このトピックでは、マルチテナントシナリオでArenaを使用する方法について説明します。 このトピックでは、5つのタスクが使用されます。
前提条件
次の操作が完了しました。
Container Service for Kubernetes (ACK) クラスターが作成されました。 詳細については、「ACK管理クラスターの作成」をご参照ください。
ACKクラスターがデプロイされている仮想プライベートクラウド (VPC) に、Linuxを実行するElastic Compute Service (ECS) インスタンスが作成されます。 詳細については、「カスタム起動タブでインスタンスを作成する」をご参照ください。
この例では、ECSインスタンスがクライアントとして機能します。 クライアントは、ジョブをACKクラスターに送信するアリーナワークステーションとして使用されます。
Arenaクライアントの最新バージョンがインストールされています。 詳細については、「Arenaクライアントの設定」をご参照ください。
背景情報
シナリオによっては、会社またはチーム内の複数の開発者がArenaを使用してジョブを送信したい場合があります。 ジョブ管理の効率を向上させるために、開発者を複数のユーザーグループに分割し、各ユーザーグループに異なる権限を付与できます。 これにより、リソースの割り当てと分離、およびユーザーグループごとのアクセス許可の管理が可能になります。
GPU、CPU、メモリリソースなどのビジネス要件に基づいて、ACKクラスターのリソースを各ユーザーグループに割り当てることができます。 各グループメンバーに異なる権限を付与し、各メンバーがArenaを実行するための個別の環境を提供することもできます。 ジョブの表示、ジョブの管理、特定のデータの読み取りと書き込みを行う権限をグループメンバーに付与できます。
図 1. マルチテナントシナリオでのArenaの設定

次の表に、ACKクラスターとクライアントのノードの詳細を示します。
ホスト名 | ロール | IPアドレス | GPUの数 | CPUコアの数 | メモリ |
client01 | クライアント | 10.0.0.97 (プライベート) 39.98.xxx.xxx (パブリック) | 0 | 2 | 8 GiB |
master01 | マスター | 10.0.0.91 (プライベート) | 0 | 4 | 8 GiB |
master02 | マスター | 10.0.0.92 (プライベート) | 0 | 4 | 8 GiB |
master03 | マスター | 10.0.0.93 (プライベート) | 0 | 4 | 8 GiB |
worker01 | ワーカー | 10.0.0.94 (プライベート) | 1 | 4 | 30 GiB |
worker02 | ワーカー | 10.0.0.95 (プライベート) | 1 | 4 | 30 GiB |
worker03 | ワーカー | 10.0.0.96 (プライベート) | 1 | 4 | 30 GiB |
特に明記しない限り、このトピックで説明する操作はすべて、クライアントの管理者アカウントを使用して実行されます。
タスク
この例では、次のタスクを完了する方法を示します。
タスク1: ACKクラスター用にdev1とdev2という名前の2つのユーザーグループを作成し、ユーザーBobとTomをユーザーグループdev1とdev2に別々に追加します。
タスク2: ボブとトムが自分のアカウントでのみクライアントにログオンできるようにします。 どちらも、アリーナを実行できる別の環境が必要です。
タスク3: ボブとトムに、送信するジョブのみを表示および管理する権限を付与します。
タスク4: ワーカーノードのGPU、CPU、およびメモリリソースを異なるユーザーグループに割り当てます。 Arenaジョブは、ワーカーノードのコンピューティングリソースのみを消費できます。
タスク5: ユーザーグループ内でのみ共有できるボリュームを作成し、すべてのユーザーグループで共有できるボリュームを作成します。
表 1. リソース割り当て
ユーザーグループ | ユーザー | GPU | CPU | メモリ | 共有ボリューム |
dev1 | Bob | 1 | 無制限 | 無制限 | dev1-publicおよびdepartment1-public-dev1 |
dev2 | Tom | 2 | 8 | 60 GiB | dev2-publicおよびdepartment1-public-dev2 |
department1-public-dev1ボリュームとdepartment1-public-dev2ボリュームは、Apsara File Storage NAS (NAS) ファイルシステムの同じディレクトリにマウントされます。 したがって、ユーザーグループdev1とdev2のユーザーは、ディレクトリに格納されているデータを共有できます。 dev1-publicおよびdev2-publicボリュームは、NASファイルシステムの異なるディレクトリにマウントされます。 dev1-publicに記憶されたデータは、ユーザグループdev1のボブのみにアクセス可能であり、dev2-publicに記憶されたデータは、ユーザグループdev2のトムのみにアクセス可能である。
手順1: ACKクラスターのユーザーとユーザーグループの作成と管理
