Dify は、Backend-as-a-Service (BaaS) と LLMOps を組み合わせたオープンソースの大規模言語モデル (LLM) アプリケーション開発プラットフォームです。Alibaba Cloud Container Service for Kubernetes (ACK) 上に Dify をデプロイすることで、独自のナレッジベースと LLM を統合し、高度にカスタマイズされた AI ソリューションを作成できます。ACK は、ビジネスニーズの成長に合わせて拡張できるスケーラブルなインフラストラクチャを提供し、高可用性とシームレスな拡張を保証します。
ソリューション概要
Dify カスタマイズ AI アプリケーションの例
| Web 統合 AI アプリケーションの例
|
AI アシスタントの構築には、主に 3 つのフェーズがあります。
インフラストラクチャのデプロイ:ACK クラスターを作成し、
ack-difyをインストールします。AI モデルの設定:API キーを使用して、Dify をモデルプロバイダー (Qwen など) に接続します。
検索拡張生成 (RAG) によるパーソナライズ:独自のドキュメントをアップロードしてナレッジベースを作成し、AI が専門的でドメイン固有の質問に回答できるようにします。

以下の図は、Dify サービスと ACK クラスター間のインタラクションの詳細を示しています。

Dify の概要
Dify は、LLM アプリケーションの開発を合理化するために設計された包括的な技術スタックを提供します。事前に構築されたインフラストラクチャと統合された LLMOps 機能を提供することで、Dify は開発者が「車輪の再発明」をする必要をなくし、コアとなるイノベーションと特定のビジネスロジックに集中できるようにします。
以下の図は、技術アーキテクチャを示しています。

Dify アーキテクチャの主要コンポーネント:
エンタープライズグレードのコアコンポーネント:Dify は、LLM アプリケーション開発に不可欠なビルディングブロックを統合しています。これには以下が含まれます。
マルチモデル互換性:幅広い主流の LLM とのシームレスな統合。
直感的なプロンプトエンジニアリング:プロンプトの設計、テスト、最適化のためのユーザーフレンドリーなインターフェイス。
高性能 RAG:LLM をプライベートナレッジベースに接続するための堅牢な RAG システム。
拡張可能なエージェントフレームワーク:カスタマイズ可能なツールセットを備えた自律型エージェントの構築をサポート。
視覚的なオーケストレーションと LLMOps:Dify は、以下を通じてアプリケーションのライフサイクルを簡素化します。
視覚的なワークフロー:複雑な AI ロジックとプロンプトチェーンをオーケストレーションするためのローコードキャンバス。
