このトピックでは、KServe を使用して、Alibaba Cloud Container Service for Kubernetes (ACK) に本番環境対応の DeepSeek モデル推論サービスをデプロイする方法について説明します。
背景情報
DeepSeek-R1 モデル
KServe
Arena
前提条件
GPU を含む Kubernetes クラスターを作成済みであること。詳細については、「クラスターに GPU ノードプールを追加する」をご参照ください。
kubectl を使用してクラスターに接続済みであること。詳細については、「kubectl を使用してクラスターに接続する」をご参照ください。
ack-kserve コンポーネントをインストール済みであること。詳細については、「ack-kserve コンポーネントをインストールする」をご参照ください。
Arena クライアントをインストール済みであること。詳細については、「Arena クライアントを設定する」をご参照ください。
GPU インスタンスの仕様とコスト見積もり
モデルパラメーターは、推論フェーズにおける GPU メモリの主な消費者です。必要な GPU メモリは、次の数式を使用して計算できます。
たとえば、デフォルトの精度が FP16 の 7B モデルを考えてみましょう。モデルパラメーターの数は 70 億です。データ型の精度あたりのバイト数は 2 バイト (16 ビット浮動小数点数 / 8 ビット/バイト) です。
モデルのロードに必要な GPU メモリに加えて、計算中の KV キャッシュサイズと GPU 使用率も考慮する必要があります。通常、バッファーが予約されます。したがって、ecs.gn7i-c8g1.2xlarge や ecs.gn7i-c16g1.4xlarge など、24 GiB の GPU メモリを持つ GPU インスタンスを使用することをお勧めします。GPU インスタンスタイプと課金の詳細については、「GPU 高速化コンピューティング最適化インスタンスファミリー」および「Elastic GPU Service の課金」をご参照ください。
モデルのデプロイメント
ステップ 1: DeepSeek-R1-Distill-Qwen-7B モデルファイルの準備
次のコマンドを実行して、ModelScope から DeepSeek-R1-Distill-Qwen-7B モデルをダウンロードします。
説明git-lfs プラグインがインストールされていることを確認してください。インストールされていない場合は、