セキュリティを確保するために、Arenaをインストールしたり、Arenaを実行したり、マスターノードでACKクラスターを管理したりしないことをお勧めします。 ACKクラスターがデプロイされているVPCにECSインスタンスを作成し、ECSインスタンスにArenaをインストールできます。 この例では、ECSインスタンスがクライアントとして機能します。 kubeconfigファイルを作成して、ECSインスタンスがACKクラスターにアクセスできるようにします。
クライアントでユーザーとユーザーグループを作成します。
kubectlを使用してACKクラスターに接続します。
kubectlを使用する前に、クライアントにkubectlをインストールし、管理者がACKクラスターを管理できるようにkubeconfigファイルを変更する必要があります。 詳細については、「kubectl を利用した Kubernetes クラスターへの接続」をご参照ください。
説明kubectlのバージョンは1.10以降である必要があります。
次のコマンドを実行して、クライアント上の対応するユーザーとユーザーグループのユーザーID (UID) とグループID (GID) をLinuxで作成します。
この例では、BobとTomのUIDとGIDを作成し、クライアントでユーザーグループdev1とdev2を作成します。 Linuxアカウントシステムを使用してタスク2を完了する: 各ユーザーは自分のユーザー名とパスワードでのみクライアントにログオンでき、自分の環境でのみArenaを実行できます。
# Linuxグループを作成する: dev1とdev2。 groupadd -g 10001 dev1 groupadd -g 10002 dev2 # Linuxユーザーの作成: ボブとトム。 adduser -u 20001 -s /bin/bash -G dev1 -m bob adduser -u 20002 -s /bin/bash -G dev2 -m tom # Bobがクライアントにログオンするためのパスワードを設定します。 passwdボブ # Tomがクライアントにログオンするためのパスワードを設定します。 passwdトム
ACKクラスターのサービスアカウントと名前空間を作成します。
ジョブを送信すると、ジョブはACKクラスターで実行されます。 クライアントの各ユーザーはACKクラスターのサービスアカウントに対応し、各ユーザーグループは名前空間に対応します。 したがって、サービスアカウントと名前空間を作成し、それらがクライアントの対応するユーザーとユーザーグループにマップされていることを確認する必要があります。 名前空間をユーザーグループにマップし、サービスアカウントをユーザーにマップする必要があります。
rootユーザーとしてクライアントにログオンします。 rootユーザーにACKクラスターを管理する権限があることを確認します。 詳細については、このトピックの「kubectlを使用してACKクラスターに接続する」をご参照ください。 以下のコマンドを実行します。
# ユーザーグループdev1の名前空間を作成します。 kubectl create namespace dev1 # ユーザーグループdev2の名前空間を作成します。 kubectl create namespace dev2 # Bobのサービスアカウントを作成します。 kubectl create serviceaccount bob -n dev1 # Tomのサービスアカウントを作成します。 kubectl create serviceaccount tom -n dev2期待される出力:
$ kubectlは名前空間dev1を作成します 名前空間 /dev1が作成されました $kubectl create namespace dev2 名前空間 /dev2作成 $kubectl create serviceaccount bob -n dev1 serviceaccount/bobが作成されました $kubectl create serviceaccount tom -n dev2 serviceaccount/tom作成
ステップ2: ユーザーのアリーナを設定する
Arenaをインストールします。
クライアントにArenaをインストールします。 rootユーザーとしてクライアントにログインし、コミュニティでリリースされているArenaの最新のインストールパッケージをダウンロードします。 次に、パッケージを解凍し、install.shスクリプトを実行します。 詳細については、「Arenaクライアントの設定」をご参照ください。
説明Arenaは、各Linuxクライアントに1回だけインストールする必要があります。 各ユーザーが別々の環境でArenaを使用できるようにするには、各ユーザーにkubeconfigファイルを作成する必要があります。
ユーザーごとにkubeconfigファイルを作成します。
各ユーザーが別々の環境でArenaを使用できるようにするには、各ユーザー (サービスアカウント) にkubeconfigファイルを作成する必要があります。 ACKクラスターに対してユーザーに異なる権限を付与できます。 これにより、データのセキュリティが確保されます。
rootユーザーとしてクライアントにログオンします。 generate-kubeconfig.shという名前のスクリプトを作成し、次の内容をスクリプトに貼り付けます。