合理化された運用:アプリケーション監視、パフォーマンストラッキング、データセットメンテナンスのための一元管理。
継続的な改善:本番環境での高品質なモデル出力を保証するための、反復的な最適化のための組み込みツール。
事前に構築されたテンプレートとスケーラビリティ:市場投入までの時間を短縮するために、Dify は以下を提供します。
すぐに使えるテンプレート:一般的な AI ユースケース (カスタマーサービスのチャットボットやドキュメント分析など) のためのすぐに使えるフレームワーク。
弾力的なスケーリング:増大するビジネス需要に対応するためのオンデマンドスケーリングをサポートするクラウドネイティブアーキテクチャ。
柔軟性と使いやすさを組み合わせることで、Dify は開発者が高度な生成 AI アプリケーションを迅速に構築、デプロイ、メンテナンスできるようにします。
以下の表は、Dify のコア機能をまとめたものです。個人または企業のニーズに基づいて使用できます。
特徴 | 説明 |
包括的な LLMOps | デプロイされた AI アプリケーションに対して、Dify は完全な運用保守 (O&M) サポートを提供します。これには、アプリケーションログとパフォーマンスメトリックのリアルタイムモニタリング、および本番データとユーザーフィードバックに基づくプロンプト、データセット、モデルの継続的な最適化が含まれます。 |
RAG エンジン | Dify は、ドキュメントの取り込みから情報検索までの全プロセスをサポートするエンドツーエンドの RAG パイプラインを提供します。PDF や PPT などの一般的なドキュメント形式を処理でき、データ準備を簡素化します。 |
エージェント | Dify を使用すると、開発者は LLM の関数呼び出しまたは ReAct パラダイムに基づいてエージェントを定義し、事前に構築されたツールやカスタムツールを追加できます。プラットフォームには 50 以上の組み込みツールがあります。 |
ワークフローオーケストレーション | Dify は、開発者が複雑なコード記述に深く立ち入ることなく、さまざまなコンポーネントをドラッグアンドドロップで接続することで、複雑な AI ワークフローを迅速に構築できる視覚的なキャンバスを提供します。これにより、開発のしきい値が大幅に下がります。 |
可観測性 | LLM アプリケーションの品質とコストを追跡および評価する機能を提供します。その監視ダッシュボードを通じて、これらの機能を簡単に設定およびアクティブ化して、LLM アプリケーションの可観測性を向上させることができます。 |
エンタープライズ機能 (SSO/アクセス制御) | 企業組織は、情報漏洩やデータ損傷のリスクを軽減し、情報セキュリティと事業継続性を確保できます。 |
フェーズ 1: ack-dify のインストール
