヤモンドワークフローでは、複数の並列タスクの実行結果が、後続のタスクの入力に集約されます。 Diamond構造は、データフローと実行結果を効率的に集約できます。 次のサンプルコードは、タスクaとタスクBが並行して実行され、タスクAとタスクBの実行結果がタスクCの入力に集約されるDiamondワークフローを調整するために、Heraを使用する方法の例を示しています。
simpleDAG.pyという名前のファイルを作成し、次の内容をファイルにコピーします。
# Import the required packages. from hera.workflows import DAG, Workflow, script from hera.shared import global_config import urllib3 urllib3.disable_warnings() # Specify the endpoint and token of the workflow cluster. global_config.host = "https://argo.{{clusterid}}.{{region-id}}.alicontainer.com:2746" global_config.token = "abcdefgxxxxxx" # Enter the token you obtained. global_config.verify_ssl = "" # The script decorator is the key to enabling Python-like function orchestration by using Hera. # You can call the function below a Hera context manager such as a Workflow or Steps context. # The function still runs as normal outside Hera contexts, which means that you can write unit tests on the given function. # The following code provides a sample input. @script() def echo(message: str): print(message) # Orchestrate a workflow. The Workflow is the main resource in Argo and a key class of Hera. The Workflow is responsible for storing templates, setting entry points, and running templates. with Workflow( generate_name="dag-diamond-", entrypoint="diamond", ) as w: with DAG(name="diamond"): A = echo(name="A", arguments={"message": "A"}) # Create a template. B = echo(name="B", arguments={"message": "B"}) C = echo(name="C", arguments={"message": "C"}) D = echo(name="D", arguments={"message": "D"}) A >> [B, C] >> D # Define dependencies. In this example, Task A is the dependency of Task B and Task C. Task B and Task C are the dependencies of Task D. # Create the workflow. w.create()次のコマンドを実行して、ワークフローを送信します。
python simpleDAG.pyワークフローの実行が開始されたら、[ワークフローコンソール (Argo)] に移動して、DAGプロセスと結果を表示できます。
シナリオ2: MapReduce
Argoワークフローでは、MapReduceスタイルでデータを処理するための鍵は、DAGテンプレートを使用して複数のタスクを整理および調整し、MapフェーズとReduceフェーズをシミュレートすることです。 次のサンプルコードは、Heraを使用して、テキストファイル内の単語をカウントするために使用されるサンプルMapReduceワークフローを調整する方法の詳細な例を示しています。 各ステップは、Pythonエコシステムと統合するためにPython関数で定義されます。
map-reduce.pyという名前のファイルを作成し、次の内容をファイルにコピーします。
次のコマンドを実行して、ワークフローを送信します。
python map-reduce.pyワークフローの実行が開始されたら、[ワークフローコンソール (Argo)] に移動して、DAGプロセスと結果を表示できます。

設定方法の比較
Argoワークフローは、YAMLとHera Frameworkの2つの設定方法をサポートしています。 次の表は、2つの方法を比較する。
機能 | YAML | Heraフレームワーク |
シンプリシティ | 比較的高い | 高い。 このメソッドは低コードです。 |
ワークフローオーケストレーションの複雑さ | 高い | 低い |
Pythonエコシステムとの統合 | 低い | 高い。 このメソッドは豊富なPythonライブラリと統合されています) |
テスト可能性 | 低い。 この方法は構文エラーが発生しやすいです。 | 高い。 このメソッドは、テストフレームワークをサポートします。 |
Hera Frameworkは、PythonエコシステムをArgoワークフローと適切に統合して、ワークフローオーケストレーションの複雑さを軽減します。 YAMLと比較して、Hera Frameworkは、大規模なワークフローオーケストレーションの単純化された代替手段を提供します。 さらに、Hera Frameworkを使用すると、データエンジニアはPythonを使用できます。 Hera Frameworkは、機械学習シナリオのシームレスで効率的なワークフローオーケストレーションと最適化も可能にします。 これにより、イテレーションを通じて創造的なアイデアを実際の展開に変換し、インテリジェントアプリケーションの効率的な実装と持続可能な開発を促進できます。
ACK Oneについてご質問がある場合は、DingTalkグループ35688562に参加してください。
関連ドキュメント
ヘラのドキュメント:
ヘラの詳細については、「ヘラの概要」をご参照ください。
Heraを使用してラージランゲージモデル (LLM) をトレーニングする方法の詳細については、「HeraでLLMをトレーニングする」をご参照ください。
YAMLデプロイ設定のサンプル:
YAMLファイルを使用してsimple-diamondをデプロイする方法の詳細については、「dag-diamond.yaml」をご参照ください。
YAMLファイルを使用してmap-reduceをデプロイする方法の詳細については、「map-reduce.yaml」をご参照ください。