#!/usr/bin/env bash セット-e NAMESPACE= SERVICE_ACCOUNT= 時間= 出力= help() { echo "Usage: $0 -n <namespace> -s <service-account> -d <duration> -o <output-file>" エコー "" echo "オプション:" echo "-n, -- namespace <namespace> サービスアカウントの名前空間。 echo "-s, -- service-account <name> サービスアカウントの名前。" echo "-d, -- duration <duration> トークンのDuration例えば30d." echo "-o, -- output <file> 出力ファイル名。 設定しないと、一時ファイルが作成されます。} parse() { [ $# -gt 0 ]; do ケース $1で -n | -- namespace) NAMESPACE="$2" シフト2 ;; -s | -- service-account) SERVICE_ACCOUNT="$2" シフト2 ;; -d | -- duration) DURATION="$2" シフト2 ;; -o | -- output) 出力="$2" シフト2 ;; *) help exit 0 ;; esac done if [ -z "${NAMESPACE}" ] | | [ -z "${SERVICE_ACCOUNT}" ] | | | [ -z "${DURATION}" ]; then help exit 0 fi if [ -z "${OUTPUT}" ]; then OUTPUT=$(mktemp -d)/config elif [ -f "${出力}" ]; その後 echo "出力ファイル \"${Output}\"既に存在します。 exit 1 fi } # 生成kubeconfig generate_kubeconfig() { CONTEXT=$(kubectl config current-context) CLUSTER=$(kubectl config view -o jsonpath="{.contexts[?(@.name ==\"${CONTEXT}\")].context.cluster}") SERVER=$(kubectl config view -o jsonpath="{.clusters[?(@.name ==\"${CLUSTER}\")].cluster.server}") TOKEN=$(kubectl create token "${SERVICE_ACCOUNT}" -- namespace "${NAMESPACE}" -- duration="${DURATION}") CERT=$(mktemp) mkdir -p "$(dirname"${OUTPUT}")" kubectl config view -- raw=true -o jsonpath="{.clusters[?(@.name=\"${CLUSTER}\")].cluster.certificate-authority-data}" | base64 -d >"${CERT}" kubectl config set-cluster "${CLUSTER}" -- kubeconfig="${OUTPUT}" -- server="${SERVER}" -- embed-certs=true -- certificate-authority="${CERT}" >/dev/null kubectl config set-credentials "${SERVICE_ACCOUNT}" -- kubeconfig="${OUTPUT}" -- token="${TOKEN}" >/dev/null kubectl config set-context "${CLUSTER}-${NAMESPACE}-${SERVICE_ACCOUNT}-context" -- kubeconfig="${OUTPUT}" -- cluster="${CLUSTER}" -- user="${SERVICE_ACCOUNT}"-名前空間="${namespace}" >/null /null kubectl config use-context "${CLUSTER}-${NAMESPACE}-${SERVICE_ACCOUNT}-context" -- kubeconfig="${OUTPUT}" >/dev/null rm "${CERT}" echo "Saved kubeconfig to \"${OUTPUT}\"。} main() { "$@" を解析する generate_kubeconfig } メイン "$@"次のコマンドを実行して、KubeConfigという名前のファイルを作成し、ホームディレクトリに保存します。 以下のコマンドは、有効期限を720時間に設定しますが、必要に応じてこの有効期限をカスタマイズできます。
bash generate-kubeconfig.sh -n dev1 -s bob -d 720h -o /home/bob/.kube/config bash generate-kubeconfig.sh -n dev2 -s tom -d 720h -o /home/tom/.kube/config期待される出力:
$ bash generate-kubeconfig.sh -n dev1 -s bob -d 720h -o /home/bob/.kube/config kubeconfigを "/home/bob/.kube/config" に保存しました。 $bash generate-kubeconfig.sh -n dev2 -s tom -d 720h -o /home/tom/.kube/config kubeconfigを "/home/tom/.kube/config" に保存しました。
ステップ3: ユーザーにアリーナに対するさまざまな権限を付与する
ACKクラスターの名前空間に必要なロールを作成します。
ACKクラスターの名前空間に異なる権限を持つロールを作成できます。 名前空間の各ロールには、一連の権限ルールが含まれます。 ロールの作成方法の詳細については、「RBAC権限の使用」をご参照ください。
ロール定義ファイルを作成します。
ユーザーグループdev1とdev2でロールを作成し、BobとTomに別々にロールを割り当てます。 この例では、BobとTomに最低限の権限を付与します。 これにより、送信したジョブのみを表示および管理できます。
次のサンプルコードを使用して、ユーザーグループdev1のロール定義ファイルdev1_roles.yamlを作成します。
種類: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: arena-topnode ルール: -apiGroups: - "" resources: -ポッド -サービス -デプロイメント -ノード -ノード /* -サービス /プロキシ -persistentvolumes verbs: - get -リスト --- apiVersion: rbac.authorization.k8s.io/v1 kind: ロール メタデータ: 名前: アリーナ 名前空間: dev1 ルール: - apiGroups: - "" resources: - configmaps verbs: - '*' - apiGroups: - "" resources: -サービス /プロキシ -persistentvolumeclaims -イベント verbs: - get - list - apiGroups: - "" resources: -ポッド -ポッド /ログ -サービス verbs: - '*' - apiGroups: - "" -アプリ -拡張 resources: -デプロイメント -replicasets verbs: - '*' - apiGroups: -kubeflow.org resources: - '*' verbs: - '*' - apiGroups: -バッチ resources: -ジョブ verbs: - '*'次のサンプルコードを使用して、ユーザーグループdev2のロール定義ファイルdev2_roles.yamlを作成します。
種類: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: arena-topnode ルール: -apiGroups: - "" resources: -ポッド -サービス -デプロイメント -ノード -ノード /* -サービス /プロキシ -persistentvolumes verbs: - get -リスト --- apiVersion: rbac.authorization.k8s.io/v1 kind: ロール メタデータ: 名前: アリーナ 名前空間: dev2 ルール: -apiGroups: - "" resources: - configmaps verbs: -'*' -apiGroups: - "" resources: -サービス /プロキシ -persistentvolumeclaims -イベント verbs: - get -リスト -apiGroups: - "" resources: -ポッド -ポッド /ログ -サービス verbs: -'*' -apiGroups: - "" -アプリ -拡張 resources: -デプロイメント -replicasets verbs: -'*' -apiGroups: -kubeflow.org resources: - '*' verbs: -'*' -apiGroups: -バッチ resources: -ジョブ verbs: - '*'dev1_roles.yamlおよびdev2_roles.yamlを作成した後、次のコマンドを実行してファイルをACKクラスターにデプロイします。
kubectl apply -f dev1_roles.yaml kubectl apply -f dev2_roles.yaml期待される出力:
$ kubectl apply -f dev1_roles.yaml clusterrole.rbac.authorization.k8s.io/arena-topnode created role.rbac.authorization.k8s.io/arena作成 $kubectl apply -f dev2_roles.yaml clusterrole.rbac.authorization.k8s.io/arena-topnode unchanged role.rbac.authorization.k8s.io/arena作成次のコマンドを実行して、名前空間のロールを照会します。