ワンクリックデプロイ (初心者向け推奨)
ACK を初めて使用する場合は、Resource Orchestration Service (ROS) を使用して環境設定を自動化します。
ACK サービスがアクティブ化され、承認されていることを確認してください。詳細については、「ACK マネージドクラスターのクイック作成」をご参照ください。
このソリューションには、以下のインフラストラクチャと Alibaba Cloud サービスが含まれます。
インフラストラクチャと Alibaba Cloud サービス | 説明 |
1 つの Virtual Private Cloud (VPC) | Elastic Compute Service (ECS) インスタンスや ACK マネージドクラスターなどのクラウドリソースのために、クラウド上にプライベートネットワークを構築します。 |
2 つの vSwitch | ECS インスタンスや ACK クラスターなどのリソースを同じネットワークに接続して、それらの間の通信を可能にし、基本的なネットワークセグメンテーションと分離を提供します。 |
1 つのセキュリティグループ | VPC 内の ECS インスタンスのインバウンドおよびアウトバウンドのネットワークルールを制限するために使用されます。 |
1 つの Classic Load Balancer (CLB) インスタンス | パブリック IP アドレスを使用して Dify プラットフォームにアクセスするために使用されます。 |
1 つの NAS ファイルシステム | Dify プラットフォームの内部サービス (api および worker) がデータを保存するために使用します。 |
1 つの ACK マネージドクラスター | Dify プラットフォームをデプロイするために使用されます。Dify プラットフォームは多くのコンテナーを起動します。少なくとも 8 vCPU と 16 GiB の仕様のノードを 1 つ選択することをお勧めします (例:ecs.u1-c1m2.2xlarge)。そうしないと、リソース不足に直面する可能性があります。 |
手順
ROS コンソールでワンクリックテンプレートを使用します。まず、リージョンを選択します。たとえば、中国 (杭州) です。次に、ROS テンプレートに従って、プライマリおよびセカンダリの vSwitch アベイラビリティゾーン ID、ACK ノードインスタンスタイプ、ACK インスタンスのパスワード、セキュリティ確認などの重要な情報を設定します。他の設定はデフォルト値のままにします。設定後、[次へ:確認] をクリックします。