yum install git-lfsまたはapt-get install git-lfsを実行できます。インストール方法の詳細については、「Git Large File Storage のインストール」をご参照ください。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git cd DeepSeek-R1-Distill-Qwen-7B/ git lfs pullOSS にディレクトリを作成し、モデルを OSS にアップロードします。
説明ossutil のインストールと使用方法の詳細については、「ossutil のインストール」をご参照ください。
ossutil mkdir oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7B ossutil cp -r ./DeepSeek-R1-Distill-Qwen-7B oss://<your-bucket-name>/models/DeepSeek-R1-Distill-Qwen-7B永続ボリューム (PV) と永続ボリューム要求 (PVC) を作成します。ターゲットクラスター用に
llm-modelという名前の PV と PVC を設定します。詳細については、「ossfs 1.0 静的プロビジョニングボリュームの使用」をご参照ください。コンソールの例
次の表に、サンプル PV の基本構成を示します。
設定項目
説明
PV タイプ
OSS
名前
llm-model
アクセス証明書
OSS にアクセスするための AccessKey ID と AccessKey Secret を設定します。
バケット ID
前のステップで作成した OSS バケットを選択します。
OSS パス
モデルが保存されているパスを選択します (例:
/models/DeepSeek-R1-Distill-Qwen-7B)。次の表に、サンプル PVC の基本構成を示します。
設定項目
説明
ストレージ要求のタイプ
OSS
名前
llm-model
割り当てモード
既存の PV を選択します。
既存の PV
リンクをクリックして既存の PV を選択し、作成した PV を選択します。
kubectl の例
以下はサンプル YAML ファイルです。
apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # OSS にアクセスするための AccessKey ID。 akSecret: <your-oss-sk> # OSS にアクセスするための AccessKey Secret。 --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # バケット名。 url: <your-bucket-endpoint> # エンドポイント (例: oss-cn-hangzhou-internal.aliyuncs.com)。 otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # この例では、パスは /models/DeepSeek-R1-Distill-Qwen-7B/ です。 --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model
ステップ 2: 推論サービスのデプロイ
次のコマンドを実行して、deepseek という名前の推論サービスを開始します。
arena serve kserve \ --name=deepseek \ --image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \ --gpus=1 \ --cpu=4 \ --memory=12Gi \ --data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \ "vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"次の表にパラメーターを示します。
パラメーター
必須
説明
--name
はい
送信する推論サービスの名前。名前はグローバルに一意である必要があります。
--image
はい
推論サービスのイメージアドレス。
--gpus
いいえ
推論サービスに必要な GPU の数。デフォルト値は 0 です。
--cpu
いいえ
推論サービスに必要な CPU の数。
--memory
いいえ
推論サービスに必要なメモリ量。
--data
いいえ
サービスのモデルパス。このトピックでは、モデルは前のステップで作成した
llm-modelPV として指定されます。PV はコンテナー内の /models/ ディレクトリにマウントされます。予想される出力:
inferenceservice.serving.kserve.io/deepseek created INFO[0003] The Job deepseek has been submitted successfully INFO[0003] You can run `arena serve get deepseek --type kserve -n default` to check the job status
ステップ 3: 推論サービスの検証
次のコマンドを実行して、KServe 推論サービスのデプロイメントステータスを確認します。
arena serve get deepseek予想される出力:
Name: deepseek Namespace: default Type: KServe Version: 1 Desired: 1 Available: 1 Age: 3m Address: http://deepseek-default.example.com Port: :80 GPU: 1 Instances: NAME STATUS AGE READY RESTARTS GPU NODE ---- ------ --- ----- -------- --- ---- deepseek-predictor-7cd4d568fd-fznfg Running 3m 1/1 0 1 cn-beijing.172.16.1.77出力は、KServe 推論サービスがデプロイされたことを示します。
次のコマンドを実行して、NGINX Ingress ゲートウェイの IP アドレスを使用して推論サービスにアクセスします。
# NGINX Ingress の IP アドレスを取得します。 NGINX_INGRESS_IP=$(kubectl -n kube-system get svc nginx-ingress-lb -ojsonpath='{.status.loadBalancer.ingress[0].ip}') # 推論サービスのホスト名を取得します。 SERVICE_HOSTNAME=$(kubectl get inferenceservice deepseek -o jsonpath='{.status.url}' | cut -d "/" -f 3) # リクエストを送信して推論サービスにアクセスします。 curl -H "Host: $SERVICE_HOSTNAME" -H "Content-Type: application/json" http://$NGINX_INGRESS_IP:80/v1/chat/completions -d '{"model": "deepseek-r1", "messages": [{"role": "user", "content": "Say this is a test!"