kubectl get role -n dev1 kubectl get role -n dev2期待される出力:
$ kubectl get role -n dev1 で作成された名前 アリーナ2024-09-14T08:25:34Z $kubectl get role -n dev2 で作成された名前 アリーナ2024-09-14T08:25:39Z
ACKクラスターに対する権限をユーザーに付与します。
ロールを作成したら、ロールをユーザーに割り当てて権限を付与する必要があります。 このタスクを完了するには、名前空間のロールをサービスアカウントにバインドします。
各ユーザーに異なる名前空間で1つ以上のロールを割り当てることができます。 これにより、ユーザーは異なる名前空間に属するリソースにアクセスできます。 ロールベースのアクセス制御 (RBAC) を使用すると、ユーザーが名前空間で持つ権限を管理できます。 ビジネス要件に基づいてロールバインディングを作成できます。
RoleBindingとClusterRoleBindingの2つのKubernetesオブジェクトを使用して、名前空間またはACKクラスターに対する権限をユーザーに付与するロールバインディングを作成できます。 RoleBindingとClusterRoleBindingを使用してロールバインディングを説明する方法の詳細については、「RBAC認証の使用」をご参照ください。
タスク3を完了するには、ステップ3で作成したロールをBobとTomに割り当てます。 ユーザーに権限を付与するには、次の操作を実行します。
rootユーザーとしてクライアントにログインし、次のサンプルコードを使用して、ユーザーBobのbob_rolebindings.yamlという名前の認証ファイルを作成します。
種類: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: bob-arena-topnode 名前空間: dev1 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole 名前: arena-topnode 主題: -kind: ServiceAccount 名前: bob 名前空間: dev1 --- 種類: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: bob-arena 名前空間: dev1 roleRef: apiGroup: rbac.authorization.k8s.io kind: ロール 名前: アリーナ 主題: -kind: ServiceAccount 名前: bob 名前空間: dev1次のサンプルコードを使用して、ユーザーTomのtom_rolebindings.yamlという名前の認証ファイルを作成します。
種類: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: tom-arena-topnode 名前空間: dev2 roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole 名前: arena-topnode 主題: -kind: ServiceAccount 名前: tom 名前空間: dev2 --- 種類: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 メタデータ: 名前: tom-arena 名前空間: dev2 roleRef: apiGroup: rbac.authorization.k8s.io kind: ロール 名前: アリーナ 主題: -kind: ServiceAccount 名前: tom 名前空間: dev2次のコマンドを実行して、BobとTomにロールを割り当てます。
kubectlが適用されます-f bob_rolebindings.yaml kubectl apply -f tom_rolebindings.yaml期待される出力:
$ kubectlが適用されます-f bob_rolebindings.yaml clusterrolebinding.rbac.authorization.k8s.io/bob-arena-topnode created rolebinding.rbac.authorization.k8s.io/bob-arena作成 $kubectl apply -f tom_rolebindings.yaml clusterrolebinding.rbac.authorization.k8s.io/tom-arena-topnode created rolebinding.rbac.authorization.k8s.io/tom-arenaが作成されました次のコマンドを実行して、ユーザーグループdev1およびdev2のロールバインディングを照会します。
kubectlはrolebinding -n dev1を取得します kubectl get rolebinding -n dev2期待される出力:
$ kubectlがrolebinding -n dev1を取得 名前の役割年齢 ボブ-アリーナ役割 /アリーナ34s $kubectl get rolebinding -n dev2 名前の役割年齢 トムアリーナ役割 /アリーナ33s上記の操作を完了すると、最初の3つのタスクが完了します。
手順4: ユーザーグループのリソースクォータの設定
ACKコンソールでACKクラスターのすべてのリソースを管理できます。 リソース使用のセキュリティと効率を確保するために、ユーザーグループのリソースクォータを設定できます。 権限を持つ名前空間にジョブを送信できます。 ジョブを送信すると、ACKは名前空間の使用可能なリソースを自動的にチェックします。 ジョブによって要求されたリソースの量がクォータを超えた場合、ACKはジョブを拒否します。
Kubernetesでは、ResourceQuotaオブジェクトは、名前空間ごとの総リソース消費を制限する制約を記述します。 各名前空間は、Arenaがインストールされているクライアントのユーザーグループに対応します。 CPU、メモリ、拡張リソースなど、さまざまなリソースのクォータを設定できます。 拡張リソースにはNVIDIA GPUが含まれます。 ResourceQuotaオブジェクトは、名前空間内のコンテナおよび他のKubernetesオブジェクトのリソース使用も制限します。 詳しくは、『Resource Quotas』をご参照ください。
タスク4を完了するには、各ユーザーグループのGPU、CPU、およびメモリリソースのクォータを設定します。 詳細については、このトピックの「リソース割り当て」をご参照ください。 この例では、ユーザグループdev1に1つのGPUが割り当てられる。 CPUとメモリのリソースは無制限です。 ユーザーグループdev1のBobは、クラスターのすべてのCPUおよびメモリリソースを使用できます。 次に、以下のリソースがdev2に割り当てられます: 2つのGPU、8つのCPUコア、および60 GiBのメモリ。 ユーザーグループのリソースクォータを設定するには、次の操作を実行します。
rootユーザーとしてクライアントにログインし、次のサンプルコードを使用して、ユーザーグループdev1のdev1_quota.yamlという名前のリソースクォータファイルを作成します。
apiVersion: v1 kind: ResourceQuota メタデータ: 名前: dev1-compute-resources 名前空間: dev1 spec: hard: requests.cpu: "10" requests.memory: 10Gi limits.cpu: "15" limits.memory: 20Gi requests.nvidia.com/gpu: 2次のサンプルコードを使用して、ユーザーグループdev2のdev2_quota.yamlという名前のリソースクォータファイルを作成します。
apiVersion: v1 kind: ResourceQuota メタデータ: 名前: dev2-compute-resources 名前空間: dev2 spec: hard: requests.nvidia.com/gpu: 2次のコマンドを実行して、ACKクラスターにファイルをデプロイします。
kubectl apply -f dev1_quota.yaml kubectl apply -f dev2_quota.yamlリソースクォータを設定した後、次のコマンドを実行して、設定が有効かどうかを確認します。 リソースクォータとリソース使用量を照会することもできます。
# ユーザーグループdev1のリソースクォータを照会します。 kubectl get resourcequotas -n dev1 # ユーザーグループdev2のリソースクォータを照会します。 kubectl get resourcequotas -n dev2 # ユーザーグループdev1のリソース使用量を照会します。 kubectl describe resourcequotas dev1-compute-resources -n dev1 # ユーザーグループdev2のリソース使用量を照会します。 kubectl describe resourcequotas dev2-compute-resources -n dev2期待される出力:
$ kubectl get resourcequotas -n dev1 名前の年齢リクエスト制限 dev1-compute-resources 9s requests.cpu: 0/10、requests.memory: 0/10Gi、requests.nvidia.com/gpu: 0/2 limits.cpu: 0/15、limits.memory: 0/20Gi $kubectl get resourcequotas -n dev2 名前の年齢リクエスト制限 dev2-compute-resources 10s requests.nvidia.com/gpu: 0/2 $kubectlはresourcequotas dev1-compute-resources -n dev1を説明します 名前: dev1-compute-resources 名前空間: dev1 ハード使用リソース ------- ----- ------ limits.cpu 0 15 limits.memory 0 20Gi requests.cpu 0 10 requests.memory 0 10Gi requests.nvidia.com/gpu 0 2 $kubectlはresourcequotas dev2-compute-resources -n dev2を説明します 名前: dev2-compute-resources 名前空間: dev2 ハード使用リソース ------- ----- ------ requests.nvidia.com/gpu 0 2上記の操作を完了すると、コンピューティングリソースがユーザーグループに割り当てられ、タスク4が完了します。