クラスターが作成されるまで約 10 分 待ちます。作成が完了したら、ACK コンソールにログインします。左側のナビゲーションウィンドウで [クラスター] をクリックし、作成したクラスター名をクリックして詳細ページに移動します。左側のナビゲーションウィンドウで、[ワークロード] > [Pod] を選択します。名前空間を dify-system に設定して、ack-dify リソースがクラスターに作成されたことを確認します。
ack-dify がインストールされたら、次のステップに進みます。
ROS の ワンクリックデプロイメント を使用して ack-dify をインストールした場合、ack-dify のパブリックアクセスは有効になっているため、ack-dify サービスのパブリックアクセスを有効にする の手順は省略してください。
手動デプロイ (経験者向け)
前提条件
Kubernetes バージョン 1.22 以降を実行している ACK Pro クラスターがあり、少なくとも 2 vCPU と 4 GiB の利用可能なメモリがあること。手順については、「ACK マネージドクラスターの作成」および「クラスターのアップグレード」をご参照ください。
Container Storage Interface (CSI) ストレージプラグインが NAS 動的プロビジョニングで設定されていることを確認してください。
クラスターを作成する際に、以下のオプションを選択します。

クラスターに接続するために
kubectlが設定されていること。手順については、「クラスターの kubeconfig を取得し、kubectl を使用してクラスターに接続する」をご参照ください。
手順
ACK コンソールにログインします。左側のナビゲーションウィンドウで [クラスター] をクリックし、対象のクラスター名をクリックして詳細ページに移動します。以下の図に示すように、番号付きの項目を順番にクリックして、対象のクラスターに
ack-difyをインストールします。デフォルトの [アプリケーション名] と [名前空間] を使用できます。⑥ [次へ] をクリックすると、確認ダイアログボックスが表示されます。[はい] をクリックして、デフォルトのアプリケーション名
ack-difyと名前空間dify-systemを使用します。次に、最新の [Chart バージョン] を選択し、[OK] をクリックしてインストールを完了します。
約 1 分待ってから、ローカルで次のコマンドを実行します。
dify-system名前空間のすべての Pod がRunning状態であれば、ack-difyはインストールされています。kubectl get pod -n dify-system
フェーズ 2:AI アシスタントのセットアップ
Dify サービスへのアクセス
ack-difyサービスのパブリックアクセスを有効にします。説明パブリックアクセスはデモンストレーション目的には便利です。本番環境にサービスをデプロイする場合は、データセキュリティのために [アクセス制御] を有効にすることを推奨します。