}], "max_tokens": 512, "temperature": 0.7, "top_p": 0.9, "seed": 10}'予想される出力:
{"id":"chatcmpl-0fe3044126252c994d470e84807d4a0a","object":"chat.completion","created":1738828016,"model":"deepseek-r1","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n\n</think>\n\nIt seems like you're testing or sharing some information. How can I assist you further? If you have any questions or need help with something, feel free to ask!","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":9,"total_tokens":48,"completion_tokens":39,"prompt_tokens_details":null},"prompt_logprobs":null}
可観測性
本番環境における LLM 推論サービスの可観測性は、問題を積極的に発見して解決するために不可欠です。vLLM フレームワークは、多くの LLM 推論メトリックを提供します。詳細については、「メトリックドキュメント」をご参照ください。KServe は、モデルサービスのパフォーマンスと正常性を監視するのに役立つメトリックも提供します。これらの機能は Arena に統合されています。アプリケーションを送信するときに --enable-prometheus=true パラメーターを追加して有効にできます。
arena serve kserve \
--name=deepseek \
--image=kube-ai-registry.cn-shanghai.cr.aliyuncs.com/kube-ai/vllm:v0.6.6 \
--gpus=1 \
--cpu=4 \
--memory=12Gi \
--enable-prometheus=true \
--data=llm-model:/models/DeepSeek-R1-Distill-Qwen-7B \