ステップ5: NASボリュームを作成してマルチレベルアクセス制御を実施する
マルチレベルアクセス制御の要件を満たすには、さまざまなユーザーとユーザーグループがアクセスできるボリュームを作成する必要があります。 これにより、データ共有のセキュリティが確保されます。
タスク5を完了するには、2種類の共有ボリュームを作成する必要があります。 最初のタイプのボリュームは、両方のユーザーグループのユーザーがアクセスできるデータを格納するために使用されます。 もう1つのタイプのボリュームは、特定のユーザーグループのユーザーのみがアクセスできるデータを格納するために使用されます。 共有ボリュームの詳細については、このトピックの「リソース割り当て」をご参照ください。 この例では、dev1-public、dev2-public、department1-public-dev1、department1-public-dev2の4つのボリュームが作成されます。 department1-public-dev1とdepartment1-public-dev2は、NASファイルシステムの同じディレクトリにマウントされます。 ボリュームデータは、両方のユーザグループdev1およびdev2のユーザによってアクセス可能である。 dev1-publicとdev2-publicは、NASファイルシステムの異なるディレクトリにマウントされます。 dev1-publicに格納されたデータは、ユーザグループdev1のBobのみがアクセスでき、dev2-publicに格納されたデータは、ユーザグループdev2のTomのみがアクセスできる。 データ共有用のNASボリュームを作成するには、次の操作を実行します。
NASファイルシステムを作成します。
NASコンソールにログインし、NASファイルシステムを作成し、マウントターゲットを追加します。 詳細については、「Configure a shared NAS volume」をご参照ください。
ACKクラスターの永続ボリューム (PV) と永続ボリュームクレーム (PVC) を作成します。
PVを作成します。
4つのPVを作成します。 PVの作成方法の詳細については、「静的にプロビジョニングされたNASボリュームのマウント」をご参照ください。 department1-public-dev1ボリュームは、ユーザーグループdev1内のユーザーとdepartment1のデータを共有するために使用され、department1-public-dev2ボリュームは、ユーザーグループdev2内のユーザーとdepartment1のデータを共有するために使用される。 dev1-publicボリュームはユーザーグループdev1のユーザーのみとデータを共有するために使用され、dev2-publicボリュームはユーザーグループdev2のユーザーのみとデータを共有するために使用されます。 次の図は、PVの設定を示しています。
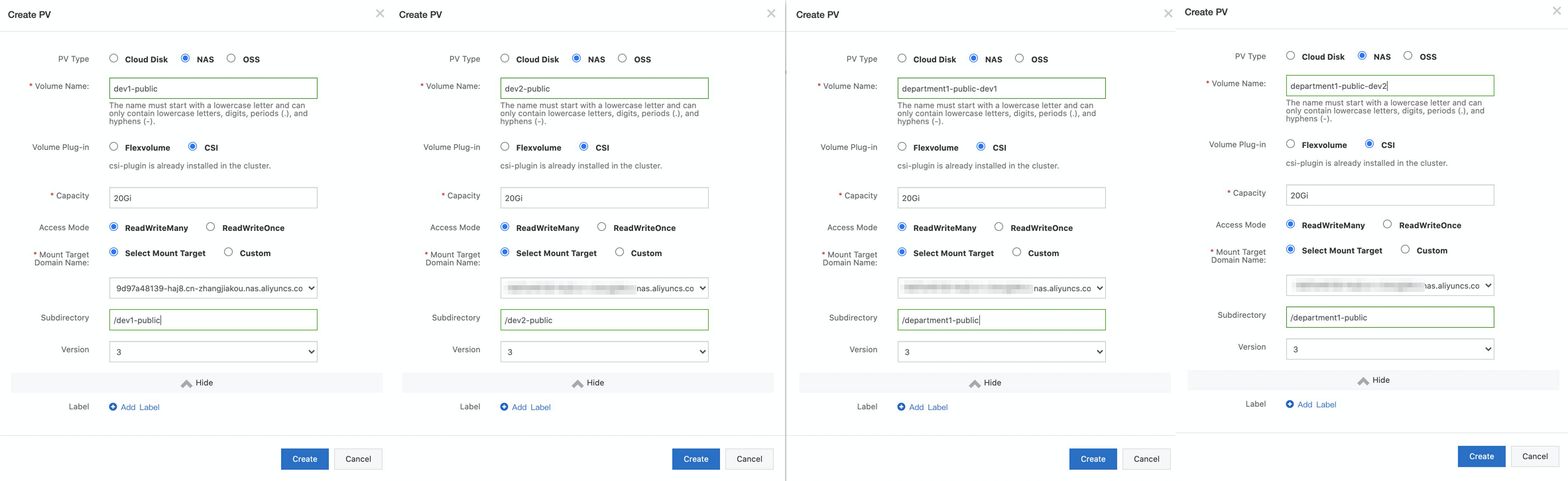 説明
説明前の手順で追加したマウントターゲットを選択します。
PVCを作成します。
新しく作成したPVごとにPVCを作成します。 PVCの作成方法の詳細については、「静的にプロビジョニングされたNASボリュームのマウント」をご参照ください。
PVCを作成すると、ユーザーグループdev1にdepartment1-public-dev1とdev1-publicが存在し、ユーザーグループdev2にdepartment1-public-dev2とdev2-publicが存在することがわかります。
ボリュームの設定を確認します。
rootユーザーとしてクライアントにログインし、次のコマンドを実行して、ユーザーグループdev1およびdev2で使用されているボリュームを照会します。
# ユーザーグループdev1が使用するボリュームを照会します。 アリーナデータ一覧-n dev1 # ユーザーグループdev2が使用するボリュームを照会します。 アリーナデータ一覧-n dev2期待される出力:
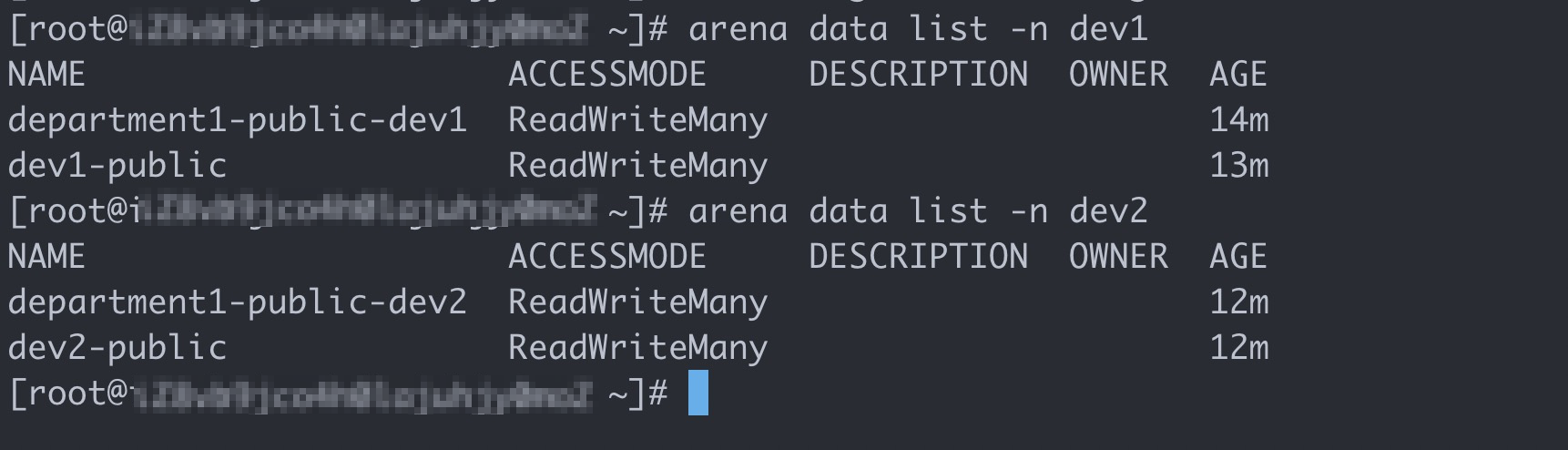
上記の操作を完了すると、5つのタスクがすべて完了します。 次の例では、BobとTomのアカウントを使用してArenaがインストールされているクライアントにログオンする方法を説明します。
ステップ6: 異なるユーザーアカウントでArenaを実行する
ボブのアカウントを使う
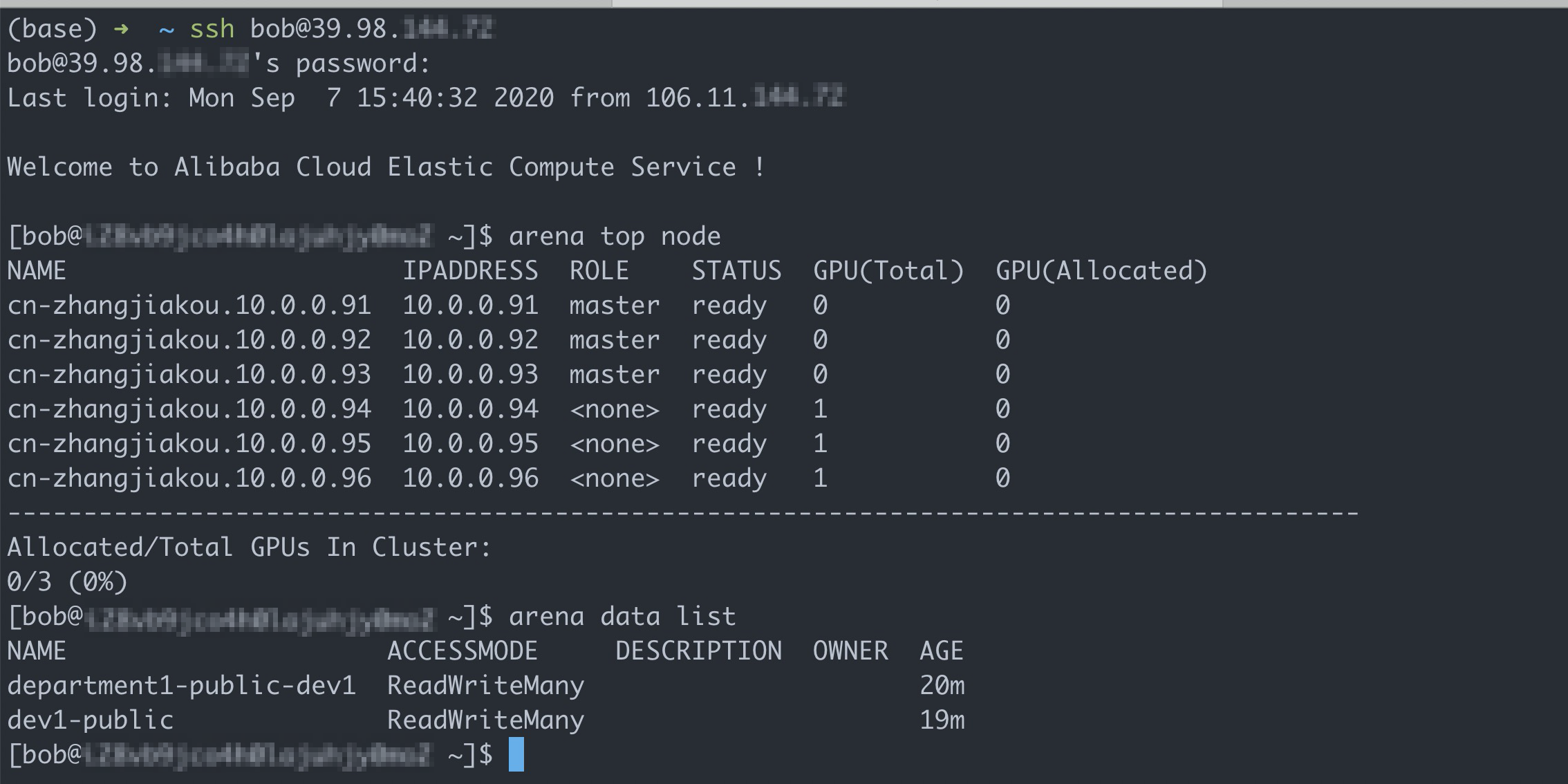
次のコマンドを実行してクライアントにログインし、使用可能な共有ボリュームを照会します。