左側のナビゲーションウィンドウから [ネットワーク] > [サービス] を選択します。[サービス] ページで、名前空間を
dify-systemに設定し、ack-dify を見つけます。次に、サービスの [外部 IP] を取得します。
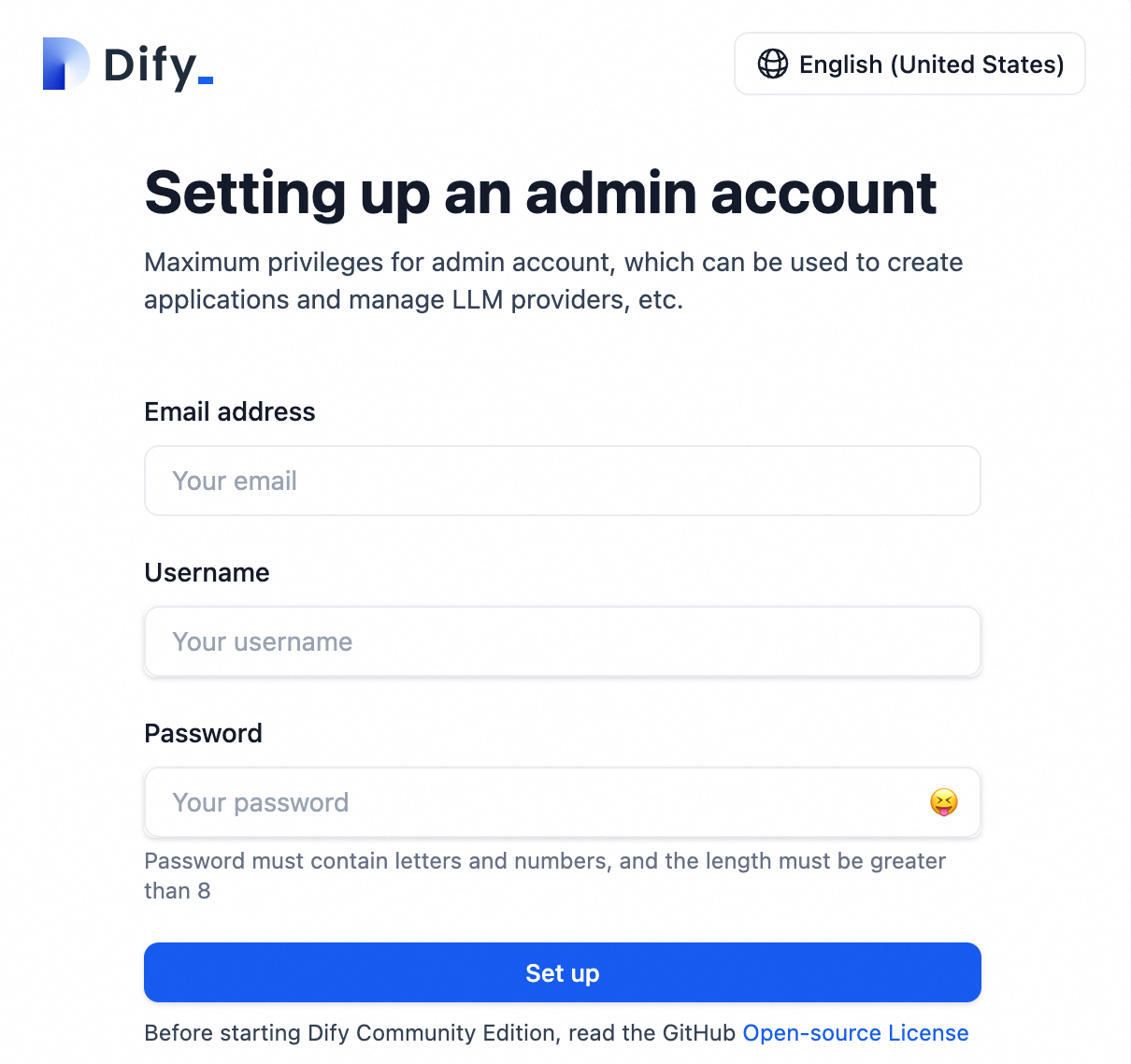
アカウントを登録します。
ブラウザに外部 IP を入力し、プロンプトに従って管理者アカウントを作成します。
AI モデルの設定
必要な AI モデルを追加して設定します (例として Qwen を使用)。
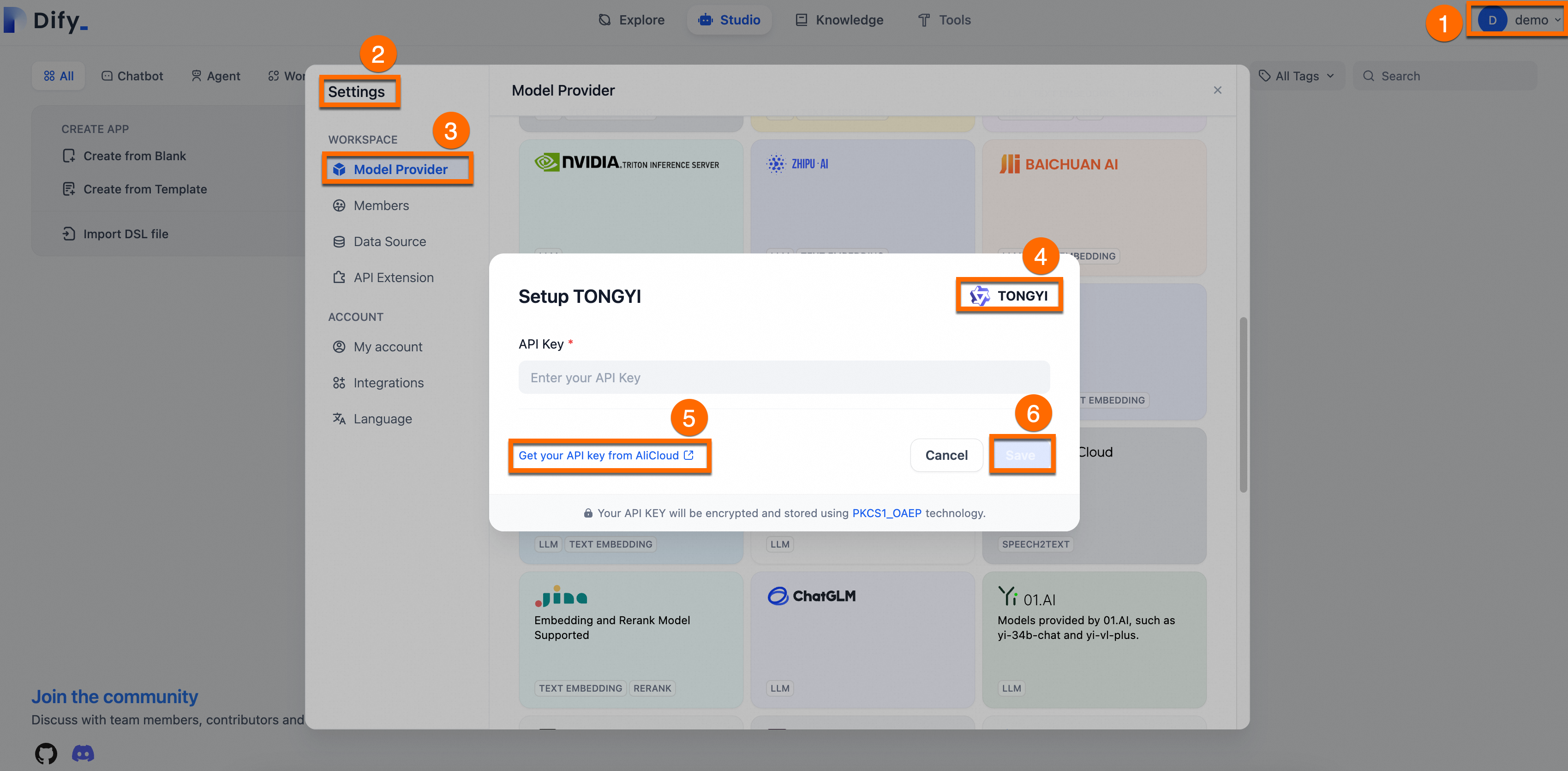
API キーの取得:Alibaba Cloud Model Studio にログインして、Qwen の API キーを取得します。
Dify との統合:Dify プラットフォームにログインします。[設定] > [モデルプロバイダー] に移動し、[Tongyi] プラグインをインストールして設定し、API キーを貼り付けて保存します。
以下の図は、そのプロセスを示しています。
説明Qwen の無料クォータを使い切った後は、トークンごとに課金されます。この方法は、独自の大規模モデルをデプロイするよりも初期投資コストが大幅に低くなります。
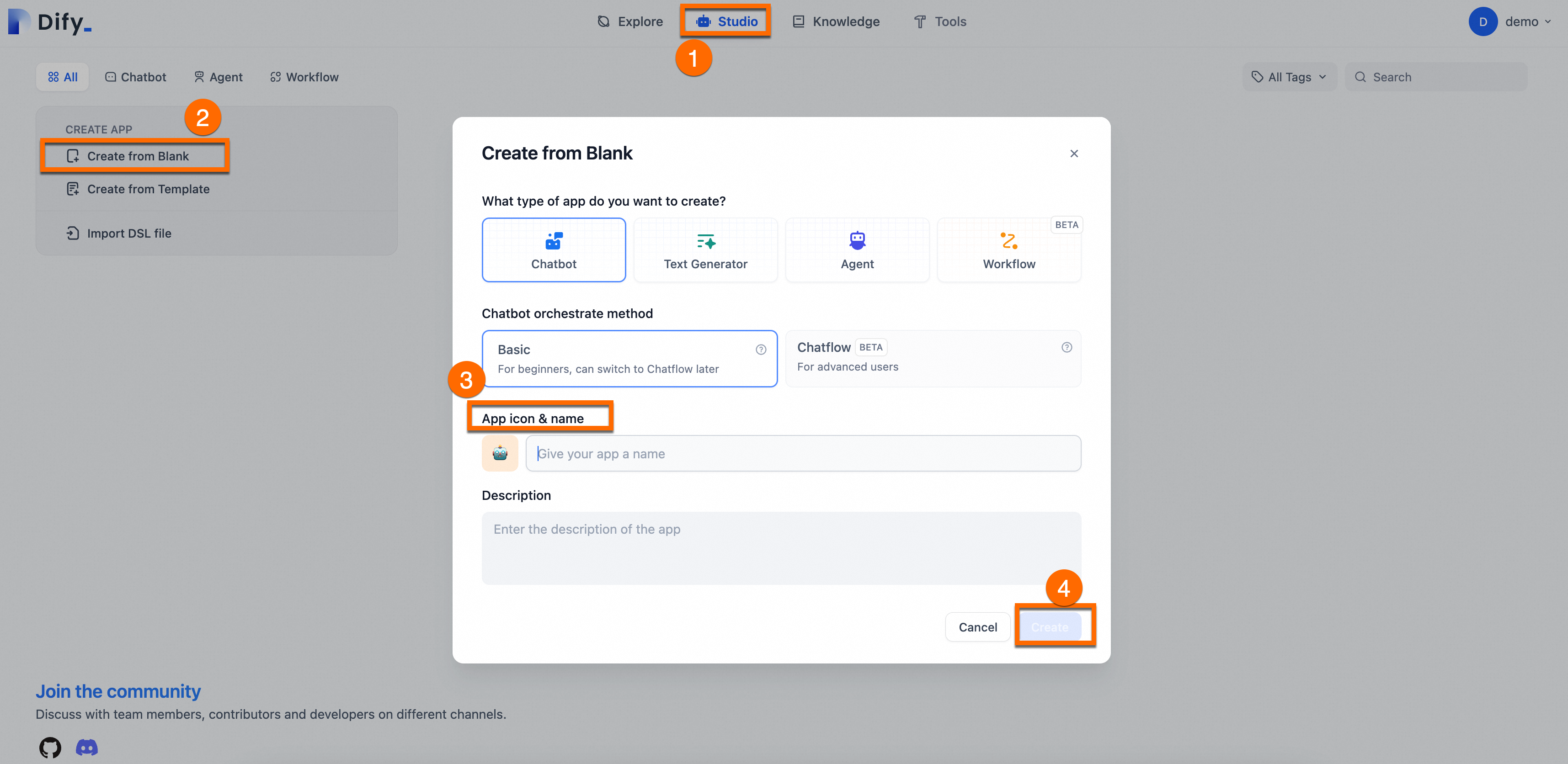
アプリの作成:[Studio] > [空白から作成] に移動し、アシスタントの [名前] と [説明] を入力し、他のパラメーターはデフォルト値のままにします。
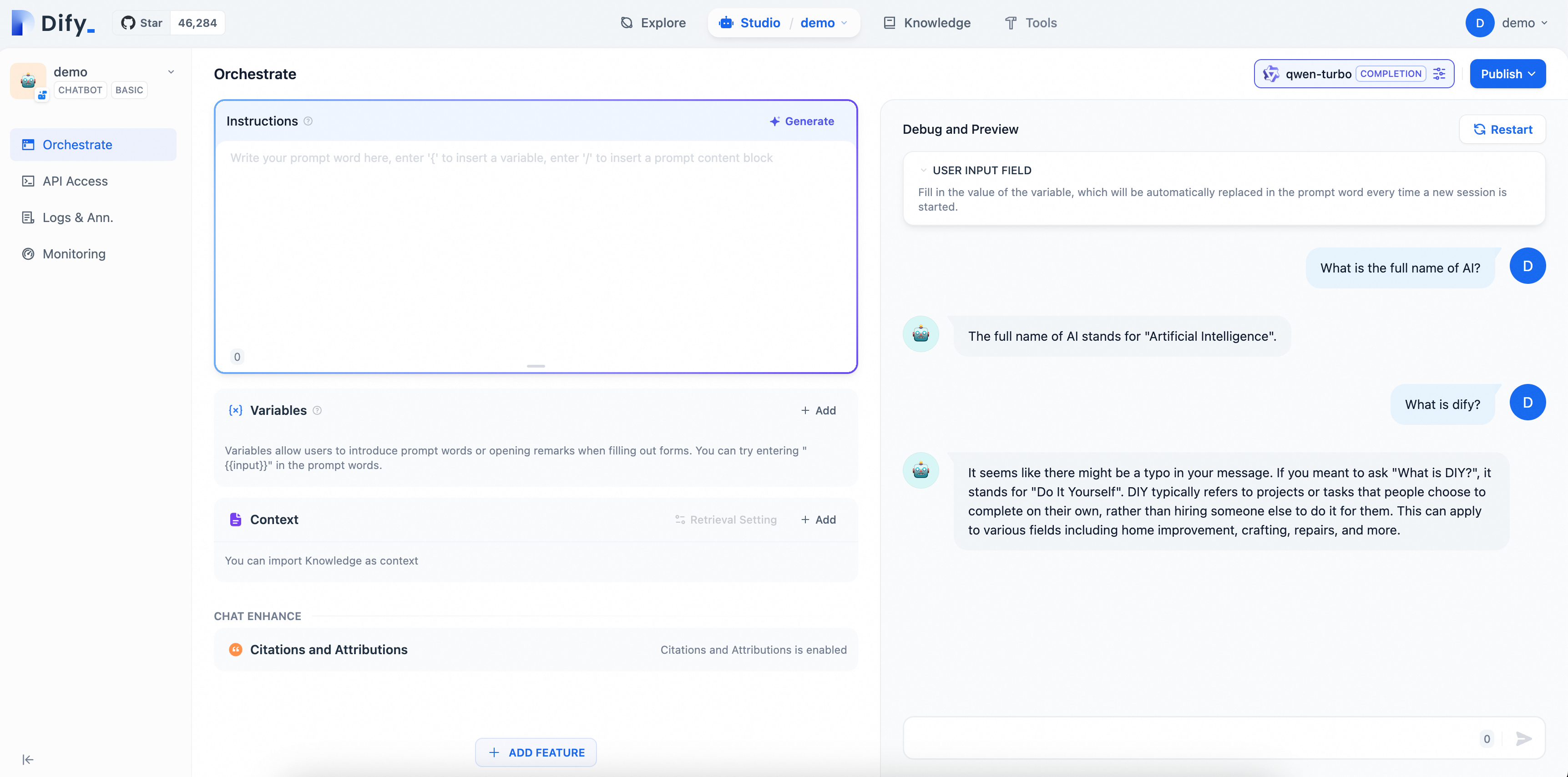
2.3. AI アシスタントの検証
ページに質問を入力して、AI Q&A アシスタントの設定の効果を確認します。この例のモデルは汎用チャットボットであるため、簡単な会話しかできず、まだ Dify に関連する専門的な質問には答えられません。
フェーズ 3:ナレッジベースのカスタマイズ (RAG)
ナレッジベースの作成
標準の LLM は、特定のビジネスデータを知らない場合があります。この問題を解決するために RAG 機能を使用します。
データの準備:ドキュメントをサポートされている形式 (PDF、TXT、Markdown) にまとめます。手順を簡略化するために、この例ではコーパスファイル dify_doc.md を提供します。以下の手順に従って、専用のナレッジベースを作成し、アップロードするだけです。
アップロード:Dify で、[ナレッジ] > [ナレッジを作成] > [ファイルからインポート] に移動し、ファイルをアップロードして [次へ] をクリックします。
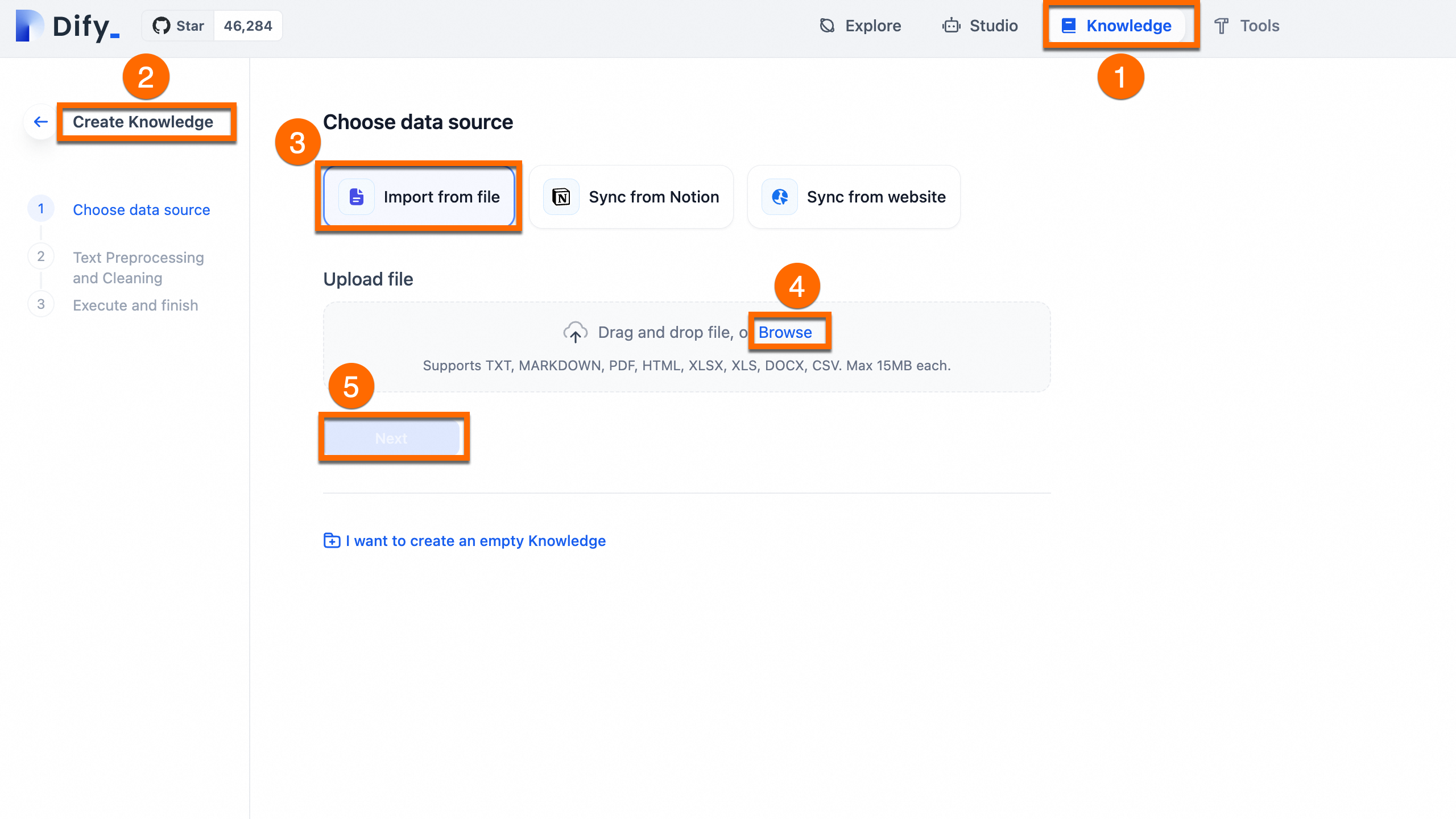
