このトピックでは、Alibaba Cloudが提供するGPU共有ソリューションを紹介し、GPU sharing Professional Editionの利点について説明し、GPU Sharing Basic EditionとGPU Sharing Professional Editionの機能と使用シナリオを比較します。 これにより、GPU共有をよりよく理解して使用できます。
背景情報
GPU共有を使用すると、同じGPUデバイスで複数のコンテナーを実行できます。 Alibaba Cloud Container Service for Kubernetes (ACK) がGPU共有をオープンソースにした後、Alibaba Cloudとオンプレミスデータセンターの両方のコンテナークラスターにGPU共有フレームワークを実装できます。 これにより、複数のコンテナが同じGPUデバイスを共有できるため、使用コストが削減されます。
ただし、コスト効率を達成する一方で、GPU上のコンテナの安定した動作を保証することも不可欠です。 各コンテナに割り当てられたGPUリソースを分離することにより、同じGPU上の各コンテナのリソース使用量を制限することができ、リソースの過剰使用による相互干渉を防ぐことができます。 この問題を解決するために、NVIDIA vGPU、Multi-Process Service (MPS) 、vCUDAなどの多くのソリューションがコンピューティング業界で提供され、より洗練されたGPU使用管理を実現しています。
これらの要件を満たすために、ACKはGPU共有ソリューションを導入しました。 このソリューションでは、単一のGPUを複数のタスクで共有できるだけでなく、同じGPU上の異なるアプリケーションに対してメモリ分離とGPUコンピューティングパワーパーティショニングを実現します。
特徴と利点
GPU共有ソリューションは、Alibaba Cloudによって開発されたサーバーカーネルドライバーを使用して、NVIDIA GPUの基盤となるドライバーをより効率的に使用します。 GPU共有は、次の機能を提供します。
高い互換性: GPU共有は、KubernetesやNVIDIA Dockerなどの標準のオープンソースソリューションと互換性があります。
使いやすさ: GPU共有は優れたユーザーエクスペリエンスを提供します。 AIアプリケーションのCompute Unified Device Architecture (CUDA) ライブラリを置き換えるために、アプリケーションを再コンパイルしたり、新しいコンテナイメージを作成したりする必要はありません。
安定性: GPU共有は、NVIDIA GPUで安定した基礎操作を提供します。 CUDAライブラリでのAPI操作、およびCUDA Deep Neural Network (cuDNN) での一部のプライベートAPI操作を呼び出すのは困難です。
リソースの分離: GPU共有により、割り当てられたGPUメモリとコンピューティングパワーが相互に影響しないようにします。
GPU共有は、費用対効果が高く、信頼性が高く、使いやすいソリューションを提供し、GPUのスケジューリングとメモリの分離を可能にします。