# Bobのアカウントでクライアントにログオンします。 ssh bob@39.98.xxx.xx # arena data listコマンドを実行して、Bobが利用できる共有ボリュームを照会します。 アリーナデータ一覧期待される出力:
次のコマンドを実行して、1つのGPUを必要とするトレーニングジョブを送信します。
アリーナはtf \を提出します -- name=tf-git-bob-01 \ -- gpus=1 \ -- image=tensorflow/tensorflow:1.5.0-devel-gpu \ -- sync-mode=git \ -- sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py -- max_steps 10000 -- data_dir=code/tensorflow-sample-code/data"次のコマンドを実行して、Bobによって送信されたすべてのジョブを一覧表示します。
アリーナ一覧期待される出力:

次のコマンドを実行して、1つのGPUを必要とする別のトレーニングジョブを送信します。
アリーナはtf \を提出します -- name=tf-git-bob-02 \ -- gpus=1 \ -- image=tensorflow/tensorflow:1.5.0-devel-gpu \ -- sync-mode=git \ -- sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py -- max_steps 10000 -- data_dir=code/tensorflow-sample-code/data"この例では、1つのGPUのみがユーザグループdev1に割り当てられる。 したがって、ACKは第2のジョブを拒否することが期待される。

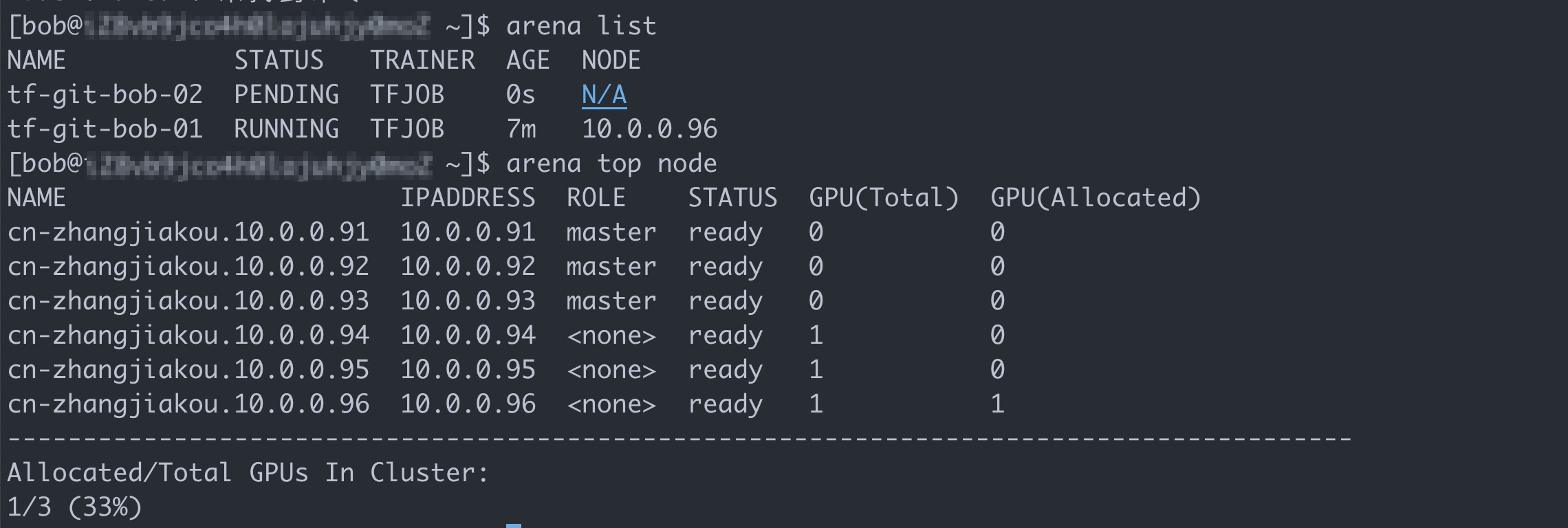
上の図は、ACKクラスターにまだ十分なリソースがあることを示しています。 しかしながら、ボブが属するユーザグループに割り当てられたGPUは、第1のジョブによって既に占有されている。 これにより、第2のジョブが中断される。
トムのアカウントを使う
次のコマンドを実行してクライアントにログインし、使用可能な共有ボリュームを照会します。
# Tomのアカウントでクライアントにログオンします。 ssh tom@39.98.xx.xx # arena data listコマンドを実行して、Tomが利用できる共有ボリュームを照会します。 アリーナデータ一覧期待される出力:
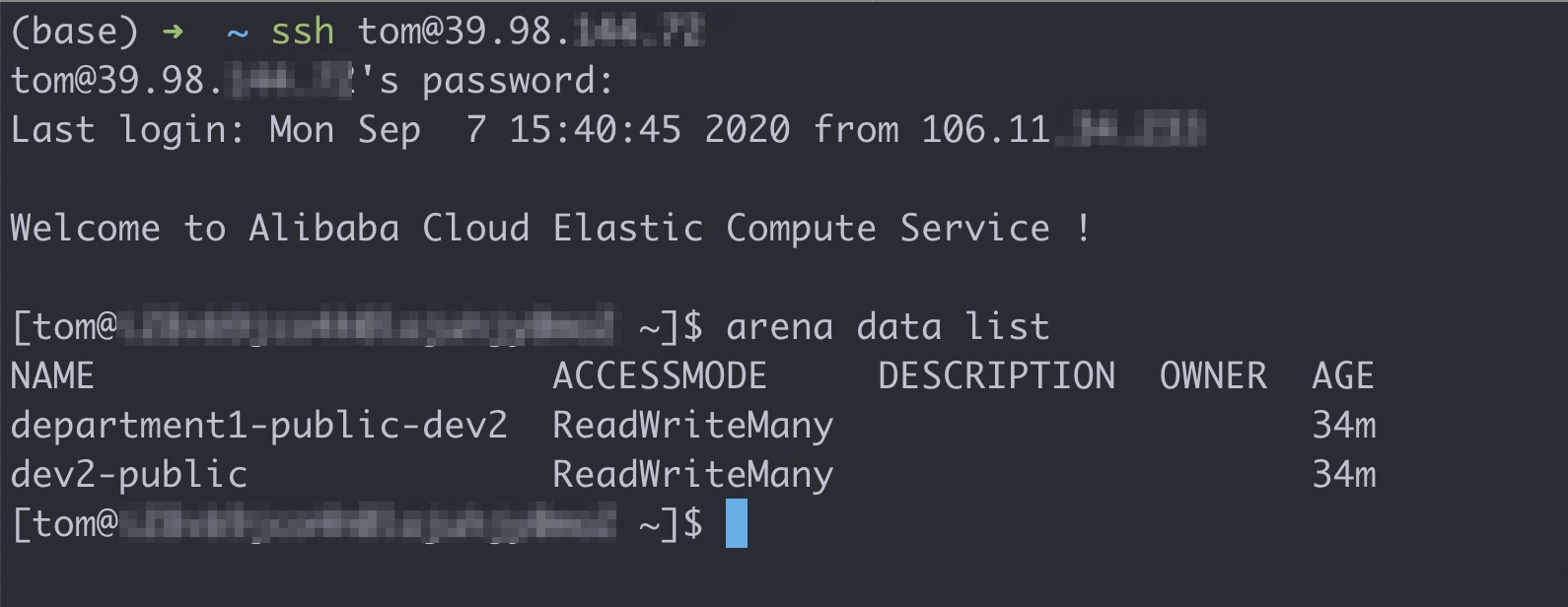
次のコマンドを実行して、Tomが送信したすべてのジョブを一覧表示します。
アリーナ一覧トムはボブによって提出されたジョブを見ることができない。

次のコマンドを実行して、1つのGPUを必要とするトレーニングジョブを送信します。
アリーナはtf \を提出します -- name=tf-git-tom-01 \ -- gpus=1 \ -- chief-cpu=2 \ -- チーフメモリ=10Gi \ -- image=tensorflow/tensorflow:1.5.0-devel-gpu \ -- sync-mode=git \ -- sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py -- max_steps 10000 -- data_dir=code/tensorflow-sample-code/data"説明この例では、GPU、CPU、およびメモリリソースが、ユーザグループdev2に割り当てられる。 したがって、Tomは、ジョブによって要求されるリソースを指定する必要があります。
次のコマンドを実行して、1つのGPUを必要とする別のジョブを送信します。
アリーナはtf \を提出します -- name=tf-git-tom-02 \ -- gpus=1 \ -- chief-cpu=2 \ -- チーフメモリ=10Gi \ -- image=tensorflow/tensorflow:1.5.0-devel-gpu \ -- sync-mode=git \ -- sync-source=https://code.aliyun.com/xiaozhou/tensorflow-sample-code.git \ "python code/tensorflow-sample-code/tfjob/docker/mnist/main.py -- max_steps 10000 -- data_dir=code/tensorflow-sample-code/data"次のコマンドを実行して、Tomが送信したすべてのジョブを一覧表示します。
アリーナ一覧期待される出力:
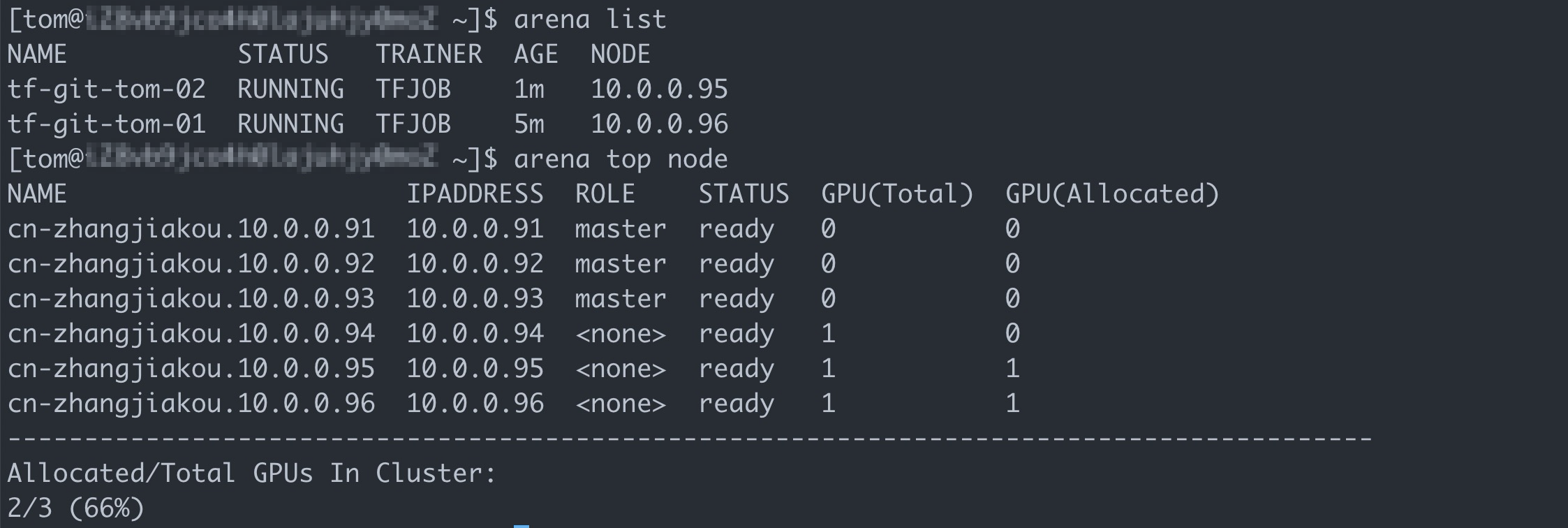
結果を表示するView the result
上記の結果は、クライアントにログオンし、BobとTomのアカウントを使用して別の環境でArenaを実行できることを示しています。 また、各ユーザーグループに割り当てられたコンピューティングおよびストレージリソースを照会して使用したり、BobとTomが送信したジョブを管理したりすることもできます。