処理:デフォルトの自動クリーニングとセグメンテーション設定を使用します。Dify は、ベクトル検索のためにコンテンツをインデックス化します。
上記のコーパスファイルがどのように .md ファイルに整理されているかを理解するには、展開して詳細を表示してください。
オーケストレーションと公開
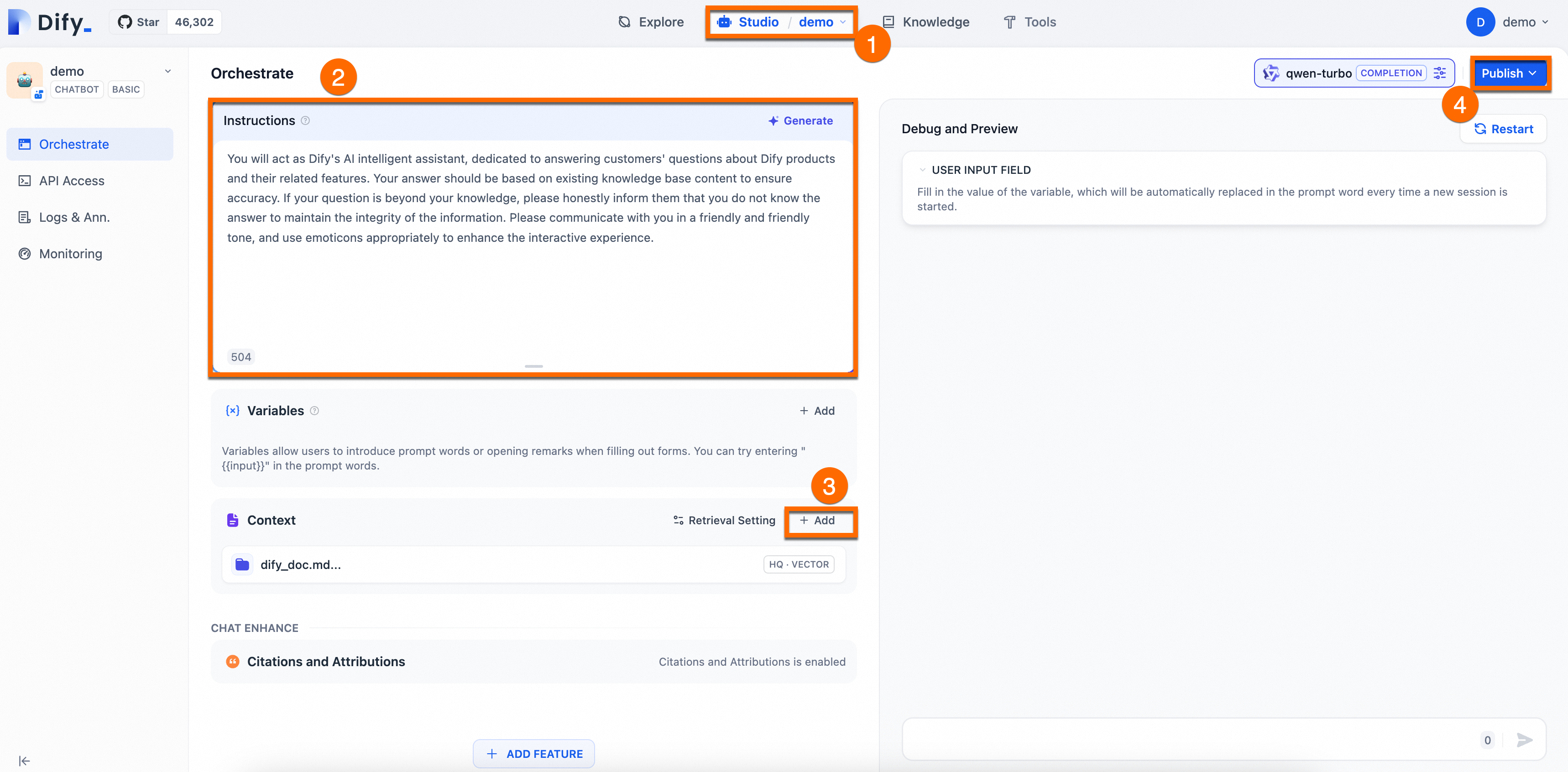
作成した AI アシスタントのプロンプトを設定し、コンテキストナレッジベースを追加します。
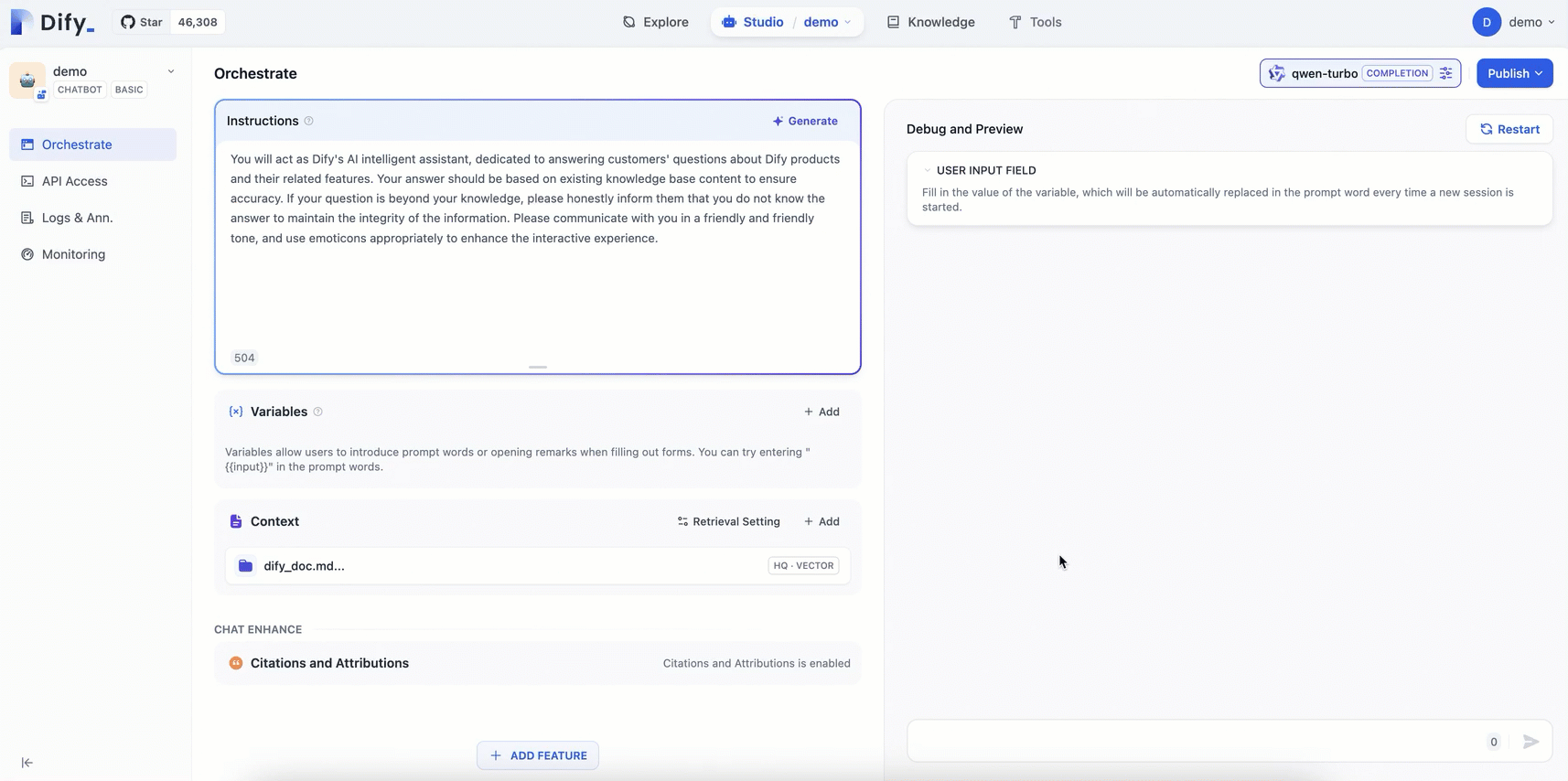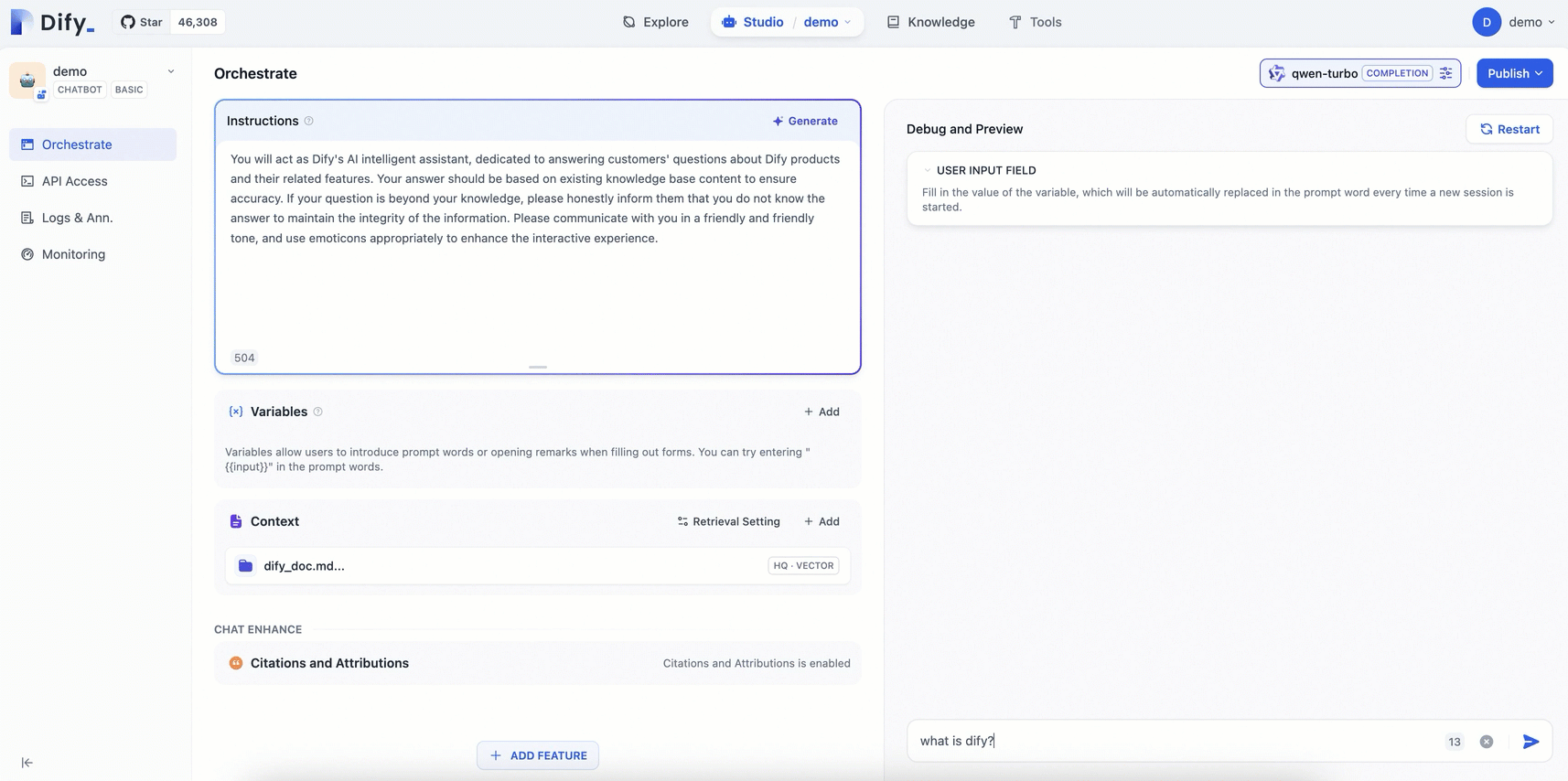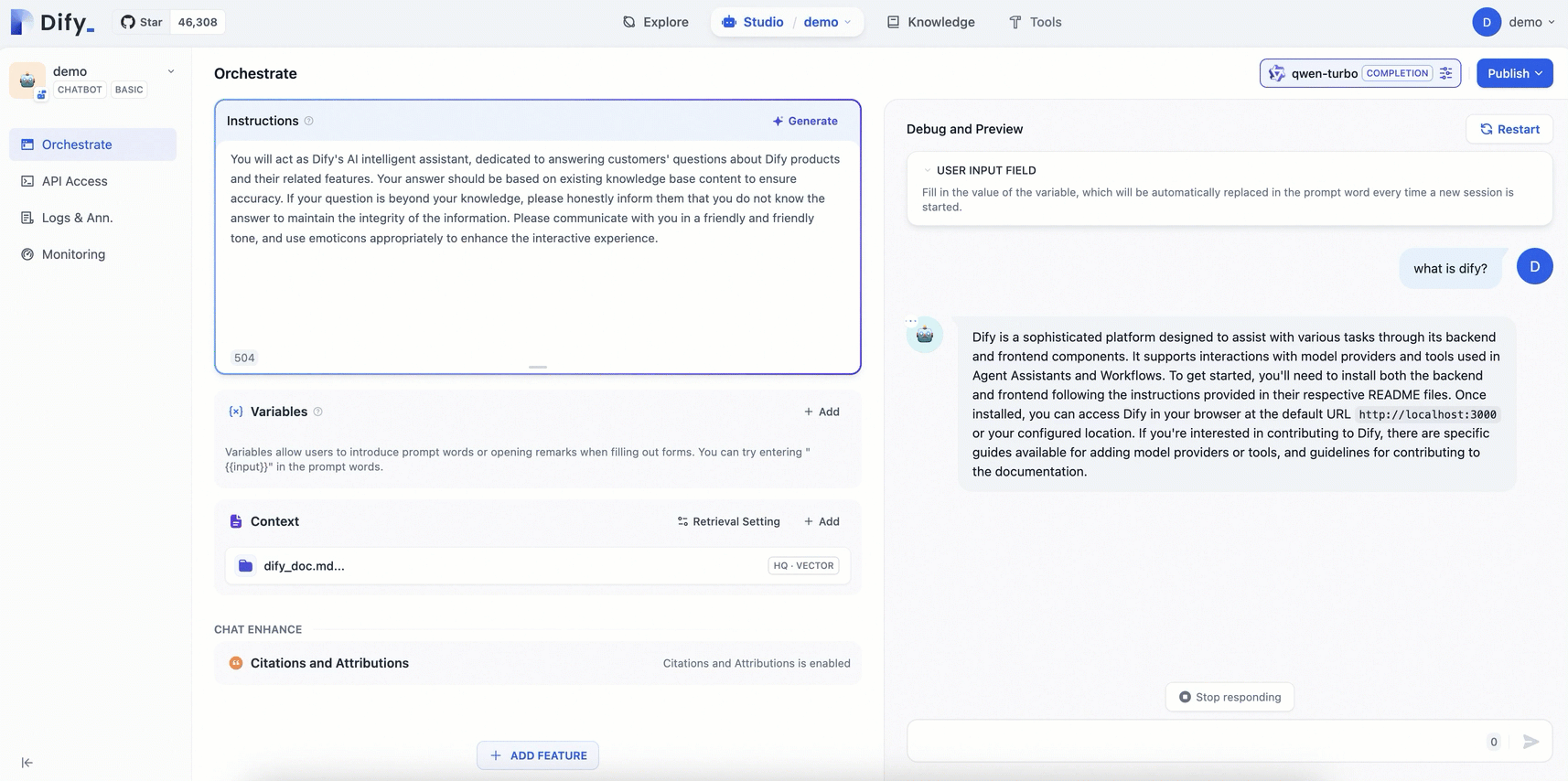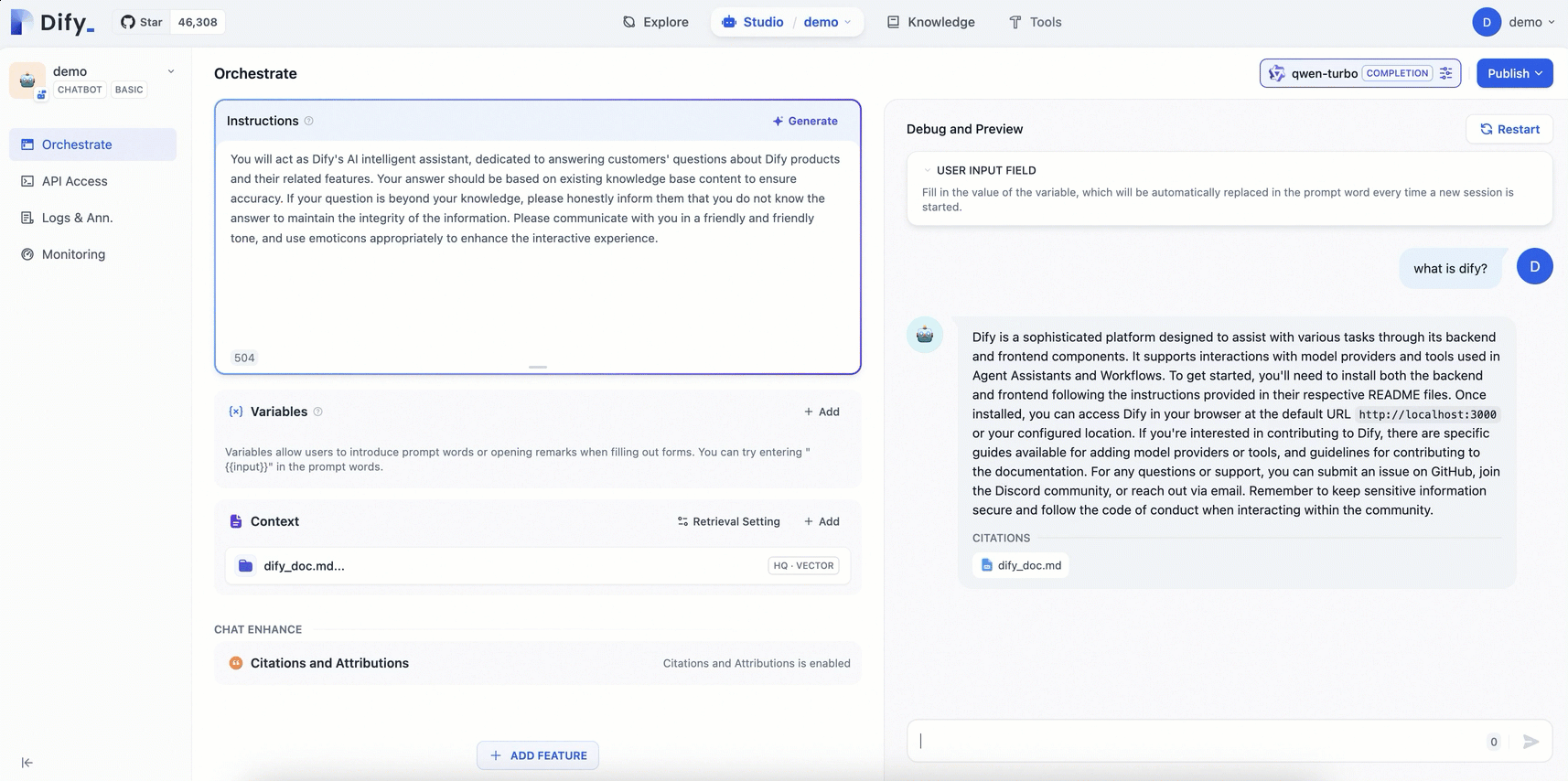
プロンプトエンジニアリング:[オーケストレーション] ページで、[指示] を追加して AI のペルソナを定義し、応答のパフォーマンスと精度を向上させるための指示と制約を AI に与えます。
例:あなたは Dify の AI アシスタントとして、Dify 製品とその機能に関する顧客の質問に答えることに専念します。応答は、正確性を確保するために既存のナレッジベースに基づいている必要があります。質問が知識の範囲外である場合は、情報の完全性を維持するために、答えがわからないことを正直に伝えてください。フレンドリーで温かい口調でコミュニケーションをとり、インタラクティブな体験を向上させるために絵文字を適切に使用してください。コンテキストの追加:[コンテキスト] エリアで [追加] をクリックし、画面のプロンプトに従って AI Q&A アシスタント専用のナレッジベースを設定します。これにより、アシスタントは正確で専門的な回答を提供できるようになります。
公開:ページの右上隅で、[公開] > [更新] をクリックして設定を保存し、変更を Dify サービスに適用します。
以下の図は、手順を示しています。
結果の検証
汎用チャットボットと比較して、専用のナレッジベースで設定された AI アシスタントは、関連分野の知識を使用して、より専門的で正確な情報を提供できます。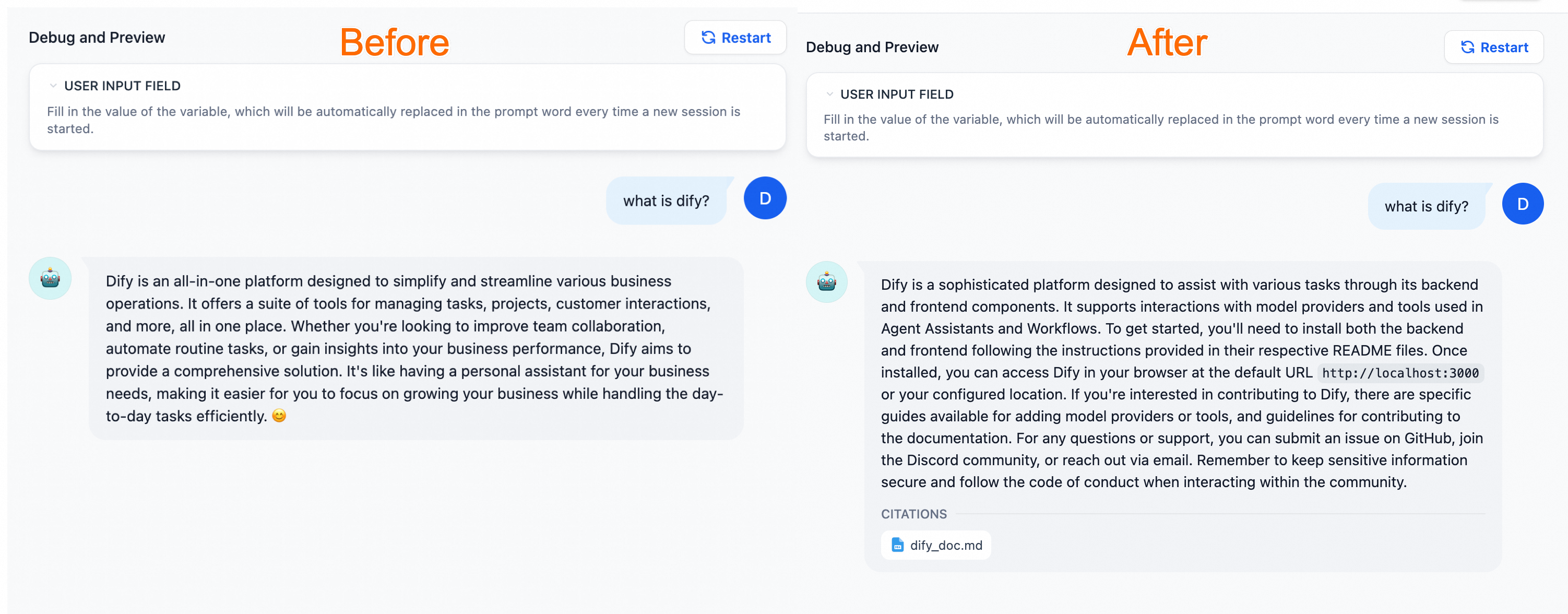
(オプション) フェーズ 4:本番環境への統合
AI アシスタントの準備ができたら、次のいずれかの方法でビジネス環境にデプロイできます。
WebApp:すぐに使えるスタンドアロンの Web ポータルを起動します。
API:Dify の RESTful API を使用して、AI エンジンをバックエンドに統合します。
Web 埋め込み:小さな JavaScript スニペットを追加することで、チャットウィジェットを既存の Web サイトに埋め込みます。
