Container Service for Kubernetes (ACK) は、スケジューリングフレームワークに基づくトポロジ対応GPUスケジューリングをサポートしています。 この機能は、GPUアクセラレーションノードからGPUの組み合わせを選択して、トレーニングジョブに最適なGPUアクセラレーションを実現します。 このトピックでは、トポロジ対応のGPUスケジューリングを使用して、TensorFlow分散ジョブに最適なGPUアクセラレーションを実現する方法について説明します。
前提条件
Container Service for Kubernetes (ACK) Proクラスターが作成され、クラスターのインスタンスタイプがElastic GPU Serviceに設定されます。 詳細については、「ACK管理クラスターの作成」をご参照ください。
Arenaがインストールされています。
システムコンポーネントのバージョンは、次の要件を満たしています。
コンポーネント
バージョン
Kubernetes
1.18.8以降
Nvidia
418.87.01以降
NVIDIA Collective Communications Library (NCCL)
2.7 +
オペレーティングシステム
CentOS 7.6
CentOS 7.7
Ubuntu 16.04
Ubuntu 18.04
Alibaba Cloud Linux 2
Alibaba Cloud Linux 3
GPU
V100
使用上の注意
トポロジ認識GPUスケジューリングは、分散フレームワークを使用してトレーニングされたMessage Passing Interface (MPI) ジョブにのみ適用できます。
ポッドによって要求されるリソースは、ジョブを送信して実行するためにポッドを作成する前に、特定の要件を満たす必要があります。 それ以外の場合、リクエストはリソースに対して保留のままです。
手順
ノードの設定
次のコマンドを実行してノードラベルを設定し、ノードのトポロジ認識GPUスケジューリングを明示的に有効にします。
kubectl label node <Your Node Name> ack.node.gpu.schedule=topologyノードでトポロジ対応のGPUスケジューリングを有効にすると、通常のGPUスケジューリングを有効にすることはできません。 次のコマンドを実行して、ラベルを変更し、通常のGPUスケジューリングを有効にします。
kubectl label node <Your Node Name> ack.node.gpu.schedule=default --overwriteジョブの送信
MPIジョブを提出し、-- gputopologyをtrueに設定します。
arena submit --gputopology=true --gang ***例1: VGG16のトレーニング
この例で使用されるクラスタは、2つのノードからなる。 各ノードは8つのV100 GPUを提供する。
トポロジ認識GPUスケジューリングを使用してVGG16をトレーニングする
次のコマンドを実行して、ジョブをクラスターに送信します。
arena submit mpi \ --name=tensorflow-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=vgg16 --batch_size=64 --variable_update=horovod"次のコマンドを実行して、ジョブのステータスを照会します。
arena get tensorflow-topo-4-vgg16 --type mpijob期待される出力:
Name: tensorflow-topo-4-vgg16 Status: RUNNINGNamespace: default Priority: N/A Trainer: MPIJOB Duration: 2m Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-topo-4-vgg16-launcher-lmhjl Running 2m true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-vgg16-worker-0 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-1 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-2 Running 2m false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-vgg16-worker-3 Running 2m false 1 cn-shanghai.192.168.16.173次のコマンドを実行して、ジョブログを印刷します。
arena logs -f tensorflow-topo-4-vgg16期待される出力:
total images/sec: 991.92
通常のGPUスケジューリングを使用してVGG16をトレーニングする
次のコマンドを実行して、ジョブをクラスターに送信します。
アリーナ送信mpi \ -- name=tensorflow-4-vgg16 \ -- gpus=1 \ -- workers=4 \ -- imag e=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun -- allow-run-as-root-npy" 4 " -bind-to none -map-by slot -x NCCL_benchseg16 DEBUG=INFO -x NCCL_SOCKET_if_IFNAME=eth0 -x LD_LIBRARY_PATH-m-- mca pta_neb_eptemarks /mot_ethnモデル1-mca-mot_nad_m_n// mobdname 64 -- variable_update=horovod"次のコマンドを実行して、ジョブのステータスを照会します。
アリーナ取得tensorflow-4-vgg16-タイプmpijob期待される出力:
名: tensorflow-4-vgg16 ステータス: RUNNING 名前空間: デフォルト 優先順位: N/A トレーナー: MPIJOB 期間: 9s インスタンス: 名前ステータス年齢IS_CHIEF GPU (要求された) ノード ---- ------ --- -------- -------------- ---- tensorflow-4-vgg16-launcher-xc28kランニング9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-0実行9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-1実行9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-vgg16-worker-2実行9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-vgg16-worker-3実行9s false 1 cn-shanghai.192.168.16.173次のコマンドを実行して、ジョブログを印刷します。
アリーナログ-f tensorflow-4-vgg16期待される出力:
合計画像 /秒: 200.47
例2: ResNet50のトレーニング
トポロジ対応GPUスケジューリングを使用したResNet50のトレーニング
次のコマンドを実行して、ジョブをクラスターに送信します。
arena submit mpi \ --name=tensorflow-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"次のコマンドを実行して、ジョブのステータスを照会します。
アリーナ取得tensorflow-topo-4-resnet50-タイプmpijob期待される出力:
名: tensorflow-topo-4-resnet50 ステータス: RUNNING 名前空間: デフォルト 優先順位: N/A トレーナー: MPIJOB 期間: 8s インスタンス: 名前ステータス年齢IS_CHIEF GPU (要求された) ノード ---- ------ --- -------- -------------- ---- tensorflow-topo-4-resnet50-launcher-7ln8jランニング8s true 0 cn-shanghai.192.168.16.172 tensorflow-topo-4-resnet50-worker-0ランニング8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-1ランニング8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-2ランニング8s false 1 cn-shanghai.192.168.16.173 tensorflow-topo-4-resnet50-worker-3実行8s false 1 cn-shanghai.192.168.16.173次のコマンドを実行して、ジョブログを印刷します。
アリーナログ-f tensorflow-topo-4-resnet50期待される出力:
合計画像 /秒: 1471.55
通常のGPUスケジューリングを使用してResNet50をトレーニングする
次のコマンドを実行して、ジョブをクラスターに送信します。
arena submit mpi \ --name=tensorflow-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/tensorflow-benchmark:tf2.3.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /tensorflow/benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=64 --variable_update=horovod"次のコマンドを実行して、ジョブのステータスを照会します。
arena get tensorflow-4-resnet50 --type mpijob期待される出力:
Name: tensorflow-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 9s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- tensorflow-4-resnet50-launcher-q24hv Running 9s true 0 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-0 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-1 Running 9s false 1 cn-shanghai.192.168.16.173 tensorflow-4-resnet50-worker-2 Running 9s false 1 cn-shanghai.192.168.16.172 tensorflow-4-resnet50-worker-3 Running 9s false 1 cn-shanghai.192.168.16.173次のコマンドを実行して、ジョブログを印刷します。
arena logs -f tensorflow-4-resnet50期待される出力:
total images/sec: 745.38
性能比較
次の図は、上記の例に基づくトポロジ対応のGPUスケジューリングと通常のGPUスケジューリングのパフォーマンスの違いを示しています。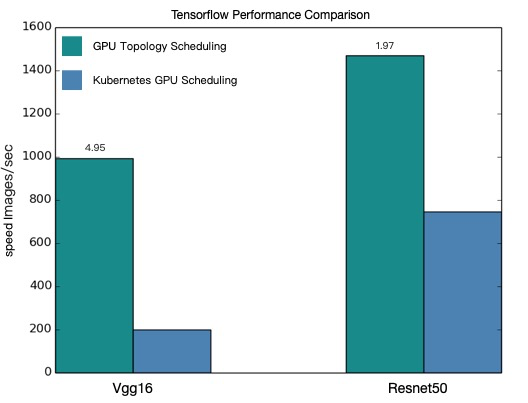
この図は、トポロジ対応のGPUスケジューリングを有効にすると、TensorFlow分散ジョブが高速化されることを示しています。
このトピックのパフォーマンス値は理論値です。 トポロジ対応のGPUスケジューリングのパフォーマンスは、モデルとクラスター環境によって異なります。 実際のパフォーマンス統計が優先されます。 上記の手順を繰り返して、モデルを評価できます。