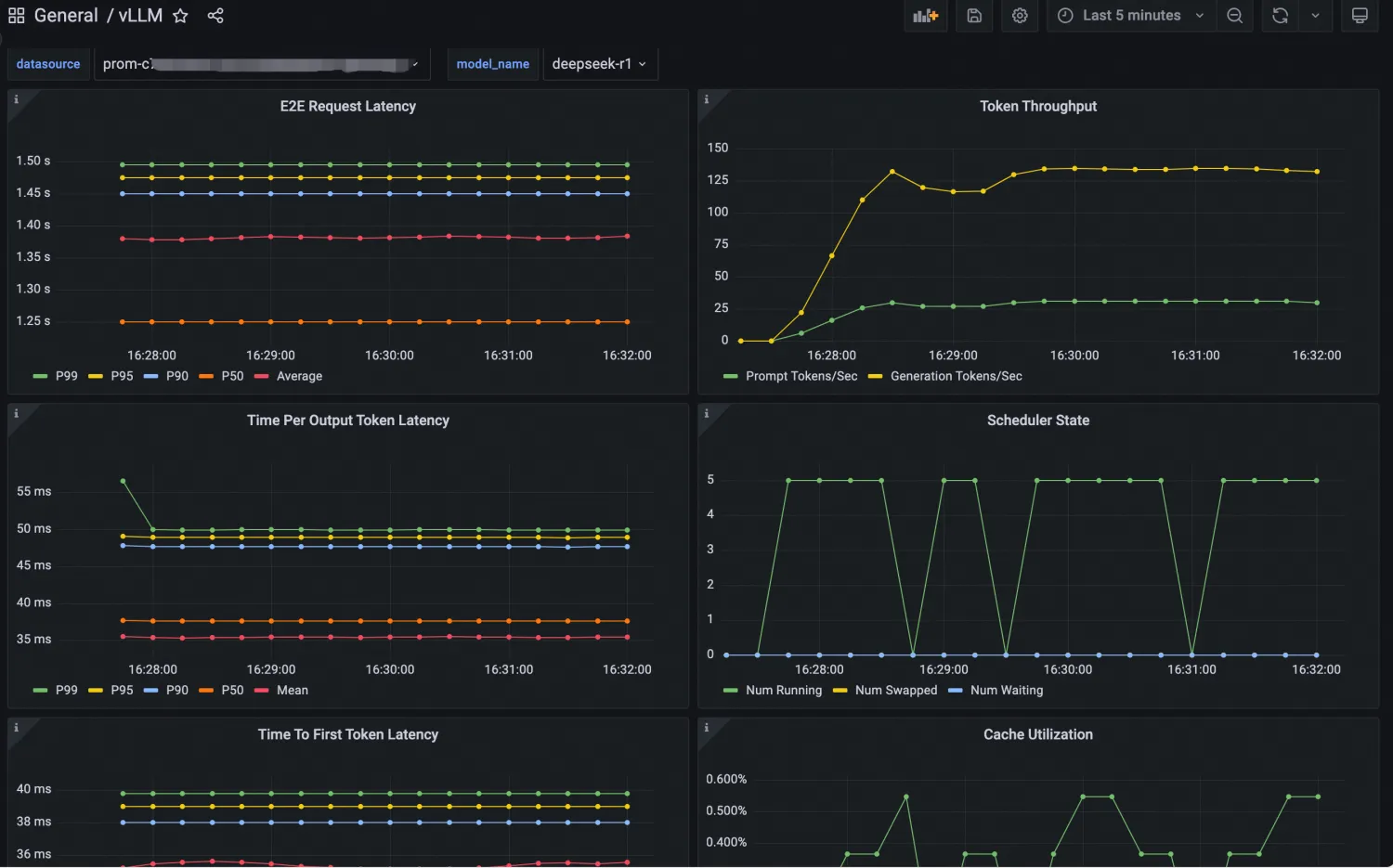
"vllm serve /models/DeepSeek-R1-Distill-Qwen-7B --port 8080 --trust-remote-code --served-model-name deepseek-r1 --max-model-len 32768 --gpu-memory-utilization 0.95 --enforce-eager"Grafana ダッシュボードを使用して、vLLM でデプロイされた LLM 推論サービスを監視できます。そのためには、vLLM Grafana JSON モデルを Grafana にインポートし、LLM 推論サービスの可観測性ダッシュボードを作成します。JSON モデルは vLLM 公式ウェブサイトから入手できます。 設定されたダッシュボードは次のように表示されます。
Grafana ダッシュボードのインポート手順
ダッシュボードのインポート
ARMS コンソールにログインします。
左側のナビゲーションウィンドウで、[統合管理] をクリックします。
[接続済み環境] タブで [コンテナー環境] を選択し、ACK クラスター名で環境を検索して、ターゲット環境をクリックします。
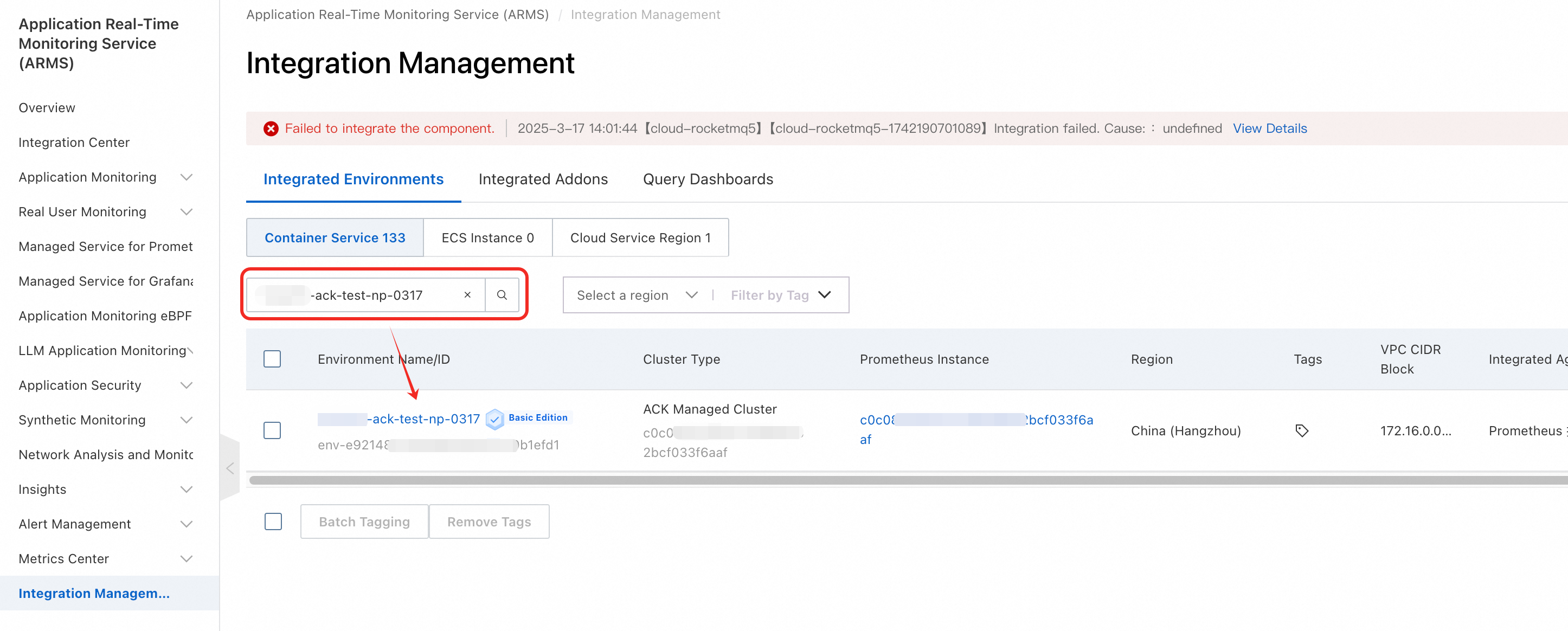
[コンポーネント管理] タブで、[クラスター ID] をコピーして保存し、[ダッシュボードディレクトリ] をクリックします。
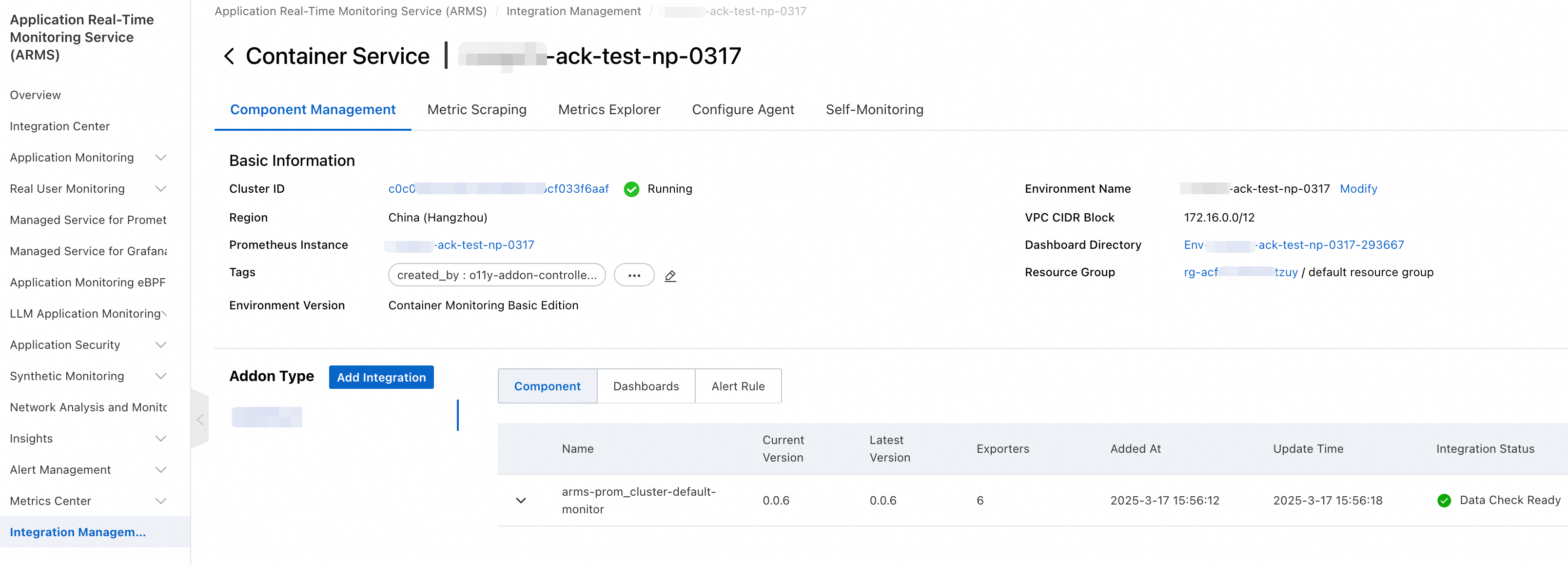
[ダッシュボード] タブの右側にある [インポート] ボタンをクリックします。
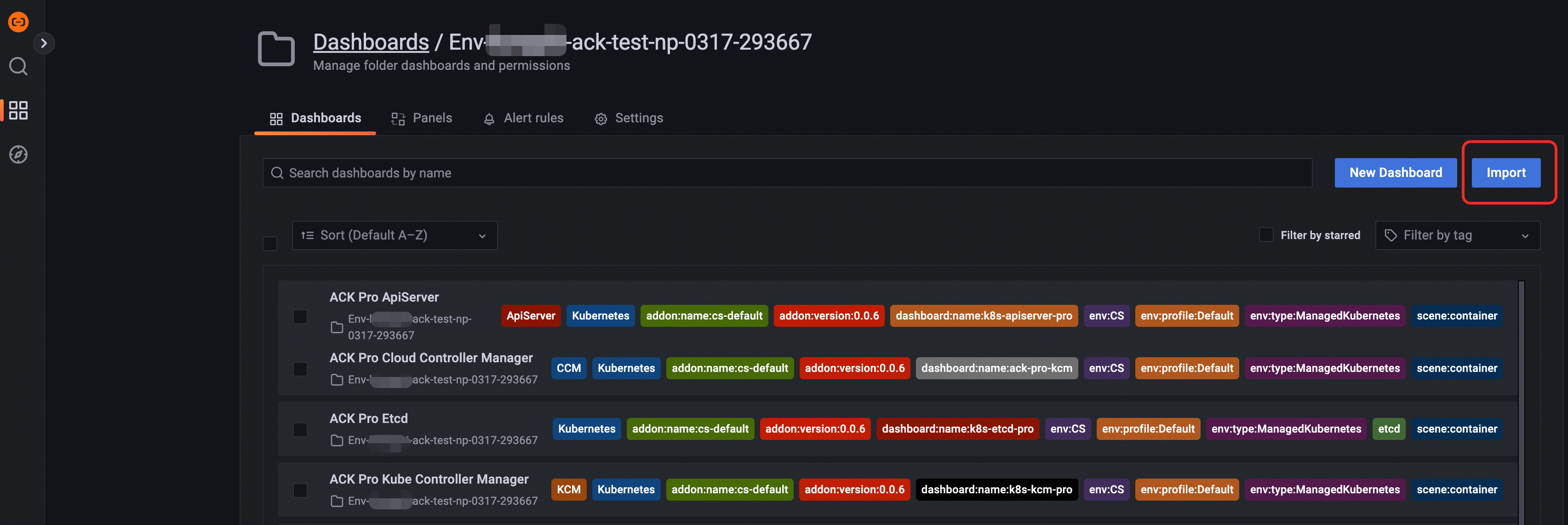
grafana.json ファイルの内容をコピーし、[パネル Json でインポート] エリアに貼り付けて、[ロード] ボタンをクリックします。
説明JSON ファイルをアップロードしてダッシュボードをインポートすることもできます。
デフォルト設定を維持し、[インポート] をクリックして LLM 推論サービスの可観測性ダッシュボードをインポートします。
ダッシュボードデータの検証
保存したクラスター ID または Prometheus インスタンス ID を使用してデータソースを検索し、ターゲットデータソースを選択します。
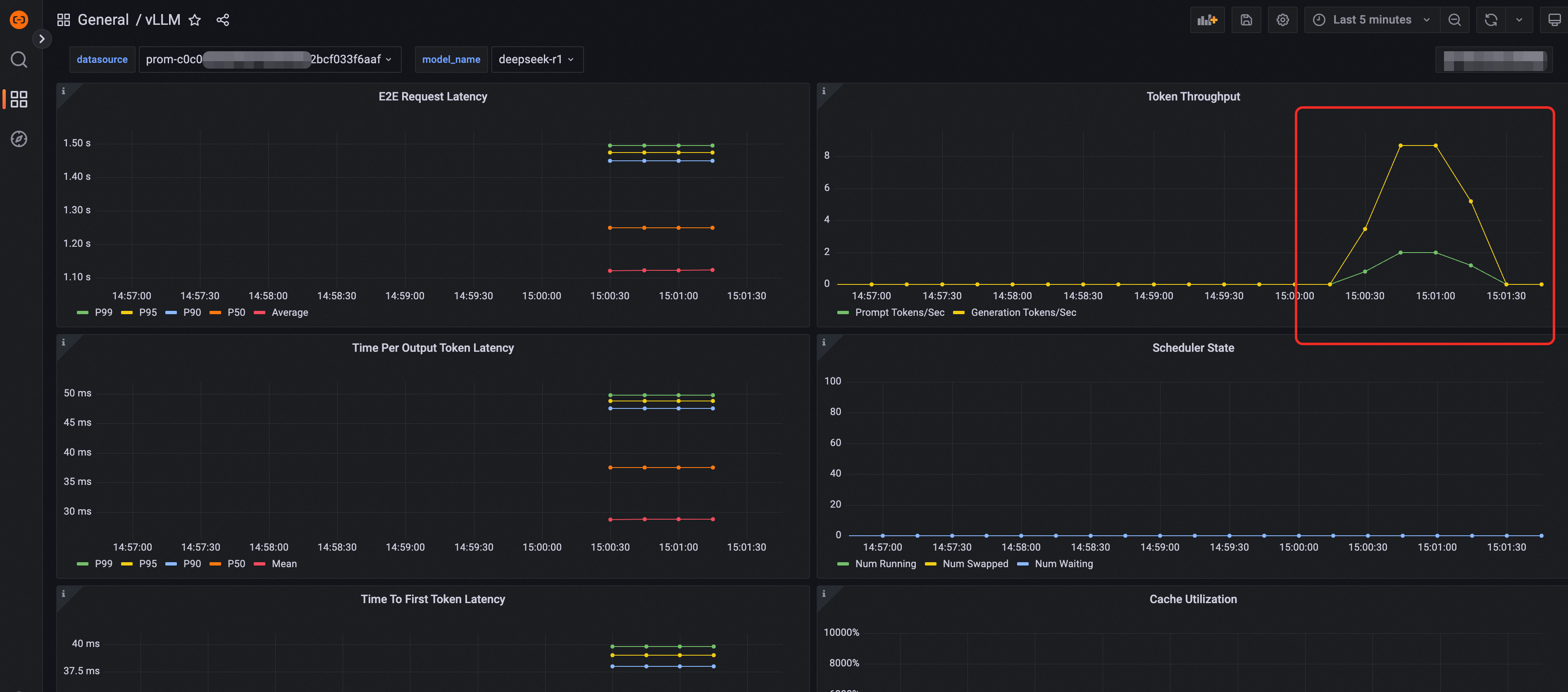