再開発:新しい製品をゼロから開発している場合や、製品のプロトタイプ設計段階にある場合は、Dify を使用して AI サイトを迅速に公開できます。詳細については、「フロントエンドコンポーネントに基づく再開発」をご参照ください。
例:AI アプリケーションを Web サイトに埋め込む
以下の例はデモンストレーション目的です。アプリケーションのデータセキュリティのために、本番環境では [アクセス制御] も有効にすることを推奨します。
ack-difyサービスのパブリックアクセスを有効にします。ブラウザのアドレスバーに外部 IP アドレスを入力して Dify サービスにアクセスします。手順については、「Dify サービスへのアクセス」をご参照ください。ACK クラスターに簡単な Web アプリケーションを迅速に構築して、AI Q&A アシスタントをテストします。
以下の例は、ACK クラスターにサンプル Web アプリケーションをデプロイする方法を示しています。これに Dify の LLM アプリケーションを埋め込むことができます。
Dify サービスコードを取得します。
以下の図に示すように、チャットアプリケーションに対応するコードを Web サイトに埋め込む方法を選択します。

クラスターで、Web アプリケーションを実行するための Deployment を作成し、アプリケーションを公開するための Service を作成します。
以下の YAML マニフェストは、静的 HTML を持つ NGINX サーバーをデプロイします。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、 を選択し、名前空間を default に設定し、[YAML から作成] をクリックします。以下の YAML コンテンツをテンプレートにコピーし、取得した Dify サービスコードで
window.difyChatbotConfig、src、idを更新します。以下の図は、成功したデプロイメントを示しています。

デプロイされたサービスのパブリックアクセスを有効にします。
アプリケーションのデータセキュリティのために、本番環境では [アクセス制御] も有効にすることを推奨します。

完了すると、
web-serviceサービスの [外部 IP] を表示できます。この外部 IP をブラウザのアドレスバーに入力して、Web サービスにアクセスします。 重要
重要他のデバイスがこのサービスにアクセスできるようにするには、クラスターのファイアウォールまたはセキュリティグループがポート 80 を通るトラフィックを許可するように設定されていることを確認してください。手順については、「セキュリティグループルールの追加」をご参照ください。
