CoreDNS は、Container Service for Kubernetes(ACK)クラスタでドメインネームシステム(DNS)ベースのサービスディスカバリを実装するために使用されるデフォルトのプラグインです。このトピックでは、CoreDNS ダッシュボードの表示方法と、ダッシュボードのメトリックについて説明します。また、異常なメトリック値に基づいてエラーをトラブルシューティングする方法についても説明します。
前提条件
ack-arms-prometheus コンポーネントがインストールされている。 詳細については、「コンポーネントの管理」をご参照ください。
CoreDNS ダッシュボードの表示
ACK コンソール にログインします。左側のナビゲーションウィンドウで、[クラスタ] をクリックします。
[クラスタ] ページで、目的のクラスタを見つけて名前をクリックします。左側のペインで、 を選択します。
[Prometheus モニタリング] ページで、[ネットワークモニタリング] タブをクリックします。[CoreDNS] タブで、CoreDNS ダッシュボードを表示できます。
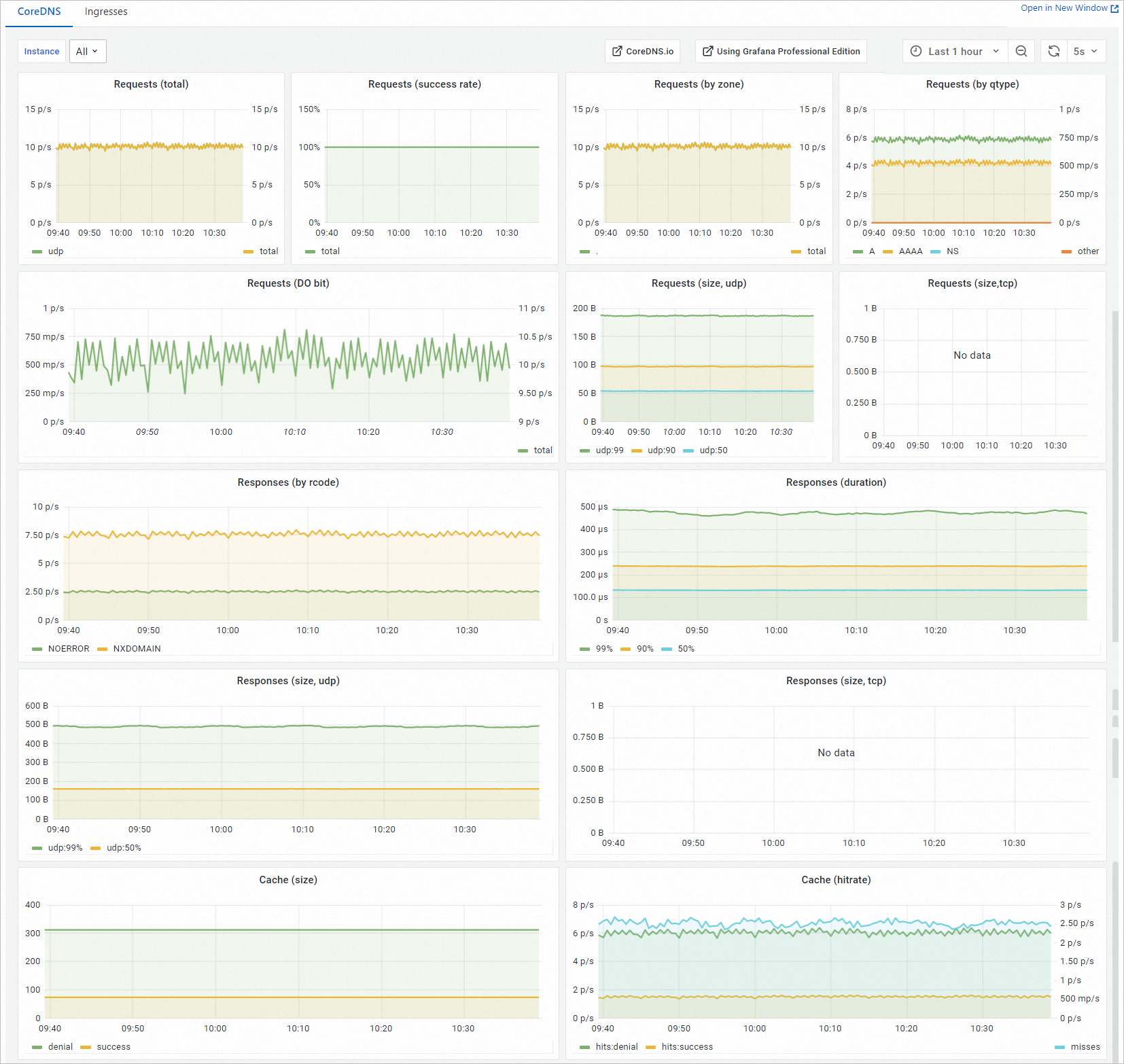
ダッシュボードの説明
CoreDNS ダッシュボードは、メトリックと Prometheus Query Language(PromQL)に基づいて生成され、リクエスト、レスポンス、およびデータキャッシングに関する情報を表示します。次の表に、ダッシュボードのメトリックを示します。
メトリック | 単位 | 説明 |
リクエスト(合計) | リクエスト/秒 | CoreDNS が 1 秒あたりに受信するリクエストの数。 |
リクエスト(成功率) | % | CoreDNS が受信したリクエストの成功率。 説明 レスポンスコード NXDOMAIN または NOERROR が返された場合、リクエストは成功したと見なされます。 |
リクエスト(ゾーン別) | リクエスト/秒 | CoreDNS がゾーンごとに 1 秒あたりに受信するリクエストの数。 |
リクエスト (qtype 別) | リクエスト/秒 | CoreDNS が解決タイプごとに 1 秒あたりに受信するリクエストの数。 |
リクエスト (DO ビット) | リクエスト/秒 | CoreDNS が 1 秒あたりに受信するリクエストの数。 DO ビットを含むリクエストのみがカウントされます。 |
リクエスト (サイズ、udp) | バイト | CorDNS が受信する各 UDP パケットのサイズ。 |
リクエスト (サイズ、tcp) | バイト | CorDNS が受信する各 TCP パケットのサイズ。 |
レスポンス (rcode 別) | リクエスト/秒 | 各レスポンスコードのレスポンスの数。 |
レスポンス (期間) | 秒 | 99 パーセンタイル、90 パーセンタイル、および 50 パーセンタイルでの応答時間。 |
レスポンス (サイズ、udp) | バイト | 99 パーセンタイルと 50 パーセンタイルでの UDP リクエストのレスポンスパケットサイズ。 |
レスポンス (サイズ、tcp) | バイト | 99 パーセンタイルと 50 パーセンタイルでの TCP リクエストのレスポンスパケットサイズ。 |
キャッシュ (サイズ) | 該当なし | キャッシュの数。 |
キャッシュ (hitrate) | % | バッファヒット率。 |
一般的な異常
異常 | 説明 |