サービストラフィックをシミュレートするために推論サービスにアクセスするリクエストをいくつか送信し、[トークンスループット] などの LLM 推論サービスの可観測性ダッシュボード上のデータを検証します。
弾力的なスケーリング
KServe モデルサービスをデプロイおよび管理する際、動的な負荷変動が発生することがあります。KServe は、Kubernetes Horizontal Pod Autoscaler (HPA) と ACK の ack-alibaba-cloud-metrics-adapter コンポーネントを使用して、CPU、メモリ、GPU 使用率、およびカスタムパフォーマンスメトリックに基づいてモデルサービス Pod の数を自動的にスケーリングし、サービスの安定性と効率を確保します。詳細については、「サービスの自動スケーリングを設定する」をご参照ください。
モデルアクセラレーション
技術の発展に伴い、AI アプリケーションで使用されるモデルのサイズは増加しています。Object Storage Service (OSS) や File Storage NAS (NAS) などのストレージサービスから大きなファイルをプルすると、高レイテンシやコールドスタートなどの問題が発生する可能性があります。Fluid を使用すると、モデルの読み込み速度を大幅に高速化し、推論サービス、特に KServe ベースの推論サービスのパフォーマンスを最適化できます。詳細については、「Fluid を使用したモデルアクセラレーション」をご参照ください。
段階的リリース
段階的リリースは、本番環境でビジネスの安定性を確保し、変更に伴うリスクを最小限に抑えるための重要な戦略です。ACK は、トラフィックの割合に基づくアプローチやリクエストヘッダーに基づくアプローチなど、さまざまな段階的リリースポリシーをサポートしています。詳細については、「推論サービスの段階的リリースを実装する」をご参照ください。
GPU 共有推論
DeepSeek-R1-Distill-Qwen-7B モデルは、14 GB の GPU メモリしか必要としません。より高いスペックの GPU を使用する場合は、GPU 共有推論技術を使用して GPU 使用率を向上させることを検討してください。この技術は GPU をパーティション分割し、複数の推論サービスがそれを共有できるようにすることで、全体的な GPU 使用率を向上させます。詳細については、「GPU 共有推論サービスをデプロイする」をご参照ください。