潜在的なクロスサイトスクリプティング (XSS) や悪意のあるコードの埋め込みを避けるために、ご自身のコードおよびサードパーティのコードが安全であることを確認してください。このトピックでは、デモンストレーションのための基本的な例を提供しています。ニーズに応じて拡張および変更できます。
結果のデモンストレーション。

トラブルシューティング
問題:Pod が
Pending状態です。解決策:通常、ストレージクラスの欠落またはリソース不足が原因です。クラスターに
ack-difyの Persistent Volume Claim (PVC) 依存関係が欠けていないか確認してください。クラスターにデフォルトの Container Network File System (CNFS) と対応する NAS StorageClass を作成します。具体的な手順については、「CNFS を使用した NAS ファイルシステムの管理 (推奨)」をご参照ください。Pod の例外のトラブルシューティングについては、「Pod の例外のトラブルシューティング」をご参照ください。問題:DNS 解決に失敗しました。
解決策:特にカスタムの hostNetwork 設定を使用している場合、Pod がクラスター内の CoreDNS にアクセスできることを確認してください。
問題:AI アシスタントの応答が不正確です。
解決策:システムプロンプトを改良するか、ナレッジベースのセグメント (チャンキング) の品質を向上させてください。
コストとメンテナンス
課金:ACK 管理費および ECS、NAS、CLB、Elastic IP アドレス (EIP) などの基盤となるリソースに対して課金されます。モデルの使用量は、モデルプロバイダーによってトークンに基づいて課金されます。クラスター管理費とリソース料金については、「課金の概要」をご参照ください。
セキュリティ:Dify の管理者パスワードと API キーを定期的にローテーションしてください。Alibaba Cloud でのきめ細かなアクセス制御には RAM ロールを使用してください。
免責事項
Dify on ACK は、オープンソースの Dify プロジェクトを Alibaba Cloud ACK 環境に適応させ、迅速なデプロイを可能にする Helm デプロイソリューションです。ACK は、Dify アプリケーションのパフォーマンスや、プラグインやデータベースなどの他のエコシステムコンポーネントとの互換性を保証するものではありません。ACK は、Dify またはそのエコシステムコンポーネントの欠陥によって生じたいかなるビジネス上の損失に対しても、補償や賠償などの商用サービスを提供しません。Dify の安定性とセキュリティを確保するために、オープンソースコミュニティからの更新をフォローし、オープンソースソフトウェアの問題を積極的に修正することを推奨します。