CoreDNS が受信するリクエストの数が急激に増加します。 | ダッシュボードの [リクエスト(合計)] グラフで、CoreDNS が受信したリクエストの数を確認できます。 CoreDNS が受信するリクエストの数が急激に増加した場合は、CoreDNS のログで最も頻繁にアクセスされるドメイン名を確認できます。次に、リクエストの増加が正常かどうかを判断できます。 CoreDNS のログを分析および監視する方法の詳細については、「CoreDNS ログの収集と分析」をご参照ください。リクエストの増加が正常な場合は、CoreDNS のポッドをさらに作成し、NodeLocal DNSCache を使用して DNS パフォーマンスを向上させることをお勧めします。詳細については、「CoreDNS の高可用性を確保する」および「NodeLocal DNSCache を構成する」をご参照ください。 |
DNS サーバーでエラーが発生し、レスポンスコード ServFail のレスポンスの数が多くなります。 | ダッシュボードの [レスポンス (rcode 別)] グラフで、レスポンスコード ServFail のレスポンスの数を確認できます。 レスポンスコード ServFail のレスポンスの数が多い場合は、CoreDNS のログを確認し、関連するドメイン名をトラブルシューティングすることをお勧めします。 CoreDNS のログを分析および監視する方法の詳細については、「CoreDNS ログの収集と分析」をご参照ください。 |
CoreDNS の応答時間が長くなります。 | ダッシュボードの [レスポンス (期間)] グラフで、応答時間を確認できます。 多数のアプリケーションが外部ドメイン名を使用している場合、CoreDNS の応答時間が長くなる可能性があります。 |
メトリック
Application Real-Time Monitoring Service (ARMS) を有効にして CoreDNS ダッシュボードを生成しない場合は、セルフマネージド Prometheus インスタンスで CoreDNS を監視できます。次の表に、CoreDNS メトリックを示します。
次の表は、CoreDNS 1.9.3 のメトリックについて説明しています。詳細については、CoreDNS 公式ドキュメント を参照してください。
メトリック | データ型 | 説明 |
requests_total | カウンター | サーバー、ゾーン、プロトコル、ファミリ、タイプなどの側面からの DNS クエリの数。 |
request_duration_seconds | ヒストグラム | サーバーとゾーンの側面からの応答時間。 |
request_size_bytes | ヒストグラム | サーバー、ゾーン、プロトコルの側面からの DNS クエリのサイズ。ヒストグラムバケットのしきい値には、0、100、200、300、400、511、1023、2047、4095、8291、16e3、32e3、48e3、64e3 が含まれます。単位:秒。 |
do_requests_total | カウンター | サーバーとゾーンの側面から DO ビットを含む DNS クエリの数。 |
response_size_bytes | ヒストグラム | サーバー、ゾーン、プロトコルの側面からの DNS レスポンスのパケットサイズ。ヒストグラムバケットのしきい値には、0、100、200、300、400、511、1023、2047、4095、8291、16e3、32e3、48e3、64e3 が含まれます。単位:秒。 |
responses_total | カウンター | サーバー、ゾーン、rcode、プラグインなどの側面からの DNS レスポンスの数。 |
panics_total | カウンター | CoreDNS で発生するパニックの数。 |
plugin_enabled | ゲージ | サーバー、ゾーン、名前などの側面からプラグインが有効になっているかどうかを示します。 |
https_responses_total | カウンター | サーバーとステータスの側面からの DNS over HTTPS (DoH) クエリの数。 |