メリット | 説明 |
GPU共有、スケジューリング、およびメモリ分離をサポートします。 |
|
柔軟なGPU共有およびメモリ分離ポリシーをサポートします。 |
|
GPUリソースの包括的なモニタリングをサポートします。 | 専用GPUと共有GPUの両方のモニタリングをサポートします。 |
無料 | GPU共有を使用する前に、クラウドネイティブAIスイートを有効化する必要があります。 2024年6月6日の00:00:00 (UTC + 8) から、Cloud Native AI Suiteは完全に無料で使用できます。 |
使用上の注意
GPU共有はACK Proクラスターのみをサポートします。 GPU共有をインストールして使用する方法の詳細については、以下のトピックを参照してください。
GPU共有によって提供される次の高度な機能を使用することもできます。
用語
共有モードと排他モード
次の図に示すように、共有モードでは、複数のポッドが1つのGPUを共有できます。 
次の図に示すように、排他モードでは、ポッドが1つ以上のGPUを排他的に占有できます。 
GPUメモリ分離
GPU共有は、複数のポッドが1つのGPUで実行されることのみを保証できますが、GPUメモリの分離が無効になっている場合、ポッド間のリソース競合を防ぐことはできません。 次のセクションは例を示します。
Pod 1は5 GiBのGPUメモリを要求し、Pod 2は10 GiBのGPUメモリを要求します。 GPUメモリの分離が無効になっている場合、Pod 1は最大10 GiBのGPUメモリを使用できます。これには、Pod 2が要求した5 GiBのGPUメモリが含まれます。 その結果、ポッド2はGPUメモリが不足して起動できません。 GPUメモリ分離を有効にした後、ポッド1が要求された値より大きいGPUメモリを使用しようとすると、GPUメモリ分離モジュールはポッド1を強制的に失敗させます。 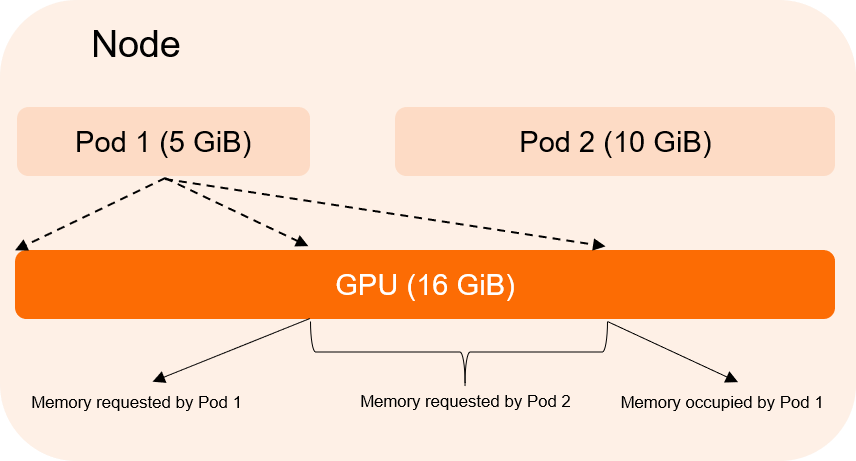
GPUスケジューリングポリシー: binpackとspread
GPU共有機能が有効になっているノードに複数のGPUがある場合、次のいずれかのGPU選択ポリシーを選択できます。
Binpack: デフォルトでは、binpackポリシーが使用されます。 スケジューラは、別のGPUに切り替える前に、GPUのすべてのリソースをポッドに割り当てます。 これにより、GPUフラグメントを防ぐことができます。
Spread: スケジューラは、GPUに障害が発生したときにビジネスの中断が発生した場合に、ノード上の異なるGPUにポッドを拡散しようとします。
この例では、ノードは2つのGPUを有する。 各GPUは15 GiBのメモリを提供します。 Pod1は2 GiBのメモリを要求し、Pod2は3 GiBのメモリを要求します。
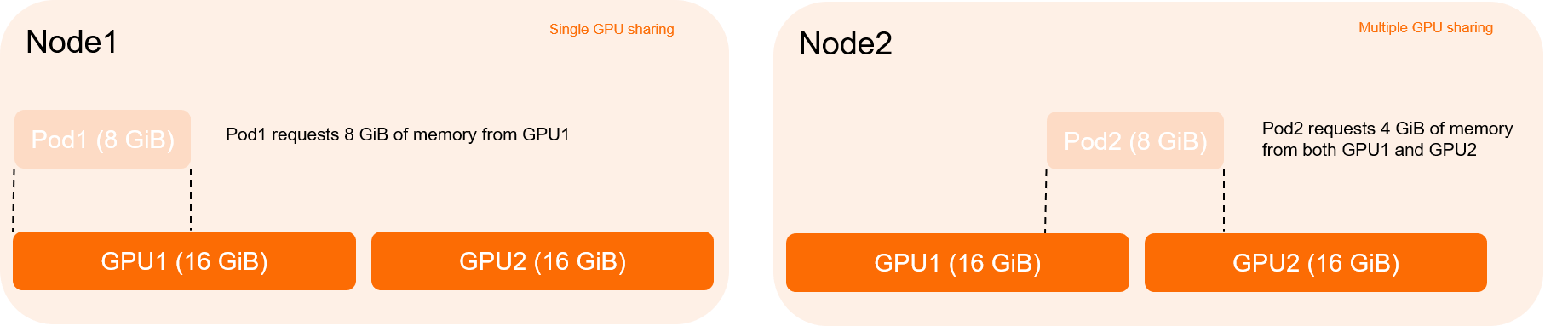
単一GPU共有および複数GPU共有
単一GPU共有: ポッドは、1つのGPUによってのみ割り当てられたGPUリソースを要求できます。
複数のGPU共有: ポッドは、複数のGPUによって均等に割り当てられたGPUリソースを要求できます。